




ElementTree内存管理艺术:如何优化内存使用以处理大型文件


使用Python的`xml.etree.ElementTree`模块处理XML数据
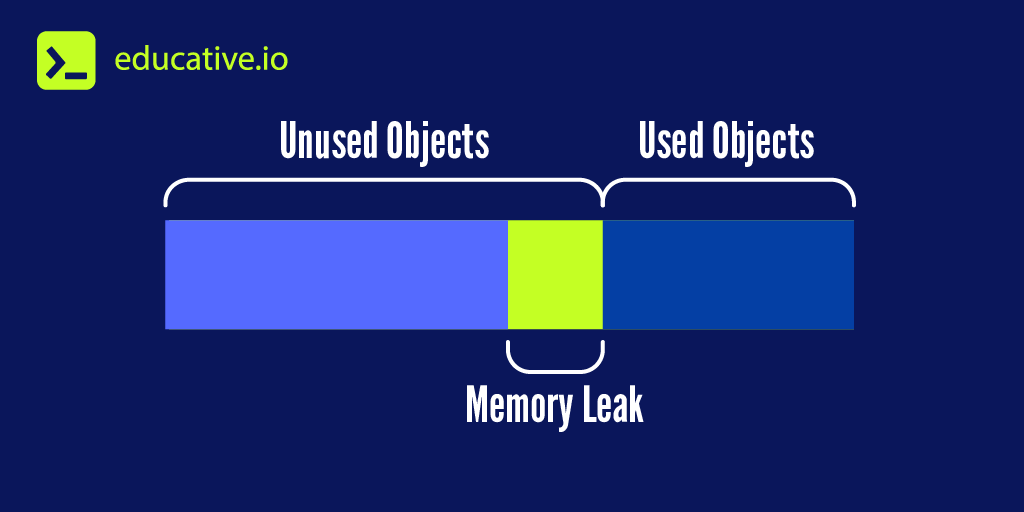
1. ElementTree的基本概念与内存开销
ElementTree的基本概念
ElementTree是Python标准库中的一个XML处理模块,它提供了一套简单易用的API来解析和创建XML数据。ElementTree的主要特点包括轻量级、高效和易于使用,这使得它成为了处理XML数据的首选工具之一。
内存开销的考量
尽管ElementTree在性能上有诸多优势,但它在处理大型XML文件时的内存开销却是一个不容忽视的问题。随着XML文件大小的增加,ElementTree需要消耗更多的内存来存储整个文件的树状结构。这种内存开销可能会影响到程序的性能,尤其是在资源受限的环境中。因此,理解和管理ElementTree的内存使用成为了提高处理效率的关键。
内存使用的实例分析
为了更好地理解ElementTree的内存开销,我们可以通过一个简单的示例来分析。假设我们有一个包含10,000个元素的XML文件,每个元素都有一个文本节点和若干属性。在加载这个文件到ElementTree时,我们可以使用Python的内置函数sys.getsizeof来测量内存使用情况。通过对比加载前后程序的内存使用,我们可以直观地看到ElementTree的内存占用。

通过上述代码,我们可以得到ElementTree解析特定XML文件时的内存开销,这对于进一步的优化和调优具有指导意义。
2. ElementTree的内存使用原理
2.1 内存占用的理论基础
2.1.1 ElementTree数据结构分析
ElementTree是Python标准库中用于解析和创建XML数据的一个轻量级的API。它提供了一种方便的方式来处理XML文档,包括遍历、搜索和修改元素。ElementTree构建的XML树结构由多个Element对象组成,每个对象代表XML中的一个元素,拥有标签、属性和子元素等属性。
在内存使用方面,ElementTree需要为每个Element对象分配内存,用于存储其属性和子元素。这意味着,如果XML文档结构复杂,拥有大量的元素和属性,那么内存的消耗将会显著增加。每个Element对象至少需要存储其标签名、属性字典、子元素列表以及对父元素的引用,这些都是内存占用的主要因素。
2.1.2 XML解析与内存分配
XML解析过程涉及到将XML文档的字符串数据转换为内存中的Element对象结构。这个过程大致分为两个步骤:
- 词法分析:将XML文档分解为一系列的标记(tokens),例如开始标签、结束标签、文本内容等。
- 语法分析:根据XML的语法规则,将这些标记组织成树状的
Element对象结构。
在词法分析阶段,解析器会创建一个或多个Token对象来表示XML文档中的每个标记。在语法分析阶段,解析器会根据标记之间的关系,创建Element对象并将它们连接起来,形成一个完整的树状结构。
由于解析过程中需要创建大量临时对象来存储标记和构建树结构,因此XML解析往往是一个内存密集型的操作。特别是对于大型XML文件,如果处理不当,很容易造成内存溢出或性能瓶颈。
2.2 内存使用的监测方法
2.2.1 内存分析工具的选择与使用
监测ElementTree的内存使用情况,可以使用多种工具,如Python内置的tracemalloc模块、memory_profiler库、objgraph库等。这些工具可以帮助我们了解内存使用模式,识别内存泄漏,并优化代码。
tracemalloc模块:Python 3.4引入的模块,可以追踪Python代码的内存分配和释放,帮助定位内存问题。memory_profiler库:可以提供Python程序的内存使用情况,通过逐行分析代码,确定内存占用的热点。objgraph库:可以生成对象的引用图,帮助分析对象之间的关系和内存占用。
使用这些工具时,通常需要在代码中加入相应的导入和调用语句,例如使用tracemalloc:
- import tracemalloc
- # 开启跟踪
- tracemalloc.start()
- # 执行ElementTree相关操作
- # ...
- # 获取当前内存使用情况快照
- snapshot = tracemalloc.take_snapshot()
- # 选择最近的快照并打印内存使用情况
- top_stats = snapshot.statistics('lineno')
- for stat in top_stats[:10]:
- print(stat)
2.2.2 ElementTree内存使用概况
通过内存分析工具,我们可以获得ElementTree在处理XML文件时的内存使用概况。例如,使用memory_profiler库,我们可以得到如下输出:
- # 使用memory_profiler分析内存使用情况
- @profile
- def parse_xml():
- # ElementTree解析XML文件的代码
- # ...
- if __name__ == "__main__":
- parse_xml()
执行上述代码后,memory_profiler会输出每个函数调用的内存使用情况,帮助我们了解ElementTree在不同阶段的内存占用。
通过这些分析,我们可以发现ElementTree在处理大型XML文件时的内存消耗模式,以及哪些操作可能导致内存使用过高。这些信息对于优化内存使用和提高程序性能至关重要。
在本章节中,我们介绍了ElementTree的内存使用原理,包括其数据结构分析、XML解析与内存分配的过程,以及如何使用内存分析工具来监测和分析ElementTree的内存使用情况。通过这些基础知识,我们可以为后续章节中关于ElementTree性能优化和处理大型文件的策略打下坚实的基础。
3. ElementTree处理大型文件的策略
3.1 优化解析策略
处理大型XML文件时,合理的解析策略至关重要。ElementTree提供了递归和迭代两种解析方式,每种方式都有其优势和局限性。选择合适的解析策略,可以大幅度提升处理效率,减少内存消耗。
3.1.1 递归与迭代解析的选择
递归解析是ElementTree默认的解析方式,它易于理解且编写简单。但是,递归解析在处理大型文件时可能会因为深度过大而导致栈溢出。以下是递归解析的一个示例代码:
- import xml.etree.ElementTree as ET
- def parse_recursive(xml_file):
- tree = ET.parse(xml_file)
- return tree.getroot()
该代码段使用ET.parse()函数直接解析XML文件,并返回根元素。递归解析适用于内存充足且XML结构不深的小型文件。
迭代解析是一种基于事件的解析方式,通过监听事件来处理XML内容,不会一次性加载整个文档到内存中。以下是使用迭代解析的一个示例代码:
- import xml.etree.ElementTree as ET
- from xml.etree.ElementTree import iterparse
- def parse_iterative(xml_file):
-

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【精准测试】:确保分层数据流图准确性的完整测试方法
Cygwin系统监控指南:性能监控与资源管理的7大要点
【T-Box能源管理】:智能化节电解决方案详解
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )





















