Java集合面试热点问题全解析:代码演示与技巧分享


Java各种必备面试题目程序代码例子与应战技巧.zip
1. Java集合框架概述
1.1 集合框架的定义与重要性
Java集合框架是Java编程语言中一个核心的库,用于存储和操作对象集合。它为开发者提供了一套性能优化、线程安全且广泛使用的数据结构实现。理解集合框架是进行高效Java开发的基石,无论是在企业应用还是框架开发中,集合框架都是不可或缺的一部分。
1.2 集合框架的组成与层次结构
Java集合框架主要包含两大部分:接口(Interface)和实现类(Implementation)。接口定义了各种集合行为,如List、Set、Map等,而实现类则是接口的具体代码实现,例如ArrayList、HashMap等。集合框架的层次结构使得它既保持了高度的灵活性,也方便了扩展。
- // 例如,实现List接口的一个简单例子
- List<String> list = new ArrayList<>();
- list.add("Hello");
- list.add("World");
1.3 集合框架的优势
使用Java集合框架的优势在于能够简化编程,提供一致的接口,易于学习和使用。此外,框架内部优化了数据结构操作,减少了内存开销,提高了程序运行效率。集合框架的迭代器模式(Iterator Pattern)也使得元素遍历变得安全和一致。
2. 集合核心类的使用与原理
在Java编程中,集合框架是支撑数据操作和传递的基础组件。了解Java集合的核心类及其使用原理,对于编写高效、可维护的代码至关重要。本章我们将深入探讨List、Set和Map这三种集合类型,它们的使用场景、特性以及内部实现原理。
2.1 List集合的使用与特性
List集合是有序的集合,可以精确控制每个元素插入的位置,用户可以通过索引访问元素。List集合有两个主要的实现类:ArrayList和LinkedList。
2.1.1 ArrayList与LinkedList的比较
ArrayList基于动态数组实现,适合随机访问元素,但在列表中间插入或删除元素时,需要移动大量元素,效率较低。而LinkedList基于双向链表实现,适合频繁插入和删除操作,但在随机访问时,由于需要遍历链表,效率也不如ArrayList。
性能测试代码示例:

以上代码中,我们分别对ArrayList和LinkedList进行了随机访问和中间插入的性能测试。通过这种方式,我们可以直观地感受到两者在不同操作下的性能差异。
2.1.2 List集合的遍历与排序
遍历List集合可以使用普通的for循环、增强型for循环,或者使用ListIterator。对于排序,可以使用Collections.sort()方法或者List自带的sort()方法(Java 8之后引入)。
排序代码示例:
排序后,我们可以看到List中的元素已经按照升序排列。
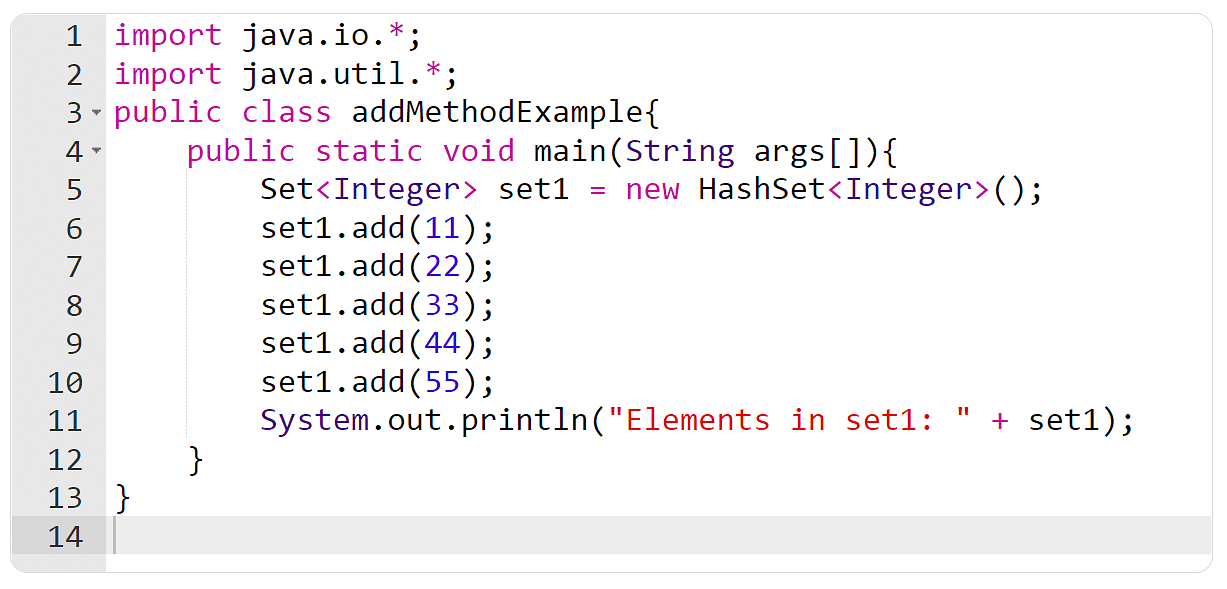
2.2 Set集合的使用与特性
Set集合不允许有重复元素,主要有HashSet和TreeSet两种实现方式。
2.2.1 HashSet与TreeSet的区别
HashSet基于HashMap实现,提供了常数时间复杂度的查找和插入操作,但不保证元素顺序。TreeSet基于红黑树实现,可以保证元素的排序状态,适用于需要元素排序的场景。
TreeSet的使用示例:
- import java.util.Set;
- import java.util.TreeSet;
- public class TreeSetExample {
- public static void main(String[] args) {
- Set<Integer> treeSet = new TreeSet<>();
- treeSet.add(5);
- treeSet.add(1);
- treeSet.add(3);
- treeSet.add(4);
- treeSet.add(2);
- System.out.println("TreeSet elements: " + treeSet);
- }
- }
以上代码中,我们创建了一个TreeSet并添加了几个整数。由于TreeSet保证了元素的顺序,所以输出的集合是按照升序排列的。
2.2.2 Set集合的去重机制
Set集合的去重机制依赖于其内部元素的equals()和hashCode()方法。当添加元素时,HashSet会先计算元素的hashCode值,然后判断该值是否已经存在。如果不存在,会继续调用equals()方法确认元素是否真正唯一。
HashSet添加元素示例:
在这个例子中,我们自定义了一个CustomObject类,并重写了equals()和hashCode()方法。通过这个自定义的类,我们可以创建一个HashSet,并添加几个CustomObject实例。由于我们重写了这两个方法,HashSet能够正确地处理这些对象的去重逻辑。
2.3 Map集合的使用与特性
Map集合存储键值对,每个键映射到一个值。主要实现类有HashMap和TreeMap。
2.3.1 HashMap与TreeMap的性能对比
HashMap基于哈希表实现,它提供平均时间复杂度为O(1)的性能,但不保证元素的顺序。TreeMap基于红黑树实现,元素会按照自然顺序或自定义的Comparator进行排序。
性能测试代码示例:
通过测试,我们可以看出对于快速查找操作,HashMap比TreeMap快,但TreeMap在需要有序访问的情况下有其独特的用途。
2.3.2 Map集合的键值对操作
在Map中,键是唯一的,而值可以重复。Map集合提供了丰富的API来进行键值对操作,例如put()用于添加键值对,get()用于获取键对应的值,remove()用于删除键值对等。
Map集合操作代码示例:
- import java.util.HashMap;
- import java.util.Map;
- public class MapExample {
- public static void main(String[] args) {
- Map<St

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高通QXDM工具进阶篇:定制化日志捕获与系统性能分析
【控制算法大比拼】:如何选择PID与先进控制算法
【HFSS仿真挑战克服指南】:实际项目难题迎刃而解
【TCP_IP与Xilinx Tri-Mode MAC的无缝整合】:网络协议深入整合与优化
中兴交换机QoS配置教程:网络性能与用户体验双优化指南
C语言动态内存:C Primer Plus第六版习题与实践解析
【MFCGridCtrl控件扩展开发指南】:创新功能与插件开发技巧
【PDFbox深度解析】:从结构到实战,全面掌握PDF文档处理
加密与安全:如何强化MICROSAR E2E集成的数据传输安全


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )








