使用Java反射解析XML配置文件
发布时间: 2023-12-20 12:26:43 阅读量: 60 订阅数: 44 
# 1. 理解Java反射
## 1.1 反射概述
在Java编程中,反射是指在程序运行时检查、获取和修改类的方法、字段、构造函数等信息的机制。通过反射,我们可以在运行时动态地操作类,实现诸如动态加载类、创建对象、调用方法、访问属性等功能,而无需在编译期就确定这些操作的类名、方法名和属性名。
反射的核心是`java.lang.reflect`包,该包提供了用于在运行时检查和操作类的工具。通过`Class`类、`Field`类、`Method`类以及`Constructor`类等,我们可以实现对类的各种操作。
## 1.2 反射的作用和优缺点
### 作用
- 实现与类相关的动态操作,如动态加载类、创建对象实例、调用方法、访问属性等。
- 支持框架和工具的扩展和自定义化,使得代码更加灵活和可配置。
- 实现通用性高的代码,减少重复代码的编写。
### 优点
- 实现代码的灵活性和可配置性。
- 使得代码更具有通用性和复用性。
### 缺点
- 性能相对较低,反射操作的效率低于直接调用类的方法和访问属性。
- 反射的使用需要谨慎,因为它可以突破封装性,导致安全问题和代码可读性降低。
## 1.3 反射在Java中的应用
反射机制在Java中有着广泛的应用,比如Spring框架中的依赖注入、AOP(面向切面编程)、JUnit测试框架、动态代理等均用到了反射机制。此外,在配置文件处理、解析JSON和XML等场景中,反射同样扮演着重要的角色。
通过反射,我们可以实现与类相关的动态操作,为代码的灵活性和可扩展性提供了有力的支持。
在接下来的章节中,我们将深入探讨如何结合XML配置文件以及反射来实现更灵活的应用程序配置和动态加载的功能。
# 2. XML配置文件介绍
在本章中,我们将介绍XML配置文件的基础知识,以及在Java中如何应用XML作为配置文件的方法。我们还将讨论XML配置文件的特点和用途。
### 2.1 XML基础知识
XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。与HTML类似,XML也使用标签来定义数据的结构和属性。但是,与HTML不同的是,XML具有更广泛的灵活性和扩展性,可以根据需求定义自定义的标签和结构。
XML的基本语法规则如下:
- 所有XML标签必须有一个开始标签和一个结束标签,并且标签是成对出现的。
- 开始标签和结束标签之间可以包含文本内容,也可以包含其他标签。
- XML标签可以具有属性,属性在开始标签中定义,并用键值对的形式表示。
下面是一个简单的XML示例:
```xml
<person>
<name>John Doe</name>
<age>30</age>
</person>
```
在上面的示例中,我们定义了一个`person`标签,它包含了一个`name`标签和一个`age`标签。`name`标签的内容是"John Doe",`age`标签的内容是"30"。
### 2.2 XML在配置中的应用
XML在配置中的应用广泛而灵活。它可以用于配置各种类型的应用程序,以定义应用程序的行为和属性。
使用XML作为配置文件的好处包括:
- 配置文件易于理解和修改:XML的结构使得配置文件的内容和属性清晰可见,易于理解和修改。
- 配置文件的扩展性:XML的灵活性使得配置文件可以轻松地扩展和添加新的配置项。
- 跨平台兼容性:XML是一种跨平台的数据格式,可以在不同的操作系统和应用程序之间进行数据交换和共享。
### 2.3 XML配置文件的特点和用途
XML配置文件具有以下特点和用途:
- 结构化:XML配置文件使用标签和属性来定义结构化数据,使得配置文件的内容更加有组织和易于理解。
- 可读性高:由于可扩展和人类可读的特性,XML配置文件在配置中非常常见。开发人员和系统管理员可以轻松地阅读和编写XML配置文件。
- 通用性:XML配置文件可以被广泛地应用在各种应用程序和领域中,如Web应用程序、桌面应用程序、服务器配置等。
在下一章节中,我们将介绍如何解析XML文件,以及使用Java反射与XML配置文件的结合。
# 3. 解析XML文件
XML文件是一种常见的数据交换格式,在Java开发中经常会用到XML文件的解析。本章将介绍使用Java中的DOM、SAX和JAXB解析XML文件的方法。
#### 3.1 使用DOM解析XML
DOM(Document Object Model)是一种基于树形结构的XML文件解析方式,它将XML文件解析为一个树形的结构,在内存中形成对应的Document对象,便于对XML中的元素进行操作。
```java
// 示例代码:使用DOM解析XML
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.DocumentBuilder;
import org.w3c.dom.Document;
import org.w3c.dom.NodeList;
import org.w3c.dom.Node;
import org.w3c.dom.Element;
import java.io.File;
public class DomXmlParser {
public static void main(String[] args) {
try {
File inputFile = new File("input.xml");
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder dBuilder = dbFactory.newDocumentBuilder();
Document doc = dBuilder.parse(inputFile);
doc.getDocumentElement().normalize();
System.out.println("Root element :" + doc.getDocumentElement().getNodeName());
NodeList nList = doc.getElementsByTagName("student");
System.out.println("----------------------------");
for (int temp = 0; temp < nList.getLength(); temp++) {
Node nNode = nList.item(temp);
System.out.println("\nCurrent Element :" + nNode.getNodeName());
if (nNode.getNodeType() == Node.ELEMENT_NODE) {
Element eElement = (Element) nNode;
System.out.println("Student roll no : " + eElement.getAttribute("rollno"));
System.out.println("First Name : " + eElement.getElementsByTagName("firstname").item(0).getTextContent());
System.out.println("Last Name : " + eElement.getElementsByTagName("lastname").item(0).getTextContent());
System.out.println("Nick Name : " + eElement.getElementsByTagName("nickname").item(0).getTextContent());
System.out.println("Marks : " + eElement.getElementsByTagName("marks").item(0).getTextContent());
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
**代码总结**:以上是一个使用DOM解析XML文件的示例,通过DocumentBuilder对XML文件进行解析并操作其节点元素,最终将XML中的数据展示出来。
**结果说明**:运行该代码后,将会输出XML文件中的学生信息,包括学生姓名、学号、成绩等。
#### 3.2 使用SAX解析XML
SAX(Simple API for XML)是一种基于事件驱动的XML解析方式,它将XML文件按照从头到尾的顺序解析,并触发相应的事件来处理XML中的数据。
```java
// 示例代码:使用SAX解析XML
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
public class SaxXmlParser {
public static void main(String[] args) {
try {
XMLReader xmlReader = XMLReaderFactory.createXMLReader();
xmlReader.setContentHandler(new DefaultHandler() {
boolean bFirstName = false;
boolean bLastName = false;
boolean bNickName = false;
boolean bMarks = false;
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (qName.equalsIgnoreCase("firstname")) {
bFirstName = true;
}
if (qName.equalsIgnoreCase("lastname")) {
bLastName = true;
}
if (qName.equalsIgnoreCase("nickname")) {
bNickName = true;
}
if (qName.equalsIgnoreCase("marks")) {
bMarks = true;
}
}
public void characters(char ch[], int start, int length) throws SAXException {
if (bFirstName) {
System.out.println("First Name: " + new String(ch, start, length));
bFirstName = false;
}
if (bLastName) {
System.out.println("Last Name: " + new String(ch, start, length));
bLastName = false;
}
if (bNickName) {
System.out.println("Nick Name: " + new String(ch, start, length));
bNickName = false;
}
if (bMarks) {
System.out.println("Marks: " + new String(ch, start, length));
bMarks = false;
}
}
});
xmlReader.parse("input.xml");
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
**代码总结**:以上是一个使用SAX解析XML文件的示例,通过实现DefaultHandler接口的方式来处理XML文件中的事件,并逐行解析XML中的数据。
**结果说明**:运行该代码后,将会按行输出XML文件中的学生信息,包括学生姓名、成绩等。
#### 3.3 使用JAXB解析XML
JAXB(Java Architecture for XML Binding)是一种将Java对象与XML数据进行映射的方式,它提供了一种简单的方式来将Java类映射为XML文件,以及从XML文件映射为Java对象。
```java
// 示例代码:使用JAXB解析XML
import javax.xml.bind.JAXBContext;
import javax.xml.bind.Unmarshaller;
import java.io.File;
public class JaxbXmlParser {
public static void main(String[] args) {
try {
File file = new File("input.xml");
JAXBContext jaxbContext = JAXBContext.newInstance(Student.class);
Unmarshaller jaxbUnmarshaller = jaxbContext.createUnmarshaller();
Student student = (Student) jaxbUnmarshaller.unmarshal(file);
System.out.println("First Name: " + student.getFirstname());
System.out.println("Last Name: " + student.getLastname());
System.out.println("Nick Name: " + student.getNickname());
System.out.println("Marks: " + student.getMarks());
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
**代码总结**:以上是一个使用JAXB解析XML文件的示例,通过JAXBContext和Unmarshaller将XML文件映射为Java对象,并展示出XML中的数据。
**结果说明**:运行该代码后,将会输出XML文件中的学生信息,包括学生姓名、成绩等。
希望以上内容能帮助您更好地理解XML文件的解析方法。
# 4. Java反射与XML配置文件结合
在前面的章节中,我们分别介绍了Java反射和XML配置文件的基础知识以及应用。本章将探讨如何将Java反射与XML配置文件结合起来使用。
#### 4.1 通过反射读取XML配置文件
在许多应用中,配置文件是必不可少的一部分。通过使用XML配置文件,我们可以灵活地配置应用的各种参数和选项。而Java反射可以帮助我们动态地读取XML配置文件中的内容,并将其映射为Java对象。
在读取XML配置文件之前,我们首先需要解析它,将其转换为内存中的数据结构。之后,我们可以利用反射机制来读取和使用这些数据。
#### 4.2 将XML配置文件映射为Java对象
通过使用Java反射,我们可以将XML配置文件中的内容映射为Java对象。这意味着我们可以利用反射来创建、操作和访问这些对象。
在将XML配置文件映射为Java对象之前,我们需要定义一个与配置文件结构相匹配的Java类。这个Java类中的每个字段都应该与配置文件中的一个属性相对应。通过反射,我们可以在运行时动态地创建这个Java类的实例,并将配置文件中的值赋给对象的相应属性。
#### 4.3 演示如何使用Java反射解析XML配置文件
现在让我们通过一个示例来演示如何使用Java反射来解析XML配置文件。
```java
// 使用Java反射解析XML配置文件的示例代码
public class XMLConfigParser {
public static void parseConfig(String configFileName) {
// 解析XML配置文件并获取配置项
// ...
// 使用反射创建对象并设置属性值
// ...
}
public static void main(String[] args) {
String configFileName = "config.xml";
parseConfig(configFileName);
}
}
```
在上面的示例代码中,我们创建了一个`XMLConfigParser`类,并在`parseConfig`方法中解析了名为`config.xml`的XML配置文件。我们使用Java反射来创建对象并设置属性值,以便于后续的操作和访问。
通过使用Java反射解析XML配置文件,我们可以通过修改配置文件来改变应用的行为,而无需重新编译和部署应用。这样大大提高了应用的灵活性和可维护性。
### 结论
本章介绍了如何将Java反射与XML配置文件结合起来使用。我们学习了如何通过反射读取XML配置文件和将XML配置文件映射为Java对象。通过使用Java反射解析XML配置文件,我们可以灵活地配置应用的各种参数和选项,从而提高应用的灵活性和可维护性。
在接下来的章节中,我们将继续讨论如何利用反射和配置文件动态加载应用,并探索一些最佳实践和注意事项。
# 5. 反射与配置文件动态加载
在本章节中,我们将深入探讨反射与配置文件动态加载的结合应用。通过反射机制,我们可以实现配置文件的动态加载,并且灵活调整配置文件参数,从而提高程序的灵活性和可维护性。
### 5.1 实现配置文件的动态加载
在实际项目中,我们经常会遇到需要动态加载配置文件的场景,比如在服务启动时根据配置文件的不同选择加载不同的实现类。通过反射,我们可以实现配置文件的动态加载,只需修改配置文件而不需要修改代码,大大提高了代码的灵活性。
```java
// 以Java为例,演示如何动态加载配置文件
Properties properties = new Properties();
try (InputStream inputStream = new FileInputStream("config.properties")) {
properties.load(inputStream);
String className = properties.getProperty("handler.class");
Class<?> handlerClass = Class.forName(className);
Handler handler = (Handler) handlerClass.newInstance();
// 使用动态加载的handler处理业务逻辑
} catch (IOException | ClassNotFoundException | InstantiationException | IllegalAccessException e) {
e.printStackTrace();
}
```
### 5.2 使用反射实现配置文件参数的灵活调整
除了动态加载配置文件外,反射还可以帮助我们实现配置文件参数的灵活调整。在配置文件中指定类名或方法名,通过反射动态调用对应的类或方法,从而达到通过修改配置文件而不需要修改代码的效果。
```java
// 以Java为例,演示如何通过反射灵活调整配置文件参数
Properties properties = new Properties();
try (InputStream inputStream = new FileInputStream("config.properties")) {
properties.load(inputStream);
String methodName = properties.getProperty("handler.method");
String className = properties.getProperty("handler.class");
Class<?> handlerClass = Class.forName(className);
Handler handler = (Handler) handlerClass.newInstance();
Method method = handlerClass.getMethod(methodName);
method.invoke(handler);
} catch (IOException | ClassNotFoundException | NoSuchMethodException | InstantiationException | IllegalAccessException | InvocationTargetException e) {
e.printStackTrace();
}
```
### 5.3 优化配置文件的动态加载方案
当涉及大规模的配置文件动态加载时,为了提高性能和便捷性,我们可以结合缓存、定时任务等技术,对动态加载方案进行优化,从而在保证灵活性的同时提升系统性能和稳定性。
在实际应用中,我们还需结合具体项目需求和环境特点,综合考虑各种因素,选择合适的配置文件动态加载方案,并进行相应的性能优化。
通过本章节的学习,我们可以更加深入地理解反射与配置文件动态加载的应用,为项目开发提供更多灵活的选择和更高的效率。
希望这一章内容能够对您有所帮助!
# 6. 最佳实践与注意事项
在使用Java反射与XML配置文件结合的过程中,我们需要注意一些最佳实践和注意事项,以确保代码的可靠性和性能。本章将介绍一些最佳实践示例,常见问题的解决方案,以及如何避免反射带来的性能问题。
#### 6.1 最佳实践示例
**示例一:合理使用缓存**
在使用反射解析XML配置文件时,可以考虑对解析结果进行缓存,避免频繁地进行反射操作。通过合理使用缓存,可以提高系统性能并减少资源开销。
```java
public class ConfigParser {
private Map<String, Object> cache = new HashMap<>();
public Object parseConfig(String configName) {
if (cache.containsKey(configName)) {
return cache.get(configName);
} else {
Object config = // 使用反射解析XML配置文件的代码
cache.put(configName, config);
return config;
}
}
}
```
**示例二:异常处理与日志记录**
在使用反射操作时,往往会涉及到类不存在、方法不存在等异常情况。因此,我们需要合理处理这些异常,并记录相应的日志,以便追踪问题。
```java
public class ReflectionUtil {
public static Object createInstance(String className) {
try {
Class<?> clazz = Class.forName(className);
return clazz.newInstance();
} catch (ClassNotFoundException | IllegalAccessException | InstantiationException e) {
// 异常处理与日志记录
e.printStackTrace();
}
return null;
}
}
```
#### 6.2 反射与XML配置文件的常见问题与解决方案
**问题:性能问题**
使用反射操作会带来一定的性能开销,特别是在大规模的系统中,频繁的反射操作可能导致性能问题。
**解决方案:**
- 合理使用缓存,避免重复的反射操作
- 考虑使用更高效的替代方案,如字节码操作等
**问题:安全问题**
反射操作能够访问私有属性和方法,可能存在安全隐患。
**解决方案:**
- 限制反射操作的范围,合理控制权限
- 对于关键操作,考虑采用其他方式实现,避免使用反射操作
#### 6.3 如何避免反射带来的性能问题
在使用反射时,为了避免性能问题,可以考虑以下几点:
- 合理使用缓存,避免重复的反射操作
- 考虑使用更高效的替代方案,如字节码操作等
- 针对关键代码进行性能优化,避免过多的反射操作
在实际应用中,需要根据具体场景和需求来综合考虑,灵活选择合适的方案来避免性能问题。
希望本章内容能帮助您更好地理解和应用Java反射与XML配置文件的结合,并避免一些常见的问题和陷阱。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Java反射机制》专栏深入探讨了Java语言中反射机制的原理与应用。从介绍反射的基本概念出发,逐步分析了如何通过反射获取类的基本信息、调用对象方法、操作字段与属性、处理泛型类型、动态创建数组对象等核心技术。此外,还深入讨论了反射与注解处理、依赖注入、类加载、动态代理、JSON数据转换、异常处理、枚举类型操作、ClassLoader详解、XML配置文件解析、接口动态实现、性能优化技巧等方面的应用。该专栏特别着重于将反射与实际开发场景紧密结合,探讨了如何利用反射实现Spring AOP、构建自定义注解处理器、搭建简单的DI容器等实践技巧。通过本专栏的学习,读者将深刻理解反射机制的核心思想及其在Java开发中的广泛应用,为进阶开发打下坚实基础。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
特征贡献的Shapley分析:深入理解模型复杂度的实用方法
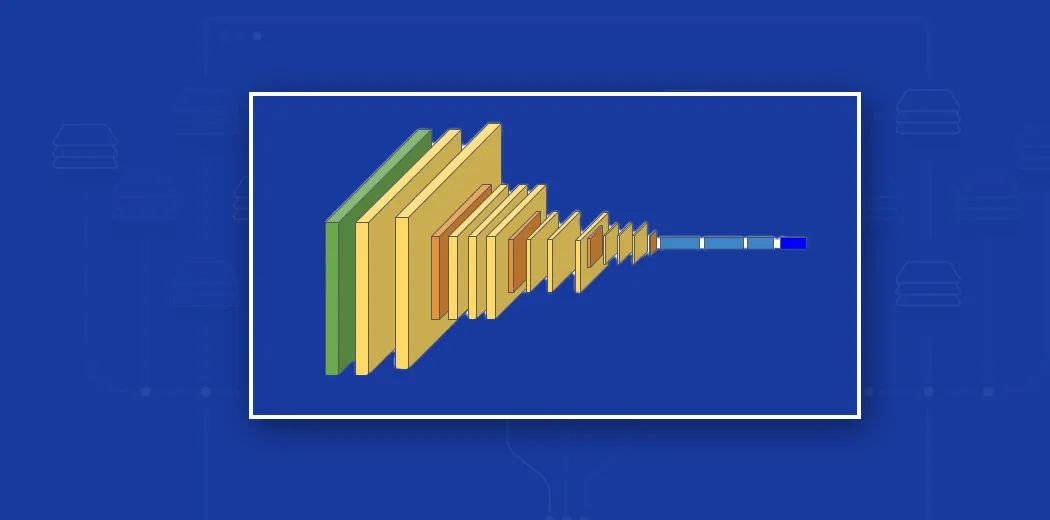
# 1. 特征贡献的Shapley分析概述
在数据科学领域,模型解释性(Model Explainability)是确保人工智能(AI)应用负责任和可信赖的关键因素。机器学习模型,尤其是复杂的非线性模型如深度学习,往往被认为是“黑箱”,因为它们的内部工作机制并不透明。然而,随着机器学习越来越多地应用于关键决策领域,如金融风控、医疗诊断和交通管理,理解模型的决策过程变得至关重要
VR_AR技术学习与应用:学习曲线在虚拟现实领域的探索

# 1. 虚拟现实技术概览
虚拟现实(VR)技术,又称为虚拟环境(VE)技术,是一种使用计算机模拟生成的能与用户交互的三维虚拟环境。这种环境可以通过用户的视觉、听觉、触觉甚至嗅觉感受到,给人一种身临其境的感觉。VR技术是通过一系列的硬件和软件来实现的,包括头戴显示器、数据手套、跟踪系统、三维声音系统、高性能计算机等。
VR技术的应用
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
机器学习调试实战:分析并优化模型性能的偏差与方差
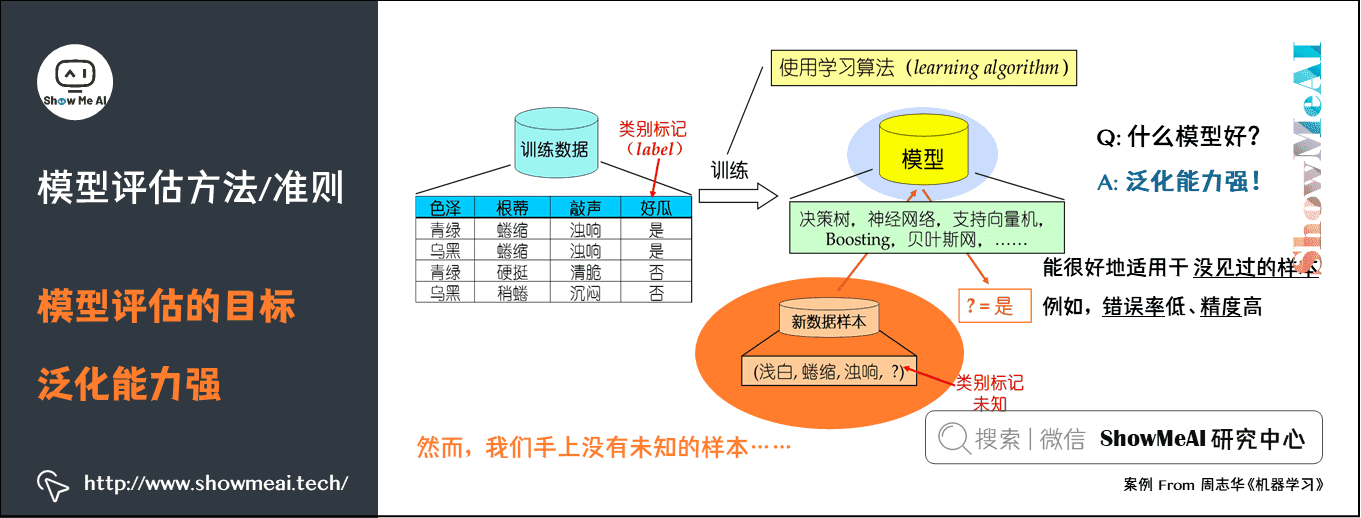
# 1. 机器学习调试的概念和重要性
## 什么是机器学习调试
机器学习调试是指在开发机器学习模型的过程中,通过识别和解决模型性能不佳的问题来改善模型预测准确性的过程。它是模型训练不可或缺的环节,涵盖了从数据预处理到最终模型部署的每一个步骤。
## 调试的重要性
有效的调试能够显著提高模型的泛化能力,即在未见过的数据上也能作出准确预测的能力。没有经过适当调试的模型可能无法应对实
贝叶斯优化软件实战:最佳工具与框架对比分析
# 1. 贝叶斯优化的基础理论
贝叶斯优化是一种概率模型,用于寻找给定黑盒函数的全局最优解。它特别适用于需要进行昂贵计算的场景,例如机器学习模型的超参数调优。贝叶斯优化的核心在于构建一个代理模型(通常是高斯过程),用以估计目标函数的行为,并基于此代理模型智能地选择下一点进行评估。
## 2.1 贝叶斯优化的基本概念
### 2.1.1 优化问题的数学模型
贝叶斯优化的基础模型通常包括目标函数 \(f(x)\),目标函数的参数空间 \(X\) 以及一个采集函数(Acquisition Function),用于决定下一步的探索点。目标函数 \(f(x)\) 通常是在计算上非常昂贵的,因此需
网格搜索:多目标优化的实战技巧

# 1. 网格搜索技术概述
## 1.1 网格搜索的基本概念
网格搜索(Grid Search)是一种系统化、高效地遍历多维空间参数的优化方法。它通过在每个参数维度上定义一系列候选值,并
模型选择与过拟合控制:交叉验证与模型复杂度调整秘籍

# 1. 模型选择与过拟合的基础概念
## 模型选择的重要性
在机器学习中,选择合适的模型是至关重要的一步,它直接影响到模型的性能和泛化能力。一个模型是否合适,不仅取决于它在训练集上的表现,更重要的是其在未知数据上的预测能力。因此,模型选择通常需要考虑两个方面:模型的拟合能力和泛化能力。
## 过拟合的定义
过拟合(Overfitting)是指模型对训练数据学得太好,以至于它
激活函数在深度学习中的应用:欠拟合克星
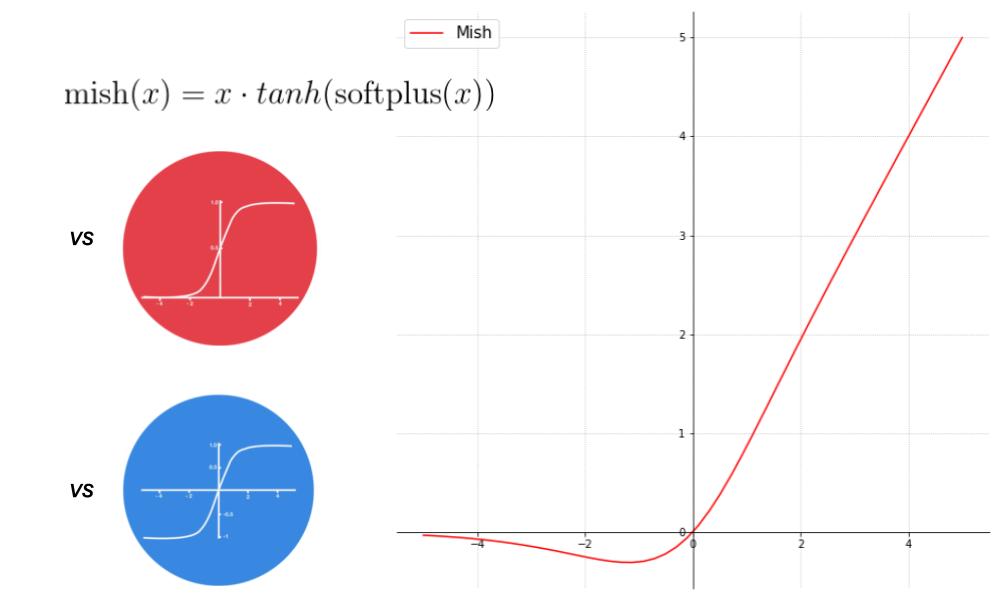
# 1. 深度学习中的激活函数基础
在深度学习领域,激活函数扮演着至关重要的角色。激活函数的主要作用是在神经网络中引入非线性,从而使网络有能力捕捉复杂的数据模式。它是连接层与层之间的关键,能够影响模型的性能和复杂度。深度学习模型的计算过程往往是一个线性操作,如果没有激活函数,无论网络有多少层,其表达能力都受限于一个线性模型,这无疑极大地限制了模型在现实问题中的应用潜力。
激活函数的基本
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
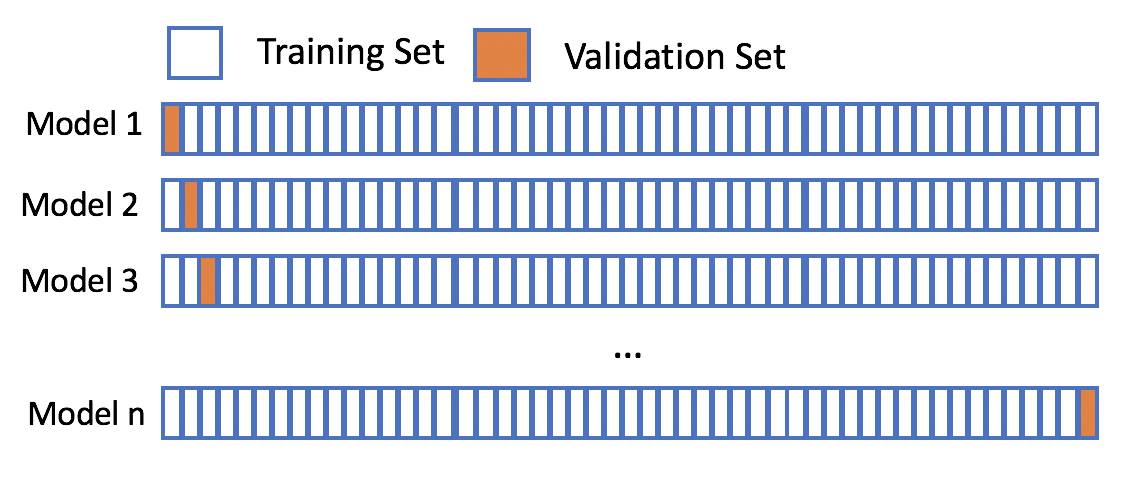
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )