初识CUDA编程模型及其应用
发布时间: 2024-04-08 15:16:53 阅读量: 76 订阅数: 30 

CUDA编程模型(入门)
# 1. CUDA编程概述
CUDA是一种并行计算平台和编程模型,由NVIDIA推出,旨在利用GPU的并行计算能力加速应用程序的运行速度。本章将介绍CUDA编程的基本概念和优势,以及CUDA在各个领域中的广泛应用。
**1.1 什么是CUDA**
CUDA(Compute Unified Device Architecture)是NVIDIA推出的面向GPU的并行计算平台和编程模型。它允许开发者利用NVIDIA的GPU进行通用目的的并行计算,从而加速应用程序的运行速度。
**1.2 CUDA编程模型简介**
CUDA编程模型主要由主机(Host)和设备(Device)两部分组成。主机负责控制应用程序的整体流程,而设备则负责执行并行计算任务。开发者需要在主机端调用CUDA API,将计算任务传递给GPU设备执行。
**1.3 CUDA编程优势**
CUDA编程具有以下优势:
- 并行计算能力强:利用GPU的多核心结构并行计算,加速计算任务的执行速度。
- 灵活性高:支持动态分配内存、自定义核函数等特性,适用于各种计算密集型应用。
- 易于使用:CUDA提供丰富的API和工具,开发者可以相对容易地编写并行程序。
**1.4 CUDA编程应用领域**
CUDA广泛应用于以下领域:
- 科学计算:加速数值计算、模拟和仿真等科学计算任务。
- 深度学习:在深度学习框架中利用CUDA加速神经网络训练和推理。
- 图形图像处理:提高图像处理、计算机视觉等任务的处理速度。
- 金融领域:加速复杂的金融模型计算等。
通过对CUDA编程概述的了解,可以更好地理解CUDA的基本原理和应用范围,为后续深入学习和实践打下基础。
# 2. CUDA编程环境搭建
在进行CUDA编程之前,首先需要搭建合适的CUDA编程环境。本章将介绍如何配置CUDA开发环境,包括安装相应的CUDA开发工具、配置编程环境以及CUDA编译器及运行时库的介绍。
### 2.1 CUDA开发工具安装
要搭建CUDA编程环境,首先需要安装CUDA Toolkit。CUDA Toolkit是NVIDIA提供的用于CUDA开发的集成开发环境(IDE),包括编译器、库文件和调试器等工具,可以方便地进行CUDA程序的开发和调试。
在安装CUDA Toolkit之前,需要确认你的显卡型号是否支持CUDA。然后,可以到NVIDIA官网下载对应版本的CUDA Toolkit,并按照官方文档进行安装。
### 2.2 CUDA编程环境配置
安装完CUDA Toolkit后,接下来需要配置CUDA编程环境。主要包括设置环境变量、配置开发环境(如IDE、编辑器)、选择合适的GPU驱动等。
在Windows系统中,可以通过设置系统环境变量`PATH`来指定CUDA的安装路径;在Linux系统中,可以编辑`~/.bashrc`文件添加CUDA路径。此外,还可以根据具体的开发环境选择合适的插件或工具进行CUDA编程。
### 2.3 CUDA编译器及运行时库介绍
CUDA编程过程中会用到nvcc编译器,它可以将CUDA C/C++源代码编译成针对NVIDIA GPU的目标代码。另外,CUDA编程还会用到一些运行时库,如CUDA Runtime API和CUDA Driver API,用于管理GPU资源、数据传输和调用GPU核函数等操作。
通过合理使用CUDA编译器和运行时库,可以更高效地进行CUDA程序的开发和调试,提高程序的性能和并行计算能力。
# 3. CUDA核心概念深入解析
CUDA编程模型中的核心概念对于理解和使用CUDA进行并行计算至关重要。本章将深入解析CUDA的核心概念,包括线程、线程块与网格、共享内存与全局内存、核函数(Kernel)与调用、统一内存与数据传输等内容。
#### 3.1 线程、线程块与网格
在CUDA编程中,任务被划分为网格(Grid)和线程块(Block),每个线程块包含若干线程(Thread)。网格由多个线程块组成,形成了一种层次化的并行结构。每个线程块中的线程可以协同工作,并共享相同的共享内存和同步机制。
```python
import numpy as np
from numba import cuda
@cuda.jit
def kernel(array):
idx = cuda.threadIdx.x + cuda.blockIdx.x * cuda.blockDim.x
if idx < array.size:
array[idx] *= 2
def main():
data = np.array([1, 2, 3, 4, 5, 6, 7, 8])
threads_per_block = 4
blocks_per_grid = (data.size + (threads_per_block - 1)) // threads_per_block
kernel[blocks_per_grid, threads_per_block](data)
print("Result:", data)
if __name__ == '__main__':
main()
```
**注释:**
- 通过CUDA的`cuda.threadIdx`、`cuda.blockIdx`、`cuda.blockDim`等特殊变量来获取线程和线程块的索引等信息。
- 在`main`函数中进行CUDA核函数的调用,传入线程块和线程的数量。
- 最终打印出经过核函数运算后的结果。
**代码总结:**
通过CUDA的并行结构,可以实现对数据的并行处理,提高计算效率。
**结果说明:**
运行代码后,原始数组中的每个元素都被乘以2,得到了处理后的结果。
# 4. CUDA编程实践
在这一章中,我们将介绍一些CUDA编程的实践案例,帮助读者更好地理解如何利用CUDA进行程序开发与优化。我们将演示一些CUDA编程的范例,实现一个简单的矩阵乘法,并展示一个图像处理的实际应用例子。
### 4.1 CUDA编程范例演练
这里我们给出一个基本的向量加法的CUDA例子,展示了CUDA程序的基本结构和编写方式。
```python
import numpy as np
from numba import cuda
@cuda.jit
def vector_add(a, b, c):
idx = cuda.grid(1)
if idx < len(c):
c[idx] = a[idx] + b[idx]
def main():
N = 100
a = np.arange(N)
b = np.ones(N)
c = np.zeros_like(a)
threadsperblock = 256
blockspergrid = (N + threadsperblock - 1) // threadsperblock
vector_add[blockspergrid, threadsperblock](a, b, c)
print(c)
if __name__ == '__main__':
main()
```
**代码解释与总结**:
- 在这个例子中,我们定义了一个向量加法的CUDA核函数`vector_add`。
- 我们首先生成了两个向量`a`和`b`,并将它们传入CUDA核函数中进行加法操作。
- 使用`numba`库中的`cuda.jit`装饰器来声明CUDA核函数。`cuda.grid(1)`用于获取当前线程在网格中的index。
- 计算出每个线程块的数量和每个线程块中线程的数量,并进行调用。
- 最后打印出加法结果`c`。
### 4.2 矩阵乘法实现
下面我们展示一个矩阵乘法的CUDA实现,加深对CUDA程序设计的理解。
```python
import numpy as np
from numba import cuda
@cuda.jit
def matrix_multiply(A, B, C):
i, j = cuda.grid(2)
if i < C.shape[0] and j < C.shape[1]:
tmp = 0
for k in range(A.shape[1]):
tmp += A[i, k] * B[k, j]
C[i, j] = tmp
def main():
N = 3
A = np.random.random((N, N))
B = np.random.random((N, N))
C = np.zeros((N, N))
threadsperblock = (16, 16)
blockspergrid_x = (N + threadsperblock[0] - 1) // threadsperblock[0]
blockspergrid_y = (N + threadsperblock[1] - 1) // threadsperblock[1]
blockspergrid = (blockspergrid_x, blockspergrid_y)
matrix_multiply[blockspergrid, threadsperblock](A, B, C)
print(C)
if __name__ == '__main__':
main()
```
**代码解释与总结**:
- 在这个例子中,我们定义了一个矩阵乘法的CUDA核函数`matrix_multiply`。
- 首先生成两个随机矩阵`A`和`B`,并初始化结果矩阵`C`。
- 使用`numba`库中的`cuda.jit`装饰器来声明CUDA核函数。`cuda.grid(2)`用于获取当前线程在网格中的index。
- 通过循环计算矩阵乘法并将结果存入矩阵`C`中。
- 最后打印出矩阵乘法的结果。
通过这些实例,读者可以更好地理解CUDA编程的实践应用。接下来我们将介绍一个图像处理的实际应用例子。
# 5. CUDA性能优化技巧
在本章中,我们将深入探讨如何通过优化技巧来提升CUDA编程的性能,包括内存访问模式优化、并行计算优化、流处理器调度及资源管理以及代码优化技巧总结。让我们逐一进行探讨:
### 5.1 内存访问模式优化
在CUDA编程中,内存访问模式对性能影响巨大。通过合理设计内存访问模式,可以减少内存读写延迟,提高数据传输效率。一些优化技巧包括:利用共享内存进行数据复用、使用规则的内存访问模式以充分利用内存带宽等。
```python
# 代码示例: 共享内存数据复用优化
shared_mem = extern_shared([size], dtype=float32)
@cuda.jit
def shared_memory_kernel(data, result):
tx = cuda.threadIdx.x
ty = cuda.blockIdx.x
# 将数据加载到共享内存
shared_mem[tx] = data[tx, ty]
cuda.syncthreads()
# 进行数据处理
result[tx, ty] = shared_mem[tx] * 2
data = np.random.randn(4, 4)
data_global_mem = cuda.to_device(data)
result_global_mem = cuda.device_array_like(data)
# 配置网格与块大小
block_dim = 4
grid_dim = 1
shared_memory_kernel[grid_dim, block_dim](data_global_mem, result_global_mem)
```
通过合理利用共享内存,可以减少全局内存访问,提升性能。
### 5.2 并行计算优化
并行计算是CUDA的核心特性之一。在编写CUDA程序时,需要充分利用GPU的大规模并行计算能力,避免线程同步和数据依赖。一些优化技巧包括:减少线程同步次数、避免使用过多的条件判断等。
```python
# 代码示例: 并行计算优化
@cuda.jit
def parallel_computation_kernel(data, result):
tx = cuda.threadIdx.x
ty = cuda.blockIdx.x
# 并行计算
result[tx, ty] = data[tx, ty] * 2
data = np.random.randn(4, 4)
data_global_mem = cuda.to_device(data)
result_global_mem = cuda.device_array_like(data)
# 配置网格与块大小
block_dim = 4
grid_dim = 1
parallel_computation_kernel[grid_dim, block_dim](data_global_mem, result_global_mem)
```
充分利用GPU的并行计算能力可以加速程序执行。
### 5.3 流处理器调度及资源管理
CUDA程序在执行时需要经过流处理器调度和资源管理,合理利用流多处理器资源可以提高程序并行度和执行效率。一些优化技巧包括:合理配置线程块大小、减少资源竞争、避免资源浪费等。
```python
# 代码示例: 流处理器资源管理优化
@cuda.jit
def resource_management_kernel(data, result):
tx = cuda.threadIdx.x
ty = cuda.blockIdx.x
# 计算流处理器资源管理示例
result[tx, ty] = data[tx, ty] + 1
data = np.random.randn(4, 4)
data_global_mem = cuda.to_device(data)
result_global_mem = cuda.device_array_like(data)
# 配置网格与块大小
block_dim = 4
grid_dim = 1
resource_management_kernel[grid_dim, block_dim](data_global_mem, result_global_mem)
```
合理管理流处理器资源可以提高程序的并行度和执行效率。
### 5.4 代码优化技巧总结
在CUDA编程中,代码优化是提升性能的关键。一些常见的代码优化技巧包括:减少全局内存访问、减少内存拷贝次数、合理使用内存层次结构等。通过细致优化代码,可以显著提升CUDA程序的性能。
本章介绍了CUDA性能优化技巧,包括内存访问模式优化、并行计算优化、流处理器调度及资源管理以及代码优化技巧总结。这些技巧对于提升CUDA程序性能具有重要意义,希望可以帮助读者更好地进行CUDA编程实践。
# 6. CUDA在深度学习与科学计算中的应用
在本章中,将详细介绍CUDA在深度学习与科学计算领域的应用及相关案例。通过CUDA技术,深度学习框架能够充分利用GPU并行计算能力,加速神经网络训练与推理过程。同时,科学计算领域也受益于CUDA高性能计算能力,加快了计算模拟、数据处理等工作的速度。
#### 6.1 CUDA与深度学习框架集成
CUDA在深度学习领域扮演着至关重要的角色,主流深度学习框架如TensorFlow、PyTorch、MXNet等均提供了与CUDA的紧密集成,通过CUDA加速计算,实现了神经网络模型的快速训练和推理。开发者可以利用CUDA在GPU上进行并行计算,大幅提升训练速度,缩短模型优化周期。
以TensorFlow为例,其通过CUDA与cuDNN(CUDA深度神经网络库)实现了对GPU的加速支持,用户可以配置TensorFlow在GPU上运行,充分利用CUDA提供的计算性能,加快模型训练速度。通过CUDA与深度学习框架的结合,实现了深度学习算法在大规模数据集上的高效训练,推动了人工智能领域的发展。
#### 6.2 CUDA在科学计算领域的应用案例
除了深度学习领域,CUDA在科学计算中也有广泛的应用。许多科学计算领域,如气候模拟、物理模拟、生物信息学等,都需要大规模数据处理和复杂计算。CUDA提供了高性能、并行计算的能力,能够加速这些领域的计算过程,提高计算效率。
一个典型的应用案例是在天体物理学中的宇宙模拟。通过CUDA在GPU上实现的高性能计算,科学家们可以模拟天体的运动、宇宙结构的演化等复杂过程,为研究宇宙提供了强大的工具和支持。CUDA在科学计算中的广泛应用,推动了各领域研究的进步和创新。
#### 6.3 CUDA技术发展与未来趋势展望
随着GPU计算能力的不断提升和CUDA技术的持续优化,CUDA在深度学习与科学计算领域的应用前景十分广阔。未来,CUDA将继续发挥重要作用,推动人工智能、科学研究等领域的发展。随着对计算效率和性能要求的不断提高,CUDA技术将不断演进,为更多领域提供高效的并行计算解决方案。
通过对CUDA与深度学习、科学计算领域的应用案例的解析,我们可以看到CUDA在高性能计算领域的重要性和广泛应用前景。深入理解CUDA技术,将有助于开发者更好地利用GPU计算能力,实现更高效的计算和应用。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 CUDA(Compute Unified Device Architecture)编程模型,重点关注其在并行计算中的应用。专栏涵盖了 CUDA 的核心概念,包括线程、块和网格,以及内存管理技巧。它深入探讨了 CUDA 并行计算的各个方面,包括异步操作、流处理、共享内存优化、纹理内存和常量内存应用。专栏还探讨了 CUDA 中的原子操作、数据传输和通信技术,以及动态并行和任务编排。此外,它还介绍了 CUDA 异构计算、分布式并行计算、优化技巧、深度学习模型部署和加速技术、图像处理和计算机视觉应用,以及在大规模数据分析中的应用。本专栏提供了全面的 CUDA 编程知识,并为开发高效的并行计算应用程序提供了宝贵的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
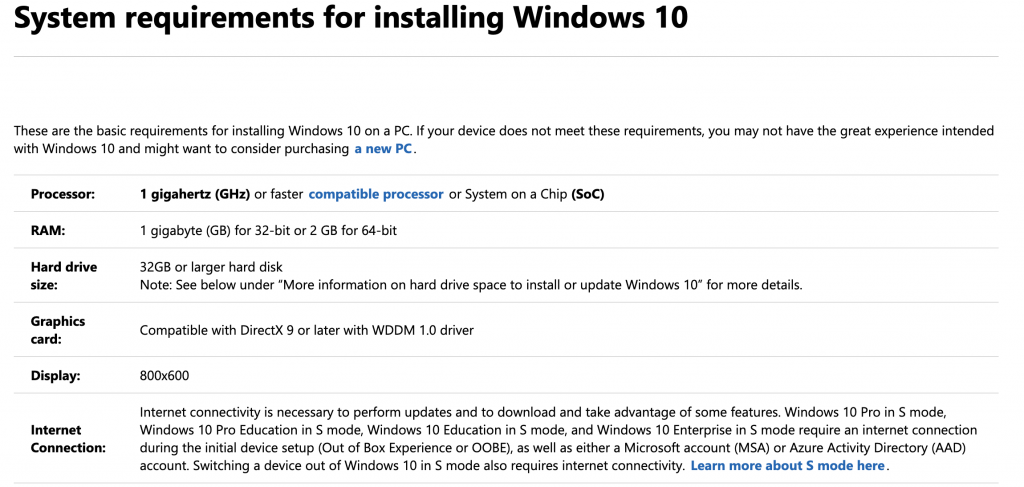
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
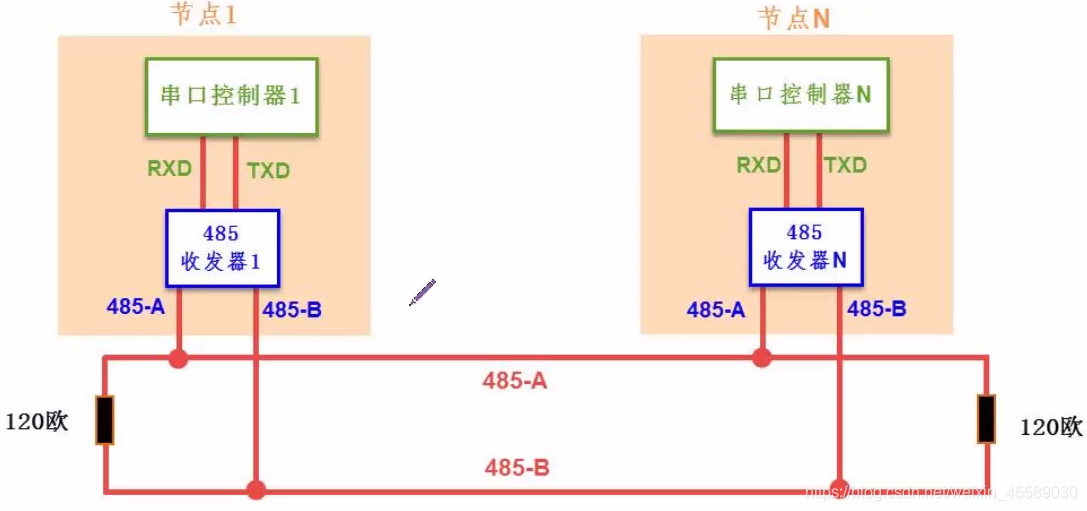
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
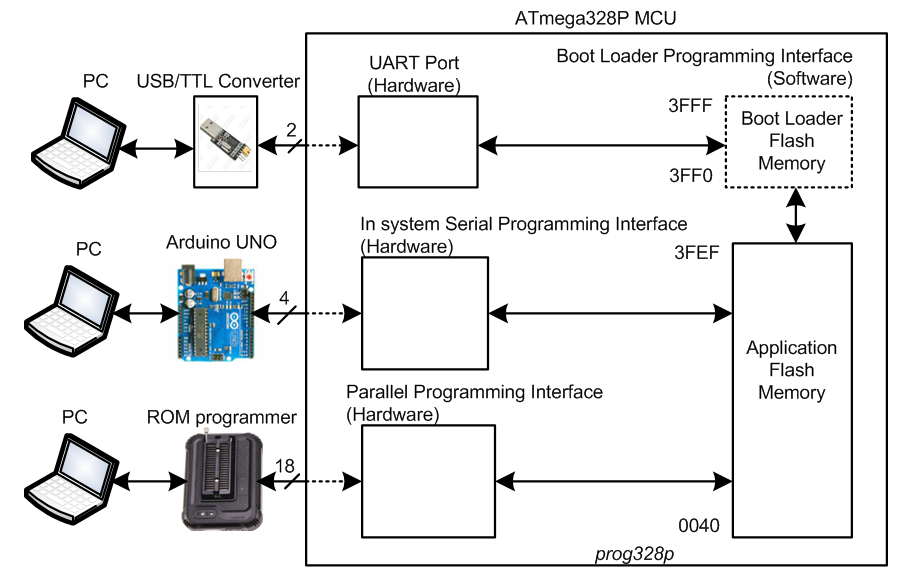
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )