【C++ Lambda表达式进阶】:打造极致性能与可读性的8种方法
发布时间: 2024-10-20 05:55:29 阅读量: 66 订阅数: 36 

C++ 中lambda表达式的编译器实现原理

# 1. C++ Lambda表达式简介
在现代C++编程中,Lambda表达式是一种快捷编写内联函数对象的方式,让开发者能够更方便地实现封装、传递、和使用函数式编程技术。它允许我们以更少的代码量完成任务,同时提高代码的可读性和模块性。
Lambda表达式的基本语法包括一个捕获列表(可以为空),一个可选的参数列表、一个可选的异常声明,以及一个可选的尾置返回类型,其核心是一个隐式的函数调用操作符。这种表达式形式的引入,使得C++在处理短小的匿名函数时与其它语言如JavaScript或Python一样灵活。
例如,一个简单的Lambda表达式可以这样书写:
```cpp
auto simpleLambda = []() {
std::cout << "Hello, Lambda!";
};
```
在上述例子中,我们定义了一个无参数的Lambda表达式`simpleLambda`,它没有捕获任何外部变量。这个Lambda可以直接调用,执行其内部的代码块。这种简洁的定义方式使得Lambda表达式非常适合用在需要快速定义函数对象的场景,如STL算法中对集合进行操作时传递自定义行为。
# 2. Lambda表达式的性能优化
性能优化是软件开发中不可或缺的环节,特别是在资源受限的环境中,优化Lambda表达式的性能可以显著提升程序的运行效率和资源利用率。本章节将从Lambda表达式的内部机制开始,探讨如何减少Lambda表达式的开销,以及如何利用模板和STL算法提高效率。
## 2.1 了解Lambda表达式的内部机制
### 2.1.1 Lambda表达式与闭包
Lambda表达式是一种非常灵活的定义匿名函数的方式,它们通常用于需要函数对象但不想显式定义函数对象类的场景。在C++中,Lambda表达式实际上会创建一个闭包对象,即一个临时的、匿名的函数对象。闭包是一种包含函数和该函数作用域中变量环境的组合体。
当Lambda表达式被创建时,编译器会根据捕获列表生成一个闭包类。捕获列表中的变量会根据值或者引用的方式被存储在闭包对象中。值捕获会复制变量到闭包对象中,而引用捕获则会创建一个到原始变量的引用。
### 2.1.2 Lambda表达式的存储和类型
Lambda表达式的类型是独特的,每一条Lambda表达式都有自己的闭包类型。这种类型是编译器在编译时自动生成的,因此我们通常无法直接引用。然而,可以使用`decltype`关键字或者`std::function`来获取或者操作这个类型。
例如,使用`decltype`可以获取与Lambda表达式相同类型的类型:
```cpp
auto lambda = []() { return 42; };
decltype(lambda) another_lambda;
another_lambda = []() { return 24; };
```
而`std::function`则提供了一个通用的函数对象封装器,可以接受任何可调用对象,包括Lambda表达式:
```cpp
std::function<int()> func = []() { return 42; };
```
## 2.2 减少Lambda表达式的开销
### 2.2.1 使用引用捕获代替值捕获
Lambda表达式的开销主要来自于捕获的数据。如果使用值捕获,每次调用Lambda表达式时,都会复制这些数据。当数据量大或者复制开销较高时,这会显著影响性能。
相比之下,引用捕获则通过引用传递数据,避免了复制。引用捕获的方式能够减少内存的占用和提高数据传递的效率。但要注意的是,引用捕获要确保在Lambda表达式生命周期内,所引用的对象一直有效。
```cpp
int x = 42;
auto lambda = [&]() { return x; }; // 引用捕获
```
### 2.2.2 减少捕获列表的长度和复杂性
捕获列表中的变量越多,闭包对象就越复杂,其构造和销毁的开销也就越大。因此,应当尽量减少捕获列表中的变量。只有当需要在Lambda内部使用这些变量时才添加到捕获列表中。
此外,如果Lambda表达式仅需要某个变量的副本,而不需要修改它,那么应该使用值捕获而不是引用捕获。这样可以避免潜在的悬挂引用问题。
### 2.2.3 优化函数调用操作符
Lambda表达式重载了函数调用操作符operator(),这个操作符的实现方式直接影响了Lambda表达式的调用开销。在实现自定义操作符时,应当尽可能地简洁和高效。
例如,如果Lambda表达式仅用于简单的计算,可以避免复杂的控制流和不必要的内存操作。在进行性能敏感的操作时,甚至可以考虑使用内联汇编代码。
```cpp
auto lambda = [](int x) -> int {
// 使用内联汇编优化性能
// asm这部分通常是非可移植的,仅作为示例
__asm__("movl %%eax, %%ebx\n\t" : : "a" (x));
return x * x;
};
```
## 2.3 利用模板和STL算法提高效率
### 2.3.1 模板编程的优势
模板编程是C++的一个强大特性,它允许函数和类在不指定具体类型的情况下进行编译。模板能够确保代码的通用性和灵活性,同时在编译时期进行类型推导和优化,从而提高运行时的性能。
将Lambda表达式与模板结合,可以在编译时期解决Lambda的类型问题,避免了运行时的类型检查开销。此外,编译器还能对模板代码进行内联优化,减少函数调用的开销。
### 2.3.2 结合STL算法的Lambda表达式使用
STL(标准模板库)提供了大量高效的数据结构和算法。将Lambda表达式与STL算法结合,可以编写出既简洁又高效的代码。特别是对于一些复杂的数据处理和转换操作,STL算法提供了多种选择,而Lambda表达式则提供了强大的自定义操作能力。
例如,可以使用`std::transform`算法和Lambda表达式一起对容器中的每个元素进行处理:
```cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
std::transform(numbers.begin(), numbers.end(), numbers.begin(),
[](int x) { return x * x; }); // 将每个元素平方
```
使用模板和STL算法与Lambda表达式结合,不仅能提高代码的运行效率,还能增加代码的可读性和可维护性。
```mermaid
flowchart LR
A[开始] --> B[定义Lambda表达式]
B --> C[结合STL算法]
C --> D[执行数据处理]
D --> E[性能优化]
E --> F[结束]
```
结合了模板和STL算法的Lambda表达式示例代码及其执行逻辑分析:
```cpp
#include <vector>
#include <algorithm>
#include <iostream>
int main() {
std::vector<int> data = {1, 2, 3, 4, 5};
// 使用模板和STL算法,结合Lambda表达式进行数据处理
std::transform(data.begin(), data.end(), data.begin(),
[](int x) { return x * x; });
// 输出处理后的数据
for (int val : data) {
std::cout << val << ' ';
}
std::cout << std::endl;
return 0;
}
```
在上述代码中,Lambda表达式作为参数传递给`std::transform`函数,对容器`data`中的每个元素进行了平方计算。这个过程没有显式的循环语句,代码的可读性和简洁性都得到了提高。同时,编译器能够对模板代码和Lambda表达式进行优化,使得整个处理过程效率更高。
```table
| 性能优化策略 | 说明 |
| --- | --- |
| 使用引用捕获 | 减少数据复制开销 |
| 简化捕获列表 | 减少闭包对象的复杂性和大小 |
| 优化函数调用操作符 | 提高Lambda表达式内部执行效率 |
| 结合模板和STL算法 | 提升代码通用性和编译时优化 |
```
# 3. Lambda表达式的可读性提升
Lambda表达式在现代C++中已成为一种不可或缺的语言特性。它们提供了一种快速、简洁且强大的方式来定义匿名函数对象。然而,随着功能的丰富性增加,代码的可读性可能会受到挑战。如何在保持Lambda表达式的简洁和功能性的同时,提升其可读性成为了开发者必须面对的问题。本章将深入探讨如何通过多种技巧和最佳实践来实现这一目标。
## 3.1 精简Lambda表达式的写法
Lambda表达式的可读性首先取决于其简洁性。一个简洁的Lambda表达式能够更加直观地传达其意图和功能,减少维护成本,并降低阅读难度。
### 3.1.1 简化参数列表
参数列表是Lambda表达式的一个核心部分,过度复杂的参数列表会使得代码难以理解。在C++14之后,编译器提供了对初始化捕获的支持,这允许我们以更简洁的方式传递参数。
例如,我们有以下的代码片段:
```cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
int adder = 10;
auto func = [adder](int number) {
return number + adder;
};
for (auto& num : numbers) {
num = func(num);
}
```
在C++14中,我们可以使用初始化捕获来简化这个过程:
```cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
auto adder = 10;
auto func = [adder](auto number) { return number + adder; };
for (auto& num : numbers) {
num = func(num);
}
```
在这个例子中,我们不仅简化了参数列表,还将参数的类型推导给了编译器,这使得Lambda表达式更加简洁。
### 3.1.2 使用auto关键字减少冗余
在C++14中,`auto`关键字不仅可以用在变量声明中,还可以用在Lambda表达式的参数中。这有助于减少参数类型的重复声明,尤其在使用复杂的数据结构时效果明显。
例如,使用STL中的迭代器作为参数:
```cpp
std::vector<std::string> words = {"one", "two", "three"};
std::for_each(words.begin(), words.end(),
[](const std::string& word) {
std::cout << word << std::endl;
});
```
可以重写为:
```cpp
std::vector<std::string> words = {"one", "two", "three"};
std::for_each(words.begin(), words.end(),
[](auto& word) { // 注意这里的auto
std::cout << word << std::endl;
});
```
在使用`auto`关键字后,代码更加简洁,且易读性更强,因为阅读者无需关注参数的具体类型。
## 3.2 利用尾置返回类型增强Lambda表达式
尾置返回类型是C++14中引入的一个特性,它允许开发者在参数列表之后明确指定函数的返回类型。这一特性在定义Lambda表达式时尤其有用。
### 3.2.1 尾置返回类型的解释
尾置返回类型的基本语法是`auto`关键字后面跟着一个尾置的`->`符号和返回类型。例如:
```cpp
auto func = [](int x, int y) -> int {
return x + y;
};
```
在上面的例子中,返回类型`int`被明确地放在参数列表之后,这有助于编译器和阅读代码的人更清楚地知道函数将返回什么类型。
### 3.2.2 如何使用尾置返回类型提高代码可读性
尾置返回类型能够提高Lambda表达式的可读性,特别是在复杂表达式中。例如,当我们需要返回一个复杂的类型时,如一个容器的迭代器:
```cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
auto it = std::find_if(numbers.begin(), numbers.end(),
[](int number) -> std::vector<int>::iterator {
return number == 3;
});
```
在这个例子中,我们知道Lambda表达式返回的是一个`std::vector<int>::iterator`类型的对象。通过尾置返回类型,我们不仅能够清晰地了解返回值的类型,而且还可以利用`auto`来简化代码:
```cpp
std::vector<int> numbers = {1, 2, 3, 4, 5};
auto it = std::find_if(numbers.begin(), numbers.end(),
[](int number) -> auto {
return number == 3 ? numbers.begin() : numbers.end();
});
```
## 3.3 组织和重构Lambda表达式
随着项目规模的增长,Lambda表达式可能会变得越来越复杂。因此,组织和重构这些表达式显得尤为重要。
### 3.3.1 将复杂Lambda表达式分解为简单部分
一个复杂且长的Lambda表达式可能会导致代码难以理解和维护。将Lambda分解为多个更小的、更简单的Lambda表达式是提高可读性的好方法。
例如,我们有一个比较复杂的排序操作,可以分解如下:
```cpp
auto complex_comparator = [](auto& a, auto& b) {
if (a.some_complicated_attribute() > b.some_complicated_attribute()) {
return true;
} else {
return false;
}
};
std::sort(v.begin(), v.end(), complex_comparator);
```
可以分解为:
```cpp
auto attribute_comparator = [](auto& a, auto& b) {
return a.some_complicated_attribute() > b.some_complicated_attribute();
};
std::sort(v.begin(), v.end(), attribute_comparator);
```
在上述重构过程中,我们创建了一个专门用于比较属性的Lambda表达式`attribute_comparator`,这使得排序操作的意图更清晰。
### 3.3.2 利用函数对象和结构化绑定优化代码结构
函数对象可以被用来代替Lambda表达式,它们提供了另一种方式来组织复杂的逻辑。此外,C++17引入的结构化绑定也可以用来简化和增强代码的可读性。
考虑如下的代码示例:
```cpp
std::map<std::string, int> frequencies = {{"one", 1}, {"two", 2}, {"three", 3}};
for (auto& [word, frequency] : frequencies) {
std::cout << word << ": " << frequency << std::endl;
}
```
在这个例子中,我们使用了结构化绑定来迭代映射中的键值对,使得代码既简洁又直观。
综上所述,通过精简Lambda表达式的写法、利用尾置返回类型以及合理地组织和重构Lambda表达式,开发者能够显著提高代码的可读性,从而使项目更加健壮和易于维护。随着这些技巧的熟练运用,开发者可以在保持Lambda表达式功能性的同时,确保代码的清晰和简洁。
# 4. Lambda表达式在实际项目中的应用
## 4.1 多线程编程中的Lambda表达式
Lambda表达式在多线程编程中的应用是现代C++编程中常见的模式之一。它们以其简洁和直观性大大简化了并发代码的编写。
### 4.1.1 Lambda表达式与std::thread
在使用`std::thread`创建线程时,经常需要传递一些参数给线程函数。Lambda表达式可以用于这种情况,它们可以直接捕获变量,而无需显式地传递。这使得代码更加清晰和简洁。
```cpp
#include <thread>
#include <iostream>
void threadTask(int value) {
std::cout << "The value is: " << value << std::endl;
}
int main() {
int value = 10;
std::thread t([](int value){ threadTask(value); }, value);
t.join();
return 0;
}
```
在上述代码中,Lambda表达式`[](int value) { threadTask(value); }`捕获了局部变量`value`并传递给`threadTask`函数。这比使用传统函数指针或函数对象来创建线程要简洁得多。
### 4.1.2 Lambda表达式与std::future和std::async
`std::async`和`std::future`是C++11中引入的用于异步操作的工具,它们可以用来实现后台任务的并发执行。Lambda表达式与`std::async`结合使用时,能够有效地启动异步任务并获取它们的结果。
```cpp
#include <iostream>
#include <future>
#include <thread>
int compute(int x) {
std::this_thread::sleep_for(std::chrono::seconds(1));
return x * x;
}
int main() {
auto result = std::async(std::launch::async, compute, 42);
std::cout << "Result: " << result.get() << std::endl;
return 0;
}
```
在这个例子中,`compute`函数被传递给`std::async`,它返回一个`std::future`对象。通过调用`get`方法,主线程会等待异步任务完成并获取结果。使用Lambda表达式,可以进一步简化异步操作的代码。
## 4.2 事件驱动编程中的Lambda表达式
Lambda表达式在事件驱动编程模式中的应用,主要体现在事件处理器的定义上。它们提供了一种优雅的方式来绑定事件和处理逻辑。
### 4.2.1 Lambda表达式与事件处理
Lambda表达式可以捕捉特定事件并提供处理逻辑,如按钮点击、键盘输入等。
```cpp
#include <iostream>
#include <functional>
int main() {
// 假设这是按钮点击事件
auto buttonClicked = [](int data) {
std::cout << "Button clicked with data: " << data << std::endl;
};
// 假设这是键盘输入事件
auto keyInput = [](char key) {
std::cout << "Key input: " << key << std::endl;
};
// 模拟事件触发
buttonClicked(123);
keyInput('a');
return 0;
}
```
在这段代码中,两个Lambda表达式分别用于模拟按钮点击和键盘输入事件的处理。在实际事件驱动的应用中,它们会被绑定到相应的事件监听器上。
### 4.2.2 设计模式中的Lambda表达式应用
在某些设计模式中,如观察者模式,Lambda表达式可以作为回调函数使用,允许在观察者收到通知时执行特定操作。
```cpp
#include <iostream>
#include <vector>
class Observer {
public:
using Callback = std::function<void()>;
void onNotify(const Callback& callback) {
if (callback) {
callback();
}
}
};
void lambdaCallback() {
std::cout << "Lambda callback called!" << std::endl;
}
int main() {
Observer observer;
observer.onNotify(lambdaCallback);
return 0;
}
```
在这个例子中,`Observer`类有一个`onNotify`方法,它接受一个回调函数作为参数。Lambda表达式`lambdaCallback`可以作为回调函数直接传递给`onNotify`方法。
## 4.3 数据处理和分析中的Lambda表达式
Lambda表达式非常适合在数据处理和分析任务中使用,它们可以与算法库如`<algorithm>`和`<numeric>`结合,以提供简洁的数据操作方式。
### 4.3.1 结合算法库的数据处理
借助Lambda表达式,可以轻松地在算法库函数中插入自定义逻辑,如排序、过滤等。
```cpp
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 使用std::remove_if和Lambda表达式移除偶数
auto newEnd = std::remove_if(numbers.begin(), numbers.end(), [](int i){ return i % 2 == 0; });
numbers.erase(newEnd, numbers.end());
for (int num : numbers) {
std::cout << num << " ";
}
std::cout << std::endl;
return 0;
}
```
### 4.3.2 使用Lambda表达式进行数据分析的案例研究
在实际项目中,Lambda表达式可以用于实现复杂的分析逻辑。例如,在金融行业中,分析市场数据时可能需要应用各种复杂的业务规则。
```cpp
#include <iostream>
#include <vector>
#include <functional>
int main() {
std::vector<double> stockPrices = {10.2, 11.5, 9.8, 13.6, 11.0};
// 使用Lambda表达式来定义一个价格过滤器
auto priceFilter = [](double price) -> bool { return price > 10.0; };
// 使用std::remove_if来移除不符合价格标准的元素
auto newEnd = std::remove_if(stockPrices.begin(), stockPrices.end(), priceFilter);
stockPrices.erase(newEnd, stockPrices.end());
for (double price : stockPrices) {
std::cout << price << " ";
}
std::cout << std::endl;
return 0;
}
```
在这个案例中,Lambda表达式`priceFilter`定义了一个价格过滤器,用于移除低于10的股票价格。这是一个数据筛选的应用示例。
通过这些例子可以看到,Lambda表达式在多线程编程、事件驱动编程、以及数据处理和分析中的广泛应用,展示了其在实际项目中强大的实用性和灵活性。
# 5. Lambda表达式的进阶主题
Lambda表达式不仅仅是一种简洁的代码编写方式,它们还是C++语言强大抽象能力的体现。随着C++标准的更新,Lambda表达式的功能变得越来越丰富和强大。本章将深入探讨Lambda表达式的几个高级主题,包括泛型Lambda表达式、捕获与生命周期以及Lambda表达式的调试和维护。
## 5.1 泛型Lambda表达式与概念
### 5.1.1 泛型Lambda的基础知识
在C++14之前,Lambda表达式并不是真正的泛型。它们依赖于模板,需要在每次使用时都声明模板参数。然而,从C++14开始,Lambda表达式可以拥有自己的模板参数,这被称为泛型Lambda表达式。泛型Lambda表达式使用`auto`关键字声明参数类型,从而实现真正的类型推导。
例如,下面的泛型Lambda表达式定义了一个接收任意类型参数的函数对象:
```cpp
auto identity = [](auto x) { return x; };
```
这个`identity`可以接受任何类型的参数,并将其原样返回,无需指定具体类型。
### 5.1.2 结合C++20概念的泛型Lambda表达式
C++20引入了概念(Concepts)这一特性,它允许开发者编写更加清晰和安全的泛型代码。概念定义了一组要求,这些要求可以用来约束模板参数或者Lambda表达式中的参数类型。当与泛型Lambda表达式结合时,概念可以提供编译时的类型检查,帮助避免潜在的类型不匹配问题。
下面是一个使用概念约束泛型Lambda表达式的例子:
```cpp
#include <concepts>
#include <iostream>
// 定义一个简单的概念,要求类型T可以使用输出流运算符
template<typename T>
concept Outputable = requires(T a, std::ostream& os) {
os << a;
};
// 泛型Lambda表达式,使用Outputable概念进行类型约束
auto print = [](auto&& arg) requires Outputable<decltype(arg)> {
std::cout << arg;
};
int main() {
print(10); // 整数类型满足Outputable概念
// print(10.5); // 这将导致编译错误,因为double不满足Outputable概念
}
```
在上面的代码中,`print`是一个泛型Lambda表达式,它接受任何满足`Outputable`概念的类型,并在标准输出流中打印该值。
## 5.2 深入探讨捕获与生命周期
### 5.2.1 非静态成员变量的捕获
当Lambda表达式被定义在一个类的成员函数中时,它可以捕获该类的非静态成员变量。但是,这要求Lambda表达式拥有一个闭包类,该闭包类需要对成员变量有一个拷贝或引用。通过使用捕获列表中的`this`指针,Lambda表达式可以访问并操作对象的成员变量。
```cpp
class MyClass {
public:
int value;
void run() {
auto lambda = [this]() {
std::cout << this->value << std::endl;
};
lambda(); // 输出成员变量value的值
}
};
```
### 5.2.2 Lambda表达式的生命周期管理
Lambda表达式的生命周期是由其创建时所处的上下文决定的。通常,如果Lambda表达式是在一个函数中定义的,那么它将在该函数执行完毕后被销毁。然而,当Lambda表达式被赋值给一个具有更长生命周期的对象时,例如std::function,它可以持续存在。
开发者需要警惕这种情况,因为如果Lambda捕获的局部变量在Lambda销毁时已经不存在,这将导致未定义行为。
## 5.3 Lambda表达式的调试和维护
### 5.3.1 调试技巧和调试工具
调试Lambda表达式可以是一个挑战,因为它们的匿名特性。然而,现代IDE和调试器通常提供了强大的功能,可以帮助开发者观察和控制Lambda表达式的执行。
使用断点可以暂停程序执行,并检查Lambda表达式中的变量。另外,使用日志记录或打印输出可以帮助开发者追踪Lambda表达式中发生的事情。
### 5.3.2 Lambda表达式在大型项目中的维护策略
在大型项目中,Lambda表达式可能会变得复杂,这要求开发者采取一定的维护策略。例如,避免使用复杂的捕获列表、将复杂的Lambda分解为多个简单函数,以及使用尾置返回类型来增强代码的可读性。
当项目中包含多个模块或文件时,确保Lambda表达式仅捕获必要的局部变量,并且避免捕获跨模块的全局变量,这有助于减少潜在的维护问题。
本章对Lambda表达式的进阶主题进行了深入探讨,包括泛型Lambda表达式与概念的结合、捕获与生命周期的深入分析,以及调试和维护的实用技巧。这些内容不仅有助于开发者编写更为高效和安全的代码,也为Lambda表达式在复杂项目中的应用提供了必要的理论和实践指导。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
C++ Lambda表达式专栏深入探讨了这种强大的编程工具,从入门到精通,涵盖了10大技巧和8种进阶方法。它揭秘了闭包原理,解锁了无限应用可能。专栏还提供了7大策略,避免内存泄漏并提升执行效率。此外,它深入探讨了线程安全、设计模式、GUI开发、模板元编程、内存管理、Boost库、事件驱动编程、数据处理、错误处理、协程、游戏开发优化、算法性能、跨平台开发、模式匹配和机器学习中的应用。通过这些主题,专栏全面展示了C++ Lambda表达式的强大功能,帮助开发者掌握其精髓,打造高效、可读性强且性能卓越的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
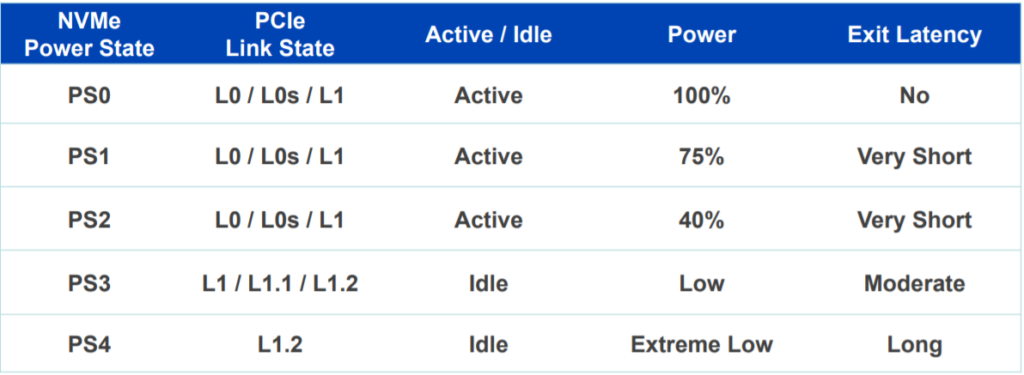
【PCIe 5.0兼容性指南】:保证旧有设备与新标准无缝对接(7大实用技巧)
# 摘要
本文深入探讨了PCIe 5.0技术的兼容性问题,从基本架构、协议新特性到设备升级和兼容性实践技巧,提供了全面的理论和实践指导。文中分析了PCIe 5.0的兼容性挑战,探讨了硬件、软件以及固件的升级策略,并通过多种实际案例,讨论了如何实现旧设备与PCIe 5.0的无缝对接。此外,本文还提出了一系列解决兼容性问题的方法,并对如何进行兼容性验证和认证给出了详细流程,旨在帮助技术人员确保设备升级后与PCIe 5.0技术的兼容性和性能的优化。
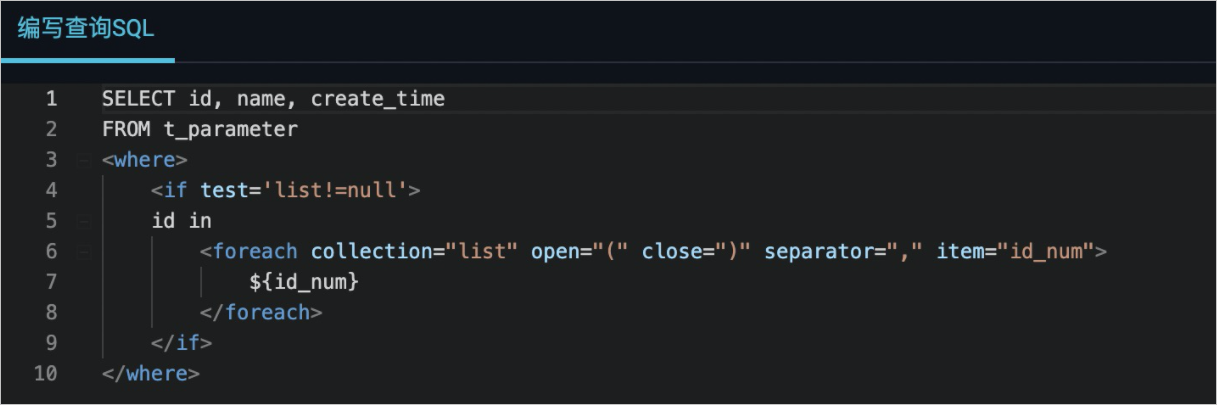
深入理解SpringBoot与数据库交互:JPA和MyBatis集成指南
# 摘要
本文详细介绍了SpringBoot与数据库交互的技术实践,探讨了JPA(Java Persistence API)和MyBatis两种流行的ORM(Object-Relational Mapping)框架的集成与应用。文章从基本概念和原理出发,详细阐述了JPA的集成过程、高级特性以及MyBatis的核心组件和工作方式。在深入分析了JPA
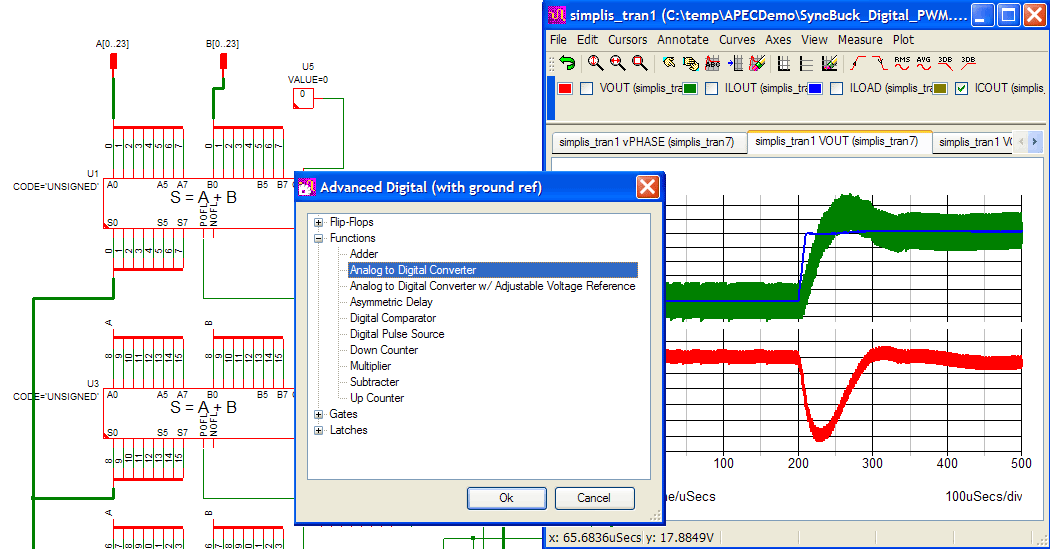
硬件在环仿真实战:Simetrix与你的完美结合
# 摘要
本文详细介绍了硬件在环仿真(Hardware in the Loop, HIL)的基本概念、Simetrix软件的功能及应用,并提供了多个实战案例分析。首先,概述了Simetrix软件的安装、界面布局和仿真技术,包括与其它仿真软件的对比。随后,本论文深入探讨了硬件在环仿真平台的搭建、测试实施以及结果分析方法。在Simetrix的高级应用方面,本文探讨了脚本编写、自动化测试、电路
【WinCC V16 脚本编程高级教程】

# 摘要
WinCC V16是西门子公司推出的组态软件,其脚本编程功能强大,是实现用户特定功能的关键工具。本文全面介绍了WinCC V16脚本编程的各个层面,从基础语法特性到高级应用技巧,再到问题诊断与优化策略。文中详细分析了变量、数据结构、控制结构、逻辑编程以及性能优化等关键编程要素。在实践应用方面,探讨了用户界面交互设计、数据通信、动态数据处理与可视化等实际场景。高级脚本应用部分着重讲解了数据处理、系统安
Layui上传文件错误处理:文件上传万无一失的终极攻略

# 摘要
Layui作为一款流行的前端UI框架,其文件上传功能对于开发交互性网页应用至关重要。本文首先介绍了Layui文件上传功能的基础知识,随后深入探讨了文件上传的理论基础,包括HTTP协议细节、Layui upload模块原理及常见错误类型。第三章和第四章集中于错误诊断与预防,以及解决与调试技巧,提供了前端和后端详细的错误处理方法和调试工具的使用。最后,第五章通过案例分析,展示了在复杂环境
【ESP8266与CJSON的结合】:打造个性化天气预警系统

# 摘要
本文介绍ESP8266平台与CJSON库的集成,旨在构建一个高效、个性化的天气预警系统。首先,本文概述ESP8266平台和CJSON库的基础知识,包括硬件架构、开发环境搭建,以及CJSON库在数据处理中的优势。接着,详细阐述了如何获取和解析天气数据,以及如何在ESP8266平台上利用CJSON进行数据解析和本地化显示。文中还探讨了如
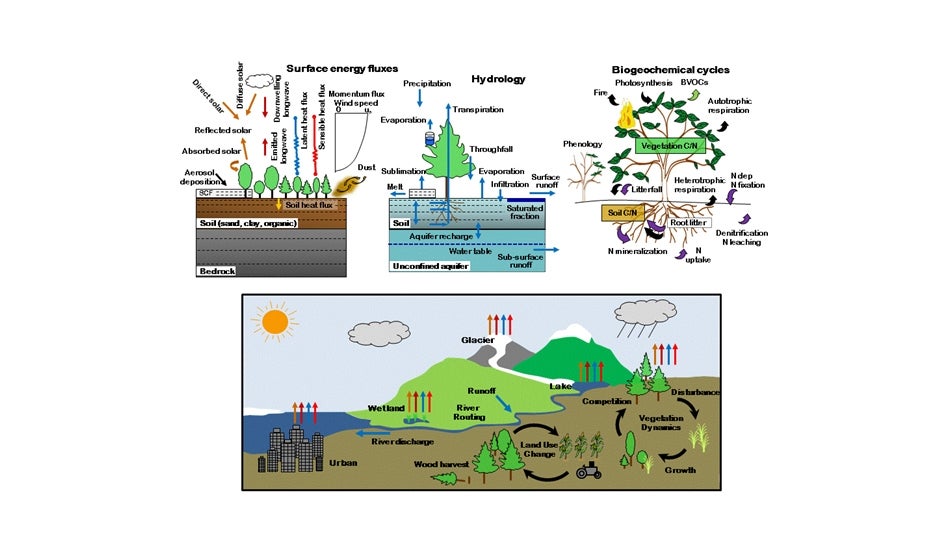
【实战揭秘】:用社区地面系统模型解决复杂问题的技巧
# 摘要
本文深入探讨了社区地面系统模型的构建与应用,从理论基础到实践案例进行了全面分析。首先,概述了社区地面系统模型的重要性和构建原则,接着讨论了系统模型的数学表达和验证方法。文章详细介绍了该模型在城市规划、灾害管理以及环境质量改善方面的具体应用,并探讨了模型在解决复杂问题时的多层次结构和优化策略。此外,本文
【Asap光学设计界面布局】:全面解析提升设计效率的关键步骤
# 摘要
本文详细探讨了Asap光学设计软件界面布局的各个方面,从基础的理论框架、设计元素到实际的应用技巧以及高级应用。文中分析了界面布局的基本原则和设计效率的关系,介绍了提高用户体验的交互设计和优化策略,并通过用户研究、设计工具的应用与界面布局的迭代来强化实践技巧。此外,文章还讨论了动态布局与响应式设计,高级交互技术的应用,以
【PLSY与PLSR调试优化】:三菱PLC脉冲控制技巧,提升性能

# 摘要
本文深入探讨了PLC(可编程逻辑控制器)中PLSY(脉冲输出)与PLSR(脉冲输入)指令的基础知识、理论基础及其在实际应用中的优化与调试方法。重点介绍了这些指令的工作原理、参数设置对性能的影响、以及在特定场合如电机控制中的实现。文章还探讨了脉冲控制技术在三菱PLC中的应用,包括多轴协调控制和精密位置控制策略,并提出
【个性化和利时M6软件体验】

# 摘要
本文介绍个性化和利时M6软件的理论基础和实践应用。首先,概述了软件的功能需求和核心架构,包括用户研究、功能模块化设计、软件的整体架构以及关键技术组件。其次,通过实践案例,展示了用户界面个性化定制、功能模块灵活配置和用户行为数据分析的应用。接着,深入探讨了软件与企业业务流程集成的最佳实践,以及技术创新对软件个性化的影响。最后,分析了个性化和利时M6软件在性能优化、安全挑战应对以及持续支持与服务升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )