主从复制模式下的数据冲突处理方法
发布时间: 2024-01-26 12:23:50 阅读量: 34 订阅数: 32 
# 1. 主从复制模式的原理和应用介绍
#### 1.1 主从复制模式的基本概念
主从复制是一种常见的数据库技术,它将一个数据库服务器(主服务器)的数据复制到其他多个从服务器上。主服务器负责处理数据写入和更新操作,从服务器负责数据备份和读取请求。主从复制模式的核心原理是通过二进制日志(binlog)实现数据的复制和同步。主从复制模式广泛应用于大型分布式系统中,可以提高数据的可用性和性能。
#### 1.2 主从复制模式在数据库和分布式系统中的应用
主从复制模式在数据库系统中被广泛应用,如MySQL、Oracle等。它可以提供高可用性和容灾能力,提升系统的并发处理能力。此外,主从复制模式还可以应用于分布式系统中,将数据分散存储在多个服务器上,提高系统的数据读取速度和负载均衡能力。
#### 1.3 主从复制模式的优势和局限性
主从复制模式具有以下优势:
- 提供了数据冗余,提高了系统的可用性和容错能力。
- 实现了读写分离,提高了系统的并发处理能力。
- 支持数据备份和恢复,提供了数据安全性保障。
主从复制模式也存在一些局限性:
- 需要维护额外的从服务器,增加了系统的复杂性和维护成本。
- 数据同步延迟问题,从服务器的数据可能与主服务器存在一定的时间差。
- 数据冲突处理是一个挑战,需要采取合适的策略和技术来解决冲突。
以上是关于主从复制模式的原理和应用介绍的第一章内容。下面将进入第二章,详细分析主从复制模式下数据冲突的原因。
# 2. 主从复制模式下数据冲突的原因分析
在主从复制模式下,数据冲突是一个常见的问题,主要原因包括数据写入冲突、数据更新冲突和数据删除冲突。本章将对这些原因进行详细分析,并探讨相应的解决方法。
### 2.1 数据写入冲突
数据写入冲突指的是多个节点同时向主数据库写入数据时发生的冲突。在主从复制模式中,当多个从节点同时向主节点提交写入请求时,由于网络延迟等因素,可能导致多个从节点写入不同的数据,进而产生冲突。
在解决数据写入冲突时,可以采用以下方法之一:
- 使用全局唯一标识符(GUID)来标识写入的数据,确保每个节点写入的数据都是唯一的;
- 设置写入优先级,当多个写入请求同时到达主节点时,根据优先级确定写入的顺序,避免冲突的发生;
- 引入锁机制,在写入数据前对相应的资源进行加锁,保证只有一个节点能够进行写入操作。
下面是一个使用Python实现数据写入冲突处理的示例代码:
```python
# 定义一个全局唯一标识符生成函数
def generate_guid():
# 实现生成GUID的逻辑
...
# 定义数据写入函数
def write_data(data):
# 生成唯一标识符
guid = generate_guid()
# ...
# 实现数据写入的逻辑
# ...
# 使用示例
data = ...
write_data(data)
```
### 2.2 数据更新冲突
数据更新冲突指的是在多个节点同时对同一条数据进行更新操作时发生的冲突。在主从复制模式中,由于数据更新操作不能立即同步到所有从节点,可能导致多个节点对同一条数据进行不同的更新操作。
为解决数据更新冲突,可以采用以下方法之一:
- 使用乐观锁(Optimistic Locking)机制,当发现数据更新冲突时,通过版本号或时间戳等方式判断数据是否过期,避免冲突的发生;
- 引入悲观锁(Pessimistic Locking)机制,当执行数据更新操作时,锁定对应的数据,其他节点需要等待锁释放后才能进行更新操作,确保数据一致性。
下面是一个使用Java实现数据更新冲突处理的示例代码:
```java
// 定义一个数据更新函数
public void updateData(int id, String newValue) {
// 使用乐观锁机制进行数据更新
while (true) {
// 获取数据,并获取当前版本号
Data data = getDataByID(id);
int currentVersion = data.getVersion();
// 更新数据
data.setValue(newValue);
// 检查更新后的版本号是否与当前版本号相同
if (compareAndSetVersion(data, currentVersion)) {
// 版本号相同,更新成功
break;
}
// 版本号不同,说明数据已被其他节点更新,重新尝试更新操作
}
}
// 使用示例
int id = ...
String newValue = ...
updateData(id, newValue);
```
### 2.3 数据删除冲突
数

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0

专栏简介
《数据库复制技术中的主从复制模式》专栏深度探索主从复制模式在数据库复制技术中的基本原理与工作流程。通过分析主从复制模式的实现原理和具体的工作流程,该专栏将帮助读者全面了解主从复制模式在数据库复制中的作用和优势。文章内容涵盖了主从复制模式的核心原理、数据同步机制、故障处理以及性能调优等多个方面。专栏旨在帮助读者深入理解主从复制模式并在实际应用中灵活运用,提高数据库的复制效率和可靠性。无论是对于已经熟悉数据库复制技术的从业者,还是对于刚入门的读者,本专栏都将为您提供有深度、实用的论述和指导,帮助您在数据库复制技术领域取得更好的成就。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Adblock Plus高级应用:如何利用过滤器提升网页加载速度

# 摘要
本文全面介绍了Adblock Plus作为一款流行的广告拦截工具,从其基本功能到高级过滤策略,以及社区支持和未来的发展方向进行了详细探讨。首先,文章概述了Adb
【QCA Wi-Fi源代码优化指南】:性能与稳定性提升的黄金法则

# 摘要
本文对QCA Wi-Fi源代码优化进行了全面的概述,旨在提升Wi-Fi性能和稳定性。通过对QCA Wi-Fi源代码的结构、核心算法和数据结构进行深入分析,明确了性能优化的关键点。文章详细探讨了代码层面的优化策略,包括编码最佳实践、性能瓶颈的分析与优化、以及稳定性改进措施。系统层面
网络数据包解码与分析实操:WinPcap技术实战指南
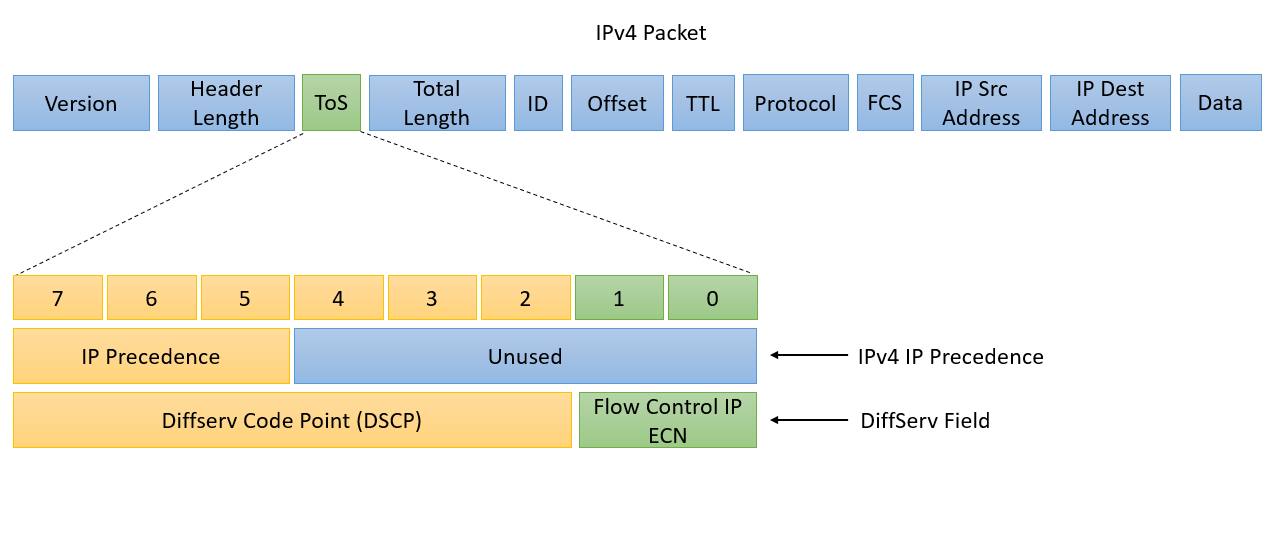
# 摘要
随着网络技术的不断进步,网络数据包的解码与分析成为网络监控、性能优化和安全保障的重要环节。本文从网络数据包解码与分析的基础知识讲起,详细介绍了WinPcap技术的核心组件和开发环境搭建方法,深入解析了数据包的结构和解码技术原理,并通过实际案例展示了数据包解码的实践过程。此外,本文探讨了网络数据分析与处理的多种技术,包括数据包过滤、流量分析,以及在网络安全中的应用,如入侵检测系统和网络
【EMMC5.0全面解析】:深度挖掘技术内幕及高效应用策略

# 摘要
EMMC5.0技术作为嵌入式存储设备的标准化接口,提供了高速、高效的数据传输性能以及高级安全和电源管理功能。本文详细介绍了EMMC5.0的技术基础,包括其物理结构、接口协议、性能特点以及电源管理策略。高级特性如安全机制、高速缓存技术和命令队列技术的分析,以及兼容性和测试方法的探讨,为读者提供了全面的EMMC5.0技术概览。最后,文章探讨了EMMC5.0在嵌入式系统中的应用以及未来的发展趋势和高效应用策略,强调了软硬
【高级故障排除技术】:深入分析DeltaV OPC复杂问题

# 摘要
本文旨在为DeltaV系统的OPC故障排除提供全面的指导和实践技巧。首先概述了故障排除的重要性,随后探讨了理论基础,包括DeltaV系统架构和OPC技术的角色、故障的分类与原因,以及故障诊断和排查的基本流程。在实践技巧章节中,详细讨论了实时数据通信、安全性和认证
手把手教学PN532模块使用:NFC技术入门指南
# 摘要
NFC(Near Field Communication,近场通信)技术是一项允许电子设备在短距离内进行无线通信的技术。本文首先介绍了NFC技术的起源、发展、工作原理及应用领域,并阐述了NFC与RFID(Radio-Frequency Identification,无线射频识别)技术的关系。随后,本文重点介绍了PN532模块的硬件特性、配置及读写基础,并探讨了
PNOZ继电器维护与测试:标准流程和最佳实践

# 摘要
PNOZ继电器作为工业控制系统中不可或缺的组件,其可靠性对生产安全至关重要。本文系统介绍了PNOZ继电器的基础知识、维护流程、测试方法和故障处理策略,并提供了特定应用案例分析。同时,针对未来发展趋势,本文探讨了新兴技术在PNOZ继电器中的应用前景,以及行业标准的更新和最佳实践的推广。通过对维护流程和故障处理的深入探讨,本文旨在为工程师提供实用的继电器维护与故障处
【探索JWT扩展属性】:高级JWT用法实战解析

# 摘要
本文旨在介绍JSON Web Token(JWT)的基础知识、结构组成、标准属性及其在业务中的应用。首先,我们概述了JWT的概念及其在身份验证和信息交换中的作用。接着,文章详细解析了JWT的内部结构,包括头部(Header)、载荷(Payload)和签名(Signature),并解释了标准属性如发行者(iss)、主题(sub)、受众(aud
Altium性能优化:编写高性能设计脚本的6大技巧

# 摘要
本文系统地探讨了基于Altium设计脚本的性能优化方法与实践技巧。首先介绍了Altium设计脚本的基础知识和性能优化的重要性,强调了缩短设计周期和提高系统资源利用效率的必要性。随后,详细解析了Altium设计脚本的运行机制及性能分析工具的应用。文章第三章到第四章重点讲述了编写高性能设计脚本的实践技巧,包括代码优化原则、脚
Qt布局管理技巧

# 摘要
本文深入探讨了Qt框架中的布局管理技术,从基础概念到深入应用,再到实践技巧和性能优化,系统地阐述了布局管理器的种类、特点及其适用场景。文章详细介绍了布局嵌套、合并技术,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )