【Go语言开发指南】:7个技巧助你提升Go环境搭建效率与性能
发布时间: 2024-10-23 19:59:28 阅读量: 28 订阅数: 39 

Go语言入门指南:特性、搭建环境及实践应用

# 1. Go语言简介与开发环境搭建
## 简介
Go语言,亦称为Golang,由Google开发,是一种开源的编程语言,旨在提升编程效率并加强系统软件开发。它具有简洁、快速、安全等特性,非常适合现代云计算平台和微服务架构的开发。
## 安装与配置
在安装Go语言开发环境之前,确保你的操作系统兼容。根据你的操作系统,可以从Go官网下载相应的安装包。安装完成后,将Go的安装目录添加到环境变量PATH中,便于在任何目录下使用`go`命令。
### 代码示例:环境变量设置
```sh
# Unix-like系统
export PATH=$PATH:/path/to/your/go/bin
# Windows系统
set PATH=%PATH%;C:\path\to\your\go\bin
```
## 开发工具
除了基础的命令行工具,你还可以使用像Visual Studio Code、GoLand这样的集成开发环境(IDE)来增强你的开发体验。在VS Code中,安装Go扩展可提供代码高亮、智能补全、语法检查等功能。
### 步骤小结
1. 从[官方网站](***下载Go语言安装包。
2. 安装并根据系统设置环境变量。
3. 选择并配置好适合Go语言开发的IDE。
通过以上步骤,你已经成功搭建了Go语言的开发环境,可以开始你的Go语言学习之旅了。
# 2. Go语言基础语法要点
## 2.1 Go语言的数据类型与变量
### 2.1.1 基本数据类型概览
Go语言拥有多种基础数据类型,包括布尔型(bool)、整型(int)、浮点型(float)、字符串(string)和复杂类型(如数组和结构体)。每种数据类型都有其特定的用途和操作方式。例如,布尔型只能表示`true`或`false`,而整型根据大小和是否带符号分为`int8`到`int64`、`uint8`到`uint64`、`uintptr`,它们的取值范围各不相同。浮点型通常有两种类型:`float32`和`float64`。字符串类型在Go中是不可变的字节序列。
```go
var isTrue bool = true
var身高 float64 = 178.2
var名字 string = "张三"
```
### 2.1.2 变量声明、初始化及作用域
在Go语言中,变量必须在使用前声明,可以使用`var`关键字进行声明。初始化可以使用等号`=`赋予一个初始值。变量的作用域由声明的位置决定,声明在函数内部的变量属于局部变量,而声明在函数外部的变量则属于全局变量。
```go
var globalVar int // 全局变量
func main() {
var localVar int = 10 // 局部变量
println(localVar)
}
```
如果声明时没有指定类型,Go编译器将通过初始化表达式推断出变量的类型。Go还支持简短变量声明方式,使用`:=`操作符,它会自动推断变量类型。
```go
num := 10 // int 类型
str := "Hello Go" // string 类型
```
## 2.2 Go语言的控制结构
### 2.2.1 条件语句与流程控制
条件语句是编程中对条件进行判断,根据条件真假执行不同代码块。Go语言的条件语句使用`if`关键字,条件表达式后不需要加括号,但需要使用大括号`{}`包围代码块。在Go中,`if`语句还可以与初始化语句结合使用,使得在判断条件前可以初始化一个变量。
```go
if num := 10; num > 0 {
println("Number is positive")
} else {
println("Number is negative")
}
```
Go也提供`switch`语句,它不仅限于整数或字符,甚至可以处理字符串。每个`case`后不需要`break`,因为`case`代码块默认就是互斥的。`switch`语句也可以带有一个初始化语句,类似于`if`语句。
```go
switch os := runtime.GOOS; os {
case "darwin":
println("macOS")
case "linux":
println("Linux")
default:
println("Other OS")
}
```
### 2.2.2 循环结构的使用与优化
Go语言提供了三种循环结构:`for`、`while`和`do-while`,尽管在Go中,所有这些循环都可以通过`for`循环实现。`for`循环可以有条件、有范围,甚至可以省略条件和递增/递减部分,只保留初始化部分和循环体。
```go
// 经典的for循环
for i := 0; i < 5; i++ {
println(i)
}
// 只有循环体
for {
// do something
if someCondition {
break
}
}
// for...range 循环遍历数组、切片、字符串
for index, value := range str {
println(index, value)
}
```
在循环中,`break`语句可以立即退出当前循环,而`continue`语句则跳过当前迭代,继续执行下一次迭代。此外,通过标签引用(例如`break label`)可以退出外层循环。
## 2.3 Go语言的函数与方法
### 2.3.1 函数定义、参数与返回值
函数是组织好的、可重复使用的、用来实现单一或相关联功能的代码块。在Go中,函数使用`func`关键字声明,参数列表和返回值类型都写在函数名后面。
```go
func add(x, y int) int {
return x + y
}
```
如果多个连续的参数类型相同,那么可以省略掉前面的类型名称,只需在最后一个参数类型后添加。
```go
func add(x, y int, z ...int) int {
sum := x + y
for _, v := range z {
sum += v
}
return sum
}
```
Go语言的函数可以有多个返回值,这对于错误处理特别有用。在返回值前,必须指明类型。
```go
func swap(x, y string) (string, string) {
return y, x
}
```
### 2.3.2 方法和接收者的基础使用
方法是带有接收者(receiver)的函数。接收者可以是类型的值(value receiver),也可以是指针(pointer receiver)。接收者定义在函数名和参数列表之间。
```go
type MyInt int
func (m MyInt) add(x int) MyInt {
return m + MyInt(x)
}
func (m *MyInt) increment() {
*m++
}
i := MyInt(10)
i.add(5) // 值接收者调用
(&i).increment() // 指针接收者调用
```
调用方法的语法是使用点符号`.`,使用值接收者调用时,方法作用于该值的副本;而使用指针接收者调用时,方法作用于实际的变量。这一点在实现`Set`和`Get`方法时尤其重要,因为通常我们希望改变实际变量的状态,这时应使用指针接收者。
请注意,我们已经详细介绍了Go语言的基础语法要点,包括数据类型、变量、控制结构、函数和方法。在实际的软件开发中,理解这些基础知识对于编写有效且高效的代码至关重要。接下来,我们将深入了解如何利用Go语言进行高效开发实践。
# 3. Go语言高效开发实践
## 3.1 Go语言的并发编程
Go语言提供了一套简洁而强大的并发机制,以goroutines和channels为核心。这种并发模式和传统多线程编程相比,有着更低的资源消耗和更简单的并发管理。
### 3.1.1 Goroutines与Channels的基本使用
Goroutines是Go语言提供的轻量级线程,通过关键字`go`来启动一个新的goroutine。每个goroutine的内存开销非常小,因此可以同时启动成千上万个并发任务。
```go
// 启动一个goroutine的示例
go sayHello()
```
在上述代码中,`sayHello`函数将在一个新的goroutine中异步执行。为了同步goroutines,Go语言引入了channels。Channels是连接并发执行的goroutines的管道,允许goroutines之间进行安全的数据通信。
```go
// 使用channel进行数据通信的示例
ch := make(chan string)
go func() {
ch <- "hello, world"
}()
fmt.Println(<-ch)
```
在上述代码中,我们创建了一个string类型的channel `ch`。然后在goroutine中向`ch`发送了一个字符串消息。主goroutine会等待从`ch`中接收消息,并将其打印出来。
### 3.1.2 并发模式与最佳实践
Go语言中常见的并发模式包括但不限于以下几种:
- **Worker Pool(工作池)**:通过限制同时运行的goroutines数量来有效管理资源。
- **Pipeline(管道)**:一系列goroutines串联起来处理数据流,每个goroutine对输入进行处理并输出到下一个环节。
- **Fan-out/Fan-in(扇出/扇入)**:多个goroutines并发执行任务(扇出),任务完成后将结果合并(扇入)。
最佳实践建议:
- 尽量避免使用共享内存,改用通道来进行goroutines间通信。
- 对于只需要单向通信的场景,可以使用无缓冲通道(unbuffered channel)。
- 考虑使用带缓冲的通道(buffered channel)来避免发送/接收操作的阻塞。
- 在处理耗时操作时,应将其放在独立的goroutine中运行,以便主goroutine可以继续执行其他任务。
## 3.2 Go语言的错误处理与测试
Go语言的错误处理机制独具特色,它要求开发者必须显式地处理错误,确保错误被及时发现和处理。在测试方面,Go语言提供了一套完善的测试工具和框架,以帮助开发者编写可靠、可维护的代码。
### 3.2.1 错误处理机制和技巧
Go语言中的错误处理通常通过返回一个错误值(`error`类型)来实现。错误值通常是`nil`,表示没有错误发生,或者是一个实现了`Error()`方法的实例,用于提供错误信息。
```go
// 错误处理的基本模式
resp, err := doSomething()
if err != nil {
// 错误处理逻辑
fmt.Println("Error:", err)
return
}
fmt.Println("Response:", resp)
```
在上述代码中,`doSomething`函数可能返回一个错误,因此我们需要检查返回的`err`是否为`nil`。如果不为`nil`,则表示发生了错误,并对其进行处理。
错误处理的技巧包括:
- 尽早返回错误:避免过深的嵌套导致代码难以阅读。
- 定义自定义错误:使用结构化数据来描述错误。
- 错误包装:使用`fmt.Errorf`来增加上下文信息,便于追踪错误源头。
- 异常断言:使用类型断言或类型切换来区分不同的错误情况。
### 3.2.* 单元测试和基准测试的编写
Go语言的测试框架提供了一种简单的方式来编写和运行测试。单元测试通常位于`*_test.go`文件中,并且函数名称以`Test`开头。测试函数接受一个指向`*testing.T`的指针参数,用于报告失败和日志。
```go
// TestAdd是加法函数的单元测试示例
func TestAdd(t *testing.T) {
result := Add(1, 2)
if result != 3 {
t.Errorf("Add(1, 2) failed. Got %d instead of 3", result)
}
}
```
基准测试(Benchmark)则使用`Benchmark`前缀来命名函数,并接受一个`*testing.B`参数。基准测试函数可以多次运行代码,以测量性能。
```go
// BenchmarkAdd是加法函数的基准测试示例
func BenchmarkAdd(b *testing.B) {
for i := 0; i < b.N; i++ {
Add(1, 2)
}
}
```
在上述基准测试代码中,`b.N`是一个由测试框架控制的循环计数器,用于确定执行次数。基准测试常用于性能调优,确保改进代码不会带来性能的下降。
## 3.3 Go语言的代码组织与模块化
随着项目规模的增长,代码组织和模块化设计显得至关重要。Go语言通过包(package)和模块(module)来实现代码的组织和依赖管理。
### 3.3.1 包的管理和依赖管理
Go语言的每个源文件都属于一个包,通过`package`声明来标识。包在文件系统中以目录形式组织,同一目录下的所有.go文件都属于同一个包。包的主要作用是封装和隔离,它提供了一种封装和重用代码的方式。
Go的包机制还提供了导入(import)功能,可以导入其他包中的函数、类型和变量。对于依赖的管理,Go从1.11版本开始引入了模块(module)的概念,使用`go.mod`文件来管理依赖。
```go
// 导入math包并使用其Sqrt函数
import "math"
func compute() {
result := math.Sqrt(16)
fmt.Println("The square root of 16 is", result)
}
```
在上述代码中,通过`import "math"`来导入了math包,并使用了其中的`Sqrt`函数。
### 3.3.2 模块化设计与代码复用
模块化设计是指将复杂的系统分解为简单的、可独立工作的组件或模块。Go语言鼓励开发者通过接口和组合来实现模块化设计,而不是继承。通过定义一组方法来表示接口,任何类型只要实现了接口的所有方法,就可以表示为接口类型。
```go
// 定义一个接口
type Speaker interface {
Speak() string
}
// 一个实现了Speaker接口的结构体
type Cat struct{}
func (c Cat) Speak() string {
return "Meow!"
}
```
在上述代码中,`Speaker`是一个接口,定义了`Speak`方法。`Cat`结构体实现了`Speaker`接口,因为`Cat`提供了`Speak`方法的具体实现。这种方式使得代码更加灵活和可复用。
代码复用在Go中通常是通过组合和嵌入来实现。通过将一个结构体嵌入到另一个结构体中,可以复用嵌入结构体的字段和方法,从而减少代码冗余。
```go
// 嵌入结构体以复用方法
type Animal struct {
Name string
}
func (a Animal) Describe() string {
return fmt.Sprintf("This is %s", a.Name)
}
type Dog struct {
Animal
}
func main() {
d := Dog{Animal{Name: "Rover"}}
fmt.Println(d.Describe()) // This is Rover
}
```
在这个例子中,`Dog`结构体嵌入了`Animal`结构体。`Dog`实例可以访问`Animal`的方法`Describe`,实现了代码的复用。
以上内容详细介绍了Go语言中并发编程的基本使用,以及如何处理错误和编写单元测试。同时,展示了Go语言如何通过包和模块实现代码的组织和模块化设计。这些内容对构建高效、可维护的Go程序至关重要。接下来的章节将探讨Go语言的环境优化与调试技巧,以及如何构建和部署Go项目。
# 4. Go语言环境优化与调试技巧
## 4.1 Go语言的性能优化
### 4.1.1 性能剖析工具介绍
性能优化是软件开发中一个至关重要的环节,特别是在资源受限或者对性能有严格要求的场合。Go语言提供了多种性能剖析工具来帮助开发者识别性能瓶颈。其中,pprof是最常使用的性能分析工具之一。
pprof允许开发者在程序运行时采集 CPU 和内存使用数据,以便分析哪些函数占用了较多的资源。这些数据可以在程序运行结束后,通过 HTTP 界面或者命令行工具进行分析。
pprof的使用通常包括两个步骤:首先是收集数据,其次是分析数据。下面的代码示例展示了如何集成pprof到一个Go程序中,并启动HTTP服务以供性能分析。
```go
package main
import (
"net/http"
_ "net/http/pprof"
)
func main() {
// 其他初始化代码...
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
// 程序主体逻辑...
}
```
在上述代码中,我们通过导入`net/http/pprof`包并启动一个HTTP服务来暴露pprof的接口。启动程序后,我们可以通过浏览器访问`***`来查看性能分析的选项。
### 4.1.2 优化策略与实例分析
性能优化的策略通常围绕以下几个核心点:减少内存分配、优化CPU计算、减少锁争用、避免阻塞调用等。Go语言的性能剖析工具可以帮助我们识别出程序中的热点(hot spots),即那些消耗CPU和内存最多的函数。
以一个简单的例子来看,如果我们发现了一个Web服务器程序在处理请求时的性能瓶颈,我们可以通过pprof分析出来是某个处理函数`ProcessRequest`消耗了过多的CPU时间。此时,我们可以采取以下优化策略:
1. 对`ProcessRequest`函数进行代码审查,查找是否有不必要的内存分配。
2. 利用Go的逃逸分析功能检查函数中局部变量是否可以优化为栈上分配。
3. 在`ProcessRequest`中使用`sync.Pool`来重用对象,减少对象创建和垃圾回收的开销。
4. 如果`ProcessRequest`涉及到并发操作,考虑使用无锁编程技术如原子操作来减少锁争用。
一旦实施了这些优化,我们可以再次使用pprof来确认这些改动是否真正提高了程序的性能。性能优化是一个不断迭代的过程,需要多次分析和调整来不断接近最佳状态。
## 4.2 Go语言的调试工具与方法
### 4.2.1 标准调试工具的使用
Go语言在语言层面提供了许多用于调试的特性。其中`go tool pprof`命令是标准调试工具之一,它与pprof剖析工具配合使用。要使用该命令,首先需要在程序中集成pprof HTTP接口,然后在需要的时候通过以下命令来收集和分析数据:
```shell
go tool pprof ***
```
这条命令会让pprof采集30秒的CPU剖析数据。采集完成后,可以在命令行界面使用`top`、`list`等命令查看具体的性能瓶颈。`top`命令会展示消耗CPU最多的函数列表,而`list`命令可以查看指定函数的代码执行情况。
除了CPU剖析外,pprof还支持内存、阻塞、互斥锁等类型的剖析。针对不同类型的需求,pprof提供了不同的分析方法和命令。
### 4.2.2 高级调试技巧与调试流程优化
除了使用标准的调试工具外,高级调试技巧对于提升调试效率也非常有帮助。例如,使用条件断点可以在满足特定条件时才触发断点,这样可以避免在循环中单步执行过多不必要的步骤。在某些集成开发环境(IDE)中,比如GoLand,提供了这样的高级调试功能。
此外,编写可调试代码也是提高调试效率的重要方法。例如,避免使用全局变量和魔法数字,为代码写上清晰的注释,合理的拆分函数,使得每个函数的职责单一明确。这些良好的编程习惯有助于在调试时快速定位问题的根源。
在调试流程优化方面,可以使用自定义的Go命令来简化调试步骤。比如,可以编写一个名为`go debug`的命令,它可以自动运行程序、附加调试器,并且设置好所有必要的断点和监视变量。通过这种方式,可以将复杂的调试步骤封装成一个简单的命令,提高调试的效率。
## 4.3 Go语言环境配置与管理
### 4.3.1 不同环境下的Go配置
在多环境配置方面,Go提供了一套灵活的环境变量设置方式,以便开发者根据不同的工作环境进行配置。例如,`GOPATH`用于设置项目的工作目录,`GOROOT`用于设置Go的安装目录。为了更精细地管理Go的环境变量,通常会将配置信息放在一个单独的配置文件中,如`.bashrc`或`.zshrc`。
在多环境配置的场景下,不同环境(如开发环境和生产环境)可能会有不同的依赖和构建需求。使用Go Modules可以更加方便地管理项目依赖,同时支持不同环境下的依赖版本切换。
此外,Go还提供了一些工具如`go env`来查看和设置环境变量。比如,下面的命令会设置`GOPATH`并导出所有环境变量:
```shell
go env -w GOPATH=/path/to/my/workspace
```
### 4.3.2 多版本Go环境的管理与切换
随着Go语言版本的不断更新,开发者可能会在同一台机器上使用不同的Go版本。为了管理不同版本的Go,开发者可以使用版本管理工具如`gvm`(Go Version Manager)。
`gvm`允许开发者安装多个版本的Go,并且可以快速切换当前使用的版本。安装好`gvm`后,开发者可以通过以下命令来安装新的Go版本:
```shell
gvm install go1.17
```
安装完成后,可以通过以下命令来切换使用指定版本的Go:
```shell
gvm use go1.17
```
切换版本之后,`gvm`会更新环境变量,使得当前会话使用新的Go版本编译和运行程序。这为开发者提供了极大的灵活性,能够针对不同的项目需求选择最合适的Go语言版本。
通过合理的配置和管理不同环境,开发者可以在保证开发效率的同时,也确保了项目部署的一致性和可靠性。
# 5. Go语言项目构建与部署
## 5.1 Go语言的构建工具和流程
Go语言的构建工具主要依赖于其自身的命令行工具集,而构建流程则往往涉及依赖管理、构建脚本和持续集成与持续部署(CI/CD)的实践。让我们一一来看这些构建相关的环节。
### 5.1.1 依赖管理工具Go Modules
Go Modules是Go官方提供的依赖管理解决方案,它通过引入`go.mod`文件来声明项目依赖,并使用`go get`命令来管理这些依赖。随着Go版本的演进,Go Modules逐渐成为了Go项目依赖管理的事实标准。它简化了包的添加、更新和删除,同时支持版本化依赖。
```go
// 示例go.mod文件
***/myproject
go 1.17
require (
***/***
***/otherpackage v1.0.0
)
```
在项目中使用Go Modules,首先需要初始化项目,通过运行`go mod init`来创建`go.mod`文件,然后在代码中导入相应的包,最后运行`go build`或`go test`命令来编译和测试项目,Go工具链会自动处理依赖。
### 5.1.2 构建脚本和CI/CD流程
在项目中除了利用Go Modules进行依赖管理外,还需要编写构建脚本以自动化构建过程,并利用CI/CD工具实现持续集成和部署。常见的构建脚本可以使用Makefile来编写。
```makefile
# 示例Makefile内容
build:
go build -o myproject
test:
go test -v ./...
release: build
git tag -a v1.0.0 -m "Release version 1.0.0"
git push origin v1.0.0
```
CI/CD流程通常会与代码托管平台(如GitHub、GitLab)结合,使用平台提供的CI/CD服务或者集成第三方CI/CD工具(如Jenkins、Travis CI等)。在这些平台上配置自动化测试、构建、部署和发布工作流,可以大大提高开发效率并保证代码质量。
## 5.2 Go语言应用的部署策略
Go语言的应用部署有多种方式,开发者可以根据具体需求和环境来选择不同的部署策略。
### 5.2.1 传统部署与容器化部署
传统部署方式涉及直接在目标机器上安装运行时和依赖,而容器化部署则采用容器技术(如Docker)来打包应用及其运行时环境,保证应用在不同环境中的运行一致性。
在Docker环境下,开发者可以创建一个`Dockerfile`来定义容器的构建过程:
```Dockerfile
# 示例Dockerfile
FROM golang:1.17
WORKDIR /app
COPY go.mod ./
COPY go.sum ./
RUN go mod download
COPY *.go ./
RUN go build -o /myapp
EXPOSE 8080
CMD ["/myapp"]
```
这个`Dockerfile`定义了基于golang:1.17镜像创建容器,然后复制应用代码和依赖,进行构建,并指定容器启动时运行的应用程序。
### 5.2.2 部署自动化与监控策略
部署自动化可减少人工干预和提高部署的可靠性,常见的自动化部署工具有Ansible、Terraform等。而应用的监控策略则需要选择适合的监控工具(如Prometheus、Grafana)来收集应用运行时的各种指标数据。
```yaml
# 示例Ansible playbook片段
- name: deploy application
hosts: servers
become: yes
tasks:
- name: copy binary to server
copy:
src: /path/to/myapp
dest: /usr/local/bin/myapp
- name: start the application
command: myapp
args:
creates: /var/log/myapp.log
```
监控策略则需要结合实际业务需求,设计合理的监控指标和报警机制,以确保应用的稳定和性能。
## 5.3 Go语言项目管理实践
Go语言项目管理不仅仅是编写代码,还涉及到版本控制、团队协作、文档编写及社区贡献等多方面。
### 5.3.1 代码版本控制与协作
版本控制是项目管理的核心部分,它通过提供历史版本追溯、分支管理等功能来帮助开发者进行协作。Go项目的版本控制通常使用Git,并将代码托管在GitHub、GitLab等平台上。
团队成员通过Pull Request机制进行代码审查和合并。良好的代码审查习惯有助于保持代码质量,同时也便于知识共享和团队成员间的沟通。
### 5.3.2 项目文档和社区贡献指南
清晰的文档是项目成功的关键之一。Go项目文档通常包括README.md、CHANGELOG.md以及可能的API文档等。文档编写应简洁明了,提供项目介绍、安装指南、使用示例、API参考等内容。
社区贡献指南(CONTRIBUTING.md)则为潜在的贡献者提供了如何参与到项目中的具体指导,包括代码风格、提交信息规范、测试要求等。
```markdown
# 示例CONTRIBUTING.md内容
## 如何贡献代码
感谢你对我们的项目感兴趣并希望贡献代码!以下是一些基本步骤和指南:
### 开发环境准备
1. 确保安装了Go语言环境和Git版本控制系统。
2. 使用`go get`获取项目的依赖。
### 提交代码
1. 从`main`分支创建一个新分支进行开发。
2. 提交代码到你的分支并推送到远程仓库。
3. 创建一个Pull Request到`main`分支。
### 代码风格和提交信息
- 代码风格遵循Go官方代码审查指南。
- 提交信息应清晰说明改动的意图。
```
以上就是Go语言项目构建与部署的相关内容。接下来,我们将进一步深入探讨Go语言的测试策略和调试技巧。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Go的社区与生态系统》专栏深入探讨了Go语言的社区和生态系统,涵盖了各种工具、技术和最佳实践。从GoLand和Visual Studio Code等开发环境的深入解析,到Go包管理、标准库和第三方库的选择指南,再到并发编程、内存管理、反射、错误处理和网络编程的进阶技巧,专栏提供了全面的指导。此外,还探讨了微服务架构、测试策略、性能优化、并发控制、模块化和跨语言交互等主题,为Go开发人员提供了构建可扩展、高效和可维护代码库所需的知识和见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
从停机到上线,EMC VNX5100控制器SP更换的实战演练
# 摘要
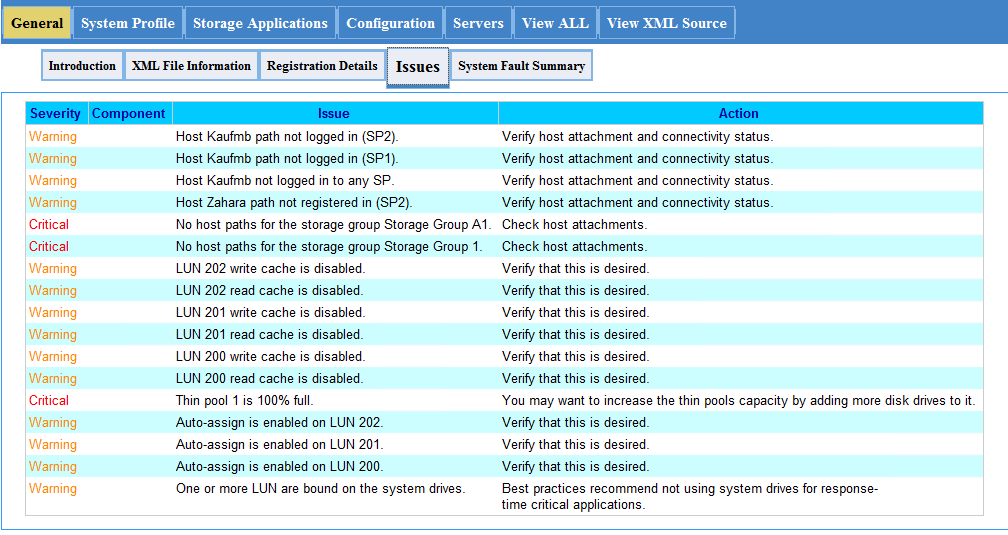
本文详细介绍了EMC VNX5100控制器的更换流程、故障诊断、停机保护、系统恢复以及长期监控与预防性维护策略。通过细致的准备工作、详尽的风险评估以及备份策略的制定,确保控制器更换过程的安全性与数据的完整性。文中还阐述了硬件故障诊断方法、系统停机计划的制定以及数据保护步骤。更换操作指南和系统重启初始化配置得到了详尽说明,以确保系统功能的正常恢复与性能优化。最后,文章强调了性能测试
【科大讯飞官方指南】:语音识别集成与优化的终极解决方案

# 摘要
本文综述了语音识别技术的当前发展概况,深入探讨了科大讯飞语音识别API的架构、功能及高级集成技术。文章详细分析了不同应用场景下语音识别的应用实践,包括智能家居、移动应用和企业级
彻底解决MySQL表锁问题:专家教你如何应对表锁困扰
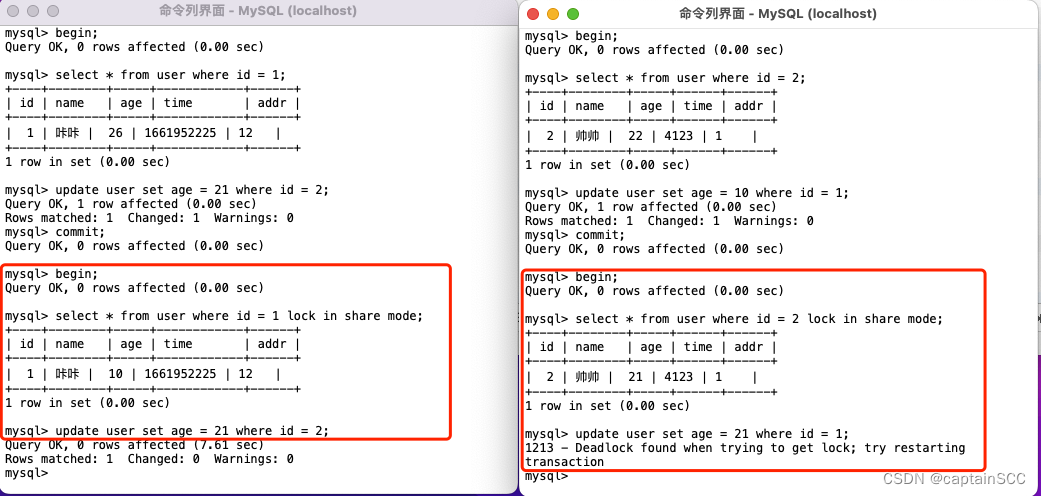
# 摘要
本文深入探讨了MySQL数据库中表锁的原理、问题及其影响。文章从基础知识开始,详细分析了表锁的定义、类型及其与行锁的区别。理论分析章节深入挖掘了表锁产生的原因,包括SQL编程习惯、数据库设计和事务处理,以及系统资源和并发控制问题。性能影响部分讨论了表锁对查询速度和事务处理的潜在负面效果。诊断与排查章节提供了表锁监控和分析工具的使用方法,以及实际监控和调试技巧。随后,本文介绍了避免和解决表锁问题
【双色球数据清洗】:掌握这3个步骤,数据准备不再是障碍
# 摘要
双色球数据清洗作为保证数据分析准确性的关键环节,涉及数据收集、预处理、实践应用及进阶技术等多方面内容。本文首先概述了双色球数据清洗的重要性,并详细解析
【SketchUp脚本编写】

# 摘要
随着三维建模需求的增长,SketchUp脚本编程因其自动化和高效性受到设计师的青睐。本文首先概述了SketchUp脚本编写的基础知识,包括脚本语言的基本概念、SketchUp API与命令操作、控制流与函数的使用。随后,深入探讨了脚本在建模自动化、材质与纹理处理、插件与扩展开发中的实际应用。文章还介绍了高级技巧,如数据交换、错误处理、性能优化
硬盘故障分析:西数硬盘检测工具在故障诊断中的应用(故障诊断的艺术与实践)

# 摘要
本文从硬盘故障的分析概述入手,系统地探讨了西数硬盘检测工具的选择、安装与配置,并深入分析了硬盘的工作原理及故障类型。在此基础上,本文详细阐述了故障诊断的理论基础和实践应用,包括常规状态检测、故障模拟与实战演练。此外,本文还提供了数据恢复与备份策略,以及硬盘故障处理的最佳实践和预防措施,旨在帮助读者全面理解和
关键参数设置大揭秘:DEH调节最佳实践与调优策略
# 摘要
本文系统地介绍了DEH调节技术的基本概念、理论基础、关键参数设置、实践应用、监测与分析工具,以及未来趋势和挑战。首先概述了DEH调节技术的含义和发展背景。随后深入探讨了DEH调节的原理、数学模型和性能指标,详细说明了DEH系统的工作机制以及控制理论在其中的应用。重点分析了DEH调节关键参数的配置、优化策略和异
【面向对象设计在软件管理中的应用】:原则与实践详解
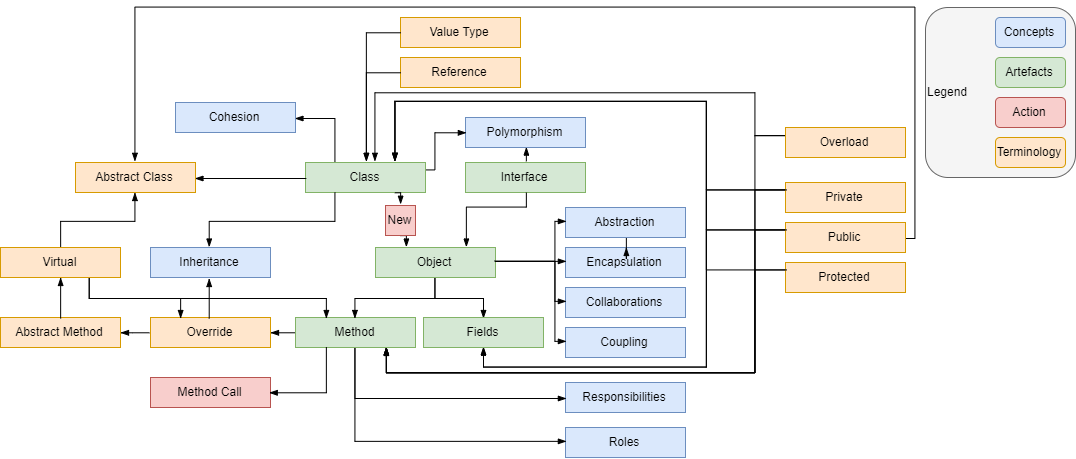
# 摘要
面向对象设计(OOD)是软件工程中的核心概念,它通过封装、继承和多态等特性,促进了代码的模块化和复用性,简化了系统维护,提高了软件质量。本文首先回顾了OOD的基本概念与原则,如单一职责原则(SRP)、开闭原则(OCP)、里氏替换原则(LSP)、依赖倒置原则(DIP)和接口隔离原则(ISP),并通过实际案例分析了这些原则的应用。接着,探讨了创建型、结构型和行为型设计模式在软件开发中的应用,以及面向对象设计
【AT32F435与AT32F437 GPIO应用】:深入理解与灵活运用

# 摘要
AT32F435/437微控制器作为一款广泛应用的高性能MCU,其GPIO(通用输入/输出端口)的功能对于嵌入式系统开发至关重要。本文旨在深入探讨GPIO的基础理论、配置方法、性能优化、实战技巧以及在特定功能中的应用,并提供故障诊断与排错的有效方法。通过详细的端口结构分析、寄存器操作指导和应用案例研究,
【sCMOS相机驱动电路信号同步处理技巧】:精确时间控制的高手方法
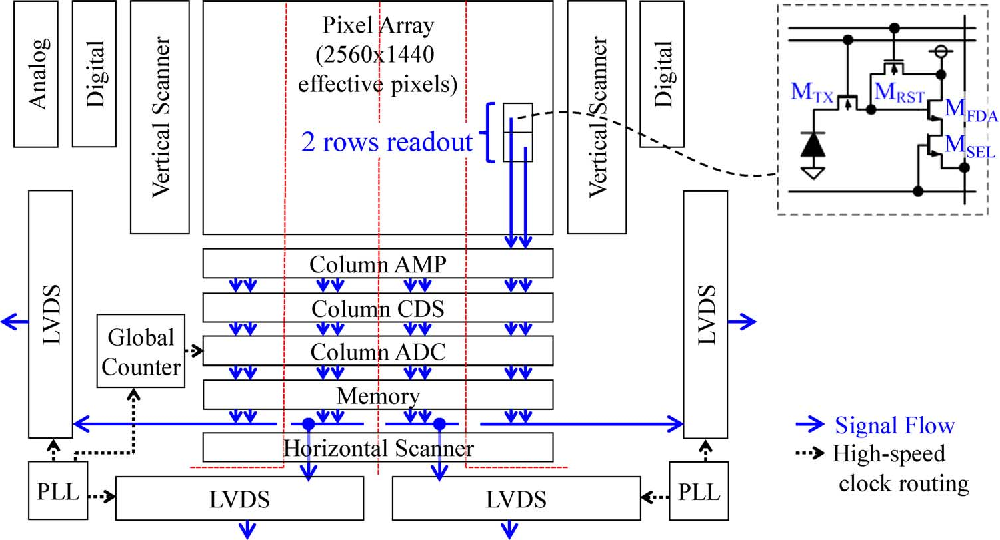
# 摘要
sCMOS相机作为高分辨率成像设备,在科学研究和工业领域中发挥着重要作用。本文首先概述了sCMOS相机驱动电路信号同步处理的基本概念与必要性,然后深入探讨了同步处理的理论基础,包括信号同步的定义、分类、精确时间控制理论以及时间延迟对信号完整性的影响。接着,文章进入技术实践部分,详细描述了驱动电路设计、同步信号生成控制以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )