【Python append函数权威指南】:从入门到精通,掌握高效数据追加
发布时间: 2024-06-25 11:18:33 阅读量: 118 订阅数: 37 

python学习笔记之append的用法介绍

# 1. Python append函数简介
Python 中的 `append()` 函数是一个内置函数,用于在现有列表的末尾追加一个或多个元素。它是一个非常有用的函数,可以轻松地扩展和修改列表。`append()` 函数的语法简单且易于使用,使其成为在 Python 中处理列表时必不可少的工具。
# 2. append函数的语法和参数
### 2.1 append函数的基本语法
append函数的基本语法格式如下:
```python
list.append(element)
```
其中:
* `list`:要追加元素的目标列表。
* `element`:要追加到列表中的元素。
append函数的作用是将指定元素追加到列表的末尾。如果列表中不存在该元素,则会将其添加到列表中;如果列表中已存在该元素,则不会重复添加。
### 2.2 append函数的参数详解
append函数只有一个必需参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| element | 任意对象 | 要追加到列表中的元素 |
此外,append函数还支持一个可选参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| index | 整数 | 指定要插入元素的位置(可选) |
**index参数说明:**
* 如果index参数未指定,则将元素追加到列表的末尾。
* 如果index参数指定了一个有效的索引值,则将元素插入到该索引位置,并将该索引位置及之后的元素向后移动一位。
* 如果index参数指定了一个超出列表范围的索引值,则会引发IndexError异常。
**代码示例:**
```python
# 创建一个空列表
my_list = []
# 向列表中追加元素
my_list.append(1)
my_list.append(2)
my_list.append(3)
# 打印列表
print(my_list) # 输出:[1, 2, 3]
# 在指定索引位置插入元素
my_list.append(1, 4)
# 打印列表
print(my_list) # 输出:[1, 4, 2, 3]
```
# 3.1 向列表中追加元素
append 函数最常见的应用场景是向列表中追加元素。其语法格式如下:
```python
list.append(element)
```
其中,`list` 表示要追加元素的目标列表,`element` 表示要追加的元素。
**代码示例:**
```python
my_list = [1, 2, 3]
my_list.append(4)
print(my_list) # 输出:[1, 2, 3, 4]
```
**逻辑分析:**
* 创建一个列表 `my_list`,包含元素 `[1, 2, 3]`。
* 使用 `append()` 函数向 `my_list` 中追加元素 `4`。
* 打印 `my_list`,输出结果为 `[1, 2, 3, 4]`,表明元素 `4` 已成功追加到列表末尾。
**参数说明:**
* `list`:目标列表,类型为 `list`。
* `element`:要追加的元素,类型可以是任意对象。
### 3.2 向元组中追加元素
虽然元组是不可变对象,但可以使用 `append()` 函数向元组中追加元素。这可以通过将元组转换为列表,执行追加操作,然后再将列表转换为元组来实现。
**代码示例:**
```python
my_tuple = (1, 2, 3)
my_list = list(my_tuple) # 将元组转换为列表
my_list.append(4) # 向列表中追加元素
my_tuple = tuple(my_list) # 将列表转换为元组
print(my_tuple) # 输出:(1, 2, 3, 4)
```
**逻辑分析:**
* 创建一个元组 `my_tuple`,包含元素 `(1, 2, 3)`。
* 将 `my_tuple` 转换为列表 `my_list`。
* 使用 `append()` 函数向 `my_list` 中追加元素 `4`。
* 将 `my_list` 转换为元组 `my_tuple`。
* 打印 `my_tuple`,输出结果为 `(1, 2, 3, 4)`,表明元素 `4` 已成功追加到元组末尾。
**参数说明:**
* `my_tuple`:目标元组,类型为 `tuple`。
* `my_list`:中间转换的列表,类型为 `list`。
* `4`:要追加的元素,类型可以是任意对象。
### 3.3 向字典中追加键值对
`append()` 函数不适用于字典,因为字典是一个无序集合,没有明确的顺序。要向字典中添加键值对,可以使用 `update()` 函数或直接赋值。
**代码示例:**
```python
my_dict = {'name': 'John', 'age': 30}
my_dict['city'] = 'New York' # 直接赋值
print(my_dict) # 输出:{'name': 'John', 'age': 30, 'city': 'New York'}
```
**逻辑分析:**
* 创建一个字典 `my_dict`,包含键值对 `{'name': 'John', 'age': 30}`。
* 使用直接赋值的方式向 `my_dict` 中添加键值对 `'city': 'New York'`。
* 打印 `my_dict`,输出结果为 `{'name': 'John', 'age': 30, 'city': 'New York'}`,表明键值对已成功添加到字典中。
**参数说明:**
* `my_dict`:目标字典,类型为 `dict`。
* `'city'`:要添加的键,类型为 `str`。
* `'New York'`:要添加的值,类型可以是任意对象。
# 4. append函数的进阶用法
### 4.1 使用append函数实现列表合并
append函数不仅可以向列表中追加单个元素,还可以将另一个列表合并到当前列表中。语法如下:
```python
list1.append(list2)
```
其中,`list1`为当前列表,`list2`为要合并的列表。
**代码块逻辑分析:**
此代码将`list2`中的所有元素追加到`list1`的末尾。`list1`的长度将增加`list2`的长度。
**参数说明:**
* `list1`:当前列表,类型为`list`。
* `list2`:要合并的列表,类型为`list`。
**示例:**
```python
list1 = [1, 2, 3]
list2 = [4, 5, 6]
list1.append(list2)
print(list1) # 输出:[1, 2, 3, [4, 5, 6]]
```
### 4.2 使用append函数实现字符串拼接
append函数还可以将字符串追加到列表中。语法如下:
```python
list1.append(string)
```
其中,`list1`为当前列表,`string`为要追加的字符串。
**代码块逻辑分析:**
此代码将`string`转换为列表元素并追加到`list1`的末尾。`list1`的长度将增加1。
**参数说明:**
* `list1`:当前列表,类型为`list`。
* `string`:要追加的字符串,类型为`str`。
**示例:**
```python
list1 = ['a', 'b', 'c']
string = 'd'
list1.append(string)
print(list1) # 输出:['a', 'b', 'c', 'd']
```
### 4.3 使用append函数实现对象的深拷贝
append函数还可以实现对象的深拷贝。深拷贝是指创建对象的副本,副本与原对象完全独立,对副本的修改不会影响原对象。语法如下:
```python
list1.append(copy.deepcopy(object))
```
其中,`list1`为当前列表,`object`为要深拷贝的对象。
**代码块逻辑分析:**
此代码使用`copy.deepcopy()`函数创建`object`的深拷贝,并将深拷贝结果追加到`list1`的末尾。`list1`的长度将增加1。
**参数说明:**
* `list1`:当前列表,类型为`list`。
* `object`:要深拷贝的对象,类型可以是任意对象。
**示例:**
```python
class MyClass:
def __init__(self, value):
self.value = value
list1 = [MyClass(1), MyClass(2)]
list2 = []
list2.append(copy.deepcopy(list1[0]))
list2[0].value = 3
print(list1[0].value) # 输出:1
print(list2[0].value) # 输出:3
```
# 5. append函数的性能优化
在实际应用中,为了提高代码的执行效率,需要对append函数的性能进行优化。以下介绍两种常见的优化方法:
### 5.1 避免频繁调用append函数
频繁调用append函数会造成不必要的性能开销,尤其是在需要向列表中追加大量元素时。为了避免这种情况,可以采用以下方法:
- **使用列表推导或生成器表达式:**列表推导和生成器表达式可以一次性生成新的列表,避免了多次调用append函数的开销。例如:
```python
# 使用append函数
my_list = []
for i in range(100000):
my_list.append(i)
# 使用列表推导
my_list = [i for i in range(100000)]
# 使用生成器表达式
my_list = (i for i in range(100000))
```
- **预分配列表空间:**在知道要追加的元素数量时,可以预先分配列表空间,避免多次重新分配内存的开销。例如:
```python
my_list = [None] * 100000
for i in range(100000):
my_list[i] = i
```
### 5.2 使用列表推导或生成器表达式
列表推导和生成器表达式是Python中强大的工具,可以用来创建新的列表或生成器对象。与append函数相比,列表推导和生成器表达式具有以下优点:
- **一次性生成:**列表推导和生成器表达式可以一次性生成新的列表或生成器对象,避免了多次调用append函数的开销。
- **简洁高效:**列表推导和生成器表达式的语法简洁高效,可以减少代码量和提高可读性。
例如,以下代码使用列表推导将一个列表中的所有元素乘以2:
```python
my_list = [1, 2, 3, 4, 5]
new_list = [x * 2 for x in my_list]
```
而使用append函数实现同样的功能需要多次调用append函数:
```python
my_list = [1, 2, 3, 4, 5]
new_list = []
for x in my_list:
new_list.append(x * 2)
```
通过使用列表推导或生成器表达式,可以显著提高代码的执行效率和可读性。
# 6.1 append函数向不可变对象追加元素的异常处理
在Python中,字符串、元组等对象是不可变的,这意味着它们的内容一旦创建就不能被修改。因此,如果尝试使用append函数向不可变对象追加元素,将会引发TypeError异常。
```python
>>> my_tuple = (1, 2, 3)
>>> my_tuple.append(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'tuple' object has no attribute 'append'
```
为了解决这个问题,可以将不可变对象转换为可变对象,然后再进行追加操作。例如,可以将元组转换为列表,再使用append函数追加元素。
```python
>>> my_tuple = (1, 2, 3)
>>> my_list = list(my_tuple)
>>> my_list.append(4)
>>> my_list
[1, 2, 3, 4]
```
## 6.2 append函数向嵌套对象追加元素的注意事项
当向嵌套对象追加元素时,需要特别注意嵌套对象的类型。如果嵌套对象是可变对象,则直接追加元素即可。但是,如果嵌套对象是不可变对象,则需要先将其转换为可变对象,然后再追加元素。
```python
>>> my_dict = {'name': 'John', 'age': 30}
>>> my_dict['hobbies'] = ['reading', 'writing']
>>> my_dict['hobbies'].append('coding')
>>> my_dict
{'name': 'John', 'age': 30, 'hobbies': ['reading', 'writing', 'coding']}
```
需要注意的是,在向嵌套对象追加元素时,如果嵌套对象是列表或字典,则追加元素不会影响嵌套对象的引用。这意味着,如果在函数内部对嵌套对象进行修改,函数外部的嵌套对象也会受到影响。
```python
def add_hobby(my_dict):
my_dict['hobbies'].append('coding')
my_dict = {'name': 'John', 'age': 30}
add_hobby(my_dict)
print(my_dict) # {'name': 'John', 'age': 30, 'hobbies': ['coding']}
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 append 函数,从入门到精通,涵盖了广泛的主题。从性能优化技巧到最佳实践,再到与 extend 和 insert 函数的比较,您将全面了解如何有效地追加数据。专栏还探讨了 append 函数在不同数据结构中的应用,包括列表、元组和字典。此外,还介绍了进阶用法,如实现动态数组和队列,以及内存管理机制和线程安全问题。通过深入研究 append 函数在数据科学、Web 开发、机器学习、数据分析、自动化测试、系统管理、网络编程、图像处理、自然语言处理和金融科技中的应用,本专栏为您提供了全面而实用的指南,帮助您掌握 Python 中的数据追加技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Masm32基础语法精讲:构建汇编语言编程的坚实地基

# 摘要
本文详细介绍了Masm32汇编语言的基础知识和高级应用。首先概览了Masm32汇编语言的基本概念,随后深入讲解了其基本指令集,包括数据定义、算术与逻辑操作以及控制流指令。第三章探讨了内存管理及高级指令,重点描述了寄存器使用、宏指令和字符串处理等技术。接着,文章转向模块化编程,涵盖了模块化设计原理、程序构建调
TLS 1.2深度剖析:网络安全专家必备的协议原理与优势解读
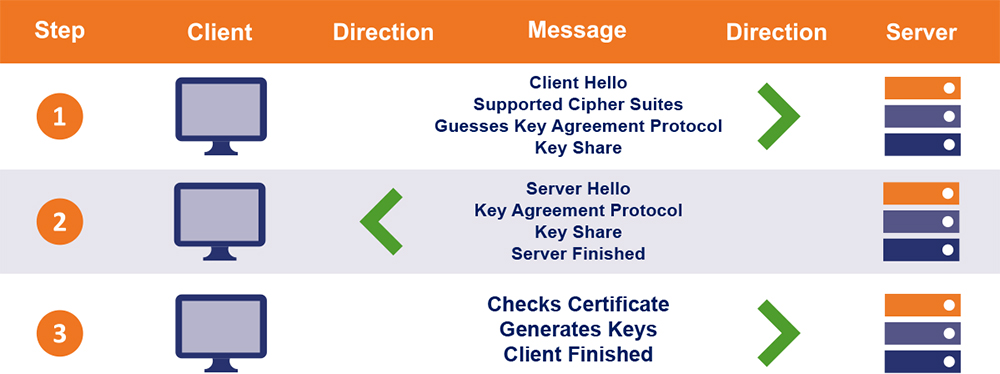
# 摘要
传输层安全性协议(TLS)1.2是互联网安全通信的关键技术,提供数据加密、身份验证和信息完整性保护。本文从TLS 1.2协议概述入手,详细介绍了其核心组件,包括密码套件的运作、证书和身份验证机制、以及TLS握手协议。文章进一步阐述了TLS 1.2的安全优势、性能优化策略以及在不同应用场景中的最佳实践。同时,本文还分析了TLS 1.2所面临的挑战和安全漏
案例分析:TIR透镜设计常见问题的即刻解决方案

# 摘要
TIR透镜设计是光学技术中的一个重要分支,其设计质量直接影响到最终产品的性能和应用效果。本文首先介绍了TIR透镜设计的基础理论,包括光学全内反射原理和TIR透镜设计的关键参数,并指出了设计过程中的常见误区。接着,文章结合设计实践,分析了设计软件的选择和应用、实际案例的参数分析及设计优化,并总结了实验验证的过程与结果。文章最后探讨了TIR透镜设计的问题预防与管理策
ZPL II高级应用揭秘:实现条件打印和数据库驱动打印的实用技巧
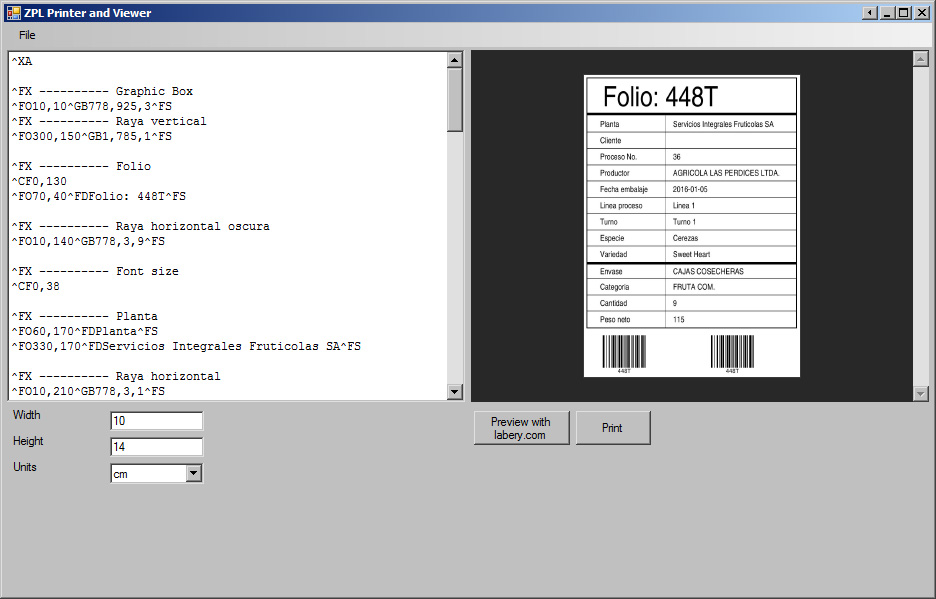
# 摘要
本文对ZPL II打印技术进行了全面的介绍,包括其基本概念、条件打印技术、数据库驱动打印的实现与高级应用、打印性能优化以及错误处理与故障排除。重点分析了条件打印技术在不同行业中的实际应用案例,并探讨了ZPL II技术在行业特定解决方案中的创新应用。同时,本文还深入讨论了自动化打印作业的设置与管理以及ZPL II打印技术的未来发展趋势,为打印技术的集成和业
泛微E9流程设计高级技巧:打造高效流程模板
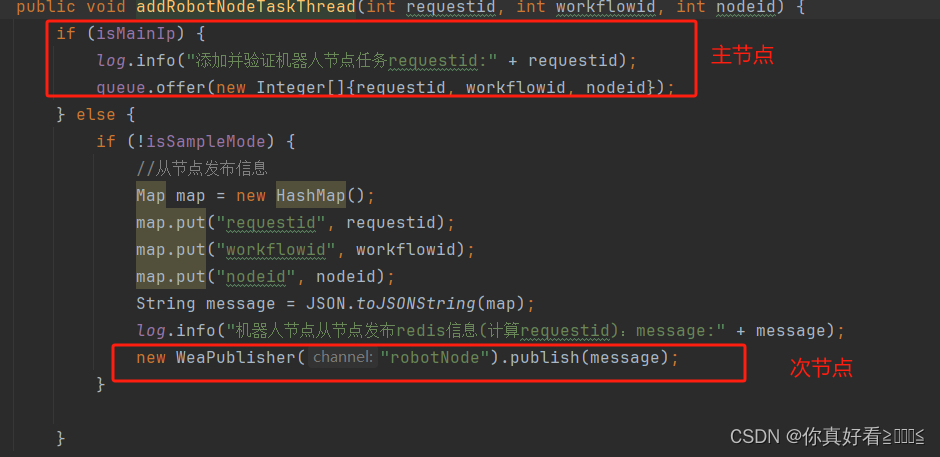
# 摘要
本文系统介绍了泛微E9在流程设计方面的关键概念、基础构建、实践技巧、案例分析以及未来趋势。首先概述了流程模板设计的基础知识,包括其基本组成和逻辑构建,并讨论了权限配置的重要性和策略。随后,针对提升流程设计的效率与效果,详细阐述了优化流程设计的策略、实现流程自动化的方法以及评估与监控流程效率的技巧。第四章通过高级流程模板设计案例分析,分享了成功经验与启示。最后,展望了流程自动化与智能化的融合
约束管理101:掌握基础知识,精通高级工具

# 摘要
本文系统地探讨了约束管理的基础概念、理论框架、工具与技术,以及在实际项目中的应用和未来发展趋势。首先界定了约束管理的定义、重要性、目标和影响,随后分类阐述了不同类型的约束及其特性。文中还介绍了经典的约束理论(TOC)与现代技术应用,并提供了约束管理软件工具的选择与评估。本文对约束分析技术进行了详细描述,并提出风险评估与缓解策略。在实践应用方面,分析了项目生
提升控制效率:PLC电动机启动策略的12项分析
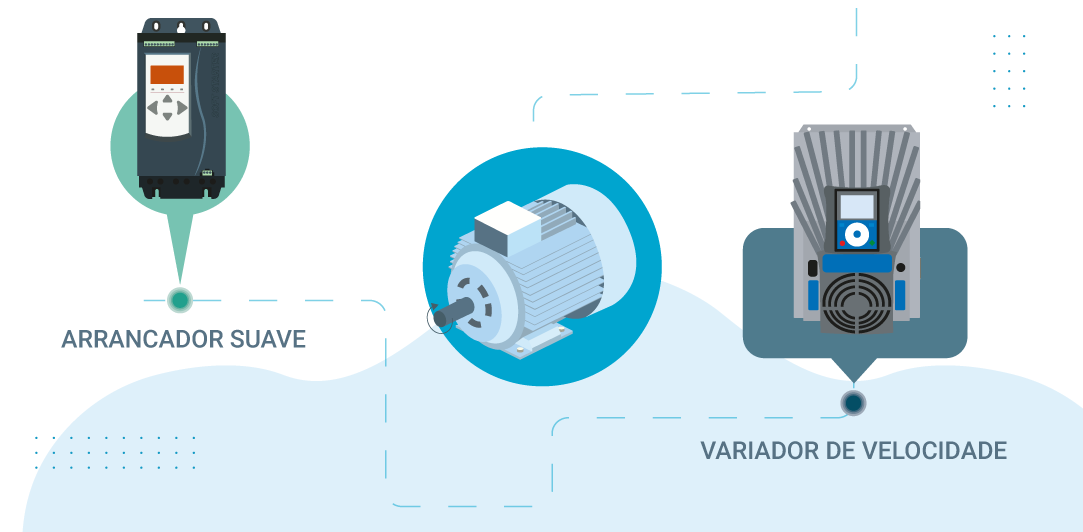
# 摘要
本论文全面探讨了PLC电动机启动策略的理论与实践,涵盖了从基本控制策略到高级控制策略的各个方面。重点分析了直接启动、星-三角启动、软启动、变频启动、动态制动和智能控制策略的理论基础与应用案例。通过对比不同启动策略的成本效益和环境适应性,本文探讨了策略选择时应考虑的因素,如负载特性、安全性和可靠性,并通过实证研究验证了启动策略对能效的
JBoss负载均衡与水平扩展:确保应用性能的秘诀

# 摘要
本文全面探讨了JBoss应用服务器的负载均衡和水平扩展技术及其高级应用。首先,介绍了负载均衡的基础理论和实践,包括其基本概念、算法与技术选择标准,以及在JBoss中的具体配置方法。接着,深入分析了水平扩展的原理、关键技术及其在容器化技术和混合云环境下的部署策略。随后,文章探讨了JBoss在负载均衡和水平扩展方面的高可用性、性能监控与调优、安全性与扩展性的考量。最后,通过行业案例分析,提供了实际应
【数据采集无压力】:组态王命令语言让实时数据处理更高效
# 摘要
本文全面探讨了组态王命令语言在数据采集中的应用及其理论基础。首先概述了组态王命令语言的基本概念,随后深入分析了数据采集的重要性,并探讨了组态王命令语言的工作机制与实时数据处理的关系。文章进一步细化到数据采集点的配置、数据流的监控技术以及数据处理策略,以实现高效的数据采集。在实践应用章节中,详细讨论了基于组态王命令语言的数据采集实现,以及在特定应用如能耗管理和设备监控中的应用实例。此外,本文还涉及性能优化和
【OMP算法:实战代码构建指南】:打造高效算法原型

# 摘要
正交匹配追踪(OMP)算法是一种高效的稀疏信号处理方法,在压缩感知和信号处理领域得到了广泛应用。本文首先对OMP算法进行概述,阐述其理论基础和数学原理。接着,深入探讨了OMP算法的实现逻辑、性能分析以及评价指标,重点关注其编码实践和性
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )