揭秘Keras与TensorFlow关系:优势与差异大公开
发布时间: 2024-08-21 09:54:53 阅读量: 53 订阅数: 23 

注意就是您所需要的所有keras:变压器的Keras + TensorFlow实现:注意就是您所需要的
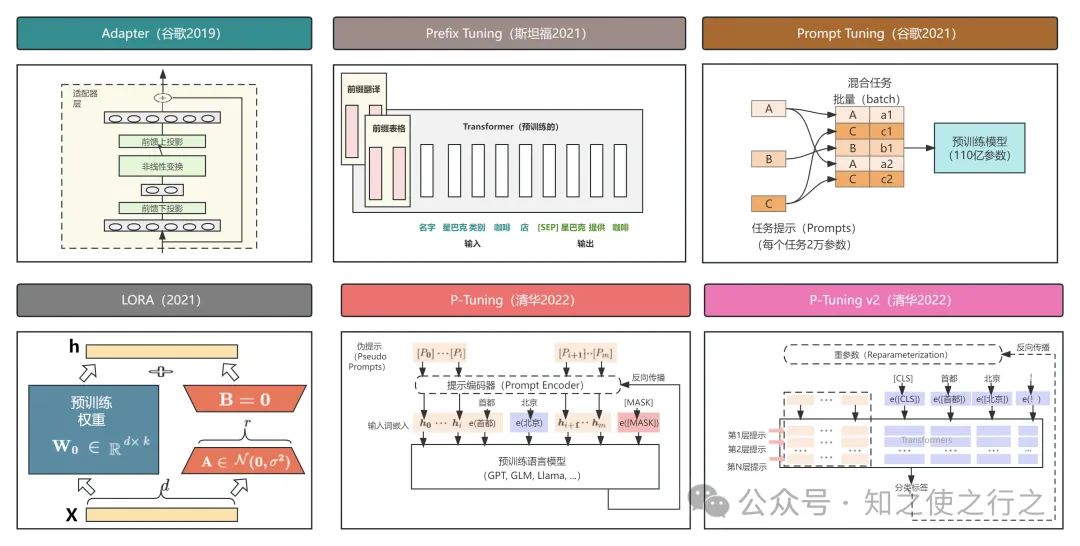
# 1. 神经网络与深度学习简介**
神经网络是一种受人脑神经元启发的机器学习模型,具有强大的特征提取和模式识别能力。深度学习是一种神经网络,具有多个隐藏层,能够从数据中学习复杂的关系和模式。
深度学习模型的结构通常包括输入层、隐藏层和输出层。输入层接收数据,隐藏层处理数据并提取特征,输出层产生预测或决策。隐藏层的数量和神经元的数量决定了模型的复杂性和表示能力。
# 2. Keras与TensorFlow的关系
### 2.1 Keras的概念与架构
**概念**
Keras是一个高级神经网络API,构建在TensorFlow之上。它提供了一个用户友好的界面,使开发和训练神经网络变得更加容易。Keras抽象了TensorFlow的底层复杂性,允许用户专注于模型架构和训练过程。
**架构**
Keras采用模块化架构,由以下组件组成:
- **层(Layers):**神经网络的基本构建块,用于执行特定操作(例如,卷积、池化、激活)。
- **模型(Models):**由层组成的神经网络模型。
- **优化器(Optimizers):**用于更新模型权重的算法。
- **损失函数(Loss Functions):**用于衡量模型预测与实际值之间的差异。
- **评估指标(Metrics):**用于评估模型的性能(例如,准确率、召回率)。
### 2.2 Keras与TensorFlow的底层实现
Keras直接构建在TensorFlow之上,使用TensorFlow作为其后端引擎。这意味着Keras的底层实现依赖于TensorFlow的计算图机制。
**计算图**
TensorFlow使用计算图来表示神经网络模型。计算图是一个有向无环图,其中节点表示操作,边表示数据流。Keras通过一个名为`tf.keras`的模块与TensorFlow的计算图进行交互。
**Eager Execution**
Keras还支持Eager Execution,这是一种TensorFlow的执行模式,允许在定义模型时立即执行操作。这使得调试和原型设计变得更加容易。
**代码示例**
以下代码示例展示了如何使用Keras构建一个简单的线性回归模型:
```python
import tensorflow as tf
from tensorflow.keras import layers
# 创建一个线性回归模型
model = tf.keras.Sequential([
layers.Dense(1, input_shape=(1,))
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(x_train, y_train, epochs=100)
```
**逻辑分析**
此代码示例创建了一个线性回归模型,该模型有一个输入层和一个输出层。输入层有一个神经元,接受一个输入值。输出层有一个神经元,产生一个预测值。模型使用Adam优化器和均方误差损失函数进行编译。然后,模型使用训练数据进行训练,训练100个epoch。
**参数说明**
- `x_train`: 训练数据的输入特征。
- `y_train`: 训练数据的目标值。
- `epochs`: 训练模型的epoch数。
# 3. Keras与TensorFlow的优势对比**
**3.1 Keras的优势**
**3.1.1 高级API,易于使用**
Keras提供了一个高级API,极大地简化了神经网络的构建和训练过程。其API设计直观且面向对象,使得开发者能够轻松地创建和配置复杂的神经网络模型。
```python
# 导入Keras库
import keras
# 创建一个简单的顺序模型
model = keras.Sequential()
# 添加一个密集层
model.add(keras.layers.Dense(units=10, activation='relu', input_dim=784))
# 添加一个输出层
model.add(keras.layers.Dense(units=10, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
```
**参数说明:**
* `units`: 输出层的单元数
* `activation`: 激活函数
* `input_dim`: 输入数据的维度
* `optimizer`: 优化器
* `loss`: 损失函数
* `metrics`: 评估指标
**代码逻辑分析:**
1. 导入Keras库。
2. 创建一个顺序模型,这是一个线性堆叠的层序列。
3. 添加一个密集层,它是一个全连接层。
4. 添加一个输出层,它是一个softmax激活的分类层。
5. 编译模型,指定优化器、损失函数和评估指标。
**3.1.2 丰富的预训练模型**
Keras提供了大量的预训练模型,涵盖了图像分类、自然语言处理、计算机视觉等多个领域。这些预训练模型可以在各种任务中作为特征提取器或微调基础,极大地提高了模型开发效率。
**3.2 TensorFlow的优势**
**3.2.1 底层控制,灵活性强**
TensorFlow是一个低级库,它提供了对底层计算图的直接访问。这使得开发者能够完全控制模型的构建和训练过程,实现高度定制化和灵活性。
```python
# 导入TensorFlow库
import tensorflow as tf
# 创建一个计算图
graph = tf.Graph()
# 创建一个会话
sess = tf.Session(graph=graph)
# 创建一个占位符,作为模型输入
x = tf.placeholder(tf.float32, shape=[None, 784])
# 创建一个变量,作为模型参数
W = tf.Variable(tf.random.normal([784, 10]))
# 创建一个运算,计算模型输出
y = tf.matmul(x, W)
# 创建一个损失函数
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=y))
# 创建一个优化器
optimizer = tf.train.AdamOptimizer(learning_rate=0.01)
# 创建一个训练操作
train_op = optimizer.minimize(loss)
# 初始化变量
sess.run(tf.global_variables_initializer())
# 训练模型
for epoch in range(10):
# 获取训练数据
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 训练模型
sess.run(train_op, feed_dict={x: x_train, y: y_train})
# 评估模型
accuracy = sess.run(tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y, 1), tf.argmax(y_test, 1)), tf.float32)))
print(f'Epoch {epoch}: Accuracy = {accuracy}')
```
**参数说明:**
* `shape`: 占位符或变量的形状
* `learning_rate`: 优化器的学习率
* `logits`: 模型输出,未经过softmax激活
* `labels`: 真实标签
**代码逻辑分析:**
1. 导入TensorFlow库。
2. 创建一个计算图。
3. 创建一个会话。
4. 创建一个占位符,作为模型输入。
5. 创建一个变量,作为模型参数。
6. 创建一个运算,计算模型输出。
7. 创建一个损失函数。
8. 创建一个优化器。
9. 创建一个训练操作。
10. 初始化变量。
11. 训练模型。
12. 评估模型。
# 4. Keras与TensorFlow的差异分析**
**4.1 模型构建方式**
* **Keras:**
- 高级API,面向模型结构和训练过程,简化模型构建。
- 提供预定义的层和模型,支持快速搭建复杂神经网络。
- 代码示例:
```python
from keras.models import Sequential
from keras.layers import Dense, Activation
# 创建顺序模型
model = Sequential()
# 添加隐藏层
model.add(Dense(units=100, activation='relu', input_dim=784))
# 添加输出层
model.add(Dense(units=10, activation='softmax'))
```
* **TensorFlow:**
- 低级API,直接操作张量和计算图,提供更细粒度的控制。
- 要求手动定义计算图,包括变量、操作和数据流。
- 代码示例:
```python
import tensorflow as tf
# 创建变量
x = tf.Variable(tf.zeros([100, 784]))
# 创建计算图
hidden_layer = tf.nn.relu(tf.matmul(x, tf.Variable(tf.random.normal([784, 100]))))
output_layer = tf.nn.softmax(tf.matmul(hidden_layer, tf.Variable(tf.random.normal([100, 10]))))
```
**4.2 训练过程控制**
* **Keras:**
- 提供内置的训练循环,简化训练过程。
- 支持各种优化器、损失函数和训练策略。
- 代码示例:
```python
# 编译模型
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
```
* **TensorFlow:**
- 训练过程完全可定制,提供更灵活的控制。
- 需要手动定义训练操作和优化器。
- 代码示例:
```python
# 创建优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# 创建训练操作
train_op = optimizer.minimize(loss, var_list=[x, w1, w2])
# 训练模型
for epoch in range(10):
for batch in range(num_batches):
# 执行训练操作
optimizer.run(train_op)
```
**4.3 部署和生产**
* **Keras:**
- 提供易于部署的模型格式(如HDF5、TF-Lite)。
- 支持云平台和边缘设备部署。
- 代码示例:
```python
# 保存模型
model.save('my_model.h5')
# 加载模型
model = keras.models.load_model('my_model.h5')
```
* **TensorFlow:**
- 提供多种部署选项,包括SavedModel、TF-Serving和TensorFlow Lite。
- 支持自定义部署管道和优化。
- 代码示例:
```python
# 保存模型
tf.saved_model.save(model, 'my_model')
# 加载模型
model = tf.saved_model.load('my_model')
```
# 5. Keras与TensorFlow的应用实践
### 5.1 Keras实战示例
#### 5.1.1 图像分类
**代码块:**
```python
# 导入必要的库
import tensorflow as tf
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Flatten, Dense, Dropout
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 归一化输入数据
x_train, x_test = x_train / 255.0, x_test / 255.0
# 创建顺序模型
model = Sequential([
Flatten(input_shape=(28, 28)),
Dense(128, activation='relu'),
Dropout(0.2),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10)
# 评估模型
model.evaluate(x_test, y_test)
```
**参数说明:**
- `mnist.load_data()`: 加载 MNIST 数据集,返回训练集和测试集。
- `x_train, x_test = x_train / 255.0, x_test / 255.0`: 归一化输入数据,将像素值缩放到 0 到 1 之间。
- `Sequential()`: 创建一个顺序模型,其中层按顺序堆叠。
- `Flatten()`: 将输入数据展平为一维数组。
- `Dense()`: 添加一个全连接层,指定神经元数量和激活函数。
- `Dropout()`: 添加一个 Dropout 层,以防止过拟合。
- `model.compile()`: 编译模型,指定优化器、损失函数和指标。
- `model.fit()`: 训练模型,指定训练数据、批次大小和时代数。
- `model.evaluate()`: 评估模型,指定测试数据和指标。
#### 5.1.2 自然语言处理
**代码块:**
```python
# 导入必要的库
import tensorflow as tf
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import Embedding, LSTM, Dense
# 加载文本数据
with open('text_data.txt', 'r') as f:
text = f.read()
# 分词和向量化
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text])
sequences = tokenizer.texts_to_sequences([text])
padded_sequences = pad_sequences(sequences, maxlen=100)
# 创建顺序模型
model = Sequential([
Embedding(len(tokenizer.word_index) + 1, 128),
LSTM(128),
Dense(1, activation='sigmoid')
])
# 编译模型
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(padded_sequences, y_train, epochs=10)
# 评估模型
model.evaluate(padded_sequences, y_test)
```
**参数说明:**
- `Tokenizer()`: 将文本数据分词并转换为整数序列。
- `texts_to_sequences()`: 将文本转换为整数序列。
- `pad_sequences()`: 将序列填充到相同长度。
- `Embedding()`: 将整数序列嵌入到稠密向量中。
- `LSTM()`: 添加一个长短期记忆 (LSTM) 层。
- `Dense()`: 添加一个全连接层,指定神经元数量和激活函数。
- `model.compile()`: 编译模型,指定优化器、损失函数和指标。
- `model.fit()`: 训练模型,指定训练数据、批次大小和时代数。
- `model.evaluate()`: 评估模型,指定测试数据和指标。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Keras,一个强大的深度学习框架,涵盖了从入门指南到高级技巧的各个方面。通过一系列详尽的文章,您将了解 Keras 与 TensorFlow 的关系,掌握 Keras 层和模型,学习高效的数据预处理和模型训练技巧。专栏还深入探讨了过拟合和欠拟合问题,以及优化训练时间和内存使用的方法。此外,您将了解 Keras 模型预测不准确的原因,以及如何通过并行化训练和部署模型来提高效率和准确性。最后,专栏提供了关于 Keras 可解释性、迁移学习、生成对抗网络、自然语言处理和计算机视觉的实用指南,使您能够构建和部署强大的深度学习模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
高效DSP编程揭秘:VisualDSP++代码优化的五大策略

# 摘要
本文全面介绍了VisualDSP++开发环境,包括其简介、基础编程知识、性能优化实践以及高级应用案例分析。首先,文中概述了VisualDSP++的环境搭建、基本语法结构以及调试工具的使用,为开发者提供了一个扎实的编程基础。接着,深入探讨了在代码、算法及系统三个层面的性能优化策略,旨在帮助开发者提升程序的运行效率。通过高级应用和案例分析,本文展示了VisualD
BRIGMANUAL高级应用技巧:10个实战方法,效率倍增

# 摘要
BRIGMANUAL是一种先进的数据处理和管理工具,旨在提供高效的数据流处理与优化,以满足不同环境下的需求。本文首先介绍BRIGMANUAL的基本概念和核心功能,随后深入探讨了其理论基础,包括架构解析、配置优化及安全机制。接着,本文通过实战技巧章节,展示了如何通过该工具优化数据处理和设计自动化工作流。文章还具体分析了BRIGMANUAL在大数据环境、云服务平台以及物联网应用中的实践案例。最后,文
QNX Hypervisor调试进阶:专家级调试技巧与实战分享

# 摘要
QNX Hypervisor作为一种先进的实时操作系统虚拟化技术,对于确保嵌入式系统的安全性和稳定性具有重要意义。本文首先介绍了QNX Hypervisor的基本概念,随后详细探讨了调试工具和环境的搭建,包括内置与第三方调试工具的应用、调试环境的配置及调试日志的分析方法。在故障诊断方面,本文深入分析了内存泄漏、性能瓶颈以及多虚拟机协同调试的策略,并讨论了网络和设备故障的排查技术。此外,文中还介绍了QNX Hypervis
协议层深度解析:高速串行接口数据包格式与传输协议
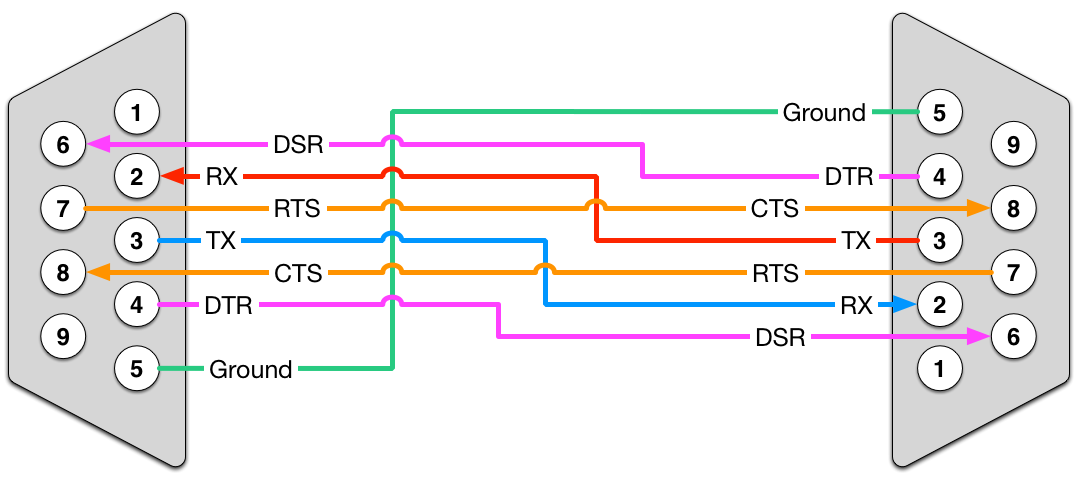
# 摘要
高速串行接口技术是现代数据通信的关键部分,本文对高速串行接口的数据包概念、结构和传输机制进行了系统性的介绍。首先,文中阐述了数据包的基本概念和理论框架,包括数据包格式的构成要素及传输机制,详细分析了数据封装、差错检测、流量控制等方面的内容。接着,通过对比不同高速串行接口标准,如USB 3.0和PCI Express,进一步探讨了数据包格式的实践案例分析,以及数据包的生成和注入技术。第四章深入分析了传输协议的特性、优化策略以及安全
SC-LDPC码性能评估大公开:理论基础与实现步骤详解
# 摘要
低密度奇偶校验(LDPC)码,特别是短周期LDPC(SC-LDPC)码,因其在错误校正能力方面的优势而受到广泛关注。本文对SC-LDPC码的理论基础、性能评估关键指标和优化策略进行了全面综述。首先介绍了信道编码和迭代解码原理,随后探讨了LDPC码的构造方法及其稀疏矩阵特性,以及SC-LDPC码的提出和发展背景。性能评估方面,本文着重分析了误码率(BER)、信噪比(SNR)、吞吐量和复杂度等关键指标,并讨论了它们在SC-LDPC码性能分析中的作用。在实现步骤部分,本文详细阐述了系统模型搭建、仿真实验设计、性能数据收集和数据分析的流程。最后,本文提出了SC-LDPC码的优化策略,并展望了
CU240BE2调试速成课:5分钟掌握必备调试技巧

# 摘要
本文详细介绍了CU240BE2变频器的应用与调试过程。从基础操作开始,包括硬件连接、软件配置,到基本参数设定和初步调试流程,以及进阶调试技巧,例如高级参数调整、故障诊断处理及调试工具应用。文章通过具体案例分析,如电动机无法启动
【Dos与大数据】:应对大数据挑战的磁盘管理与维护策略

# 摘要
随着大数据时代的到来,磁盘管理成为保证数据存储与处理效率的重要议题。本文首先概述了大数据时代磁盘管理的重要性,并从理论基础、实践技巧及应对大数据挑战的策略三个维度进行了系统分析。通过深入探讨磁盘的硬件结构、文件系统、性能评估、备份恢复、分区格式化、监控维护,以及面向大数据的存储解决方案和优化技术,本文提出了适合大数据环境的磁盘管理策略。案例分析部分则具体介绍
【电脑自动关机问题全解析】:故障排除与系统维护的黄金法则

# 摘要
电脑自动关机问题是一个影响用户体验和数据安全的技术难题,本文旨在全面概述其触发机制、可能原因及诊断流程。通过探讨系统命令、硬件设置、操作系统任务等触发机制,以及软件冲突、硬件故障、病毒感染和系统配置错误等可能原因,本文提供了一套系统的诊断流程,包括系统日志分析、硬件测试检查和软件冲突
MK9019故障排除宝典:常见问题的诊断与高效解决方案
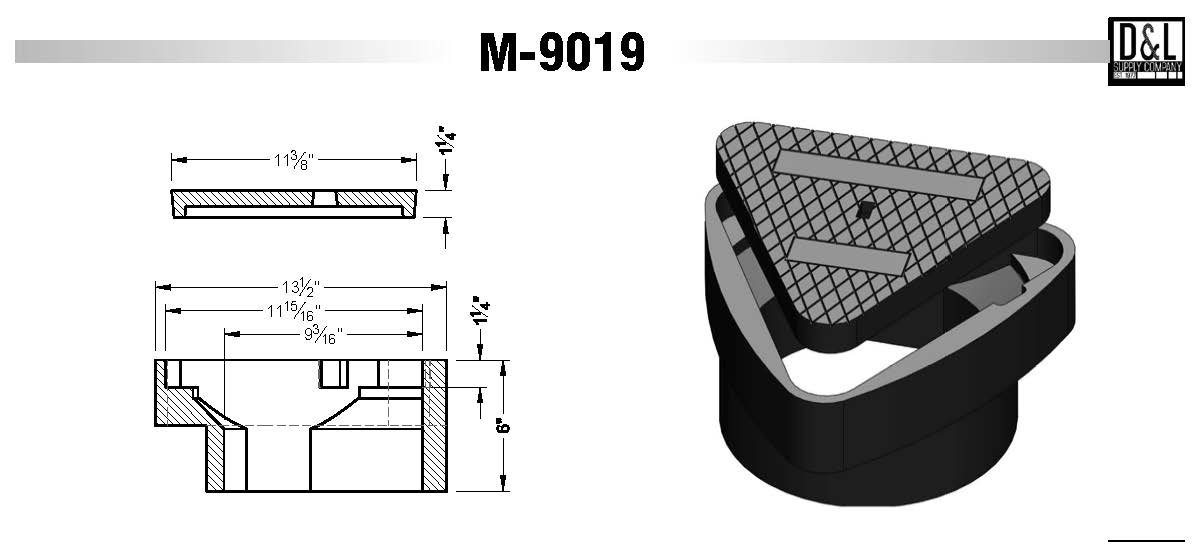
# 摘要
MK9019作为一种复杂设备,在运行过程中可能会遇到各种故障问题,从而影响设备的稳定性和可靠性。本文系统地梳理了MK9019故障排除的方法和步骤,从故障诊断基础到常见故障案例分析,再到高级故障处理技术,最后提供维护与预防性维护指南。重点介绍了设备硬件架构、软件系统运行机制,以及故障现象确认、日志收集和环境评估等准备工作。案例分析部分详细探讨了硬件问题、系统崩溃、性能问题及其解决方案。同时,本文还涉及
LTE-A技术新挑战:切换重选策略的进化与实施

# 摘要
本文首先介绍了LTE-A技术的概况,随后深入探讨了切换重选策略的理论基础、实现技术和优化实践。在切换重选策略的理论基础部分,重点分析了LTE-A中切换重选的定义、与传统LTE的区别以及演进过程,同时指出了切换重选过程中可能遇到的关键问题。实现技术章节讨论了自适应切换、多连接切换以及基于负载均衡的切换策略,包括其原理和应用场景。优化与实践章节则着重于切换重选参数的优化、实时监测与自适应调整机制以及切换重选策略的测试与评估方法。最
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )