Python多重继承陷阱全解析:避免问题的终极指南
发布时间: 2024-09-18 21:38:41 阅读量: 103 订阅数: 37 

Python多重继承的方法解析执行顺序实例分析
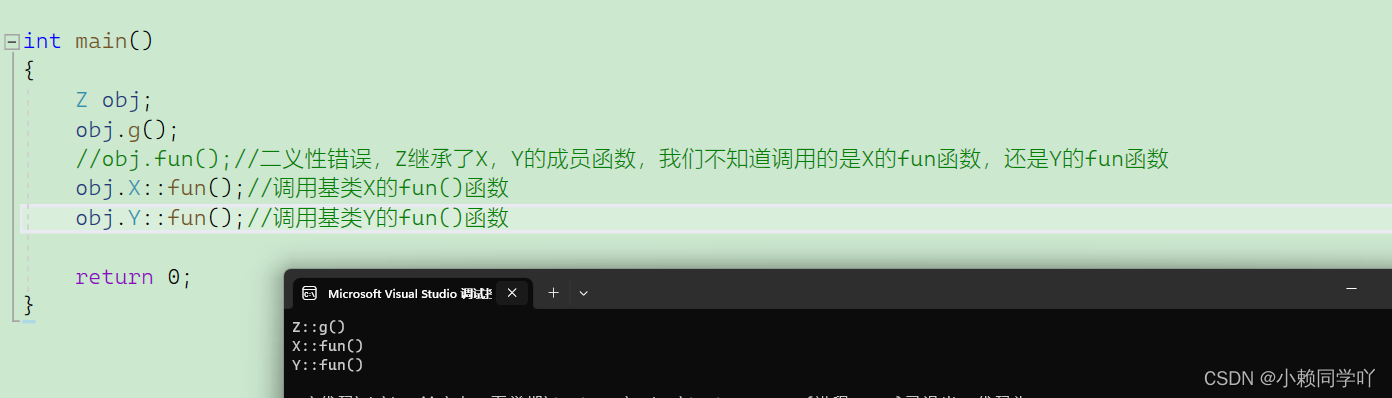
# 1. 多重继承的初衷与概念
在面向对象编程(OOP)中,多重继承是一种能够创建包含两个或更多父类的子类的机制。这种概念起源于编程语言设计的初衷之一——代码复用。多重继承允许开发者在设计软件时更灵活地利用已有的类,实现功能的组合和扩展。然而,它也引入了复杂性,尤其是在确定方法调用顺序和解决潜在的命名冲突时。Python语言对多重继承支持得比较好,提供了一个优雅的解决方案来处理这些复杂情况,接下来我们将深入探讨Python中的多重继承机制。
# 2. Python多重继承的工作原理
## 2.1 Python类继承机制
### 2.1.1 类、子类与超类的关系
在Python中,类之间的继承关系是一个基本面向对象编程概念。当创建一个类时,可以明确指定它的父类(也叫基类或超类),这样子类就继承了父类的所有属性和方法。这种机制允许创建一个新类(子类),通过继承的方式复用已有类(超类)的功能。例如:
```python
class Animal:
def __init__(self):
print("Animal created")
class Mammal(Animal):
def __init__(self):
super().__init__() # 调用父类的构造函数
print("Mammal created")
class Dog(Mammal):
def __init__(self):
super().__init__() # 继续向上调用,形成继承链
print("Dog created")
```
在这个例子中,`Dog` 类继承自 `Mammal` 类,而 `Mammal` 类又继承自 `Animal` 类。当实例化 `Dog` 类时,会依次执行所有超类的构造函数。
### 2.1.2 方法解析顺序(MRO)的定义和影响
Python使用C3线性化算法来计算方法解析顺序(MRO),确保类继承中方法调用的一致性和正确性。MRO是类及其父类的方法解析顺序列表,它确定了在多继承的情况下,Python解释器查找方法的顺序。
一个类的MRO可以通过`__mro__`属性或者`mro()`方法获得:
```python
print(Dog.__mro__)
# 或者
print(Dog.mro())
```
输出将会是:
```
(<class '__main__.Dog'>, <class '__main__.Mammal'>, <class '__main__.Animal'>, <class 'object'>)
```
MRO对多重继承非常重要,因为它决定了调用方法时,解释器将查找哪些基类。MRO列表中,一个类只会出现一次,即使是多个超类的共同子类,也能保证方法调用的唯一性和无二义性。
## 2.2 多重继承的内部实现
### 2.2.1 C3线性化算法解析
C3线性化算法是一种计算类继承结构的方法解析顺序的算法。C3算法的核心思想是首先满足所有超类的要求,再满足当前类的要求,确保继承体系中没有循环依赖,并保持一定的顺序。
C3线性化算法的一个关键操作是合并操作,用以合并所有父类的线性化结果。具体合并操作的规则是:
1. 选择第一个类(如果它在所有列表中都可用)。
2. 移除这个类以及它出现在所有列表中的位置。
3. 重复以上步骤,直到没有剩余的类。
在Python的实现中,`super()`函数在内部实际上依赖于C3算法来确定MRO。
### 2.2.2 方法解析顺序对继承的影响
方法解析顺序(MRO)在多重继承中影响方法和属性的查找过程。当调用一个方法时,Python会按照MRO列表从左至右的顺序在类中查找该方法。只有当找不到该方法时,才会继续沿MRO链向上搜索。
这可以导致一些意料之外的行为,尤其是当几个父类提供同名方法时。例如,如果`Mammal`和`Bird`是`Animal`的两个子类,并且它们都重写了`fly`方法。当`FlyingMammal`(多重继承自`Mammal`和`Bird`)调用`fly`方法时,将遵循MRO的顺序来确定调用`Mammal.fly`或`Bird.fly`。
## 2.3 多重继承与钻石问题
### 2.3.1 钻石问题的定义及其在多重继承中的表现
钻石问题(也称为菱形继承问题)是指在多重继承场景中,当两个超类继承自同一个基类,那么同一个基类会在子类的MRO中重复出现。这会导致子类继承了两个超类的属性和方法,可能会产生冲突。
以一个经典的钻石问题示例说明:
```python
class A:
def show(self):
print("Class A")
class B(A):
pass
class C(A):
def show(self):
print("Class C")
class D(B, C):
pass
d = D()
d.show() # 输出什么?
```
由于C3线性化,`D`类的MRO为`[D, B, C, A]`。因此,调用`d.show()`将输出`"Class C"`,因为`show`方法在MRO列表中第一次出现的地方是`C`类。
### 2.3.2 Python处理钻石问题的策略和实例
Python通过其C3线性化算法处理了钻石问题。该算法保证了当多重继承导致继承链中出现重复基类时,每个类只会在MRO中出现一次,并且正确地优先选择最直接的超类。
为了解决这个问题,Python在类定义时就预先计算好了MRO,确保了调用方法时的一致性和可预测性。这种处理方式避免了传统C++等语言在多重继承时需要通过虚拟基类等方式解决的复杂性。
例如,在上节的钻石问题示例中,尽管`B`和`C`都是`A`的子类,`D`类的MRO中只包含了一个`A`类实例。这样当调用`show`方法时,只会调用`C`类的实现,因为`C`是`D`类的直接超类。
```python
print(D.__mro__)
# 输出 (<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)
```
通过这个策略,Python成功地处理了多重继承中的钻石问题,确保了方法和属性的正确解析,同时避免了在继承图中形成循环依赖。
# 3. 多重继承的实际应用与风险
## 3.1 多重继承的实用案例分析
### 3.1.1 混入(Mixins)与代码复用
在Python中,多重继承的一个重要应用是混入(Mixins),它们是一种提供小型功能模块的类,可以被其他类重用。Mixins旨在实现代码复用,同时避免了传统单继承体系的局限性。每个Mixin通常只负责提供一组相关的方法,而不会影响到类的主继承路径。以下是一个典型的Mixin使用案例。
```python
class LoggedMappingMixin:
"""
Add logging to get/set/delete operations for debugging.
"""
def __getitem__(self, key):
print(f"Getting {key}")
return super().__getitem__(key)
def __setitem__(self, key, value):
print(f"Setting {key} to {value}")
return super().__setitem__(key, value)
def __delitem__(self, key):
print(f"Deleting {key}")
return super().__delitem__(key)
class SetOnceMappingMixin:
"""
Only allow a key to be set once.
"""
def __setitem__(self, key, value):
if key in self:
raise KeyError(f"{key} already set")
return super().__setitem__(key, value)
# Mixin的使用
class DictWithLogging(LoggedMappingMixin, dict):
pass
# 这样,我们创建了一个能够记录get/set/delete操作的字典
d = DictWithLogging()
d['x'] = 100
print(d['x'])
del d['x']
```
在上述代码中,我们首先定义了两个Mixin类:`LoggedMappingMixin` 与 `SetOnceMappingMixin`。`LoggedMappingMixin` 添加了日志

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 类设计的各个方面,从基础概念到高级实践。涵盖了继承、装饰器、属性、方法、设计模式、私有化、序列化、内存管理、反射、特殊方法等主题。通过深入浅出的讲解和丰富的代码示例,帮助读者掌握 Python 类设计精髓,编写优雅、可复用、高效的代码。本专栏旨在为 Python 开发者提供全面的指南,提升他们在类设计方面的技能,从而构建更强大、更灵活的应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )