ANSYS Fluent UDF 数据后处理:高级数据处理与可视化策略
发布时间: 2024-12-15 16:58:37 阅读量: 4 订阅数: 7 

参考资源链接:[2020 ANSYS Fluent UDF定制手册(R2版)](https://wenku.csdn.net/doc/50fpnuzvks?spm=1055.2635.3001.10343)
# 1. ANSYS Fluent UDF概述
在流体动力学研究和工程实践中,**ANSYS Fluent** 是一款广泛使用的计算流体动力学(CFD)软件,其用户自定义函数(UDF)功能为用户提供了强大的扩展能力,能够根据特定需求实现软件功能的定制。
## 1.1 UDF的功能和优势
UDF 允许用户通过 C 语言编程来实现对模拟过程的控制。这包括但不限于:定义边界条件、源项、材料属性以及自定义的数据处理过程。UDF 的优势在于能够实现软件自带功能无法直接完成的特定计算和分析。
## 1.2 UDF在CFD工作流程中的位置
在CFD的工作流程中,UDF主要用于预处理阶段的数据输入和初始化,求解阶段的控制以及后处理阶段的数据分析和可视化。UDF可以极大地提升模拟的灵活性和深度,是提高CFD模拟效率和质量的重要工具。
接下来的章节中,我们将深入探讨UDF的具体应用,例如在数据处理和优化中的应用、高级数据处理技术、可视化技巧,以及如何在实际中应用这些技巧来提高模拟的准确性和效率。此外,我们还会展望未来UDF的发展方向及其在新兴技术中的应用前景。
# 2. 数据处理基础理论
## 2.1 UDF中的数据结构
### 2.1.1 基本数据类型
在ANSYS Fluent UDF(User-Defined Functions)编程中,基本数据类型是构成更复杂数据结构的基础。基本数据类型主要包括整型(integer)、浮点型(float)、双精度浮点型(double)和字符型(character)。理解这些类型对于编写高效且准确的UDF至关重要。
**整型**(integer)通常用于表示没有小数部分的数值,例如计数器和索引值。ANSYS Fluent UDF中的整型变量占用内存空间较小,适用于需要整数运算的场景。
**浮点型**(float)和**双精度浮点型**(double)则用于表示含有小数部分的数值。在大多数工程计算中,这两个类型都是用来存储温度、压力、速度等连续变量的首选。浮点型相比双精度浮点型占用的内存空间较少,但其精度和范围也相对有限。双精度浮点型则提供了更高的精度和更大的数值范围,适用于更复杂或更精细的数值计算。
**字符型**(character)通常用于表示文本信息,比如字符串。在UDF中,字符型变量可以用来存储和处理文本数据,如描述性的变量名、文件路径等。
### 2.1.2 高级数据结构和操作
除了基本数据类型之外,ANSYS Fluent UDF还支持一系列的高级数据结构,包括数组、结构体、指针和自定义类型等。这些数据结构的引入极大地增加了UDF的表达能力和处理复杂数据的能力。
**数组**是同一数据类型元素的有序集合。在ANSYS Fluent UDF中,可以定义整型数组、浮点型数组等,它们适用于批量处理具有相同数据类型的数据。
**结构体**(struct)是一种将不同类型的数据组合在一起的方式。通过定义结构体,可以创建包含多个字段的复合数据类型,每个字段可以是不同的基本数据类型或自定义数据类型。结构体在组织相关数据时非常有用,例如定义一个包含速度矢量和压力值的流体粒子状态。
**指针**在UDF中提供了灵活的动态内存管理。通过指针,可以创建指向数据的引用,而不是数据的副本。这使得在处理大量数据或创建复杂数据结构时,能够节省内存并提高处理效率。
最后,ANSYS Fluent UDF还支持通过**预处理器宏**创建**自定义数据类型**。这种宏允许开发者定义自己的数据结构,从而扩展UDF的功能。通过预处理器宏,开发者可以定义模板化的数据类型,这在创建复杂的数据组织结构时特别有用。
代码块示例及其解析如下:
```c
#include "udf.h"
DEFINE Scalar場函数,用于定义新的自定义数据类型
DEFINE Scalar(udf_scalar_type, name, initial_value)
{
/* 定义数据类型 */
type = (int) initial_value;
/* 返回数据类型 */
return type;
}
```
在这个例子中,我们创建了一个名为 `udf_scalar_type` 的自定义标量类型,其初始值由 `initial_value` 参数指定。定义完毕后,我们使用 `(int) initial_value` 来初始化我们的数据类型。这个宏允许我们在ANSYS Fluent UDF中更灵活地定义和处理数据类型。
高级数据结构的运用不仅扩展了UDF的功能,也为处理复杂问题提供了更加丰富的工具。在随后的章节中,我们将深入探讨如何高效地使用这些结构进行数据筛选、分类和处理。
# 3. 高级数据处理技术
## 3.1 复杂数据的提取和转换
### 3.1.1 自定义数据提取方法
在处理复杂数据时,标准的数据处理方法可能无法满足特定的需求。因此,ANSYS Fluent UDF 提供了灵活的接口来自定义数据提取方法。这允许用户按照自己的算法和逻辑提取数据,从而更好地处理和分析结果。
代码块示例:
```c
DEFINE_ON_DEMAND(custom_extract)
{
/* 参数声明 */
Thread *t;
cell_t c;
real x[ND_ND]; /* ND_ND为维度常量,通常为2或3 */
real y;
/* 数据提取过程 */
t = RP_CELL_THREAD(c, t);
begin_c_loop(c, t)
{
C_CENTROID(x, c, t);
y = /* 计算或获取数据的代码 */;
/* 在此处可以进行自定义数据处理,例如提取、筛选、存储等操作 */
/* 例如,将数据存储到自定义数组或文件中 */
}
end_c_loop(c, t)
}
```
参数说明和代码逻辑:
- `DEFINE_ON_DEMAND` 宏用于定义一个按需执行的用户定义函数(UDF)。
- 在函数体内,我们声明了必要的变量,如 `Thread` 类型的指针 `t`,用于表示当前处理的单元格。
- `C_CENTROID` 宏用于获取当前单元格质心的坐标。
- `y` 变量用于存储提取的数据点。
## 3.1.2 数据类型转换技巧
在数据处理过程中,经常需要将数据从一种类型转换为另一种类型,以适应特定的分析需求。ANSYS Fluent UDF 支持多种数据类型,包括整数、浮点数和字符串等。转换数据类型时,需要注意精度损失和格式一致性问题。
代码块示例:
```c
DEFINETHREADINIT(thread_init_convert)
{
/* 参数声明 */
int int_var;
real float_var;
char *str_var;
char new_str[64];
/* 将整数转换为字符串 */
int_var = 123;
sprintf(new_str, "%d", int_var);
/* 将字符串转换为整数 */
str_var = "456";
sscanf(str_var, "%d", &int_var);
/* 将字符串转换为浮点数 */
str_var = "78.90";
sscanf(str_var, "%lf", &float_var);
}
```
参数说明和代码逻辑:
- `DEFINETHREADINIT` 宏用于初始化线程数据,这里用于演示数据类型转换。
- 使用 `sprintf` 函数将整数转换为字符串格式。
- 使用 `sscanf` 函数将字符串转换为整数或浮点数。
- 数据类型转换应该注意格式兼容性,以及在转换过程中可能发生的精度损失。
## 3.2 数据处理算法应用
### 3.2.1 插值与外推方法
在处理离散数据时,经常需要利用插值或外推方法来估计数据点之间的值。ANSYS Fluent UDF 内置了多种插值算法,如线性插值、多项式插值等,同时也支持自定义插值方法。
代码块示例:
```c
DEFINE_PROFILE(custom_interpolation, t, i)
{
/* 参数声明 */
real x[ND_ND];
real y;
real z = 0.0;
face_t f;
real profile[20]; /* 假设使用20个数据点作为插值基准 */
/* 插值逻辑 */
begin_f_loop(f, t)
{
F_CENTROID(x, f, t);
/* 使用自定义插值算法计算 y */
y = custom_interpolation_algorithm(x, profile);
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
提升Rational Rose顺序图效率的5个高级技巧

参考资源链接:[Rational Rose顺序图建模详细教程:创建、修改与删除](https://wenku.csdn.net/doc/6412b4d0be7fbd1778d40ea9?spm=1055.2635.3001.10343)
# 1. Rational Rose顺序图概述
## 简介
Rational Rose是IBM旗下的一款面向对象分析设计工具,广泛应用于软
【Prompt指令与用户体验】:设计高效AI互动体验的10大技巧

参考资源链接:[掌握ChatGPT Prompt艺术:全场景写作指南](https://wenku.csdn.net/doc/2b23iz0of6?spm=1055.2635.3001.10343)
# 1. Prompt指令的基础与用户交互
## 1.1 Prompt指令定义
在用户与人工智能(AI)系统交互中,Prompt指令充当着沟通桥梁的角色。它是一个明确的、可执行的命
快充技术实用攻略:IP5328优化策略提升功耗与效率
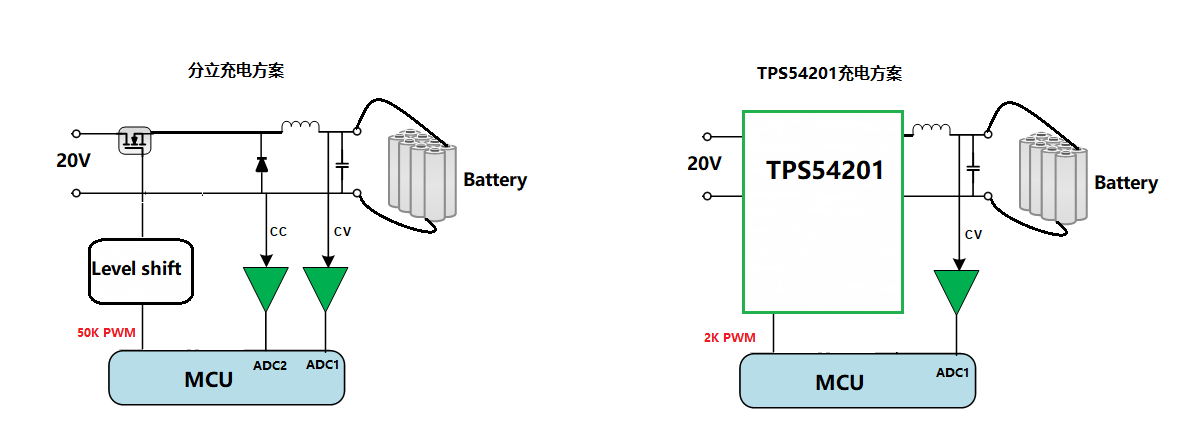
参考资源链接:[IP5328移动电源SOC:全能快充协议集成,支持PD3.0](https://wenku.csdn.net/doc/16d8bvpj05?spm=1055.2635.3001.10343)
# 1. 快充技术基础与IP5328芯片概述
## 1.1 快充技术
【iSecure Center 管理手册解读】:一步到位掌握iSecure Center运行管理秘籍

参考资源链接:[海康iSecure Center运行管理手册:部署、监控与维护详解](https://wenku.csdn.net/doc/2ibbrt393x?spm=1055.2635.3001.10343)
# 1. iSecure Center概述
在信息安全领域,iSecure Center作为一款集成的IT安全与合规管理解决方案,已被众多企业机构采用。它为IT安全团
SSD1309数据手册深度解读

参考资源链接:[SSD1309: 128x64 OLED驱动控制器技术数据](https://wenku.csdn.net/doc/6412b6efbe7fbd1778d48805?spm=1055.2635.3001.10343)
# 1. SSD1309概览
本章将对SSD1309 OLED显示控制器进行全面介绍。SSD1309是一种广泛使用的OLED显示驱动器,特别适用于需要高分辨率、低功耗和快速响应时间的应用
【Modbus TCP协议深度剖析】:汇川H5U高效实现指南
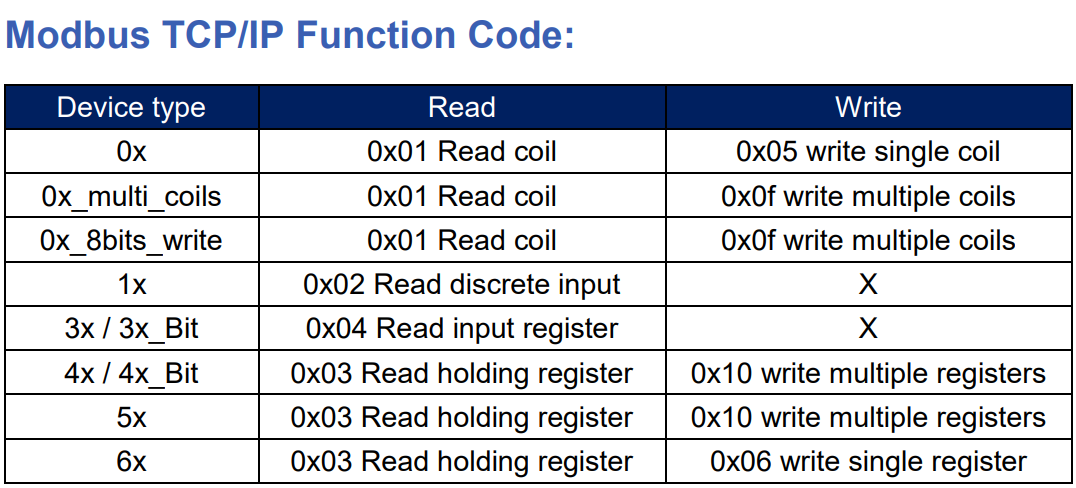
参考资源链接:[汇川H5U系列控制器Modbus通讯协议详解](https://wenku.csdn.net/doc/4bnw6asnhs?spm=1055.2635.3001.10343)
# 1. Modbus TCP协议概述
Modbus TCP协议是一种广泛应用于工业自动化领域的通信协议,它是Modbus协议的
VoNR性能革命:信令优化策略的7大关键步骤

参考资源链接:[5G VoNR信令流程详解与语音业务实施](https://wenku.csdn.net/doc/62a0bacs03?spm=1055.2635.3001.10343)
# 1. VoNR技术背景及信令概述
## 1.1 VoNR技术的发展和重要性
【TFT-OLED显示问题根源】:像素单元故障诊断与解决方案
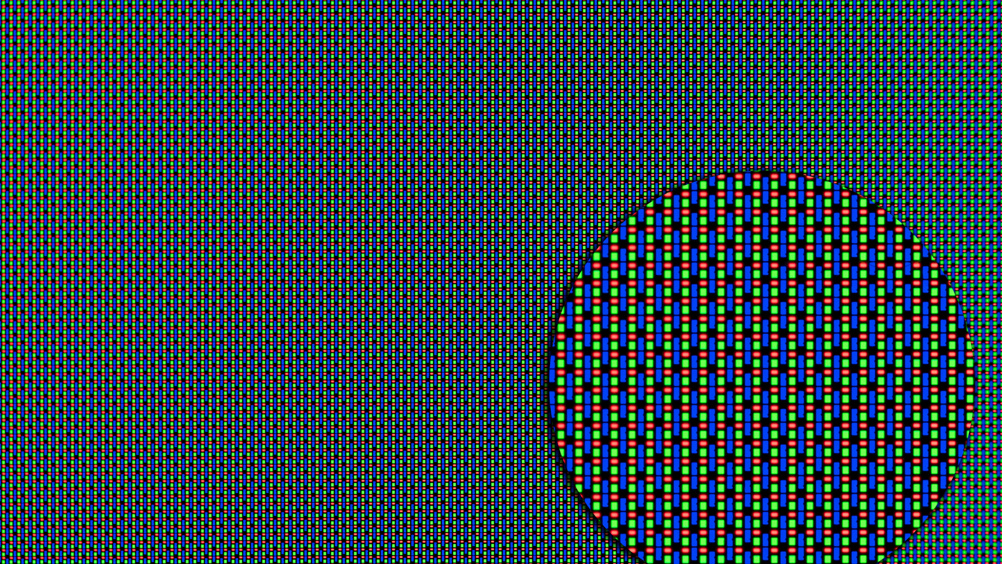
参考资源链接:[TFT-OLED像素单元与驱动电路:新型显示技术的关键](https://wenku.csdn.net/doc/645e5453543f8444888953bc?spm=105
海康综合安防平台1.7权限管理精讲:构建企业级安全防线

参考资源链接:[海康威视iSecureCenter综合安防平台1.7配置指南](https://wenku.csdn.net/doc/3a4qz526oj?spm=1055.2635.3001.10343)
# 1. 海康综合安防平
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )