Kubernetes集群管理与部署最佳实践
发布时间: 2024-02-23 06:39:22 阅读量: 72 订阅数: 31 
# 1. 理解Kubernetes集群管理
Kubernetes作为一个开源的容器编排引擎,在当今云计算领域发挥着越来越重要的作用。了解Kubernetes的基本概念、架构特点以及选择它的理由,对于进行集群管理和部署至关重要。在本章中,我们将深入探讨Kubernetes集群管理的核心内容。
## 1.1 什么是Kubernetes?
Kubernetes是一个跨主机集群的容器编排平台,可以实现应用程序的自动部署、扩展和管理。它最初由Google开发,如今已成为CNCF(Cloud Native Computing Foundation)旗下的顶级项目之一。
Kubernetes的主要功能包括:
- 自动化部署和扩展:Kubernetes能够根据应用程序的需求自动部署和扩展容器实例。
- 服务发现与负载均衡:Kubernetes提供内建的服务发现和负载均衡功能,确保应用程序能够稳定运行。
- 自愈机制:当容器发生故障时,Kubernetes能够自动进行替换,确保应用程序的高可用性。
## 1.2 Kubernetes集群的架构与特点
Kubernetes集群通常由多个节点组成,其中包括Master节点和Worker节点。Master节点负责整个集群的管理和控制,而Worker节点则负责运行应用程序的容器实例。
Kubernetes集群的架构特点包括:
- Master节点:包括API Server、Scheduler、Controller Manager和etcd等组件,负责集群的管理和控制。
- Worker节点:包括Kubelet、Kube-proxy和容器运行时等组件,负责调度和运行容器实例。
- Pod:是Kubernetes的最小调度单位,可以包含一个或多个容器实例。
## 1.3 为什么选择Kubernetes进行集群管理?
选择Kubernetes进行集群管理有诸多优势,包括:
- 弹性和可伸缩性:Kubernetes能够根据应用程序的负载自动进行扩展和缩减。
- 跨平台支持:Kubernetes可以在各种云平台和裸机环境上运行。
- 社区支持和生态丰富:Kubernetes拥有庞大的开发者社区和丰富的生态系统,能够满足各种场景的需求。
- 自动化和自愈能力:Kubernetes支持自动化部署、滚动升级和故障自愈,降低人工操作成本。
通过深入理解Kubernetes的原理和优势,可以更好地应用它来进行集群管理,提高应用程序的可靠性和扩展性。
# 2. 搭建Kubernetes集群
在搭建Kubernetes集群之前,首先需要确定是选择单节点还是多节点集群,再根据需求选择适合的搭建工具。接下来将介绍两种常用的搭建方式和对应工具的详细使用方法。
### 2.1 单节点与多节点集群的选择
#### 单节点集群
单节点集群适用于测试、开发或教学目的。通过在一台机器上部署单节点集群,可以快速体验Kubernetes的基本功能。然而,由于单点故障风险较高,并不适合生产环境使用。
#### 多节点集群
多节点集群是在多台机器上搭建Kubernetes集群,通常包括Master节点和多个Worker节点。这种方式适合生产环境,具有更高的可靠性和可扩展性。
### 2.2 KubeAdm工具的介绍与使用
KubeAdm是官方推荐的用于快速部署Kubernetes集群的工具,它简化了集群的安装过程,同时提供了默认的配置和最佳实践。
以下是使用KubeAdm搭建Kubernetes集群的简要步骤:
#### 步骤1:安装Docker和Kubelet
```bash
# 安装Docker
sudo apt-get update
sudo apt-get install -y docker.io
# 安装Kubelet、Kubeadm和Kubectl
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
```
#### 步骤2:初始化Master节点
```bash
sudo kubeadm init
```
#### 步骤3:加入Worker节点
```bash
# 在Master节点执行的命令
sudo kubeadm token create --print-join-command
# 在Worker节点执行打印出的加入命令
```
#### 步骤4:安装网络插件
```bash
kubectl apply -f https://docs.projectcalico.org/v3.3/getting-started/kubernetes/installation/hosted/rbac-kdd.yaml
kubectl apply -f https://docs.projectcalico.org/v3.3/getting-started/kubernetes/installation/hosted/kubernetes-datastore/calico-networking/1.7/calico.yaml
```
### 2.3 使用Kubespray快速搭建高可用Kubernetes集群
Kubespray是一个基于Ansible的开源工具,可帮助用户在多台机器上快速搭建高可用的Kubernetes集群。通过Kubespray,用户可以自定义集群配置,并实现自动化部署和管理。
以下是使用Kubespray搭建高可用Kubernetes集群的简要步骤:
#### 步骤1:克隆Kubespray存储库
```bash
git clone https://github.com/kubernetes-sigs/kubespray.git
cd kubespray
```
#### 步骤2:准备Inventory文件
```bash
cp -rfp inventory/sample inventory/mycluster
```
#### 步骤3:配置集群规格和选项
```bash
declare -a IPS=(10.0.0.3 10.0.0.4 10.0.0.5)
CONFIG_FILE=inventory/mycluster/group_vars/all/all.yml python3 contrib/inventory_builder/inventory.py ${IPS[@]}
```
#### 步骤4:部署集群
```bash
ansible-playbook -i inventory/mycluster/hosts.yml cluster.yml
```
通过以上步骤,您可以使用KubeAdm或Kubespray快速搭建Kubernetes集群,满足不同场景下的需求。
# 3. 部署应用程序到Kubernetes集群
在本章中,我们将详细讨论如何将应用程序部署到Kubernetes集群中。我们将介绍使用Kubectl命令行工具和Helm包管理工具来简化部署流程,并分享一些常见的应用部署案例和最佳实践。
#### 3.1 使用Kubectl命令行工具
Kubectl是Kubernetes的命令行工具,可以用于与Kubernetes集群交互、创建、管理应用程序、监视集群资源等。以下是一个简单的示例,演示如何使用Kubectl来部署一个Nginx应用:
```bash
# 创建一个Nginx的Deployment
kubectl create deployment nginx --image=nginx
# 将Nginx服务暴露出来,使其可以通过集群外部访问
kubectl expose deployment nginx --port=80 --type=NodePort
```
上述代码片段演示了如何使用Kubectl创建一个Nginx Deployment,并通过Service将其暴露为一个NodePort类型的服务。通过这种方式,可以在Kubernetes集群中轻松部署和管理各种应用程序。
#### 3.2 利用Helm包管理工具简化部署流程
Helm是一个开源的Kubernetes包管理工具,可以简化在Kubernetes集群上部署和管理应用程序的流程。通过Helm Charts,用户可以轻松地定义、安装、更新和卸载复杂的Kubernetes应用。
以下是一个简单的示例,演示如何使用Helm来部署一个WordPress应用:
```bash
# 添加Helm Stable Repo
helm repo add stable https://charts.helm.sh/stable
# 安装WordPress Chart
helm install my-wordpress stable/wordpress
```
通过上述代码片段,用户可以通过Helm快速部署WordPress应用程序,而无需深入了解其背后的复杂性。
#### 3.3 常见应用部署案例与最佳实践
除了上述的基本部署方法外,还有许多常见的应用部署案例和最佳实践,比如StatefulSet部署有状态应用、DaemonSet部署特定节点上的Pod等。在实际应用部署过程中,根据应用的特点和需求,选择合适的部署方式和最佳实践至关重要。
同时,还可以通过制定适当的Pod资源请求和限制、配置生命周期钩子、使用ConfigMap和Secrets等方式,进一步优化和管理应用的部署过程。
在实际生产环境中,根据具体的业务需求和场景选择合适的部署方式和最佳实践,对于提高应用的稳定性和可用性至关重要。
通过本章的学习,读者将了解到如何使用Kubectl和Helm进行应用程序部署,以及一些常见的应用部署案例和最佳实践,为实际生产环境中的部署工作提供指导和参考。
下一章中,我们将继续探讨Kubernetes集群监控与日志管理的相关内容。
# 4. Kubernetes集群监控与日志管理
Kubernetes集群的监控与日志管理是保障集群稳定运行和故障排查的重要环节。本章将介绍Kubernetes集群监控与日志管理的最佳实践,包括Prometheus与Grafana的集成、EFK日志管理方案以及性能指标监控与日志分析的关键指标。
#### 4.1 Prometheus与Grafana的集成
Prometheus是一款开源的监控及报警系统,可帮助用户记录实时的监控数据并提供友好的查询界面。Grafana是一款流行的开源数据可视化工具,可以与Prometheus无缝集成,通过各种图表展示监控数据。
以下是使用Helm部署Prometheus与Grafana的示例代码:
```yaml
# prometheus.yaml
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
# 创建名为monitoring的命名空间
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
# 创建Prometheus的ServiceAccount
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
verbs:
- get
- list
- watch
# 创建Prometheus的ClusterRole,用于授予Prometheus对Kubernetes资源的访问权限
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
# 创建Prometheus的ClusterRoleBinding,将ClusterRole绑定到Prometheus的ServiceAccount
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-server-conf
namespace: monitoring
labels:
name: prometheus-server-conf
data:
prometheus.yml: |-
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'kubernetes-apiservers'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
tls_config:
insecure_skip_verify: true
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
# 创建Prometheus的ConfigMap,配置Prometheus的抓取规则
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
labels:
app: prometheus
spec:
type: NodePort
ports:
- port: 9090
targetPort: 9090
protocol: TCP
name: web
selector:
app: prometheus
# 创建Prometheus的Service,并指定NodePort类型的端口暴露Prometheus的Web界面
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus-deployment
namespace: monitoring
spec:
selector:
matchLabels:
app: prometheus
replicas: 1
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- name: prometheus
image: prom/prometheus:v2.11.1
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus"
- "--web.console.libraries=/etc/prometheus/console_libraries"
- "--web.console.templates=/etc/prometheus/consoles"
ports:
- containerPort: 9090
volumeMounts:
- name: prometheus-config
mountPath: /etc/prometheus
- name: prometheus-storage
mountPath: /prometheus
volumes:
- name: prometheus-config
configMap:
defaultMode: 420
name: prometheus-server-conf
- name: prometheus-storage
emptyDir: {}
# 创建Prometheus的Deployment,部署Prometheus实例
apiVersion: v1
kind: Service
metadata:
name: prometheus-grafana
namespace: monitoring
labels:
app: prometheus
spec:
ports:
- port: 80
targetPort: 3000
protocol: TCP
selector:
app: prometheus
# 创建Prometheus的Grafana Service,并指定端口暴露Grafana的Web界面
```
```yaml
# grafana.yaml
apiVersion: v1
kind: Namespace
metadata:
name: monitoring
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
labels:
app: grafana
spec:
type: NodePort
ports:
- port: 3000
targetPort: 3000
protocol: TCP
name: web
selector:
app: grafana
# 创建Grafana的Service,并指定NodePort类型的端口暴露Grafana的Web界面
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana-deployment
namespace: monitoring
spec:
selector:
matchLabels:
app: grafana
replicas: 1
template:
metadata:
labels:
app: grafana
spec:
containers:
- name: grafana
image: grafana/grafana:6.1.6
ports:
- containerPort: 3000
# 创建Grafana的Deployment,部署Grafana实例
```
上述代码演示了通过Helm部署Prometheus与Grafana,并将它们暴露在Kubernetes集群中。读者在部署时需要注意相关的权限、网络设置等,以确保Prometheus与Grafana能够正常工作。当集成完成后,用户可以通过访问对应的NodePort或者通过Ingress等方式访问Prometheus和Grafana的Web界面进行监控数据展示和分析。
#### 4.2 EFK(Elasticsearch、Fluentd、Kibana)日志管理方案
除了监控外,日志管理也是Kubernetes集群管理的关键环节。EFK方案即Elasticsearch、Fluentd、Kibana的组合,可以提供日志收集、存储和可视化展示的功能。
以下是使用Helm部署EFK的示例代码:
```yaml
# elasticsearch.yaml
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.6.1
nodeSets:
- name: default
count: 1
config:
node.master: true
node.data: true
node.ingest: true
node.store.allow_mmap: false
# 创建Elasticsearch实例
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
spec:
version: 7.6.1
count: 1
elasticsearchRef:
name: quickstart
# 创建Kibana实例,关联到已创建的Elasticsearch实例
apiVersion: v1
kind: Service
metadata:
name: quickstart-kb-http
spec:
type: NodePort
ports:
- port: 5601
targetPort: 5601
selector:
common.k8s.elastic.co/type: kibana
# 创建Kibana的Service,并指定NodePort类型的端口暴露Kibana的Web界面
```
```yaml
# fluentd.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd
namespace: logging
data:
fluent.conf: |
<source>
@type tail
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag kubernetes.*
time_format %Y-%m-%dT%H:%M:%S.%NZ
read_from_head true
<parse>
@type json
time_format %Y-%m-%dT%H:%M:%S.%NZ
</parse>
</source>
<match kubernetes.**>
@type elasticsearch
logstash_format true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
include_tag_key true
tag_key @log_name
logstash_prefix fluentd
logstash_dateformat %Y%m%d
</match>
# 创建Fluentd的ConfigMap,配置Fluentd的日志收集规则并将日志发送到Elasticsearch
```
上述代码演示了通过Helm部署Elasticsearch、Kibana和Fluentd,并将它们暴露在Kubernetes集群中。读者在部署时同样需要留意相关的配置及权限设置,以确保EFK能够正常工作。部署完成后,用户可以通过访问对应的NodePort或者通过Ingress等方式访问Kibana的Web界面来查看和分析日志。
#### 4.3 性能指标监控与日志分析的关键指标
在Kubernetes集群监控与日志管理中,除了部署监控与日志工具外,还需要了解一些关键指标与日志分析的方法:
- 对于Prometheus与Grafana,用户需要熟悉Kubernetes集群的性能指标,如CPU、内存、网络流量等,以及如何利用PromQL查询这些指标并通过Grafana进行可视化展示。
- 对于EFK,用户需要了解如何在Fluentd中配置日志的收集规则,以及如何在Kibana中进行日志检索、过滤与分析。
本章介绍的Prometheus与Grafana集成以及EFK日志管理方案,以及重要的监控指标和日志分析方法,将有助于读者更好地理解Kubernetes集群的监控与日志管理的相关实践。
# 5. Kubernetes集群安全与权限管理
在Kubernetes集群管理中,安全性是至关重要的一个方面,特别是随着集群规模的扩大和业务敏感性的增加。适当的安全措施可以有效地保护集群不受未经授权的访问和攻击。在本章中,将重点介绍Kubernetes集群的安全与权限管理的相关内容。
### 5.1 RBAC角色的定义与使用
RBAC(Role-Based Access Control)是Kubernetes提供的一种访问控制机制,通过为用户分配特定角色和权限来管理集群资源的访问。下面是一个简单的示例,演示如何定义一个RBAC角色并授予用户相应的权限。
```yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: User
name: alice
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
```
在上面的示例中,定义了一个名为`pod-reader`的角色,该角色具有对`pods`资源的`get`、`watch`和`list`权限。然后通过`RoleBinding`将`pod-reader`角色绑定到用户`alice`,这样`alice`就拥有了对`pods`资源的相应权限。
### 5.2 使用网络策略确保集群安全通信
Kubernetes的网络策略(Network Policies)允许您定义哪些Pod可以与其他Pod通信,以及通信的方式。通过网络策略,您可以限制流量只能从特定源到达特定的Pod,从而增强集群的安全性。
下面是一个简单的网络策略示例,只允许同一Namespace下的Pod可以与Nginx服务的Pod进行通信:
```yaml
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-from-same-namespace
spec:
podSelector:
matchLabels:
app: nginx
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchExpressions:
- key: app
operator: In
values:
- allowed-app
```
### 5.3 TLS证书管理与集群认证
Kubernetes集群中的通信可以通过TLS证书来加密保护,确保数据传输的安全性。合理管理和维护TLS证书对于集群的安全至关重要。此外,集群成员的身份认证也是保护集群安全的一环,可以通过服务账户、证书等方式进行认证管理。
在实际生产环境中,建议定期更新证书、定期轮转密钥,并确保证书的有效性和安全性。
通过本章介绍的内容,您可以更好地理解Kubernetes集群安全与权限管理方面的最佳实践,提升集群的整体安全性。
# 6. Kubernetes集群运维与故障处理
在Kubernetes集群的日常运维中,需要关注集群的可用性、稳定性和高效性。同时,当集群发生故障时,需要快速响应并进行故障处理。本章将介绍Kubernetes集群的运维实践与故障处理策略。
#### 6.1 集群备份与恢复策略
在生产环境中,备份与恢复策略是至关重要的,它可以帮助我们快速有效地应对因各种原因导致的数据丢失或集群损坏情况。对于Kubernetes集群,我们可以采取以下策略进行备份与恢复:
```yaml
# 示例代码: 使用Velero进行Kubernetes集群备份与恢复
# 安装Velero
$ velero install \
--provider aws \
--plugins velero/velero-plugin-for-aws:v1.0.0
# 创建备份
$ velero backup create my-backup
# 恢复备份
$ velero restore create --from-backup my-backup
```
**总结:** 通过Velero工具,我们可以轻松实现Kubernetes集群的备份与恢复,确保集群数据的安全性与可靠性。
#### 6.2 节点故障处理与自愈机制
Kubernetes集群在生产环境中会遇到节点故障的情况,为了保证集群的稳定性,我们需要实施节点故障处理与自愈机制。以下是一个使用Kubernetes的自动伸缩机制来应对节点故障的示例:
```yaml
# 示例代码:使用Kubernetes的水平Pod自动伸缩实现节点故障自愈
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
```
**总结:** 通过水平Pod自动伸缩的方式,Kubernetes集群可以在节点故障时自动增加副本数量,保证服务的可用性与稳定性。
#### 6.3 针对高可用性与性能优化的运维实践
针对高可用性与性能优化的运维实践是Kubernetes集群管理中的重要环节,例如合理配置节点资源、定期清理集群垃圾数据、监控集群负载等。以下是一个利用Prometheus监控集群负载的示例:
```yaml
# 示例代码:使用Prometheus监控集群负载
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: myapp-service-monitor
spec:
selector:
matchLabels:
app: myapp
endpoints:
- port: web
```
**总结:** 通过Prometheus监控集群负载,我们可以及时发现集群的负载情况,做出针对性的优化与调整,确保集群的高可用性和性能。
通过本章的内容,我们深入探讨了Kubernetes集群运维与故障处理的关键实践,帮助读者更好地管理与维护Kubernetes集群。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《后端面试精讲》专栏深入探讨了后端开发领域的重要知识和技能,涵盖了多个关键主题。从深入理解RESTful API设计到数据库基础的关系型和NoSQL比较,再到SQL查询优化和数据缓存策略的讲解,专栏不仅帮助读者建立起扎实的基础,还着重介绍了技术实践中的关键工具和框架,如Spring Boot和Spring Cloud。此外,内容还涵盖了RESTful API的安全设计、持续集成与部署等实用主题,为读者提供了全面的学习路径和实战经验。无论是准备面试还是提升技能,本专栏都将为后端开发者提供深入且全面的知识体系,助力他们在职场中取得成功。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【C#内存管理与事件】:防止泄漏,优化资源利用
# 摘要
本文深入探讨了C#语言中的内存管理技术,重点关注垃圾回收机制和内存泄漏问题。通过分析垃圾回收的工作原理、内存分配策略和手动干预技巧,本文提供了识别和修复内存泄漏的有效方法。同时,本文还介绍了一系列优化C#内存使用的实践技巧,如对象池、引用类型选择和字符串处理策略,以及在事件处理中如何管理内存和避免内存泄漏。此外,文中还讨论了使用内存分析工具和最佳实践来进一步提升应用程序的内存效率。通过对高级内存管理技术和事件处理机制的结合分析,本文旨在为C#开发者提供全面的内存管理指南,以实现高效且安全的事件处理和系统性能优化。
# 关键字
C#内存管理;垃圾回收;内存泄漏;优化内存使用;事件处理
【维护Electron应用的秘诀】:使用electron-updater轻松管理版本更新

# 摘要
随着软件开发模式的演进,Electron应用因其跨平台的特性在桌面应用开发中备受青睐。本文深入探讨了Electron应用版本更新的重要性,详细分析了electron-updater模块的工作机制、
高性能计算新挑战:zlib在大规模数据环境中的应用与策略
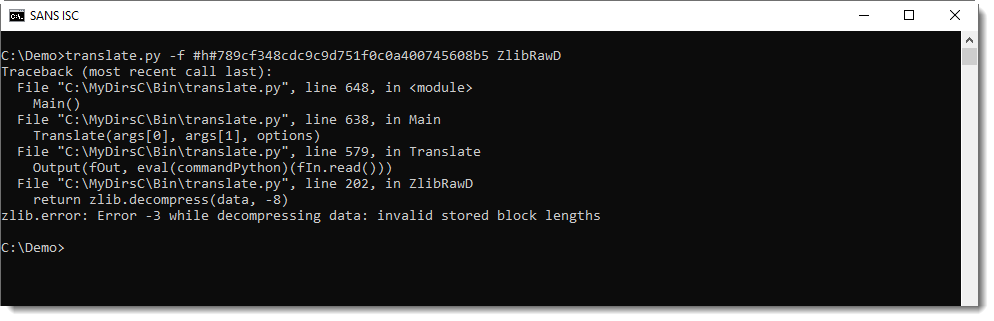
# 摘要
随着数据量的激增,高性能计算成为处理大规模数据的关键技术。本文综合探讨了zlib压缩算法的理论基础及其在不同数据类型和高性能计算环境中的应用实践。文中首先介绍了zlib的设计目标、压缩解压原理以及性能优化策略,然后通过文本和二进制数据的压缩案例,分析了zlib的应用效果。接着探讨了zlib在高性能计算集成、数据流处理优化方面的实际应用,以及在网络传输、分布式存储环境下的性能挑战与应对策略。文章最后对
ADPrep故障诊断手册

# 摘要
ADPrep工具在活动目录(Active Directory)环境中的故障诊断和维护工作中扮演着关键角色。本文首先概述了ADPrep工具的功能和在故障诊断准备中的应用,接着详细分析了常见故障的诊断理论基础及其实践方法,并通过案例展示了故障排查的过程和最佳实践。第三章进一步讨论了常规和高级故障排查技巧,包括针对特定环
步进电机热管理秘籍:散热设计与过热保护的有效策略
# 摘要
本文系统介绍了步进电机热管理的基础知识、散热设计理论与实践、过热保护机制构建以及案例研究与应用分析。首先,阐述了步进电机散热设计的基本原理和散热材料选择的重要性。其次,分析了散热解决方案的创新与优化策略。随后,详细讨论了过热保护的理论基础、硬件实施及软件策略。通过案例研究,本文展示了散热设计与过热保护系统的实际应用和效果评估。最后,本文对当前步进电机热管理技术的挑战、发展前景以及未来研究方向进行了探讨和展望。
SCADA系统网络延迟优化实战:从故障到流畅的5个步骤
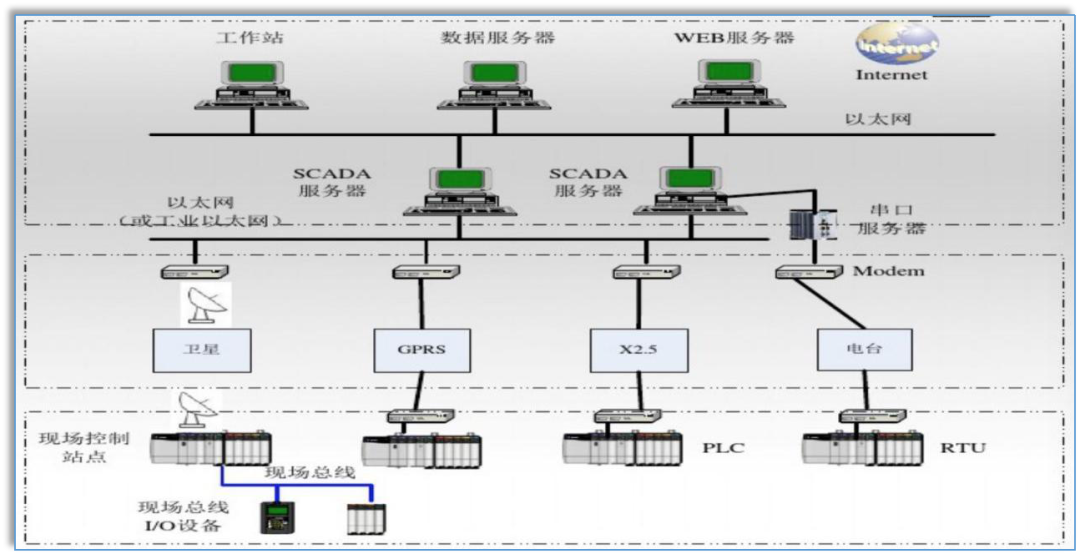
# 摘要
SCADA系统作为工业自动化中的关键基础设施,其网络延迟问题直接影响到系统的响应速度和控制效率。本文从SCADA系统的基本概念和网络延迟的本质分析入手,探讨了延迟的类型及其影响因素。接着,文章重点介绍了网络延迟优化的理论基础、诊断技术和实施策略,以及如何将理论模型与实际情况相结合,提出了一系列常规和高级的优化技术。通过案例分析,本文还展示了优化策略在实际SCADA系统中的应用及其效果评
【USACO数学问题解析】:数论、组合数学在算法中的应用,提升你的算法思维
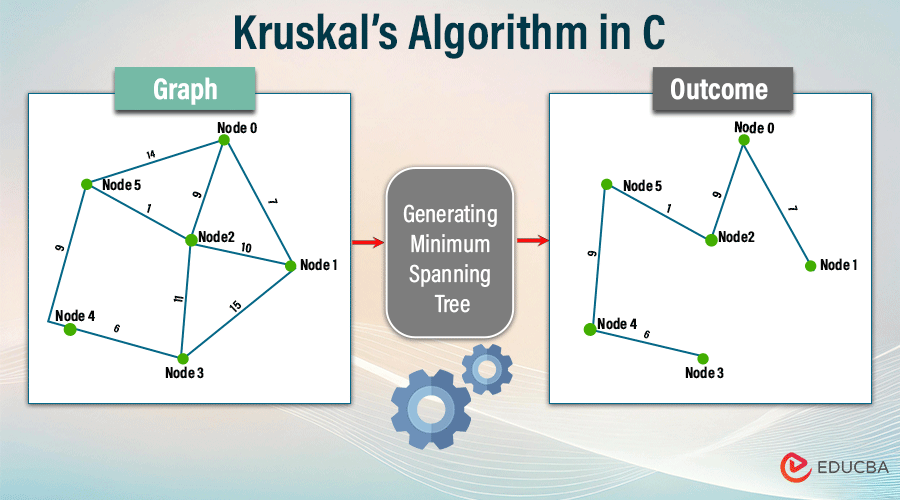
# 摘要
本文探讨了数论和组合数学在USACO算法竞赛中的应用。首先介绍了数论的基础知识,包括整数分解、素数定理、同余理论、欧拉函数以及费马小定理,并阐述了这些理论在USACO中的具体应用和算法优化。接着,文中转向组合数学,分析了排列组合、二项式定理、递推关系和生成函数以及图论基础和网络流问题。最后,本文讨论了USACO算
SONET基础:掌握光纤通信核心技术,提升网络效率

# 摘要
同步光网络(SONET)是一种广泛应用于光纤通信中的传输技术,它提供了一种标准的同步数据结构,以支持高速网络通信。本文首先回顾了SONET的基本概念和历史发展,随后深入探讨了其核心技术原理,包括帧结构、层次模型、信号传输、网络管理以及同步问题。在第三章中,文章详细说明了SONET的网络设计、部署以及故障诊断和处理策略。在实践应用方面,第四章分析了SONET在
SM2258XT固件更新策略:为何保持最新状态至关重要

# 摘要
SM2258XT固件作为固态硬盘(SSD)中的关键软件组件,其更新对设备性能、稳定性和数据安全有着至关重要的作用。本文从固件更新的重要性入手,深入探讨了固件在SSD中的角色、性能提升、以及更新带来的可靠性增强和安全漏洞修复。同时,本文也不忽视固件更新可能带来的风险,讨论了更新失败的后果和评估更新必要性的方法。通过制定和执
Quoted-printable编码:从原理到实战,彻底掌握邮件编码的艺术

# 摘要
Quoted-printable编码是一种用于电子邮件等场景的编码技术,它允许非ASCII字符在仅支持7位的传输媒介中传输。本文首先介绍Quoted-printable编码的基本原理和技术分析,包括编码规则、与MIME标准的关系及解码过程。随后,探讨了Quoted-printable编码在邮件系统、Web开发和数据存储等实战应用中的使用,以及在不同场景下的处理方法。文章还
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )