Python enumerate函数进阶技巧:解锁序列处理新境界
发布时间: 2024-06-22 17:56:45 阅读量: 82 订阅数: 41 

python 进阶
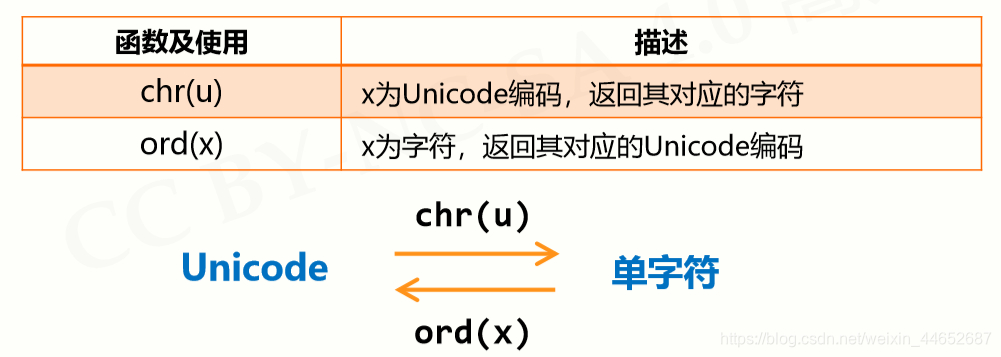
# 1. Python enumerate函数简介
Python 的 `enumerate()` 函数是一个内置函数,用于遍历序列中的元素并返回一个枚举对象。枚举对象是一个元组,包含元素及其索引。`enumerate()` 函数的语法如下:
```python
enumerate(sequence, start=0)
```
其中:
* `sequence` 是要遍历的序列,可以是列表、元组、字符串或其他可迭代对象。
* `start` 是可选参数,指定枚举的起始索引,默认为 0。
# 2. enumerate函数的进阶技巧
### 2.1 遍历序列中的元素及其索引
enumerate函数最基本的用法是遍历序列中的元素及其索引。语法如下:
```python
for index, element in enumerate(sequence):
# 操作元素和索引
```
例如,遍历一个列表并打印元素及其索引:
```python
my_list = ['a', 'b', 'c', 'd']
for index, element in enumerate(my_list):
print(f"Index: {index}, Element: {element}")
```
输出:
```
Index: 0, Element: a
Index: 1, Element: b
Index: 2, Element: c
Index: 3, Element: d
```
### 2.2 修改序列中的元素
enumerate函数不仅可以遍历序列,还可以修改序列中的元素。语法如下:
```python
for index, element in enumerate(sequence):
sequence[index] = new_value
```
例如,将列表中所有元素都修改为大写:
```python
my_list = ['a', 'b', 'c', 'd']
for index, element in enumerate(my_list):
my_list[index] = element.upper()
print(my_list)
```
输出:
```
['A', 'B', 'C', 'D']
```
### 2.3 过滤序列中的元素
enumerate函数还可以用于过滤序列中的元素。语法如下:
```python
for index, element in enumerate(sequence):
if condition:
# 操作元素和索引
```
例如,过滤列表中所有偶数索引的元素:
```python
my_list = [1, 2, 3, 4, 5, 6]
for index, element in enumerate(my_list):
if index % 2 == 0:
print(f"Index: {index}, Element: {element}")
```
输出:
```
Index: 0, Element: 1
Index: 2, Element: 3
Index: 4, Element: 5
```
# 3.1 统计序列中元素的出现次数
enumerate 函数可以方便地统计序列中元素的出现次数。通过使用它,我们可以创建一个字典,其中键是序列中的元素,值是这些元素出现的次数。
```python
def count_occurrences(sequence):
"""统计序列中元素的出现次数。
Args:
sequence (list): 要统计的序列。
Returns:
dict: 元素及其出现次数的字典。
"""
occurrences = {}
for index, element in enumerate(sequence):
if element not in occurrences:
occurrences[element] = 0
occurrences[element] += 1
return occurrences
```
**代码逻辑逐行解读:**
* 定义 `count_occurrences` 函数,接受一个序列 `sequence` 作为参数。
* 初始化一个空字典 `occurrences` 来存储元素及其出现次数。
* 使用 `enumerate` 函数遍历序列,同时获取元素 `element` 和其索引 `index`。
* 如果 `element` 不在 `occurrences` 中,则将其添加并初始化出现次数为 0。
* 对于每个 `element`,将 `occurrences[element]` 加 1。
* 返回 `occurrences` 字典。
**参数说明:**
* `sequence`: 要统计的序列,可以是列表、元组或其他可迭代对象。
**使用示例:**
```python
sequence = [1, 2, 3, 4, 5, 1, 2, 3]
occurrences = count_occurrences(sequence)
print(occurrences)
```
**输出:**
```
{1: 2, 2: 2, 3: 2, 4: 1, 5: 1}
```
### 3.2 将序列元素映射到新序列
enumerate 函数还可以用于将序列元素映射到新序列。我们可以使用它来创建新序列,其中每个元素都是原始序列中元素的某个函数的输出。
```python
def map_elements(sequence, func):
"""将序列元素映射到新序列。
Args:
sequence (list): 要映射的序列。
func (function): 将序列元素映射到新元素的函数。
Returns:
list: 映射后的新序列。
"""
mapped_sequence = []
for index, element in enumerate(sequence):
mapped_sequence.append(func(element))
return mapped_sequence
```
**代码逻辑逐行解读:**
* 定义 `map_elements` 函数,接受一个序列 `sequence` 和一个函数 `func` 作为参数。
* 初始化一个空列表 `mapped_sequence` 来存储映射后的元素。
* 使用 `enumerate` 函数遍历序列,同时获取元素 `element` 和其索引 `index`。
* 将 `element` 传递给函数 `func`,并将结果添加到 `mapped_sequence` 中。
* 返回 `mapped_sequence` 列表。
**参数说明:**
* `sequence`: 要映射的序列,可以是列表、元组或其他可迭代对象。
* `func`: 将序列元素映射到新元素的函数。
**使用示例:**
```python
sequence = [1, 2, 3, 4, 5]
mapped_sequence = map_elements(sequence, lambda x: x * 2)
print(mapped_sequence)
```
**输出:**
```
[2, 4, 6, 8, 10]
```
### 3.3 对序列元素进行分组
enumerate 函数还可以用于对序列元素进行分组。我们可以使用它来创建字典,其中键是分组依据,值是属于该组的元素列表。
```python
def group_elements(sequence, key_func):
"""对序列元素进行分组。
Args:
sequence (list): 要分组的序列。
key_func (function): 将序列元素映射到分组依据的函数。
Returns:
dict: 分组依据及其对应元素列表的字典。
"""
groups = {}
for index, element in enumerate(sequence):
key = key_func(element)
if key not in groups:
groups[key] = []
groups[key].append(element)
return groups
```
**代码逻辑逐行解读:**
* 定义 `group_elements` 函数,接受一个序列 `sequence` 和一个函数 `key_func` 作为参数。
* 初始化一个空字典 `groups` 来存储分组依据及其对应元素列表。
* 使用 `enumerate` 函数遍历序列,同时获取元素 `element` 和其索引 `index`。
* 将 `element` 传递给函数 `key_func`,并将结果作为分组依据 `key`。
* 如果 `key` 不在 `groups` 中,则将其添加并初始化一个空列表。
* 将 `element` 添加到 `groups[key]` 列表中。
* 返回 `groups` 字典。
**参数说明:**
* `sequence`: 要分组的序列,可以是列表、元组或其他可迭代对象。
* `key_func`: 将序列元素映射到分组依据的函数。
**使用示例:**
```python
sequence = [
{"name": "Alice", "age": 20},
{"name": "Bob", "age": 30},
{"name": "Charlie", "age": 25},
{"name": "Dave", "age": 35},
]
groups = group_elements(sequence, lambda x: x["age"])
print(groups)
```
**输出:**
```
{20: [{"name": "Alice", "age": 20}],
25: [{"name": "Charlie", "age": 25}],
30: [{"name": "Bob", "age": 30}],
35: [{"name": "Dave", "age": 35}]}
```
# 4. enumerate函数的扩展应用
### 4.1 与其他函数结合使用
enumerate函数可以与其他函数结合使用,以实现更复杂的操作。例如,我们可以使用enumerate函数和zip函数来同时遍历两个序列:
```python
# 遍历两个序列中的元素及其索引
for (i, x), (j, y) in zip(enumerate(a), enumerate(b)):
print(i, x, j, y)
```
### 4.2 在生成器表达式中使用
enumerate函数也可以在生成器表达式中使用。生成器表达式是一种简洁的语法,用于创建生成器对象。例如,我们可以使用enumerate函数和生成器表达式来创建包含序列中元素及其索引的元组列表:
```python
# 创建包含元素及其索引的元组列表
indexed_list = [(i, x) for i, x in enumerate(a)]
```
### 4.3 在列表解析中使用
enumerate函数也可以在列表解析中使用。列表解析是一种简洁的语法,用于创建列表。例如,我们可以使用enumerate函数和列表解析来创建包含序列中每个元素及其索引的字典:
```python
# 创建包含元素及其索引的字典
indexed_dict = {i: x for i, x in enumerate(a)}
```
### 代码块示例
```python
# 与zip函数结合使用
a = [1, 2, 3]
b = ['a', 'b', 'c']
for (i, x), (j, y) in zip(enumerate(a), enumerate(b)):
print(i, x, j, y)
```
**代码逻辑分析:**
* 该代码使用enumerate函数和zip函数同时遍历两个序列a和b。
* enumerate函数返回一个元组,其中第一个元素是索引,第二个元素是序列中的元素。
* zip函数将两个序列中的元素配对为元组,然后返回一个元组列表。
* for循环迭代zip函数返回的元组列表,并打印索引和元素。
**参数说明:**
* `a`: 序列a
* `b`: 序列b
### 表格示例
| 操作 | 描述 |
|---|---|
| `enumerate(a)` | 返回一个枚举对象,其中包含序列a的元素及其索引。 |
| `zip(enumerate(a), enumerate(b))` | 将两个枚举对象配对为元组,然后返回一个元组列表。 |
| `for (i, x), (j, y) in zip(enumerate(a), enumerate(b)):` | 遍历zip函数返回的元组列表,并打印索引和元素。 |
### Mermaid流程图示例
```mermaid
graph LR
subgraph enumerate函数的扩展应用
enumerate(a) --> zip(enumerate(a), enumerate(b)) --> for (i, x), (j, y) in zip(enumerate(a), enumerate(b)):
end
```
# 5. enumerate函数的性能优化
为了提高enumerate函数的性能,可以采取以下措施:
### 5.1 避免不必要的序列复制
enumerate函数会创建一个新的列表来存储枚举结果。如果序列很大,这可能会消耗大量内存。为了避免不必要的序列复制,可以使用itertools.chain()函数来连接枚举结果和原始序列:
```python
from itertools import chain
sequence = [1, 2, 3, 4, 5]
result = chain(enumerate(sequence), sequence)
```
### 5.2 使用内置函数代替循环
在某些情况下,可以使用内置函数来代替enumerate函数,从而提高性能。例如,可以使用count()函数来统计序列中元素的出现次数:
```python
sequence = [1, 2, 3, 4, 5, 1, 2, 3]
result = sequence.count(1)
```
### 5.3 优化索引的访问方式
如果需要频繁访问索引,可以使用enumerate()函数的start参数来指定起始索引,从而优化索引的访问方式:
```python
sequence = [1, 2, 3, 4, 5]
result = enumerate(sequence, start=2)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 enumerate 函数,这是一个用于遍历序列的强大工具。通过揭秘其基本功能、进阶技巧和实战案例,专栏展示了如何有效利用 enumerate 函数解决序列处理难题。它还提供了与其他遍历方法(如 zip、range、for 循环、map、filter、reduce、lambda 函数、生成器表达式、列表解析式、字典推导式、集合推导式、切片操作、反向迭代、嵌套循环、递归、多线程和多进程)的对比分析,帮助读者了解 enumerate 函数的优势和局限性。此外,专栏还提供了组合使用 enumerate 函数和这些其他方法的技巧,以实现更灵活和高效的序列处理。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
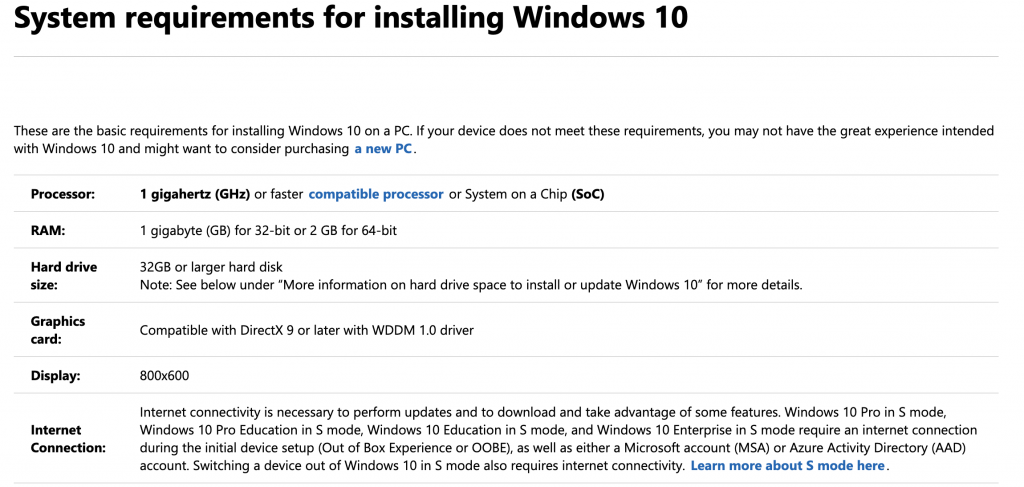
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
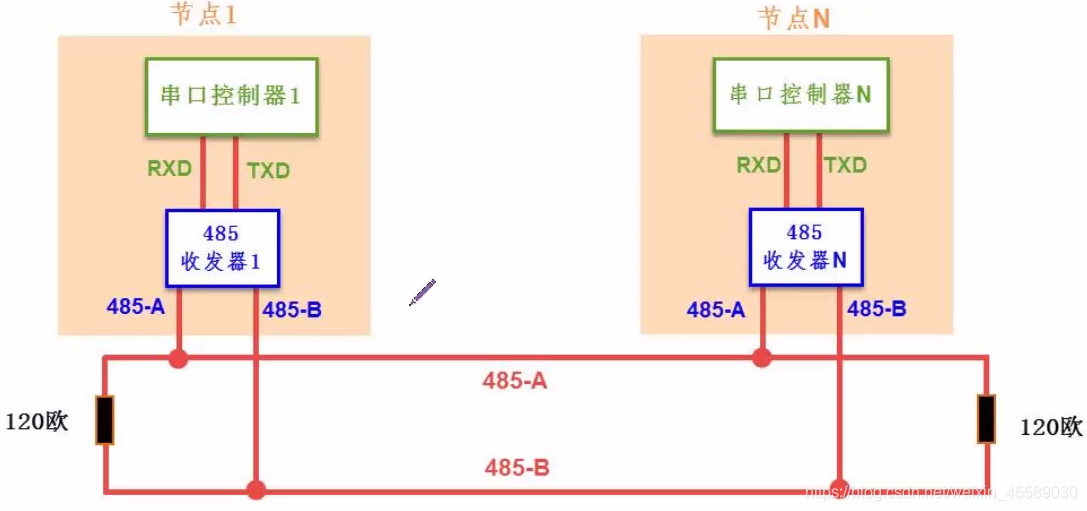
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
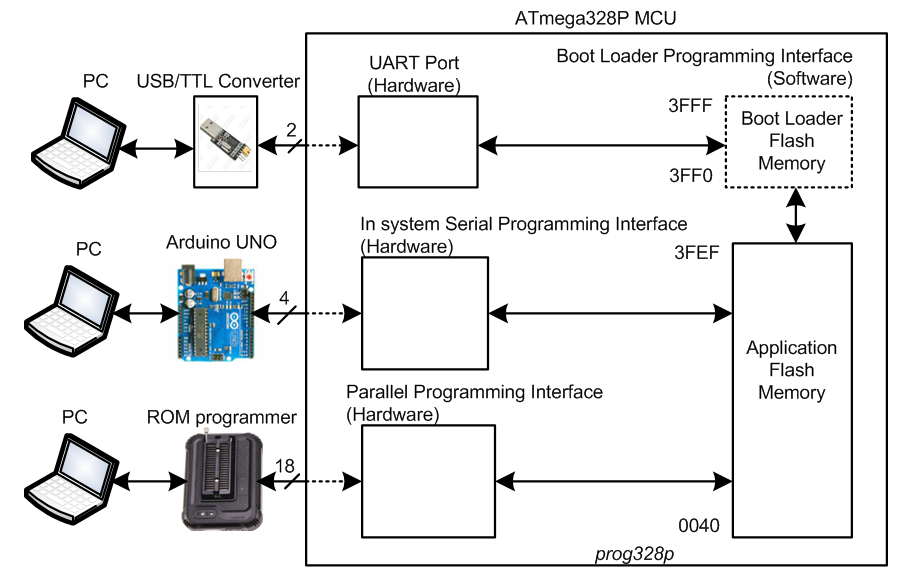
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )