CentOS 7 安装 Python 3:从基础到实战
发布时间: 2024-06-21 05:34:23 阅读量: 12 订阅数: 19 

# 1. Python 3 简介**
Python 3 是一种高级编程语言,以其简洁、易读和强大的功能而闻名。它广泛用于各种领域,包括 Web 开发、数据科学、机器学习和自动化。与 Python 2 相比,Python 3 进行了重大改进,包括:
- 统一了整数和浮点数类型,简化了代码。
- 移除了 print 语句,取而代之的是 print() 函数。
- 引入了新的关键字参数,提高了代码的可读性和可维护性。
# 2. CentOS 7 上安装 Python 3
### 2.1 安装 Python 3
**步骤 1:更新系统**
```bash
sudo yum update
```
**步骤 2:安装 Python 3**
```bash
sudo yum install python3
```
### 2.2 验证 Python 3 安装
**步骤 1:检查 Python 3 版本**
```bash
python3 --version
```
**步骤 2:运行 Python 3 交互式 shell**
```bash
python3
```
### 2.3 设置 Python 3 环境变量
**步骤 1:编辑环境变量文件**
```bash
sudo nano /etc/profile.d/python3.sh
```
**步骤 2:添加 Python 3 路径**
```bash
export PATH=/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbin:/usr/local/sbin:/opt/bin
```
**步骤 3:保存并退出**
按 `Ctrl+O` 保存文件,然后按 `Ctrl+X` 退出。
**步骤 4:重新加载环境变量**
```bash
source /etc/profile.d/python3.sh
```
### 2.4 扩展内容
**参数说明:**
* `--version`:显示 Python 3 版本。
* `/usr/local/bin`:Python 3 可执行文件路径。
* `/usr/bin`:系统可执行文件路径。
* `/bin`:基本可执行文件路径。
* `/usr/sbin`:系统管理员可执行文件路径。
* `/sbin`:基本管理员可执行文件路径。
* `/usr/local/sbin`:本地管理员可执行文件路径。
* `/opt/bin`:可选软件可执行文件路径。
**逻辑分析:**
* **步骤 1:更新系统**:确保系统是最新的,以避免安装冲突。
* **步骤 2:安装 Python 3**:使用 `yum` 包管理器安装 Python 3。
* **步骤 3:检查 Python 3 版本**:验证 Python 3 是否已成功安装。
* **步骤 4:运行 Python 3 交互式 shell**:进入 Python 3 交互式环境,用于测试和交互。
* **步骤 5:编辑环境变量文件**:创建或编辑环境变量文件,以添加 Python 3 路径。
* **步骤 6:添加 Python 3 路径**:将 Python 3 可执行文件路径添加到 `PATH` 环境变量中。
* **步骤 7:保存并退出**:保存更改并退出环境变量文件。
* **步骤 8:重新加载环境变量**:重新加载环境变量,以使更改生效。
# 3.1 数据类型和变量
Python 3 中的数据类型用于定义变量中存储数据的类型。Python 3 具有以下内置数据类型:
- **数字类型:** int、float、complex
- **字符串类型:** str
- **布尔类型:** bool
- **序列类型:** list、tuple、range
- **映射类型:** dict
- **集合类型:** set、frozenset
**变量**用于存储数据,并通过变量名对其进行引用。变量名必须以字母或下划线开头,后面可以跟字母、数字或下划线。变量名不能是 Python 3 关键字。
要声明变量,只需将值分配给变量名即可,如下所示:
```python
x = 10
y = "Hello"
z = True
```
### 3.2 运算符和表达式
**运算符**用于对变量和值执行操作。Python 3 中有以下类型的运算符:
- **算术运算符:** +、-、*、/、%、**
- **比较运算符:** ==、!=、<、>、<=、>=
- **逻辑运算符:** and、or、not
- **位运算符:** &、|、^、~、<<、>>
**表达式**是由运算符和操作数组成的公式。表达式可以求值,产生一个值。
以下是一些 Python 3 表达式的示例:
```python
x + y
x - y
x * y
x / y
x % y
x ** y
x == y
x != y
x < y
x > y
x <= y
x >= y
x and y
x or y
not x
```
### 3.3 流程控制
**流程控制**用于控制程序执行的流程。Python 3 中有以下流程控制语句:
- **if 语句:**用于根据条件执行代码块。
- **elif 语句:**用于在 if 语句中添加其他条件。
- **else 语句:**用于在 if 语句中添加一个默认代码块。
- **for 循环:**用于遍历序列中的元素。
- **while 循环:**用于只要条件为真就执行代码块。
- **break 语句:**用于退出循环。
- **continue 语句:**用于跳过循环的当前迭代。
以下是一些 Python 3 流程控制语句的示例:
```python
if x > 0:
print("x is positive")
elif x < 0:
print("x is negative")
else:
print("x is zero")
for i in range(10):
print(i)
while x > 0:
x -= 1
print(x)
```
### 3.4 函数和模块
**函数**是代码块,可以接收输入,执行操作并返回输出。函数可以提高代码的可重用性和可维护性。
要定义函数,请使用以下语法:
```python
def function_name(parameters):
"""Function documentation"""
# Function body
return output
```
**模块**是包含函数、类和变量的 Python 文件。模块可以导入到其他 Python 程序中,以重用代码。
要导入模块,请使用以下语法:
```python
import module_name
```
# 4. Python 3 实战应用
### 4.1 文件操作
文件操作是 Python 中一项重要的功能,它允许程序与文件系统进行交互。Python 提供了多种内置函数和模块来处理文件,包括打开、读取、写入和关闭文件。
**打开文件**
要打开一个文件,可以使用 `open()` 函数。该函数接受两个参数:文件路径和模式。模式指定如何打开文件,常见模式包括:
- `r`:以只读模式打开文件
- `w`:以只写模式打开文件,如果文件不存在则创建文件
- `a`:以追加模式打开文件,如果文件不存在则创建文件
- `r+`:以读写模式打开文件
- `w+`:以读写模式打开文件,如果文件不存在则创建文件
**示例:**
```python
# 以只读模式打开文件
with open("myfile.txt", "r") as f:
# 读取文件内容
contents = f.read()
```
**读取文件**
打开文件后,可以使用 `read()` 方法读取文件内容。该方法返回一个字符串,其中包含文件的全部内容。
**示例:**
```python
# 读取文件内容
contents = f.read()
```
**写入文件**
要写入文件,可以使用 `write()` 方法。该方法接受一个字符串参数,其中包含要写入文件的内容。
**示例:**
```python
# 以只写模式打开文件
with open("myfile.txt", "w") as f:
# 写入文件内容
f.write("Hello, world!")
```
**关闭文件**
在完成文件操作后,必须关闭文件以释放系统资源。可以使用 `close()` 方法关闭文件。
**示例:**
```python
# 关闭文件
f.close()
```
### 4.2 网络编程
Python 提供了强大的网络编程功能,允许程序通过网络与其他计算机进行通信。Python 中的网络编程主要使用 `socket` 模块。
**创建套接字**
要创建套接字,可以使用 `socket()` 函数。该函数接受三个参数:
- `family`:套接字家族,指定使用的协议(例如,`AF_INET` 用于 IPv4,`AF_INET6` 用于 IPv6)
- `type`:套接字类型,指定套接字的行为(例如,`SOCK_STREAM` 用于 TCP 套接字,`SOCK_DGRAM` 用于 UDP 套接字)
- `protocol`:套接字协议,指定使用的协议(例如,`0` 表示使用默认协议)
**示例:**
```python
# 创建 TCP 套接字
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0)
```
**绑定套接字**
要将套接字绑定到特定地址和端口,可以使用 `bind()` 方法。该方法接受一个元组参数,其中包含地址和端口。
**示例:**
```python
# 将套接字绑定到本地主机和端口 8080
sock.bind(("localhost", 8080))
```
**监听套接字**
要监听传入的连接,可以使用 `listen()` 方法。该方法接受一个参数,指定允许排队的最大连接数。
**示例:**
```python
# 监听传入的连接,允许最多 5 个连接排队
sock.listen(5)
```
**接受连接**
当有客户端连接到套接字时,可以使用 `accept()` 方法接受连接。该方法返回一个元组,其中包含新的套接字对象和客户端地址。
**示例:**
```python
# 接受传入的连接
conn, addr = sock.accept()
```
### 4.3 数据库编程
Python 提供了对各种数据库系统的支持,包括 MySQL、PostgreSQL、SQLite 和 MongoDB。Python 中的数据库编程主要使用 `sqlalchemy` 模块。
**创建引擎**
要创建连接到数据库的引擎,可以使用 `create_engine()` 函数。该函数接受一个连接字符串参数,其中包含数据库类型、主机、用户名、密码和数据库名称。
**示例:**
```python
# 创建连接到 MySQL 数据库的引擎
engine = create_engine("mysql+pymysql://user:password@host/database")
```
**创建会话**
要创建会话,可以使用 `sessionmaker()` 函数。该函数接受一个引擎参数,返回一个会话类。
**示例:**
```python
# 创建会话类
Session = sessionmaker(bind=engine)
```
**创建会话对象**
要创建会话对象,可以使用会话类的 `__call__()` 方法。
**示例:**
```python
# 创建会话对象
session = Session()
```
**查询数据库**
要查询数据库,可以使用 `query()` 方法。该方法接受一个查询对象参数,返回一个结果集。
**示例:**
```python
# 查询所有用户
users = session.query(User).all()
```
# 5.1 对象和类
### 5.1.1 面向对象编程简介
面向对象编程(OOP)是一种编程范式,它将程序组织成对象。对象封装了数据和操作这些数据的行为。OOP 的主要优点包括:
- **封装:** 对象将数据和方法捆绑在一起,从而隐藏了实现细节。
- **继承:** 子类可以继承父类的属性和方法,从而实现代码重用。
- **多态性:** 对象可以以不同的方式响应相同的消息,从而提高了代码的灵活性。
### 5.1.2 Python 中的类
Python 中的类使用 `class` 关键字定义。类包含数据成员(属性)和方法(行为)。
```python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
def get_age(self):
return self.age
```
### 5.1.3 对象实例化
要创建类的实例,请使用 `()` 运算符。实例是类的具体对象,它具有自己的数据和行为。
```python
person = Person("John Doe", 30)
print(person.get_name()) # 输出:John Doe
```
### 5.1.4 继承
继承允许子类从父类继承属性和方法。子类可以使用父类的方法,并可以定义自己的新方法。
```python
class Employee(Person):
def __init__(self, name, age, salary):
super().__init__(name, age)
self.salary = salary
def get_salary(self):
return self.salary
```
### 5.1.5 多态性
多态性允许对象以不同的方式响应相同的消息。这可以通过方法覆盖来实现,其中子类重新定义父类的方法。
```python
class Manager(Employee):
def get_salary(self):
return super().get_salary() + 1000
```
### 5.1.6 练习
1. 创建一个 `Student` 类,具有 `name`、`age` 和 `grade` 属性。
2. 为 `Student` 类添加一个 `get_grade()` 方法,该方法返回学生的成绩。
3. 创建一个 `Teacher` 类,从 `Person` 类继承,具有 `name`、`age` 和 `subject` 属性。
4. 为 `Teacher` 类添加一个 `get_subject()` 方法,该方法返回老师教授的科目。
# 6. 案例实战**
**6.1 使用 Python 3 编写 Web 应用程序**
**使用 Flask 框架创建 Web 应用程序**
Flask 是一个轻量级的 Python Web 框架,它提供了创建 Web 应用程序所需的基本功能。要使用 Flask 框架,首先需要安装它:
```bash
pip install Flask
```
安装完成后,创建一个名为 `app.py` 的 Python 文件,并输入以下代码:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello, World!'
if __name__ == '__main__':
app.run()
```
这个代码创建了一个简单的 Web 应用程序,它会在根路径 `/` 上显示 "Hello, World!"。要运行这个应用程序,请在终端中输入以下命令:
```bash
python app.py
```
然后,在浏览器中访问 `http://localhost:5000`,就可以看到 "Hello, World!"。
**使用 Django 框架创建 Web 应用程序**
Django 是一个全栈 Python Web 框架,它提供了更丰富的功能,包括模型、视图和模板。要使用 Django 框架,首先需要安装它:
```bash
pip install Django
```
安装完成后,创建一个名为 `myproject` 的 Django 项目:
```bash
django-admin startproject myproject
```
然后,在 `myproject` 目录下创建一个名为 `myapp` 的应用程序:
```bash
python manage.py startapp myapp
```
在 `myapp` 目录下创建一个名为 `models.py` 的文件,并输入以下代码:
```python
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=30)
age = models.IntegerField()
```
这个代码创建了一个名为 `Person` 的 Django 模型,它包含两个字段:`name` 和 `age`。
在 `myapp` 目录下创建一个名为 `views.py` 的文件,并输入以下代码:
```python
from django.shortcuts import render
def index(request):
people = Person.objects.all()
return render(request, 'index.html', {'people': people})
```
这个代码创建了一个名为 `index` 的 Django 视图,它从数据库中获取所有 `Person` 对象,并将其传递给 `index.html` 模板。
在 `myapp` 目录下创建一个名为 `index.html` 的模板文件,并输入以下代码:
```html
<h1>People</h1>
<ul>
{% for person in people %}
<li>{{ person.name }} ({{ person.age }})</li>
{% endfor %}
</ul>
```
这个代码创建了一个简单的 HTML 模板,它将 `people` 列表中的每个 `Person` 对象显示为一个列表项。
最后,在 `myproject` 目录下运行以下命令来启动 Django 开发服务器:
```bash
python manage.py runserver
```
然后,在浏览器中访问 `http://localhost:8000/myapp/`,就可以看到所有 `Person` 对象的列表。
**6.2 使用 Python 3 进行数据分析**
**使用 Pandas 库进行数据分析**
Pandas 是一个用于数据分析和操作的 Python 库。它提供了各种数据结构和操作,包括 DataFrame、Series 和 Index。要使用 Pandas 库,首先需要安装它:
```bash
pip install pandas
```
安装完成后,创建一个名为 `data_analysis.py` 的 Python 文件,并输入以下代码:
```python
import pandas as pd
data = pd.read_csv('data.csv')
print(data.head())
```
这个代码从 `data.csv` 文件中读取数据并将其存储在 DataFrame 中。然后,它打印 DataFrame 的前五行。
**使用 NumPy 库进行数据分析**
NumPy 是一个用于科学计算的 Python 库。它提供了各种数学和统计函数,包括数组、矩阵和线性代数。要使用 NumPy 库,首先需要安装它:
```bash
pip install numpy
```
安装完成后,创建一个名为 `data_analysis.py` 的 Python 文件,并输入以下代码:
```python
import numpy as np
data = np.loadtxt('data.csv', delimiter=',')
print(data.mean())
```
这个代码从 `data.csv` 文件中加载数据并将其存储在 NumPy 数组中。然后,它计算数组中所有元素的平均值。
**使用 SciPy 库进行数据分析**
SciPy 是一个用于科学和技术计算的 Python 库。它提供了各种高级数学和统计函数,包括优化、积分和微分方程求解。要使用 SciPy 库,首先需要安装它:
```bash
pip install scipy
```
安装完成后,创建一个名为 `data_analysis.py` 的 Python 文件,并输入以下代码:
```python
import scipy.stats as stats
data = np.loadtxt('data.csv', delimiter=',')
print(stats.ttest_ind(data[:, 0], data[:, 1]))
```
这个代码从 `data.csv` 文件中加载数据并将其存储在 NumPy 数组中。然后,它使用 SciPy 的 `ttest_ind` 函数执行两个独立样本的 t 检验。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 CentOS 7 上安装和使用 Python 3 的指南,从基础到实战,一步步详解。涵盖从安装 Python 3 到优化性能和稳定性的最佳实践。此外,专栏还深入探讨了 MySQL 数据库性能提升、死锁问题解决、索引失效分析、表锁问题解析、慢查询优化等数据库相关主题。同时,还提供了 Redis 缓存机制、数据结构和持久化机制的深入剖析。对于容器化技术,专栏介绍了 Docker 和 Kubernetes 的部署和管理。其他内容还包括 Linux 系统性能优化、Nginx 服务器配置和优化、Java 虚拟机调优、Spring Boot 微服务开发、Git 版本控制、Linux 网络配置和故障排除,以及 Python 数据分析实战。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】使用Docker与Kubernetes进行容器化管理
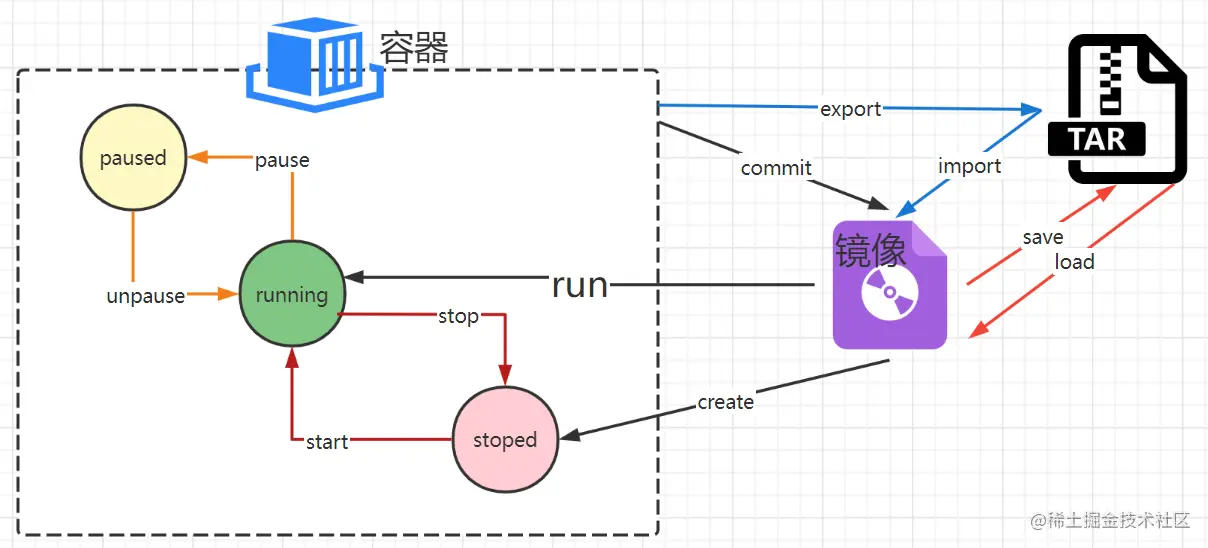
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】python云数据库部署:从选择到实施
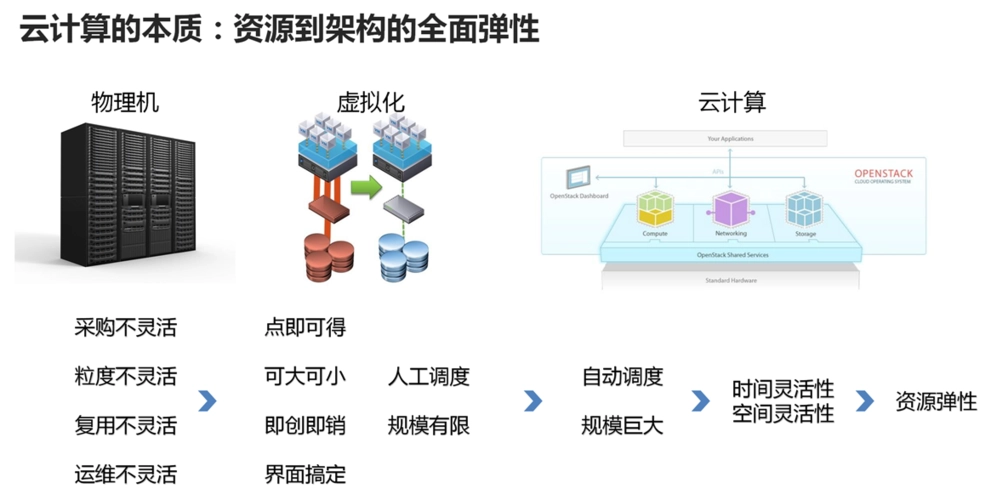
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】通过强化学习优化能源管理系统实战
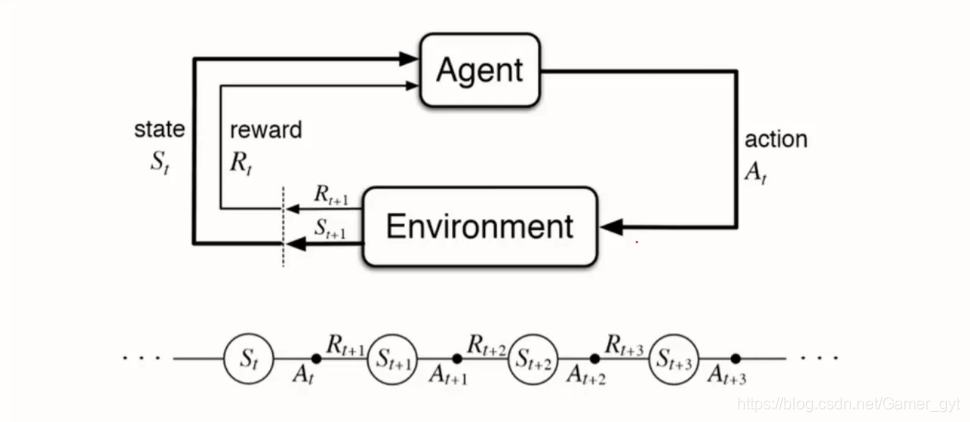
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】渗透测试的方法与流程

# 2.1 信息收集与侦察
信息收集是渗透测试的关键阶段,旨在全面了解目标系统及其环境。通过收集目标信息,渗透测试人员可以识别潜在的攻击向量并制定有效的攻击策略。
###
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )