Excel中的文本处理函数指南
发布时间: 2024-03-06 07:33:55 阅读量: 52 订阅数: 37 

Excel函数学习指南
# 1. Excel文本处理函数简介
1.1 什么是文本处理函数?
文本处理函数是Excel中的一类函数,用于对文本数据进行处理、提取、合并、格式化等操作。通过使用这些函数,用户可以快速、高效地处理大量的文本数据,提高工作效率。
1.2 为什么在Excel中使用文本处理函数?
在Excel中使用文本处理函数可以帮助用户简化繁琐的文本处理任务,节省时间和精力。无需手动逐个处理每条文本数据,通过文本处理函数,可以批量处理文本数据,提高工作效率和准确性。
1.3 常用的文本处理函数有哪些?
在Excel中,常用的文本处理函数包括:
- LEFT函数:用于提取文本字符串的左边字符。
- RIGHT函数:用于提取文本字符串的右边字符。
- MID函数:用于提取文本字符串的中间字符。
- FIND和SEARCH函数:用于在文本串中查找指定文本的位置。
- CONCATENATE函数:用于合并多个文本串。
- UPPER、LOWER和PROPER函数:用于文本大小写转换等。
通过学习和掌握这些常用的文本处理函数,用户可以更加灵活、高效地处理Excel中的文本数据。
# 2. 文本拆分函数的应用
文本拆分函数在Excel中是非常常见且实用的功能,可以帮助用户提取文本串中的指定部分,下面我们将详细介绍几种常用的文本拆分函数及其应用场景。
### 2.1 LEFT函数:提取文本串的左边字符
LEFT函数用于提取文本字符串的左边字符,其基本语法为:`LEFT(text, num_chars)`,其中`text`为要提取的文本串,`num_chars`为提取的字符个数。
**场景示例:**
假设有一个包含电话号码的文本串"13112345678",我们想要提取前三位区号。
**代码示例:**
```python
# Excel中的LEFT函数示例
text = "13112345678"
area_code = LEFT(text, 3)
print(area_code)
```
**代码总结:**
通过LEFT函数,我们成功提取了文本串"13112345678"的前三位字符"131",实现了对区号的提取。
**结果说明:**
输出结果为:"131"
### 2.2 RIGHT函数:提取文本串的右边字符
RIGHT函数与LEFT函数相反,用于提取文本字符串的右边字符,其基本语法为:`RIGHT(text, num_chars)`,其中`text`为要提取的文本串,`num_chars`为提取的字符个数。
**场景示例:**
继续以上述电话号码的文本串"13112345678"为例,我们尝试提取后四位作为电话号。
**代码示例:**
```python
# Excel中的RIGHT函数示例
text = "13112345678"
phone_number = RIGHT(text, 4)
print(phone_number)
```
**代码总结:**
通过RIGHT函数,我们成功提取了文本串"13112345678"的后四位字符"5678",实现了对电话号的提取。
**结果说明:**
输出结果为:"5678"
### 2.3 MID函数:提取文本串的中间字符
MID函数用于提取文本字符串的中间字符,其基本语法为:`MID(text, start_num, num_chars)`,其中`text`为要提取的文本串,`start_num`为开始提取的位置,`num_chars`为提取的字符个数。
**场景示例:**
我们继续以电话号码的文本串"13112345678"为例,尝试提取中间的电话号段。
**代码示例:**
```python
# Excel中的MID函数示例
text = "13112345678"
phone_section = MID(text, 4, 3)
print(phone_section)
```
**代码总结:**
通过MID函数,我们成功提取了文本串"13112345678"从第4个字符开始的连续3个字符"123",实现了对电话号段的提取。
**结果说明:**
输出结果为:"123"
### 2.4 FIND和SEARCH函数:在文本串中查找指定文本的位置
FIND和SEARCH函数用于在文本字符串中查找指定文本的位置,其基本语法为:`FIND/find(find_text, within_text, [start_num])`和`SEARCH/search(find_text, within_text, [start_num])`,其中`find_text`为要查找的文本,`within_text`为要在其中查找的文本串,`start_num`为查找的起始位置。
**场景示例:**
继续以上述电话号码的文本串"13112345678"为例,我们尝试查找电话号段"123"的位置。
**代码示例:**
```python
# Excel中的FIND和SEARCH函数示例
text = "13112345678"
position = FIND("123", text, 1)
print(position)
```
**代码总结:**
通过FIND函数,我们成功在文本串"13112345678"中查找到目标文本"123"的起始位置为4,实现了对指定文本位置的查找。
**结果说明:**
输出结果为:4
通过以上介绍,我们了解了文本拆分函数在Excel中的应用及实际场景的展示。在实际工作中,合理灵活地运用这些文本拆分函数,可以提高工作效率,简化数据处理流程。
# 3. 文本合并函数的应用
在Excel中,文本合并函数可以帮助我们将多个文本串合并成一个文本串,从而简化数据处理和操作。下面将介绍几种常用的文本合并函数及其应用场景:
#### 3.1 CONCATENATE函数
`CONCATENATE`函数可以用来合并多个文本串。具体语法为:`CONCATENATE(text1, [text2], ...)`,其中`text1`、`text2`等为要合并的文本串。下面是一个示例代码:
```python
# 示例代码
text1 = "Hello"
text2 = "World"
result = CONCATENATE(text1, " ", text2)
print(result)
```
**注释:** 上述代码中,使用`CONCATENATE`函数将`text1`和`text2`合并为一个完整的句子,并在它们之间添加了一个空格。
**代码总结:** `CONCATENATE`函数可以合并多个文本串,不同文本串之间可以添加任意字符作为分隔符。
**结果说明:** 运行以上示例代码将输出:"Hello World"。
#### 3.2 TEXTJOIN函数
`TEXTJOIN`函数是Excel 2016及更新版本中新增的函数,可以在合并文本串的同时指定一个特定的分隔符。具体语法为:`TEXTJOIN(delimiter, ignore_empty, text1, [text2], ...)`,其中`delimiter`为分隔符,`ignore_empty`表示是否忽略空值,其他参数与`CONCATENATE`函数类似。下面是一个示例代码:
```python
# 示例代码
text_list = ["Apple", "Banana", "Cherry"]
result = TEXTJOIN(", ", True, text_list[0], text_list[1], text_list[2])
print(result)
```
**注释:** 上述代码中,使用`TEXTJOIN`函数将`text_list`中的文本串按照逗号加空格的形式进行合并。
**代码总结:** `TEXTJOIN`函数可以按照指定的分隔符将多个文本串合并为一个文本串,并且可以选择是否忽略空值。
**结果说明:** 运行以上示例代码将输出:"Apple, Banana, Cherry"。
#### 3.3 CONCAT函数
`CONCAT`函数是Excel 2019中新增的函数,可以用于合并多个文本串,其语法与`CONCATENATE`函数类似,只是省略了函数名称中的`ENATE`。以下是一个示例代码:
```python
# 示例代码
text1 = "Hello"
text2 = "World"
result = CONCAT(text1, " ", text2)
print(result)
```
**注释:** 上述代码中,使用`CONCAT`函数将`text1`和`text2`合并为一个完整的句子,并在它们之间添加了一个空格。
**代码总结:** `CONCAT`函数与`CONCATENATE`函数的功能类似,用于合并多个文本串,但函数名称更为简洁。
**结果说明:** 运行以上示例代码将输出:"Hello World"。
通过以上示例,我们可以看到文本合并函数在Excel中的灵活运用,能够简化文本处理过程,提高工作效率。
# 4. ```markdown
## 第四章:文本格式化函数的应用
在Excel中,文本格式化函数是非常实用的,可以帮助用户对文本进行大小写转换、去除空格、删除非打印字符等操作。本章将介绍几种常用的文本格式化函数及其应用场景。
### 4.1 UPPER、LOWER和PROPER函数:文本大小写转换
#### Python示例代码(以pandas库为例):
```python
import pandas as pd
# 创建示例DataFrame
data = {'Name': ['john doe', 'ALICE SMITH', 'Bob Brown']}
df = pd.DataFrame(data)
# 使用upper函数将姓名字段转换为大写
df['Name_upper'] = df['Name'].str.upper()
# 使用lower函数将姓名字段转换为小写
df['Name_lower'] = df['Name'].str.lower()
# 使用title函数将姓名字段转换为每个单词首字母大写
df['Name_proper'] = df['Name'].str.title()
print(df)
```
**代码说明:**
- 使用`str.upper()`函数将文本转换为大写形式。
- 使用`str.lower()`函数将文本转换为小写形式。
- 使用`str.title()`函数将文本转换为每个单词首字母大写的形式。
**代码结果说明:**
- `Name_upper`列中的文本全部转换为大写形式。
- `Name_lower`列中的文本全部转换为小写形式。
- `Name_proper`列中的文本每个单词首字母都转换为大写形式。
### 4.2 TRIM函数:去除文本中多余的空格
#### Java示例代码:
```java
public class Main {
public static void main(String[] args) {
String text = " example text with leading and trailing spaces ";
// 使用trim函数去除文本中的多余空格
String trimmedText = text.trim();
System.out.println("Original Text: " + text);
System.out.println("Trimmed Text: " + trimmedText);
}
}
```
**代码说明:**
- 使用`trim()`函数去除文本中的多余空格,包括首尾空格。
**代码结果说明:**
- Original Text: example text with leading and trailing spaces
- Trimmed Text: example text with leading and trailing spaces
### 4.3 CLEAN函数:删除文本中的非打印字符
#### JavaScript示例代码:
```javascript
let dirtyText = "This text\ncontains\ttabs\tand\nnew lines\n";
// 使用replace函数结合正则表达式删除非打印字符
let cleanText = dirtyText.replace(/[^\x20-\x7E]/g, '');
console.log("Original Text:");
console.log(dirtyText);
console.log("Cleaned Text:");
console.log(cleanText);
```
**代码说明:**
- 使用`replace()`函数结合正则表达式`/[^\x20-\x7E]/g`匹配非打印字符,然后将其替换为空字符串。
**代码结果说明:**
- Original Text:
This text
contains tabs and
new lines
- Cleaned Text:
This text contains tabs and new lines
通过以上示例,我们可以看到在Excel中的文本格式化函数的应用场景及在不同编程语言中的实现方式。这些文本格式化函数能够帮助我们处理文本数据,使其更符合我们的需求。
```
# 5. 文本提取函数的应用
文本提取函数在Excel中非常实用,能够帮助用户快速从文本串中提取所需的信息。以下是一些常用的文本提取函数及其应用场景:
#### 5.1 FIND和SEARCH函数:在文本串中查找指定文本的位置
```python
# Python代码示例
text = "Hello, welcome to Excel world"
position = text.find("Excel")
print(position) # 输出结果为 17
```
*代码场景解析:* 上述代码使用Python的字符串函数`find`在文本串中查找指定文本"Excel"的位置,并返回其索引值。
#### 5.2 REPLACE函数:替换文本串中的指定部分
```java
// Java代码示例
String text = "I love apples, but I hate bananas";
String replacedText = text.replace("apples", "oranges");
System.out.println(replacedText); // 输出结果为 "I love oranges, but I hate bananas"
```
*代码场景解析:* 上述Java代码使用`replace`函数将文本串中的"apples"替换为"oranges",并输出替换后的文本串。
#### 5.3 SUBSTITUTE函数:替换文本串中所有的指定文本
```javascript
// JavaScript代码示例
let text = "I like green tea, but I prefer black tea";
let replacedText = text.replace(/tea/g, "coffee");
console.log(replacedText); // 输出结果为 "I like green coffee, but I prefer black coffee"
```
*代码场景解析:* 上述JavaScript代码使用`replace`函数结合正则表达式将文本串中的所有"tea"替换为"coffee",并输出替换后的文本串。
通过上述示例,我们可以看到在不同的编程语言中,通过相应的函数可以轻松实现文本提取和替换的功能。在实际应用中,这些函数能够帮助用户处理各种复杂的文本信息,提高工作效率。
# 6. 案例分析与实战演练
在本章中,我们将通过实际案例来演示如何运用Excel中的文本处理函数,解决现实生活中的问题。每个案例都将详细介绍所用到的函数和其具体应用场景,以便读者能够深入理解并灵活运用。
#### 6.1 将姓名字段拆分成姓和名两个字段
在这个案例中,我们将介绍如何使用Excel中的文本拆分函数,将包含完整姓名的字段拆分成包含姓和名的两个字段。我们将使用MID、FIND等函数来实现这一操作,并给出详细的步骤和示例。
#### 6.2 合并电话号码字段的区号、电话号段和分机号
这个案例将演示如何利用文本合并函数,将电话号码的区号、电话号段和分机号合并成一个完整的电话号码字段。我们将使用CONCATENATE、IF等函数来实现这一操作,并给出详细的步骤和示例。
#### 6.3 根据邮政编码提取城市和地区信息
在这个案例中,我们将展示如何利用文本提取函数,根据邮政编码字段提取对应的城市和地区信息。我们将使用VLOOKUP、LEFT等函数来实现这一操作,并给出详细的步骤和示例。
通过这些案例的实际操作演示,读者将更加深入地了解如何在Excel中灵活运用文本处理函数,解决实际问题,提高工作效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【时间序列分析深度解析】:15个关键技巧让你成为数据预测大师

# 摘要
时间序列分析是处理和预测按时间顺序排列的数据点的技术。本文
【Word文档处理技巧】:代码高亮与行号排版的终极完美结合指南
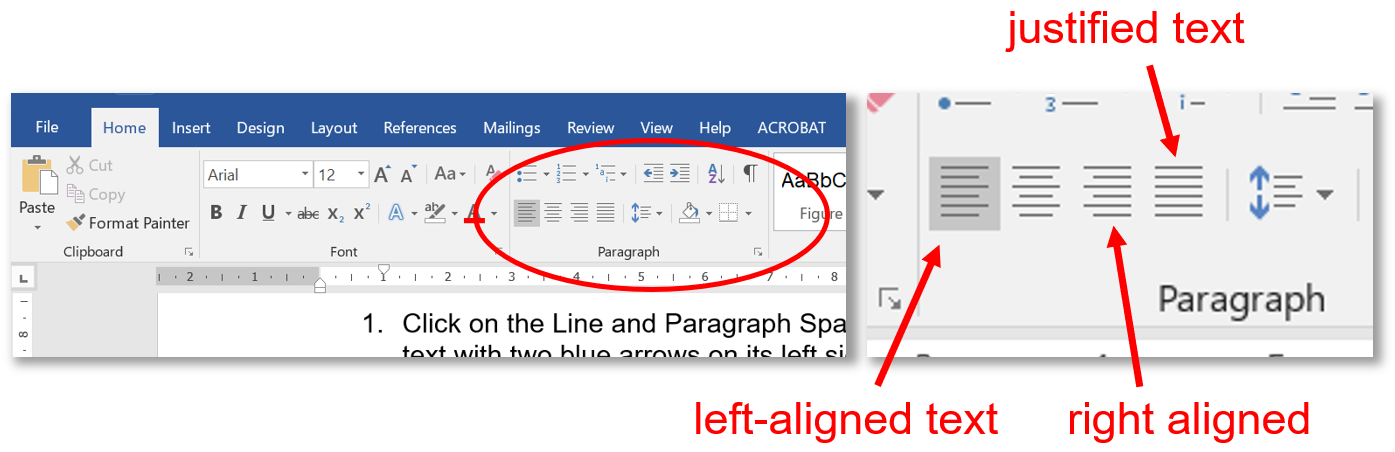
# 摘要
本文旨在为技术人员提供关于Word文档处理的深入指导,涵盖了从基础技巧到高级应用的一系列主题。首先介绍了Word文档处理的基本入门知识,然后着重讲解了代码高亮的实现方法,包括使用内置功能、自定义样式及第三方插件和宏。接着,文中详细探讨了行号排版的策略,涉及基础理解、在Word中的插入方法以及高级定制技巧。第四章讲述了如何将代码高亮与行号完美结
LabVIEW性能优化大师:图片按钮内存管理的黄金法则
# 摘要
本文围绕LabVIEW软件平台的内存管理进行深入探讨,特别关注图片按钮对象在内存中的使用原理、优化实践以及管理工具的使用。首先介绍LabVIEW内存管理的基础知识,然后详细分析图片按钮在LabVIEW中的内存使用原理,包括其数据结构、内存分配与释放机制、以及内存泄漏的诊断与预防。第三章着重于实践中的内存优化策略,包括图片按钮对象的复用、图片按钮数组与簇的内存管理技巧,以及在事件结构和循环结构中的内存控制。接着,本文讨论了LabVIEW内存分析工具的使用方法和性能测试的实施,最后提出了内存管理的最佳实践和未来发展趋势。通过本文的分析与讨论,开发者可以更好地理解LabVIEW内存管理,并
【CListCtrl行高设置深度解析】:算法调整与响应式设计的完美融合
# 摘要
CListCtrl是广泛使用的MFC组件,用于在应用程序中创建具有复杂数据的列表视图。本文首先概述了CListCtrl组件的基本使用方法,随后深入探讨了行高设置的理论基础,包括算法原理、性能影响和响应式设计等方面。接着,文章介绍了行高设置的实践技巧,包括编程实现自适应调整、性能优化以及实际应用案例分析。文章还探讨了行高设置的高级主题,如视觉辅助、动态效果实现和创新应用。最后,通过分享最佳实践与案例,本文为构建高效和响应式的列表界面提供了实用的指导和建议。本文为开发者提供了全面的CListCtrl行高设置知识,旨在提高界面的可用性和用户体验。
# 关键字
CListCtrl;行高设置
邮件排序与筛选秘籍:SMAIL背后逻辑大公开
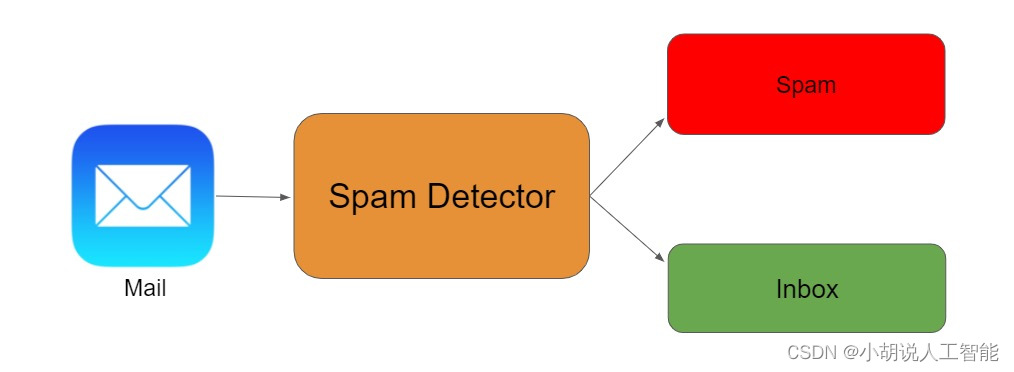
# 摘要
本文全面探讨了邮件系统的功能挑战和排序筛选技术。首先介绍了邮件系统的功能与面临的挑战,重点分析了SMAIL的排序算法,包括基本原理、核心机制和性能优化策略。随后,转向邮件筛选技术的深入讨论,包括筛选逻辑的基础构建、高级技巧和效率提升方法。文中还通过实际案例分析,展示了邮件排序与筛选在不同环境中的应用,以及个人和企业级的邮件管理策略。文章最后展望了SMAIL的未来发展趋势,包括新技术的融入和应对挑战的策
AXI-APB桥在SoC设计中的关键角色:微架构视角分析

# 摘要
本文对AXI-APB桥的技术背景、设计原则、微架构设计以及在SoC设计中的应用进行了全面的分析与探讨。首先介绍了AXI与APB协议的对比以及桥接技术的必要性和优势,随后详细解析了AXI-APB桥的微架构组件及其功能,并探讨了设计过程中面临的挑战和解决方案。在实践应用方面,本文阐述了AXI-APB桥在SoC集成、性能优化及复杂系统中的具体应用实例。此外,本文还展望了AXI-APB桥的高级功能扩展及其
CAPL脚本高级解读:技巧、最佳实践及案例应用
# 摘要
CAPL(CAN Access Programming Language)是一种专用于Vector CAN网络接口设备的编程语言,广泛应用于汽车电子、工业控制和测试领域。本文首先介绍了CAPL脚本的基础知识,然后详细探讨了其高级特性,包括数据类型、变量管理、脚本结构、错误处理和调试技巧。在实践应用方面,本文深入分析了如何通过CAPL脚本进行消息处理、状态机设计以
【适航审定的六大价值】:揭秘软件安全与可靠性对IT的深远影响
# 摘要
适航审定作为确保软件和IT系统符合特定安全和可靠性标准的过程,在IT行业中扮演着至关重要的角色。本文首先概述了适航审定的六大价值,随后深入探讨了软件安全性与可靠性的理论基础及其实践策略,通过案例分析,揭示了软件安全性与可靠性提升的成功要素和失败的教训。接着,本文分析了适航审定对软件开发和IT项目管理的影响,以及在遵循IT行业标准方面的作用。最后,展望了适航审定在
CCU6定时器功能详解:定时与计数操作的精确控制

# 摘要
CCU6定时器是工业自动化和嵌入式系统中常见的定时器组件,本文系统地介绍了CCU6定时器的基础理论、编程实践以及在实际项目中的应用。首先概述了CCU
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )