YOLOv3目标检测:使用COCO数据集进行训练
发布时间: 2024-01-09 01:19:03 阅读量: 226 订阅数: 52 

coco简化版数据集+目标检测yolov使用
# 1. 介绍YOLOv3目标检测算法
## YOLOv3算法简介
YOLOv3(You Only Look Once v3)是一种基于深度学习的目标检测算法,由Joseph Redmon等人于2018年提出。相比于传统的目标检测算法,如R-CNN系列和SSD,YOLOv3具有更快的检测速度和更高的准确率。
## YOLOv3的优势和特点
- 快速:YOLOv3使用单个神经网络将图像作为整体进行处理,因此速度非常快速。在GPU上运行时,可以达到每秒30帧的处理速度。
- 多尺度特征提取:YOLOv3通过在不同尺度下提取特征,能够检测出各种大小的目标。
- 直接回归边界框:YOLOv3通过将目标检测问题转化为回归问题,直接预测边界框的坐标和大小,简化了目标检测算法的流程。
- 全局上下文信息:YOLOv3通过多层次的特征融合,能够更好地利用图像的全局上下文信息,提高了目标检测的准确率。
- 可拓展性:YOLOv3的网络结构可以根据需求进行拓展,从而适应不同场景下的目标检测任务。
通过以上内容,我们初步了解了YOLOv3目标检测算法的基本概念和特点。下面,我们将详细介绍使用COCO数据集进行训练的步骤以及相关的技术细节。
# 2. COCO数据集介绍
COCO(Common Objects in Context)数据集是一个通用的物体检测、分割和图像描述数据集。它是一个广泛使用的图像数据集,包含了丰富多样的目标类别和复杂的环境背景,适用于目标检测算法的训练和评估。
### COCO数据集的概述
COCO数据集由微软公司倾力打造,是一个大规模的图像数据库,用于训练和评估计算机视觉算法。该数据集包含了超过33万张图像,总共有80个不同类别的目标,以及超过20万个标注。
COCO数据集提供了四个主要任务的标注信息,包括目标检测、语义分割、实例分割和关键点检测。其中,目标检测是最常用的任务之一,因此在本章中我们重点介绍目标检测方面的数据标注方式。
### COCO数据集的数据组成和标注方式
COCO数据集的数据组成主要包括图像数据和标注数据。图像数据以JPEG格式存储,分辨率不等,从480x320到910x997不等。标注数据则以JSON格式存储,包含了目标类别、位置,以及其他相关信息。
每个图像对应的标注数据是一个列表,每个列表元素代表一个目标实例的标注。每个目标实例的标注信息包括类别ID、目标的二维边界框(Bounding Box)的位置坐标、遮挡信息、分割掩码等。
以下是一个示例标注数据的JSON格式:
```json
{
"images": [
{
"id": 1,
"width": 800,
"height": 600,
"file_name": "000000001.jpg"
},
...
],
"annotations": [
{
"id": 1,
"image_id": 1,
"category_id": 1,
"bbox": [96, 155, 205, 220],
"area": 10000,
"iscrowd": 0,
"segmentation": [...]
},
...
],
"categories": [
{
"id": 1,
"name": "person",
"supercategory": "person"
},
...
]
}
```
在上述示例中,"images"字段代表图像数据的列表,每个图像数据包含了ID、宽度、高度和文件名等信息。"annotations"字段代表标注数据的列表,每个标注数据包含了ID、图像ID、类别ID、目标边界框位置、面积、是否遮挡等信息。"categories"字段代表目标类别的列表,每个类别包含了ID、类别名称和超级类别等信息。
通过解析标注数据,可以获取COCO数据集中每个图像的目标实例信息,从而用于训练和评估目标检测算法。
在下一章中,我们将详细介绍如何下载和准备COCO数据集,并对图像数据和标注数据进行预处理,以用于YOLOv3目标检测模型的训练。
# 3. 数据预处理
在进行目标检测模型训练之前,数据预处理是非常重要的一步。本章将介绍如何下载和准备COCO数据集,并详细讨论图像数据和标注数据的预处理方法。
#### COCO数据集的下载和准备
COCO数据集是一个大型的通用物体检测、分割和字幕数据集,包含超过200,000个图像以及对超过80个物体类别的超过1.5 million个标注。你可以从[COCO官方网站](http://cocodataset.org/#download)下载最新版本的数据集。数据集包括图像文件、标注文件和类别标签文件,下载完成后需要对数据进行解压和组织。
#### 数据预处理的重要性
数据预处理对于模型训练的影响非常大。良好的数据预处理可以提高模型的训练效率和检测准确度,包括数据的清洗、标准化、增强等方面。
#### 图像数据和标注数据的预处理方法
1. **图像数据预处理方法:**
- 读取图像数据并解码成像素矩阵。
- 图像数据的缩放和裁剪,确保输入模型的图像尺寸符合要求。
- 数据增强操作,如随机裁剪、翻转、旋转等,增加数据多样性。
```python
import cv2
import numpy as np
# 读取图像数据
image = cv2.imread('image.jpg')
# 图像尺寸缩放
resized_image = cv2.resize(image, (416, 416))
# 数据增强:随机水平翻转
if np.random.rand() < 0.5:
flipped_image = cv2.flip(resized_image, 1)
else:
flipped_image = resized_image
```
2. **标注数据预处理方法:**
- 解析标注文件,并与对应的图像数据进行匹配。
- 将标注数据转换成模型所需的格式,如(x_min, y_min, x_max, y_max, class_id)。
- 对标注数据进行相应的缩放和裁剪,保持与图像数据一致。
```python
# 从标注文件中读取标注数据
annotation = load_annotation('annotation.json')
# 将标注数据转换成模型格式
processed_annotation = process_annotation(annotation)
# 标注数据缩放和裁剪
rescaled_annotation = rescale_annotation(processed_annotation, original_size, target_size)
```
通过以上图像数据和标注数据的预处理步骤,我们可以为模型训练提供高质量、多样性的数据集,从而提高模型的检测性能和泛化能力。
接下来,我们将介绍如何使用COCO数据集进行模型训练,包括模型的网络结构介绍、模型训练步骤和优化器的选择。
# 4. 模型训练
在这一章中,我们将介绍YOLOv3模型的网络结构,并讨论如何使用COCO数据集进行模型训练的具体步骤。我们还会涉及到损失函数和优化器的选择,这些都是模型训练中至关重要的部分。
#### YOLOv3模型的网络结构介绍
YOLOv3是一种基于深度学习的目标检测算法,其网络结构采用了Darknet-53作为其特征提取网络,相较于之前的版本,YOLOv3在网络结构上进行了改进和优化,提高了检测精度的同时降低了计算复杂度。该模型的网络结构设计简洁高效,适合在移动设备等资源受限的环境下进行目标检测。
#### 使用COCO数据集进行模型训练的步骤
1. 数据加载:首先,我们需要将COCO数据集加载到训练环境中。可以使用现有的数据加载工具或自行编写代码进行数据加载。
```python
# 代码示例
from pycocotools.coco import COCO
# 加载COCO数据集
dataDir = 'path_to_data'
dataType = 'train2017'
annFile = '{}/annotations/instances_{}.json'.format(dataDir, dataType)
coco = COCO(annFile)
```
2. 数据预处理:对加载的图像数据和标注数据进行预处理,包括图像尺寸调整、标注信息提取等操作。
```python
# 代码示例
# 图像尺寸调整
image = cv2.imread('path_to_image')
resized_image = cv2.resize(image, (416, 416))
# 标注信息提取
annIds = coco.getAnnIds(imgIds=[img_id], catIds=cat_ids, iscrowd=None)
anns = coco.loadAnns(annIds)
```
3. 模型训练:使用预处理后的数据对YOLOv3模型进行训练,这一步通常需要GPU资源和较长的时间。
```python
# 代码示例
# 模型训练
model.fit(X_train, y_train, epochs=100, batch_size=32, validation_data=(X_val, y_val))
```
#### 损失函数和优化器的选择
在模型训练过程中,损失函数和优化器的选择对训练效果有着巨大影响。针对YOLOv3模型的训练,一般会选择使用交叉熵损失函数(cross-entropy loss)和优化器(如Adam优化器)。
```python
# 代码示例
# 使用交叉熵损失函数
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
```
通过以上步骤,我们可以完成对YOLOv3模型在COCO数据集上的训练过程。在下一章中,我们将介绍模型的评估和调优,以及模型在COCO数据集上的表现。
# 5. 模型评估和调优
在模型训练完成之后,我们需要对模型进行评估和调优,以确保其在目标检测任务中具有良好的性能。
#### 模型评估指标
在目标检测任务中,常用的模型评估指标包括准确率(Precision)、召回率(Recall)、F1值(F1-score)和 mAP(mean Average Precision)。
- 准确率(Precision):指模型预测为正的样本中,真正为正样本的比例,即预测正确的正样本数占所有被预测为正样本的比例。
- 召回率(Recall):指所有真正为正的样本中,被模型预测为正的比例,即预测正确的正样本数占所有真正为正样本的比例。
- F1值(F1-score):是准确率和召回率的调和均值,综合考量了模型的准确率和召回率。
- mAP(mean Average Precision):是目标检测任务中常用的模型评估指标,综合考虑了不同类别目标的准确率和召回率,是一种更全面的模型性能评估指标。
#### 调参技巧和方法
在模型训练过程中,我们需要进行一些调参的技巧和方法,以提高模型的性能和泛化能力。一些常用的调参技巧包括:
- 学习率调整:可以使用学习率衰减的方法,随着训练的进行逐步减小学习率,以提高模型的收敛性。
- 数据增强:通过对训练数据进行随机裁剪、旋转、翻转等操作,增加训练数据的多样性,提高模型的泛化能力。
- 正则化:通过L1或L2正则化等方法,控制模型的复杂度,防止过拟合。
#### 模型在COCO数据集上的表现
最后,我们需要对模型在COCO数据集上的表现进行评估。可以通过在COCO数据集上进行目标检测的测试,得到模型在不同类别目标上的准确率、召回率和mAP等指标,从而全面评估模型在实际任务中的性能表现。
通过对模型的评估和调优,我们可以进一步改进模型的性能,提高其在实际场景中的适用性和准确性。
# 6. 实际应用与展望
YOLOv3模型在实际应用中的情况
YOLOv3目标检测算法的出现,给各行各业的实际应用带来了巨大的影响。以下是YOLOv3在几个典型领域中的应用案例:
1. 无人驾驶:YOLOv3可以在自动驾驶系统中用于实时的车辆和行人检测,确保行驶安全。通过在车辆上安装相应的摄像头,YOLOv3可以实时检测周围的目标并生成精确的边界框,以帮助车辆做出准确的决策。
2. 安防监控:利用YOLOv3算法,可以在监控摄像头所捕获的图像中快速准确地检测到人员和物体,从而实现对安全事件的实时识别和告警。这对于提升安防监控的效率和准确性至关重要。
3. 工业质检:对于工厂和生产线中的质检任务,YOLOv3可以快速准确地检测出产品中的缺陷和瑕疵,并及时进行排查和处理。这不仅提高了质检的效率,也降低了人工质检的误判和漏检率。
4. 物体识别与辅助决策:YOLOv3可以应用在各种基于图像的物体识别任务中,如智能拍照识别、图像搜索、辅助决策等。通过快速而准确地检测出图像中的目标物体,使得计算机能够更好地理解图像,并根据图像内容做出相应的决策。
YOLOv3目标检测的发展趋势和展望
目标检测技术在实际应用中的需求越来越迫切,同时也在不断发展与演进。对于YOLOv3目标检测算法而言,未来的发展趋势和展望主要包括以下几个方面:
1. 动态目标检测:目前的YOLOv3算法主要针对静态图像的目标检测,在处理视频场景时仍然存在一定的困难。未来的发展方向是将YOLOv3算法扩展到视频目标检测领域,实现对动态目标的准确检测和跟踪。
2. 多模态目标检测:未来的目标检测算法可能会融合多种输入模态,如图像、语音、雷达等,实现对复杂场景和多种传感器数据的联合分析和目标检测。这将进一步提高目标检测的准确性和可靠性。
3. 联邦学习与隐私保护:目标检测算法在实际应用中通常需要使用大量的数据进行模型训练,而这些数据往往包含用户的个人隐私信息。未来的发展方向是通过联邦学习等技术,实现在保护用户隐私的前提下,进行跨设备、跨组织的目标检测模型训练和共享。
4. 算法优化与硬件加速:随着目标检测模型的不断深入和复杂化,如何实现模型的高效推理和应用成为一个重要的问题。未来的发展方向是通过算法优化和硬件加速等手段,进一步提高目标检测算法的效率和实时性。
综上所述,YOLOv3目标检测算法在实际应用中发挥着重要作用,并且具有广阔的发展前景。随着技术的不断进步和应用需求的不断增长,相信YOLOv3目标检测算法将在更多领域中得到应用,并为智能化社会的发展做出贡献。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏 "yolov3目标检测:原理与源码解析" 包含从基础的 YOLOv3 目标检测简介与基本原理到深入的模型优化与性能提升的系列文章。首先,我们将介绍 YOLOv3 目标检测算法的基本原理,然后深入探讨如何使用COCO数据集进行训练以及Darknet框架的详细解析。接着,我们会分析 YOLOv3 的网络结构与特征提取方式,以及 bounding box 回归与 NMS 算法的实现原理。随后,我们会深入理解 YOLOv3 的损失函数,并探讨模型评估指标与性能评估方法。此外,还将介绍深度学习加速技术在 YOLOv3 中的应用,以及使用 OpenCV 进行图像处理与预处理的方法。同时,我们会探讨 GPU 加速计算与并行计算优化,以及在嵌入式设备上的部署与优化技巧。此外,还会介绍使用 TFLite 进行模型转换与量化,以及在移动端应用中的优化与性能提升方法。最后,将深入探讨使用 TensorRT 进行模型加速与推理优化,以及比较 YOLOv4 与 YOLOv5 的改进,以及深度学习模型的鲁棒性与对抗性攻击相关话题。通过本专栏,读者可以系统地学习和理解 YOLOv3 目标检测算法及其在各个方面的实际应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
爱普生R230打印机:废墨清零的终极指南,优化打印效果与性能

# 摘要
本文全面介绍了爱普生R230打印机的功能特性,重点阐述了废墨清零的技术理论基础及其操作流程。通过对废墨系统的深入探讨,文章揭示了废墨垫的作用限制和废墨计数器的工作逻辑,并强调了废墨清零对防止系统溢出和提升打印机性能的重要性。此外,本文还分享了提高打印效果的实践技巧,包括打印头校准、色彩管理以及高级打印设置的调整方法。文章最后讨论了打印机的维护策略和性能优化手段,以及在遇到打印问题时的故障排除
【Twig在Web开发中的革新应用】:不仅仅是模板

# 摘要
本文旨在全面介绍Twig模板引擎,包括其基础理论、高级功能、实战应用以及进阶开发技巧。首先,本文简要介绍了Twig的背景及其基础理论,包括核心概念如标签、过滤器和函数,以及数据结构和变量处理方式。接着,文章深入探讨了Twig的高级
如何评估K-means聚类效果:专家解读轮廓系数等关键指标
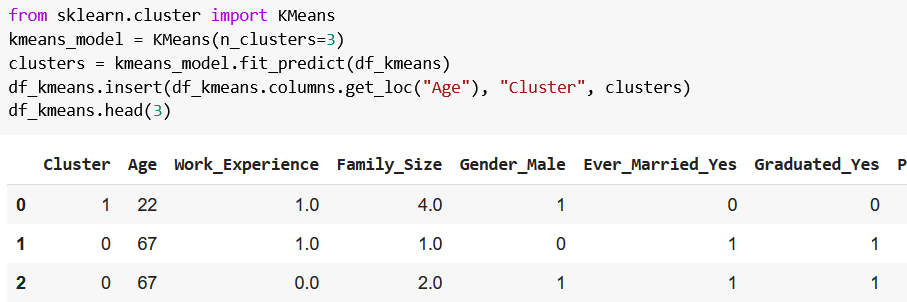
# 摘要
K-means聚类算法是一种广泛应用的数据分析方法,本文详细探讨了K-means的基础知识及其聚类效果的评估方法。在分析了内部和外部指标的基础上,本文重点介绍了轮廓系数的计算方法和应用技巧,并通过案例研究展示了K-means算法在不同领域的实际应用效果。文章还对聚类效果的深度评估方法进行了探讨,包括簇间距离测量、稳定性测试以及高维数据聚类评估。最后,本
STM32 CAN寄存器深度解析:实现功能最大化与案例应用
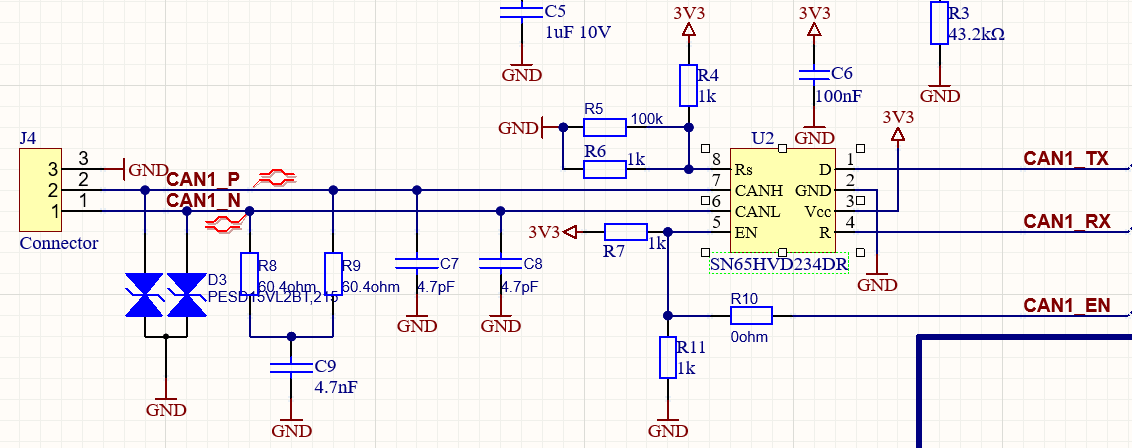
# 摘要
本文对STM32 CAN总线技术进行了全面的探讨和分析,从基础的CAN控制器寄存器到复杂的通信功能实现及优化,并深入研究了其高级特性。首先介绍了STM32 CAN总线的基本概念和寄存器结构,随后详细讲解了CAN通信功能的配置、消息发送接收机制以及错误处理和性能优化策略。进一步,本文通过具体的案例分析,探讨了STM32在实时数据监控系统、智能车载网络通信以
【GP错误处理宝典】:GP Systems Scripting Language常见问题与解决之道
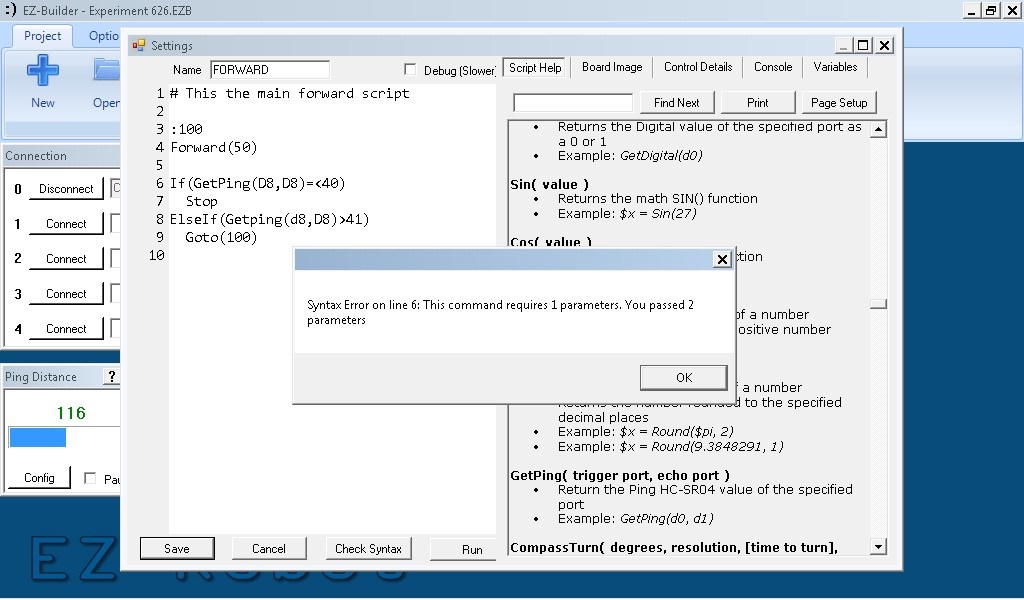
# 摘要
GP Systems Scripting Language是一种为特定应用场景设计的脚本语言,它提供了一系列基础语法、数据结构以及内置函数和运算符,支持高效的数据处理和系统管理。本文全面介绍了GP脚本的基本概念、基础语法和数据结构,包括变量声明、数组与字典的操作和标准函数库。同时,详细探讨了流程控制与错误处理机制,如条件语句、循环结构和异常处
【电子元件精挑细选】:专业指南助你为降噪耳机挑选合适零件

# 摘要
随着个人音频设备技术的迅速发展,降噪耳机因其能够提供高质量的听觉体验而受到市场的广泛欢迎。本文从电子元件的角度出发,全面分析了降噪耳机的设计和应用。首先,我们探讨了影响降噪耳机性能的电子元件基础,包括声学元件、电源管理元件以及连接性与控制元
ARCGIS高手进阶:只需三步,高效创建1:10000分幅图!
# 摘要
本文深入探讨了ARCGIS环境下1:10000分幅图的创建与管理流程。首先,我们回顾了ARCGIS的基础知识和分幅图的理论基础,强调了1:10000比例尺的重要性以及地理信息处理中的坐标系统和转换方法。接着,详细阐述了分幅图的创建流程,包括数据的准备与导入、创建和编辑过程,以及输出格式和版本管理。文中还介绍了一些高级技巧,如自动化脚本的使用和空间分析,以
【数据质量保障】:Talend确保数据精准无误的六大秘诀
# 摘要
数据质量对于确保数据分析与决策的可靠性至关重要。本文探讨了Talend这一强大数据集成工具的基础和在数据质量管理中的高级应用。通过介绍Talend的核心概念、架构、以及它在数据治理、监控和报告中的功能,本文强调了Talend在数据清洗、转换、匹配、合并以及验证和校验等方面的实践应用。进一步地,文章分析了Talend在数据审计和自动化改进方面的高级功能,包括与机器学习技术的结合。最后,通过金融服务和医疗保健行业的案
【install4j跨平台部署秘籍】:一次编写,处处运行的终极指南

# 摘要
本文深入探讨了使用install4j工具进行跨平台应用程序部署的全过程。首先介绍了install4j的基本概念和跨平台部署的基础知识,接着详细阐述了其安装步骤、用户界面布局以及系统要求。在此基础上,文章进一步阐述了如何使用install4j创建具有高度定制性的安装程序,包括定义应用程序属性、配置行为和屏幕以及管理安装文件和目录。此外,本文还
【Quectel-CM AT命令集】:模块控制与状态监控的终极指南

# 摘要
本论文旨在全面介绍Quectel-CM模块及其AT命令集,为开发者提供深入的理解与实用指导。首先,概述Quectel-CM模块的基础知识与AT命令基础,接着详细解析基本通信、网络功能及模块配置命令。第三章专注于AT命令的实践应用,包括数据传输、状态监控
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )