RESTful API设计原则与实践
发布时间: 2024-02-27 22:29:45 阅读量: 31 订阅数: 33 

RESTful API 设计最佳实践
# 1. 理解RESTful API
RESTful API是一种常见的API设计风格,它基于REST(Representational State Transfer)架构。在本章中,我们将深入探讨RESTful API的基本概念,优势特点以及应用场景与实际案例分析。让我们一起来理解RESTful API的精髓。
## 1.1 什么是RESTful架构
RESTful架构是一种设计风格,它利用标准的HTTP方法来对资源进行操作和访问。RESTful架构的核心理念包括统一接口、资源的标识、无状态通信等。通过RESTful架构,我们可以构建出灵活、可扩展且易于理解的API。
```python
# 示例代码:使用Python Flask框架创建一个简单的RESTful API
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api/books', methods=['GET'])
def get_books():
books = [
{'id': 1, 'title': 'RESTful API Design'},
{'id': 2, 'title': 'Mastering HTTP Methods'}
]
return jsonify(books)
if __name__ == '__main__':
app.run()
```
**总结:**
RESTful架构是一种基于HTTP协议的API设计风格,通过统一的接口和资源标识实现客户端与服务端的通信。在实际开发中,我们可以使用各种编程语言和框架来构建RESTful API。
## 1.2 RESTful API的优势与特点
RESTful API具有诸多优势,包括良好的可伸缩性、可移植性、性能和可读性等。其特点包括接口统一、状态无关、客户端-服务端分离、可缓存等。这些特点使得RESTful API成为当前Web API设计的首选方案之一。
```java
// 示例代码:使用Java Spring Boot创建一个简单的RESTful API
@RestController
public class BookController {
@GetMapping("/api/books")
public List<Book> getBooks() {
return Arrays.asList(
new Book(1, "RESTful API Design"),
new Book(2, "Mastering HTTP Methods")
);
}
}
```
**总结:**
RESTful API具有诸多优势,包括良好的可伸缩性和可读性等。其特点使得RESTful API在Web API设计中得到广泛应用,成为开发者们借鉴和实践的设计范本。
## 1.3 RESTful API的应用场景与实际案例分析
RESTful API的应用场景非常广泛,从传统的Web开发到移动应用接口,再到物联网和微服务架构等领域,都可以看到RESTful API的身影。在实际案例分析中,我们可以深入了解各种行业中RESTful API的设计与实践。
```javascript
// 示例代码:使用Node.js Express创建一个简单的RESTful API
const express = require('express');
const app = express();
app.get('/api/books', (req, res) => {
res.json([
{ id: 1, title: 'RESTful API Design' },
{ id: 2, title: 'Mastering HTTP Methods' }
]);
});
app.listen(3000, () => {
console.log('RESTful API Server is running on port 3000');
});
```
**总结:**
通过实际案例分析,我们可以更好地理解RESTful API在不同领域中的应用场景,以及如何利用其优势特点设计出高效、可扩展的API接口。RESTful API的设计原则与实践需要不断总结与实践,才能更好地发挥其作用。
# 2. 设计原则与最佳实践
在设计RESTful API时,遵循一些基本的设计原则和最佳实践是非常重要的。这些原则和实践可以帮助我们创建出清晰、可扩展、安全且易于理解的API接口。接下来,我们将深入探讨RESTful API的设计原则与最佳实践。
### 2.1 简单性与可读性
设计RESTful API时,应该尽量保持简单和易读性。接口命名应具有自解释性,使用清晰的名词来代表资源,并且遵循统一的命名规范。另外,在API文档和注释中提供清晰易懂的描述也是至关重要的。
```java
// 示例:简单易懂的命名和注释
@GetMapping("/users/{userId}")
public ResponseEntity<User> getUserById(@PathVariable Long userId) {
// 获取指定用户信息
// ...
}
```
### 2.2 易于扩展与版本控制
随着业务的发展,API接口可能需要不断地进行扩展和更新。因此,在设计API时,要考虑到接口的扩展性和版本控制。可以使用URI版本ing或者使用自定义的版本ing header来管理不同的API版本。
```python
# 示例:版本控制
@app.route('/api/v1/users', methods=['GET'])
def get_users_v1():
# 获取用户列表(版本1)
# ...
@app.route('/api/v2/users', methods=['GET'])
def get_users_v2():
# 获取用户列表(版本2)
# ...
```
### 2.3 安全与认证授权
RESTful API的安全性至关重要。在设计API时,需要考虑用户认证和授权机制,确保API接口只能被合法的用户访问。可以使用基本认证、OAuth2.0等方式来保护API接口的安全性。
```go
// 示例:使用JWT进行用户认证授权
func (c *UserController) getUserByID(c *gin.Context) {
// 验证JWT token
if err := auth.ValidateToken(c.Request); err != nil {
// 返回未授权错误
c.JSON(http.StatusUnauthorized, gin.H{"error": "Unauthorized"})
return
}
// 获取用户信息
// ...
}
```
### 2.4 数据格式与交互规范
在RESTful API中,数据的交互格式对于接口的使用和理解至关重要。通常情况下,可以使用JSON或者XML格式来传递数据。此外,在设计API响应结构时,应该遵循统一的规范,保证返回的数据结构清晰明了。
```javascript
// 示例:统一的API响应结构
{
"code": 200,
"message": "Success",
"data": {
"id": 1,
"name": "John Doe",
"email": "john@example.com"
}
}
```
通过遵循上述设计原则与最佳实践,在实际的API接口设计中,可以创建出高质量、易于维护的RESTful API接口。
# 3. 资源与URI设计
在RESTful API设计中,资源和URI的设计是至关重要的。本章将深入探讨如何合理设计资源和URI,以满足RESTful API的最佳实践要求。
#### 3.1 标识资源与资源定位
在RESTful架构中,一切皆资源。资源是API暴露给客户端的核心对象,可以是数据库中的实体、文件、服务等。每个资源都应该有一个唯一的标识符来进行定位和访问。
#### 3.2 URI设计原则
- **保持简洁明了**:URI应该简洁易读,能够清晰地表达资源的层级关系和属性信息。
- **使用名词表示资源**:URI中应该使用名词而非动词,表示资源而非操作。
- **遵循RESTful风格**:URI路径应该采用RESTful风格,使用斜杠来表示层级关系,尽量避免嵌套过深的URI结构。
#### 3.3 RESTful URL最佳实践
```python
# 示例代码
from flask import Flask
from flask_restful import Api, Resource
app = Flask(__name__)
api = Api(app)
class Book(Resource):
def get(self, book_id):
# 根据book_id获取书籍信息
return {'book_id': book_id, 'title': 'Example Book'}
api.add_resource(Book, '/books/<int:book_id>')
if __name__ == '__main__':
app.run(debug=True)
```
**代码总结**:
- 在示例中,我们定义了一个返回书籍信息的RESTful API。
- 使用`/books/<int:book_id>`来表示获取特定书籍信息的URI,其中`<int:book_id>`表示book_id为整数类型参数。
**结果说明**:
- 当客户端访问 `/books/123` 时,将返回书籍ID为123的信息,如`{'book_id': 123, 'title': 'Example Book'}`。
通过合理设计资源和URI,我们可以构建出符合RESTful风格且易于理解和操作的API接口。
# 4. HTTP方法与操作
RESTful API设计中,HTTP方法是非常重要的一部分,它定义了对资源的操作行为,包括获取数据、创建新资源、更新已有资源和删除资源等。在本章中,我们将深入探讨不同的HTTP方法及其在RESTful API设计中的应用。
#### 4.1 GET、POST、PUT、DELETE等HTTP方法的语义与应用
HTTP协议定义了多种方法,其中最常见的包括GET、POST、PUT和DELETE。每种方法都有其独特的语义和在RESTful API中的应用场景。
- **GET**: 用于获取指定资源的表述,不应该对服务器上的资源产生任何副作用。在RESTful API中,通常用于获取资源的信息,例如获取用户信息、文章内容等。
```python
# Python示例代码
import requests
response = requests.get('https://api.example.com/users/123')
print(response.json())
```
- **POST**: 用于在服务器上创建新的资源,通常会返回新资源的URI,并可能返回创建的资源信息。在RESTful API中,通常用于创建新的资源,例如创建新的用户、发布文章等。
```java
// Java示例代码
HttpPost httpPost = new HttpPost("https://api.example.com/users");
StringEntity entity = new StringEntity("{'username': 'newuser', 'email': 'newuser@example.com'}");
httpPost.setEntity(entity);
HttpResponse response = httpClient.execute(httpPost);
```
- **PUT**: 用于更新服务器上的资源,客户端提供完整的更新后的资源表述。在RESTful API中,通常用于更新已有的资源,例如更新用户信息、更新文章内容等。
```go
// Go示例代码
func UpdateUser(w http.ResponseWriter, r *http.Request) {
userID := mux.Vars(r)["id"]
var updatedUser User
json.NewDecoder(r.Body).Decode(&updatedUser)
// 更新userID对应的用户信息
}
```
- **DELETE**: 用于删除服务器上的资源。在RESTful API中,通常用于删除指定的资源,例如删除用户、删除文章等。
```javascript
// JavaScript示例代码(使用axios库)
axios.delete('https://api.example.com/users/123')
.then(response => {
console.log('User deleted');
})
.catch(error => {
console.error('Error deleting user', error);
});
```
#### 4.2 如何使用HTTP方法进行资源操作
在设计RESTful API时,合理地使用HTTP方法可以使API具有更好的可读性和易用性。根据HTTP方法的语义来设计API接口,可以使接口的行为更加直观和符合预期。
- 通过合理使用HTTP方法来对资源进行CRUD操作,可以使API的设计更加符合RESTful风格,也易于理解和记忆。
#### 4.3 有关PATCH、OPTIONS等非标准HTTP方法的考量
除了常见的GET、POST、PUT和DELETE方法外,还有一些非标准的HTTP方法,如PATCH、OPTIONS等。在实际的API设计中,我们需要考虑是否有必要使用这些非标准方法,以及如何在框架和工具支持上进行处理。
- **PATCH**: 用于对资源进行局部更新,只更新指定字段或属性。在RESTful API中,可以用于部分更新用户信息、修改文章部分内容等。
```python
# Python示例代码
import requests
response = requests.patch('https://api.example.com/users/123', json={'email': 'newemail@example.com'})
```
- **OPTIONS**: 用于获取目标资源所支持的通信选项。在RESTful API中,可以用于获取指定资源支持的HTTP方法、跨域请求的预检等。
```java
// Java示例代码
HttpOptions httpOptions = new HttpOptions("https://api.example.com/users");
HttpResponse response = httpClient.execute(httpOptions);
Header[] allowHeaders = response.getHeaders("Allow");
```
对于非标准的HTTP方法,我们需要权衡其在API设计中的实际价值和可行性,并在文档中明确说明其使用方式和效果。
通过对不同HTTP方法的语义和应用进行深入了解,可以帮助我们更好地设计和实现RESTful API,提供更好的接口操作体验和性能优化。
# 5. 数据格式与交互规范
在设计RESTful API时,选择合适的数据格式与交互规范对于提升API的易用性和性能至关重要。本章将深入探讨RESTful API中数据格式与交互规范的相关内容。
### 5.1 JSON与XML的选择与比较
在RESTful API中,常用的数据格式包括JSON(JavaScript Object Notation)和XML(eXtensible Markup Language)。它们各有优缺点:
- **JSON**:
- 优点:轻量、易读、易解析、易于传输和处理、支持多种语言。
- 缺点:不适合非结构化数据、可读性较差。
- **XML**:
- 优点:适合复杂数据结构、支持命名空间、可读性较好。
- 缺点:冗长、解析复杂、传输效率低。
根据实际需求和团队偏好,选择适合的数据格式进行API设计是至关重要的。
```python
# 以Python为例,展示JSON与XML数据格式的简单示例
# JSON示例
import json
# 定义JSON数据
json_data = '{"name": "Alice", "age": 30, "city": "New York"}'
# 将JSON数据解析为Python字典
parsed_json = json.loads(json_data)
# 输出解析后的数据
print(parsed_json)
# XML示例
import xml.etree.ElementTree as ET
# 定义XML数据
xml_data = '<person><name>Alice</name><age>30</age><city>New York</city></person>'
# 解析XML数据
parsed_xml = ET.fromstring(xml_data)
# 输出解析后的数据
for child in parsed_xml:
print(child.tag, child.text)
```
### 5.2 数据格式的设计与优化
设计良好的数据格式能够提高API的可读性和扩展性。在选择JSON或XML后,需要考虑以下设计原则:
- **一致性**:保持数据格式的一致性,便于开发者理解和操作。
- **简洁性**:避免冗余信息,精简数据结构,减少数据传输量。
- **嵌套与扁平**:合理使用嵌套结构,避免过度嵌套导致数据访问复杂性增加。
- **命名规范**:采用清晰的命名规范,提高数据字段的可理解性。
### 5.3 请求与响应的规范结构
在RESTful API中,请求与响应的数据结构应当符合规范,以便客户端和服务器之间的信息交换。通常,一个标准的请求与响应应该包括以下内容:
- 请求:请求方法、请求头、请求体(数据内容)。
- 响应:状态码、响应头、响应体(数据内容)。
```java
// Java示例,展示标准的HTTP请求与响应结构
// HTTP GET请求
HttpGet request = new HttpGet("https://api.example.com/data");
request.setHeader("Accept", "application/json");
// 发送请求并获取响应
HttpClient client = HttpClientBuilder.create().build();
HttpResponse response = client.execute(request);
// 处理响应
int statusCode = response.getStatusLine().getStatusCode;
String responseBody = EntityUtils.toString(response.getEntity());
```
### 5.4 错误处理与异常信息的标准化
良好的API设计也包括对错误处理与异常信息的规范化。在API中,应该定义清晰的错误码和对应的错误信息,以便客户端能够准确处理错误情况。
```javascript
// JavaScript示例,展示错误处理的标准化方式
// 定义错误码与错误信息的映射
const errorMessages = {
400: 'Bad Request - 请求参数有误',
401: 'Unauthorized - 鉴权失败',
404: 'Not Found - 资源不存在',
500: 'Internal Server Error - 服务器内部错误'
};
// 处理HTTP请求错误
function handleHTTPError(statusCode) {
if (errorMessages[statusCode]) {
console.log(errorMessages[statusCode]);
} else {
console.log('Unknown Error');
}
}
```
通过遵循以上数据格式与交互规范,可以提高RESTful API的可读性、可维护性和易用性,从而为开发者提供更好的API体验。
# 6. 实践指南与性能优化
在实际开发过程中,设计了优秀的RESTful API是第一步,如何进行测试、性能优化和文档编写同样重要。本章将介绍一些实践指南和性能优化的实用技巧,以及RESTful API的生命周期管理与版本迁移。
#### 6.1 如何进行RESTful API的测试与调试
在开发RESTful API时,测试与调试是至关重要的环节。我们可以使用例如Postman、JUnit、JUnit5、RestAssured等工具来实现API的自动化测试。以下是一个使用JUnit5进行RESTful API测试的示例(Java语言):
```java
import static io.restassured.RestAssured.*;
import static org.hamcrest.Matchers.*;
import org.junit.jupiter.api.Test;
public class ApiTest {
@Test
public void testGetUser() {
given()
.when().get("https://api.example.com/users/123")
.then()
.statusCode(200)
.body("username", equalTo("johnDoe"));
}
@Test
public void testCreateUser() {
given()
.contentType("application/json")
.body("{\"username\": \"newUser\"}")
.when().post("https://api.example.com/users")
.then()
.statusCode(201);
}
}
```
通过编写类似的测试用例,可以对API进行全面的测试,确保其功能的正常运行。
#### 6.2 提高RESTful API性能的实用技巧
为了提升RESTful API的性能,可以采取一系列优化措施。其中包括利用缓存机制、合理使用HTTP缓存头部信息、减少网络请求次数、异步处理等。以下是一个使用Python Flask框架实现API异步处理的示例:
```python
from flask import Flask, jsonify
import time
import concurrent.futures
app = Flask(__name__)
def async_task():
time.sleep(5) # 模拟耗时操作
return {"message": "Async task completed"}
@app.route('/async-task', methods=['GET'])
def trigger_async_task():
with concurrent.futures.ThreadPoolExecutor() as executor:
future = executor.submit(async_task)
result = future.result()
return jsonify(result)
if __name__ == '__main__':
app.run()
```
通过异步处理,可以提高API的并发处理能力和性能表现。
#### 6.3 API文档的编写与维护
良好的API文档对于API的使用者至关重要。我们可以通过工具如Swagger、Apiary等来编写和维护API文档。以下是一个使用Swagger编写API文档的示例(基于YAML):
```yaml
openapi: 3.0.0
info:
title: Sample API
version: 1.0.0
description: This is a sample API documentation
paths:
/users:
get:
summary: Retrieve a list of users
responses:
'200':
description: A list of users
content:
application/json:
schema:
type: array
items:
type: object
properties:
username:
type: string
post:
summary: Create a new user
requestBody:
required: true
content:
application/json:
schema:
type: object
properties:
username:
type: string
responses:
'201':
description: User created successfully
```
通过编写类似的API文档,可以让使用者清晰了解API的结构和使用方式。
#### 6.4 RESTful API生命周期管理与版本迁移
随着业务的发展,API的需求会不断变化,因此需要对API进行生命周期管理和版本迁移。特别是在版本迁移过程中,我们需要确保旧版本API的兼容性,引导用户迁移到新版本。以下是一个简单的API版本控制示例(Node.js Express框架):
```javascript
const express = require('express');
const app = express();
// 版本1
app.get('/v1/users', (req, res) => {
// 返回用户列表
});
// 版本2
app.get('/v2/users', (req, res) => {
// 返回用户列表,可能包含新的字段
});
app.listen(3000, () => {
console.log('Server is running on port 3000');
});
```
通过对不同版本API的区分,可以有效实现API的版本迁移。
本章介绍了RESTful API的实践指南与性能优化的一些技巧,以及API文档的编写与维护,以及RESTful API的生命周期管理与版本迁移的一些实例。通过这些内容,我们可以更好地实践和优化RESTful API的设计与开发。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【BIOS配置艺术】:提升ProLiant DL380 G6性能的Windows Server 2008优化教程

# 摘要
本文旨在探讨BIOS在服务器性能优化中的作用及其配置与管理策略。首先,概述了BIOS的基本概念、作用及其在服务器性能中的角色,接着详细介绍了BIOS的配置基础和优化实践,包括系统启动、性能相关设置以及安全性设置。文章还讨论
【安全性的守护神】:适航审定如何确保IT系统的飞行安全

# 摘要
适航审定作为确保飞行安全的关键过程,近年来随着IT系统的深度集成,其重要性愈发凸显。本文首先概述了适航审定与IT系统的飞行安全关系,并深入探讨了适航审定的理论基础,包括安全性管理原则、风险评估与控制,以及国内外适航审定标准的演变与特点。接着分析了IT系统在适航审定中的角色,特别是IT系统安全性要求、信息安全的重要性以及IT系统与飞行控制系统的接口安全。进一步,文
【CListCtrl行高优化实用手册】:代码整洁与高效维护的黄金法则
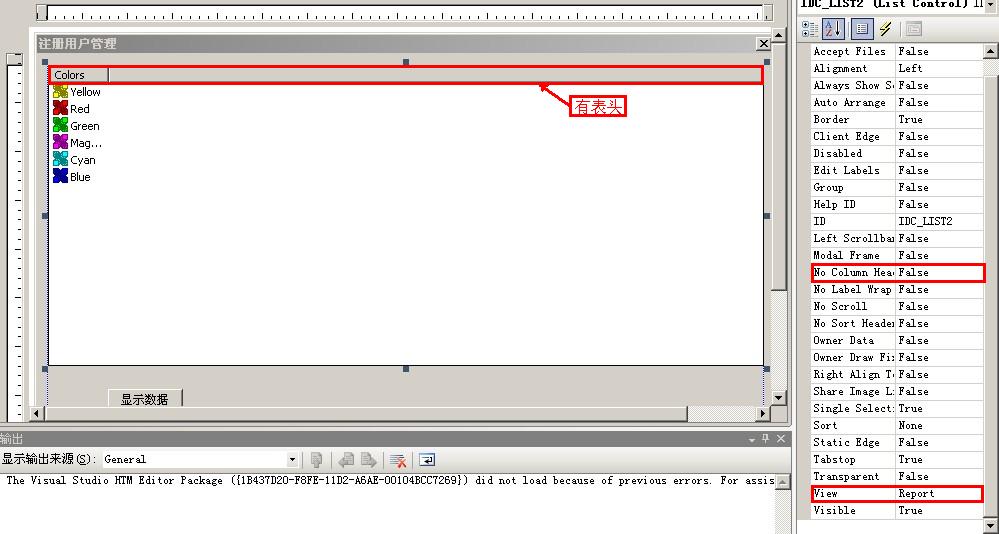
# 摘要
本文针对CListCtrl控件的行高优化进行了系统的探讨。首先介绍了CListCtrl行高的基础概念及其在不同应用场景下的重要性。其次,深入分析了行高优化的理论基础,包括其基本原理、设计原则以及实践思路。本研究还详细讨论了在实际编程中提高行高可读性与性能的技术,并提供了代码维护的最佳实践。此外,文章探讨了行高优化在用户体验、跨平台兼容性以及第三方库集成方面的高级应用。最后
【高级时间序列分析】:傅里叶变换与小波分析的实战应用

# 摘要
时间序列分析是理解和预测数据随时间变化的重要方法,在众多科学和工程领域中扮演着关键角色。本文从时间序列分析的基础出发,详细介绍了傅里叶变换与小波分析的理论和实践应用。文中阐述了傅里叶变换在频域分析中的核心地位,包括其数学原理和在时间序列中的具体应用,以及小波分析在信号去噪、特征提取和时间-频率分析中的独特优势。同时,探讨了当前高级时间序列分析工具和库的使用,以及云平台在大数据时间
【文档编辑小技巧】:不为人知的Word中代码插入与行号突出技巧
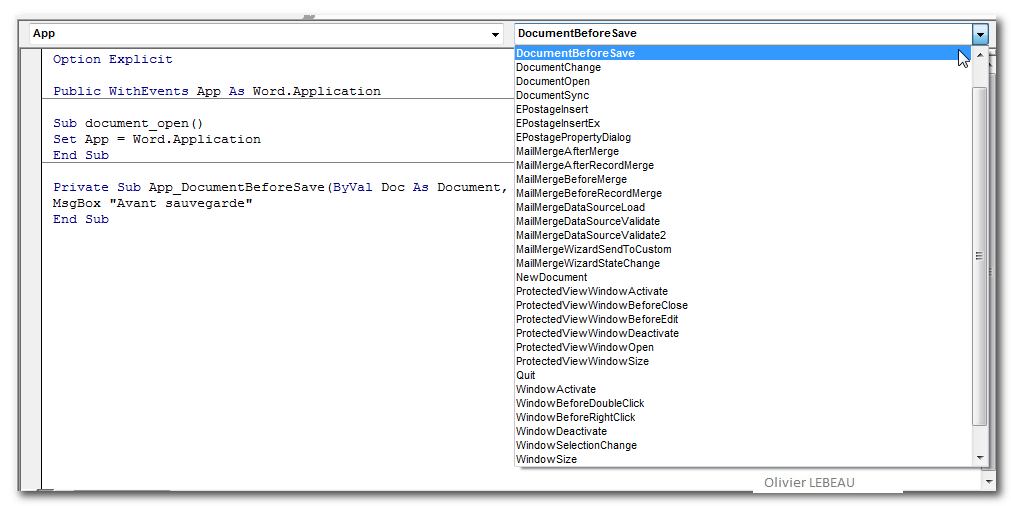
# 摘要
本文主要探讨在Microsoft Word文档中高效插入和格式化代码的技术。文章首先介绍了代码插入的基础操作,接着深入讨论了高级技术,包括利用“开发工具”选项卡、使用“粘贴特殊”功能以及通过宏录制来自动化代码插入。在行号应用方面,文章提供了自动和手动添加行号的技巧,并讨论了行号的更新与管理方法。进阶实践部分涵盖了高级代码格式化和行号与代码配合使用的技巧
长安汽车生产技术革新:智能制造与质量控制的全面解决方案

# 摘要
智能制造作为一种先进的制造范式,正逐渐成为制造业转型升级的关键驱动力。本文系统阐述了智能制造的基本概念与原理,并结合长安汽车的实际生产技术实践,深入探讨了智能制造系统架构、自动化与机器人技术、以及数据驱动决策的重要性。接着,文章着重分析了智能制造环境下的质量控制实施,包括质量管理的数字化转型、实时监控与智能检测技术的应用,以及构建问题追踪与闭环反馈机制。最后,通过案例分析和国内外比较,文章揭示了智
车载网络性能提升秘籍:测试优化与实践案例

# 摘要
随着智能网联汽车技术的发展,车载网络性能成为确保车辆安全、可靠运行的关键因素。本文系统地介绍了车载网络性能的基础知识,并探讨了不同测试方法及其评估指标。通过对测试工具、优化策略以及实践案例的深入分析,揭示了提升车载网络性能的有效途径。同时,本文还研究了当前车载网络面临的技术与商业挑战,并展望了其未来的发展趋势。本文旨在为业内研究人员、工程师提供车载
邮件规则高级应用:SMAIL中文指令创建与管理指南

# 摘要
SMAIL是一种电子邮件处理系统,具备强大的邮件规则设置和过滤功能。本文介绍了SMAIL的基本命令、配置文件解析、邮件账户和服务器设置,以及邮件规则和过滤的应用。文章进一步探讨了SMAIL的高级功能,如邮件自动化工作流、内容分析与挖掘,以及第三方应用和API集成。为了提高性能和安全性,本文还讨论了SMAIL
CCU6与PWM控制:高级PWM技术的应用实例分析
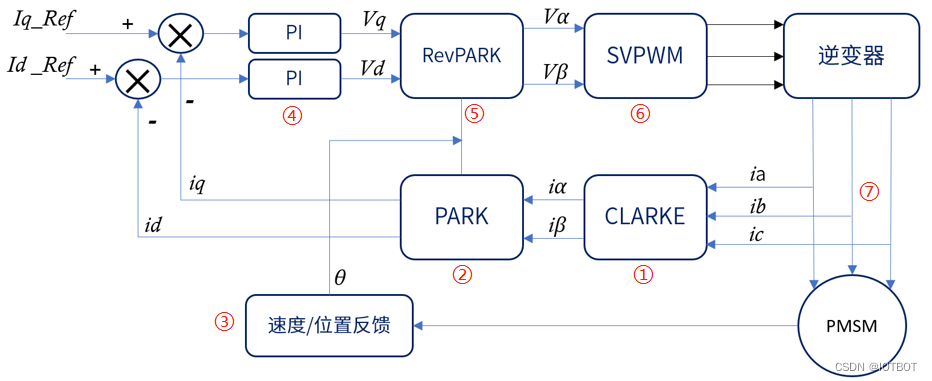
# 摘要
本文针对CCU6控制器与PWM控制技术进行了全面的概述和分析。首先,介绍PWM技术的理论基础,阐述了其基本原理、参数解析与调制策略,并探讨了在控制系统中的应用,特别是电机控制和能源管理。随后,专注于CCU6控制器的PWM功能,从其结构特点到PWM模块的配置与管理,详细解析了CCU6控制器如何执行高级PWM功能,如脉宽调制、频率控制以及故障检测。文章还通过多个实践应用案例,展示了高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )