Python面向对象编程:深入理解对象与类,揭秘代码设计的奥秘
发布时间: 2024-06-20 18:37:53 阅读量: 66 订阅数: 29 
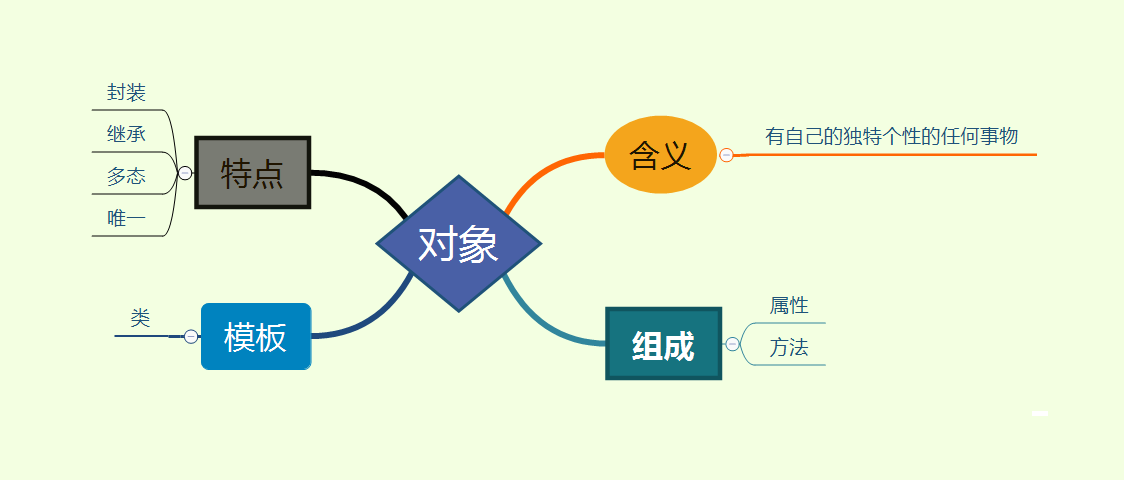
# 1. 面向对象编程(OOP)基础
面向对象编程(OOP)是一种编程范式,它将数据和行为组织成对象。对象是具有状态(数据)和行为(方法)的实体。OOP 的主要目标是提高代码的可重用性、可维护性和可扩展性。
OOP 的基本概念包括:
- **对象:** 数据和行为的封装。
- **类:** 对象的蓝图,定义了对象的属性和方法。
- **继承:** 允许类从其他类继承属性和方法。
- **多态性:** 允许对象以不同的方式响应相同的方法调用。
# 2. Python中的对象与类
### 2.1 对象的创建和属性
在Python中,对象是具有状态和行为的实体。对象的状态由其属性表示,而行为由其方法表示。要创建对象,可以使用`class`关键字定义一个类,然后使用`()`运算符实例化该类。
```python
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
person1 = Person("John", 30)
person2 = Person("Jane", 25)
```
在上面的代码中,我们定义了一个`Person`类,该类具有`name`和`age`属性。我们还创建了两个`Person`对象,`person1`和`person2`,并为它们分配了不同的属性值。
### 2.2 类的定义和继承
类是对象的模板,它定义了对象的属性和方法。要定义一个类,可以使用`class`关键字,后跟类名和冒号。类体包含类的属性和方法定义。
```python
class Person:
name = "Unknown"
age = 0
def __init__(self, name, age):
self.name = name
self.age = age
def get_name(self):
return self.name
def get_age(self):
return self.age
```
在上面的代码中,我们定义了一个`Person`类,它具有两个属性(`name`和`age`)和三个方法(`__init__`、`get_name`和`get_age`)。`__init__`方法是类的构造函数,它在创建对象时被调用。`get_name`和`get_age`方法用于获取对象的属性值。
继承允许一个类从另一个类继承属性和方法。要创建派生类,可以使用`class`关键字,后跟派生类名、冒号和基类名。
```python
class Employee(Person):
salary = 0
def __init__(self, name, age, salary):
super().__init__(name, age)
self.salary = salary
def get_salary(self):
return self.salary
```
在上面的代码中,我们定义了一个`Employee`类,它从`Person`类继承。`Employee`类具有`salary`属性和`get_salary`方法。
### 2.3 多态性和封装
多态性允许对象以不同的方式响应相同的消息。在Python中,多态性通过方法重写来实现。当派生类重写基类的方法时,派生类对象将以与基类对象不同的方式响应该方法。
```python
class Person:
def speak(self):
print("Hello")
class Employee(Person):
def speak(self):
print("Hello, I'm an employee")
```
在上面的代码中,`Person`类具有一个`speak`方法,它打印`"Hello"`。`Employee`类重写了`speak`方法,它打印`"Hello, I'm an employee"`。
封装将对象的属性和方法隐藏在类的内部。这允许类控制对这些属性和方法的访问。在Python中,封装通过访问修饰符(`public`、`protected`和`private`)来实现。
```python
class Person:
def __init__(self, name, age):
self.__name = name # 私有属性
self._age = age # 受保护的属性
self.salary = 0 # 公共属性
def get_name(self):
return self.__name
def get_age(self):
return self._age
```
在上面的代码中,`__name`属性是私有的,这意味着它只能在`Person`类中访问。`_age`属性受保护,这意味着它只能在`Person`类及其派生类中访问。`salary`属性是公共的,这意味着它可以在任何地方访问。
# 3. Python中的OOP设计模式**
### 3.1 单例模式
单例模式是一种设计模式,它确保一个类只有一个实例,并提供一个全局访问点。在Python中,可以使用以下代码实现单例模式:
```python
class Singleton:
_instance = None
def __new__(cls, *args, **kwargs):
if not cls._instance:
cls._instance = super(Singleton, cls).__new__(cls, *args, **kwargs)
return cls._instance
```
**逻辑分析:**
* `__new__`方法是类的构造方法,用于创建新实例。
* 如果`_instance`属性为`None`,表示还没有创建实例,则调用父类的`__new__`方法创建一个新实例并将其赋值给`_instance`属性。
* 否则,返回`_instance`属性,表示已经创建了实例。
### 3.2 工厂模式
工厂模式是一种设计模式,它提供了创建对象的接口,而不指定对象的具体类。在Python中,可以使用以下代码实现工厂模式:
```python
class Factory:
def create_product(self):
pass
class ConcreteFactory1(Factory):
def create_product(self):
return Product1()
class ConcreteFactory2(Factory):
def create_product(self):
return Product2()
class Product:
pass
class Product1(Product):
pass
class Product2(Product):
pass
```
**逻辑分析:**
* `Factory`类是抽象工厂类,它定义了创建产品的接口。
* `ConcreteFactory1`和`ConcreteFactory2`是具体工厂类,它们实现了`create_product`方法来创建不同的产品。
* `Product`类是抽象产品类,它定义了产品的接口。
* `Product1`和`Product2`是具体产品类,它们实现了`Product`类。
### 3.3 策略模式
策略模式是一种设计模式,它允许算法或行为在运行时动态更改。在Python中,可以使用以下代码实现策略模式:
```python
class Strategy:
def execute(self):
pass
class ConcreteStrategy1(Strategy):
def execute(self):
print("执行策略1")
class ConcreteStrategy2(Strategy):
def execute(self):
print("执行策略2")
class Context:
def __init__(self, strategy):
self.strategy = strategy
def execute_strategy(self):
self.strategy.execute()
```
**逻辑分析:**
* `Strategy`类是抽象策略类,它定义了执行策略的接口。
* `ConcreteStrategy1`和`ConcreteStrategy2`是具体策略类,它们实现了`execute`方法来执行不同的策略。
* `Context`类是上下文类,它持有策略对象并调用`execute_strategy`方法来执行策略。
# 4. Python中的OOP实践**
**4.1 数据结构的实现**
面向对象编程(OOP)在数据结构的实现中扮演着至关重要的角色。通过将数据和操作封装在对象中,OOP可以提高代码的可读性、可维护性和可重用性。
Python中提供了丰富的内置数据结构,如列表、元组、字典和集合。这些数据结构可以存储和组织各种类型的数据,并提供了方便的操作方法。
**代码块:**
```python
# 创建一个列表
my_list = [1, 2, 3, 4, 5]
# 访问列表中的元素
print(my_list[0]) # 输出:1
# 向列表中追加元素
my_list.append(6)
# 遍历列表
for item in my_list:
print(item) # 输出:1, 2, 3, 4, 5, 6
```
**逻辑分析:**
这段代码展示了如何使用列表存储和操作数据。`my_list`变量被初始化为一个包含数字的列表。然后,它访问列表的第一个元素(索引为0),向列表追加一个新元素,并遍历列表打印每个元素。
**4.2 图形用户界面的设计**
OOP在图形用户界面(GUI)的设计中也发挥着重要作用。通过将GUI组件(如按钮、文本框和菜单)封装在对象中,OOP可以简化GUI的开发和维护。
Python中提供了Tkinter库,用于创建跨平台的GUI应用程序。Tkinter中的每个GUI组件都是一个对象,具有自己的属性和方法。
**代码块:**
```python
import tkinter as tk
# 创建一个主窗口
root = tk.Tk()
# 创建一个按钮
button = tk.Button(root, text="点击我")
# 添加按钮到窗口
button.pack()
# 启动主事件循环
root.mainloop()
```
**逻辑分析:**
这段代码展示了如何使用Tkinter创建GUI应用程序。`root`变量是一个主窗口对象,`button`变量是一个按钮对象。按钮对象被添加到窗口中,然后启动主事件循环,它等待用户输入并响应事件。
**4.3 数据库连接和操作**
OOP在数据库连接和操作中也提供了便利。通过将数据库连接和查询操作封装在对象中,OOP可以简化数据库操作,提高代码的可重用性。
Python中提供了多种数据库连接库,如PyMySQL和psycopg2。这些库允许程序员连接到数据库,执行查询并获取结果。
**代码块:**
```python
import pymysql
# 连接到数据库
connection = pymysql.connect(host="localhost", user="root", password="password", database="my_database")
# 创建一个游标
cursor = connection.cursor()
# 执行一个查询
cursor.execute("SELECT * FROM users")
# 获取查询结果
results = cursor.fetchall()
# 关闭游标和连接
cursor.close()
connection.close()
```
**逻辑分析:**
这段代码展示了如何使用PyMySQL连接到数据库并执行查询。`connection`变量是一个数据库连接对象,`cursor`变量是一个游标对象,用于执行查询和获取结果。查询结果存储在`results`变量中,最后关闭游标和连接。
# 5. Python中的OOP高级应用
### 5.1 元类编程
**简介**
元类编程允许我们创建和修改类本身。它提供了对类的创建过程的控制,使我们能够动态地创建和修改类的行为。
**自定义元类**
要创建自定义元类,我们需要继承自 `type` 类。`type` 类是所有类的父类,因此自定义元类可以控制所有从它派生的类的行为。
```python
class MyMetaclass(type):
def __new__(cls, name, bases, attrs):
# 在这里修改类的属性和行为
# ...
return super().__new__(cls, name, bases, attrs)
```
**应用**
自定义元类可以用于各种目的,例如:
- 添加自动属性或方法
- 验证类属性
- 拦截类创建或销毁事件
### 5.2 协程和异步编程
**简介**
协程是一种轻量级的线程,它可以暂停和恢复执行。协程与异步编程一起使用,允许我们在不阻塞主线程的情况下执行长时间运行的任务。
**协程的创建**
协程使用 `async def` 关键字创建。它们返回一个 `asyncio.coroutine` 对象。
```python
async def my_coroutine():
# 协程代码
# ...
```
**异步编程**
异步编程使用协程来处理并发任务。它允许我们在不阻塞主线程的情况下执行长时间运行的任务。
```python
import asyncio
async def main():
# 创建协程
coroutine = my_coroutine()
# 运行协程
await asyncio.gather(coroutine)
```
### 5.3 分布式系统中的OOP
**简介**
OOP 在分布式系统中用于创建可扩展、可维护和可重用的组件。分布式系统中的 OOP 涉及使用面向服务的架构 (SOA) 和微服务。
**SOA**
SOA 是一种架构风格,它将应用程序分解为松散耦合的服务。这些服务通过消息传递进行通信。
**微服务**
微服务是一种轻量级的服务,它专注于执行单一任务。微服务通常使用 RESTful API 进行通信。
**应用**
OOP 在分布式系统中的应用包括:
- 创建可扩展和可维护的组件
- 促进代码重用
- 简化系统集成

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供一系列深入浅出的 Python 编程教程,涵盖从入门基础到高级应用的各个方面。专栏内容包括:
* Python 入门指南,带你从零基础迈入编程世界。
* 面向对象编程,揭秘代码设计的奥秘。
* 文件操作,释放数据管理的潜力。
* 网络编程,构建客户端和服务器应用。
* 数据库操作,连接、查询和更新数据库。
* 数据分析基础,探索数据洞察的基石。
* 机器学习算法,解锁人工智能的入门之钥。
* 深度学习应用,神经网络与图像识别。
* Web 框架,构建动态 Web 应用的利器。
* RESTful API 设计,构建可扩展的 Web 服务。
* Web 安全,保护你的 Web 应用免受攻击。
* 云计算基础,敲开云端世界的门。
* 云函数,在云端无服务器执行代码。
* 云存储,数据存储的云端堡垒。
* 系统管理,自动化任务,解放运维的双手。
* 日志分析,从日志数据中提取见解。
* 性能监控,跟踪和优化系统性能。
* 并发编程,解锁并行计算的威力。
* 分布式系统,构建可扩展和容错的应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言数据处理高级技巧:reshape2包与dplyr的协同效果
# 1. R语言数据处理概述
在数据分析和科学研究中,数据处理是一个关键的步骤,它涉及到数据的清洗、转换和重塑等多个方面。R语言凭借其强大的统计功能和包生态,成为数据处理领域的佼佼者。本章我们将从基础开始,介绍R语言数据处理的基本概念、方法以及最佳实践,为后续章节中具体的数据处理技巧和案例打下坚实的基础。我们将探讨如何利用R语言强大的包和
机器学习数据准备:R语言DWwR包的应用教程

# 1. 机器学习数据准备概述
在机器学习项目的生命周期中,数据准备阶段的重要性不言而喻。机器学习模型的性能在很大程度上取决于数据的质量与相关性。本章节将从数据准备的基础知识谈起,为读者揭示这一过程中的关键步骤和最佳实践。
## 1.1 数据准备的重要性
数据准备是机器学习的第一步,也是至关重要的一步。在这一阶
R语言数据透视表创建与应用:dplyr包在数据可视化中的角色

# 1. dplyr包与数据透视表基础
在数据分析领域,dplyr包是R语言中最流行的工具之一,它提供了一系列易于理解和使用的函数,用于数据的清洗、转换、操作和汇总。数据透视表是数据分析中的一个重要工具,它允许用户从不同角度汇总数据,快速生成各种统计报表。
数据透视表能够将长格式数据(记录式数据)转换为宽格式数据(分析表形式),从而便于进行
【R语言caret包多分类处理】:One-vs-Rest与One-vs-One策略的实施指南
# 1. R语言与caret包基础概述
R语言作为统计编程领域的重要工具,拥有强大的数据处理和可视化能力,特别适合于数据分析和机器学习任务。本章节首先介绍R语言的基本语法和特点,重点强调其在统计建模和数据挖掘方面的能力。
## 1.1 R语言简介
R语言是一种解释型、交互式的高级统计分析语言。它的核心优势在于丰富的统计包
R语言复杂数据管道构建:plyr包的进阶应用指南

# 1. R语言与数据管道简介
在数据分析的世界中,数据管道的概念对于理解和操作数据流至关重要。数据管道可以被看作是数据从输入到输出的转换过程,其中每个步骤都对数据进行了一定的处理和转换。R语言,作为一种广泛使用的统计计算和图形工具,完美支持了数据管道的设计和实现。
R语言中的数据管道通常通过特定的函数来实现
【R语言数据包mlr的深度学习入门】:构建神经网络模型的创新途径

# 1. R语言和mlr包的简介
## 简述R语言
R语言是一种用于统计分析和图形表示的编程语言,广泛应用于数据分析、机器学习、数据挖掘等领域。由于其灵活性和强大的社区支持,R已经成为数据科学家和统计学家不可或缺的工具之一。
## mlr包的引入
mlr是R语言中的一个高性能的机器学习包,它提供了一个统一的接口来使用各种机器学习算法。这极大地简化了模型的选择、训练
【R语言Capet包集成挑战】:解决数据包兼容性问题与优化集成流程
# 1. R语言Capet包集成概述
随着数据分析需求的日益增长,R语言作为数据分析领域的重要工具,不断地演化和扩展其生态系统。Capet包作为R语言的一个新兴扩展,极大地增强了R在数据处理和分析方面的能力。本章将对Capet包的基本概念、功能特点以及它在R语言集成中的作用进行概述,帮助读者初步理解Capet包及其在
从数据到洞察:R语言文本挖掘与stringr包的终极指南

# 1. 文本挖掘与R语言概述
文本挖掘是从大量文本数据中提取有用信息和知识的过程。借助文本挖掘,我们可以揭示隐藏在文本数据背后的信息结构,这对于理解用户行为、市场趋势和社交网络情绪等至关重要。R语言是一个广泛应用于统计分析和数据科学的语言,它在文本挖掘领域也展现出强大的功能。R语言拥有众多的包,能够帮助数据科学
【formatR包错误处理】:解决常见问题,确保数据分析顺畅

# 1. formatR包概述与错误类型
在R语言的数据分析生态系统中,formatR包是不可或缺的一部分,它主要负责改善R代码的外观和结构,进而提升代码的可读性和整洁度。本章节首先对formatR包进行一个基础的概述,然后详细解析在使用formatR包时常见的错误类型,为后续章节的深
时间数据统一:R语言lubridate包在格式化中的应用

# 1. 时间数据处理的挑战与需求
在数据分析、数据挖掘、以及商业智能领域,时间数据处理是一个常见而复杂的任务。时间数据通常包含日期、时间、时区等多个维度,这使得准确、高效地处理时间数据显得尤为重要。当前,时间数据处理面临的主要挑战包括但不限于:不同时间格式的解析、时区的准确转换、时间序列的计算、以及时间数据的准确可视化展示。
为应对这些挑战,数据处理工作需要满足以下需求:
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )