详解MapReduce框架中的Reducer组件
发布时间: 2023-12-16 16:08:09 阅读量: 41 订阅数: 21 

(175797816)华南理工大学信号与系统Signal and Systems期末考试试卷及答案
## 1. 第一章:MapReduce框架简介
### 1.1 MapReduce概述
MapReduce是一种用于处理大规模数据并发运算的编程模型和软件框架。它最初由Google提出,用于支持分布式计算和并行处理。MapReduce将计算过程分为两个主要阶段:Map阶段和Reduce阶段。在Map阶段,数据被分割为若干个小的数据块,并由多个Map任务并行处理。在Reduce阶段,Map任务的输出结果被合并和聚合,生成最终的计算结果。
### 1.2 MapReduce框架的工作原理
MapReduce框架主要由两个组件组成:Mapper和Reducer。Mapper负责解析输入数据并进行初步处理,将输入数据转化为键值对形式。Reducer负责对Mapper输出的键值对进行排序、分组和计算,最终生成最终的输出结果。
MapReduce框架的工作流程如下:
1. 输入数据被切分成多个输入数据块。
2. Map任务并行处理输入数据块,生成中间结果。
3. 中间结果被分区、排序和分组,并传输给Reducer任务。
4. Reducer任务并行处理中间结果,生成最终的输出结果。
MapReduce框架通过将计算任务分解成多个独立的子任务,并行处理这些子任务,以实现对大规模数据的高效处理和计算。
### 1.3 MapReduce框架中的Mapper和Reducer组件
Mapper和Reducer是MapReduce框架中两个核心的组件。它们分别负责处理输入数据并生成中间结果,以及对中间结果进行合并和计算。
Mapper组件的主要任务是解析输入数据并进行初步处理,将输入数据转化为键值对形式。Mapper将输入数据拆分成若干个小的数据块,在Map任务中被并行处理。Mapper的输出结果将被传输给Reducer组件进行进一步的计算。
Reducer组件的主要任务是对Mapper输出的中间结果进行排序、分组和计算,生成最终的输出结果。Reducer接收来自多个Mapper的输出结果,并按照键值对的键进行排序和分组。然后,Reducer将每个键对应的多个值进行合并和计算,生成最终的输出结果。
MapReduce框架中的Mapper和Reducer组件紧密配合,共同完成大规模数据的处理和计算任务。它们的灵活性和扩展性使得MapReduce框架成为处理大数据的重要工具和平台。
详细代码实现请查看后续章节。
## 2. 第二章:Reducer组件概述
2.1 Reducer的作用和功能
2.2 Reducer的工作流程
2.3 Reducer的输入和输出
### 第三章:Reducer组件的实现细节
在MapReduce框架中,Reducer组件承担着最后的数据处理和聚合任务。它接收来自Mapper组件的中间结果,并将它们合并、排序并输出最终的结果。下面将详细介绍Reducer组件的实现细节。
#### 3.1 Reducer的初始化
在Reducer组件开始处理数据之前,首先会执行一次初始化操作。这个过程包括设置Reducer的环境和配置,为Reducer准备一些必要的资源。通常,初始化的代码会在Reducer类的`setup()`方法中实现。
以下是Java语言中设置Reducer的环境和配置的示例代码:
```java
public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void setup(Context context) {
// 初始化代码
// 设置Reducer的环境和配置
// 准备必要的资源
}
// 其他方法和逻辑处理
}
```
#### 3.2 Reducer的排序和分组
在Reducer组件中,数据的排序和分组是非常重要的步骤。Reducer需要将相同key的数据进行合并和聚合,并输出相应的结果。MapReduce框架会自动按照key的升序将数据传递给Reducer,确保相同key的数据会被传递到同一个Reducer实例中。
以下是Python语言中对数据进行排序和分组的示例代码:
```python
from operator import itemgetter
import sys
current_word = None
current_count = 0
for line in sys.stdin:
word, count = line.strip().split('\t')
count = int(count)
if current_word == word:
current_count += count
else:
if current_word:
print(current_word, current_count)
current_word = word
current_count = count
if current_word == word:
print(current_word, current_count)
```
#### 3.3 Reducer的reduce()方法
Reducer的核心处理逻辑通常是在`reduce()`方法中实现的。在这个方法中,Reducer会对传入的相同key的数据进行聚合和处理,并输出最终的结果。
以下是Go语言中实现Reducer的reduce()方法的示例代码:
```go
import (
"fmt"
"os"
"bufio"
"strconv"
)
func reduce(inputFile string, outputFile string) error {
file, err := os.Open(inputFile)
if err != nil {
return err
}
defer file.Close()
scanner := bufio.NewScanner(file)
counts := make(map[string]int)
for scanner.Scan() {
word := scanner.Text()
counts[word]++
}
fileOut, err := os.Create(outputFile)
if err !
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏着重介绍MapReduce WordCount程序的各个方面,从基础概念解析到高级技巧应用,全面深入地解析了Hadoop MapReduce框架中的各个组件。文章包括了初识Hadoop MapReduce框架、使用Java编写MapReduce WordCount示例程序、深入理解Mapper和Reducer组件、优化程序效率以及高级技巧应用等内容。此外,还涵盖了词频统计算法、InputFormat与OutputFormat、分块处理、分布式缓存、任务调度与资源管理、异常处理与错误处理等方面。通过本专栏的学习,读者将能全面掌握MapReduce框架中的关键概念和实际应用技巧,为处理大数据提供了深入而全面的指导。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
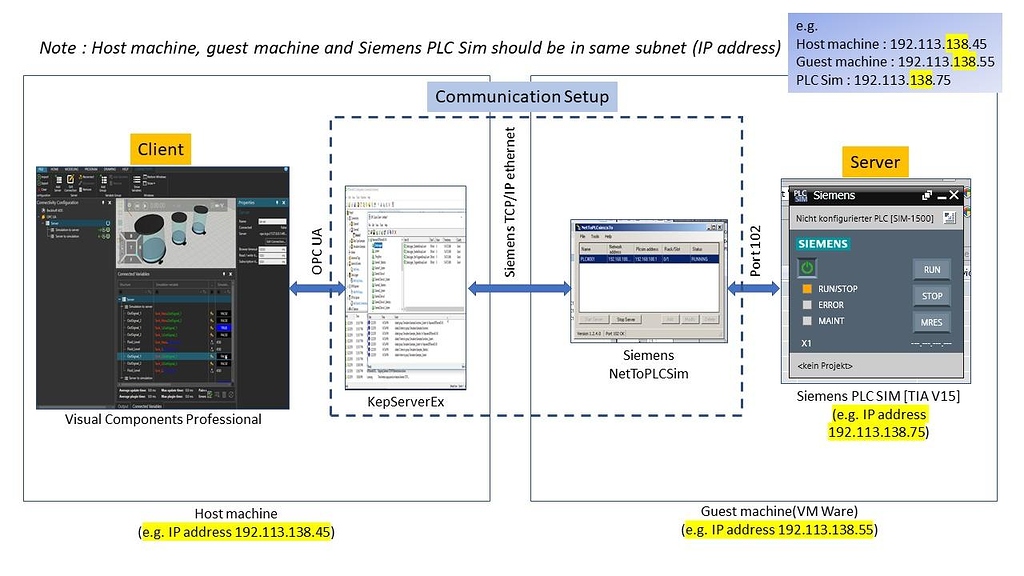
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
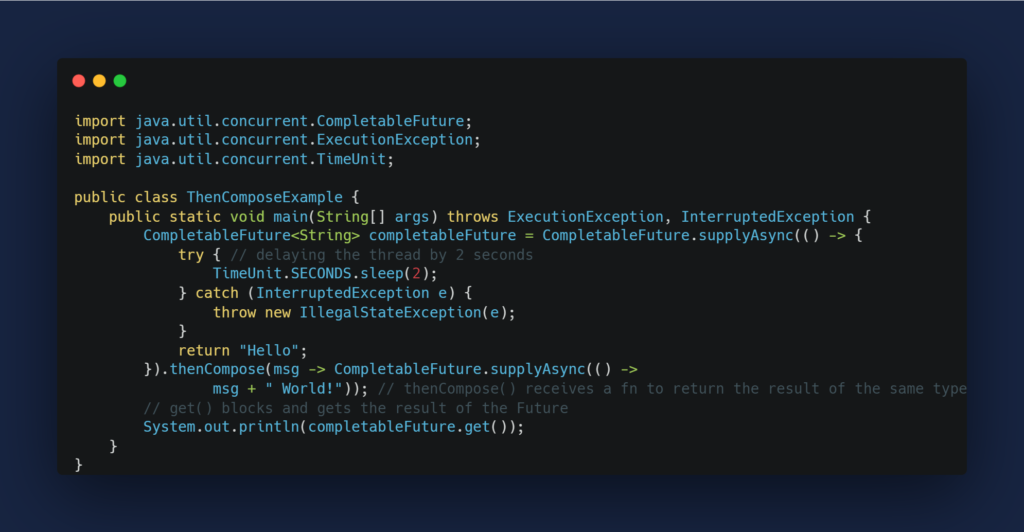
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
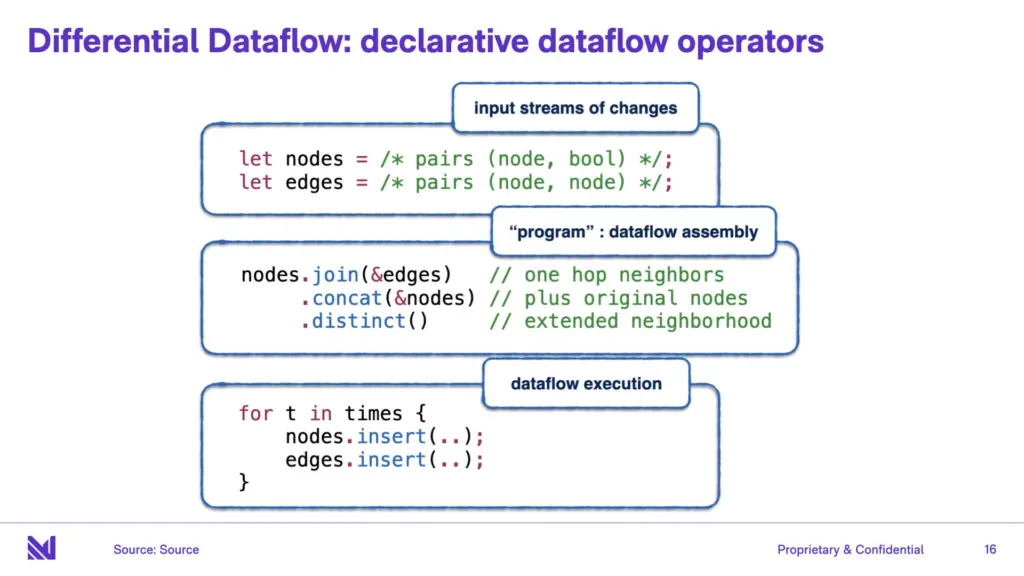
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )