Python调用MATLAB自然语言处理集成:跨语言自然语言处理任务,拓展语言处理能力
发布时间: 2024-06-09 02:51:39 阅读量: 73 订阅数: 47 

使用 Python 分析处理自然语言
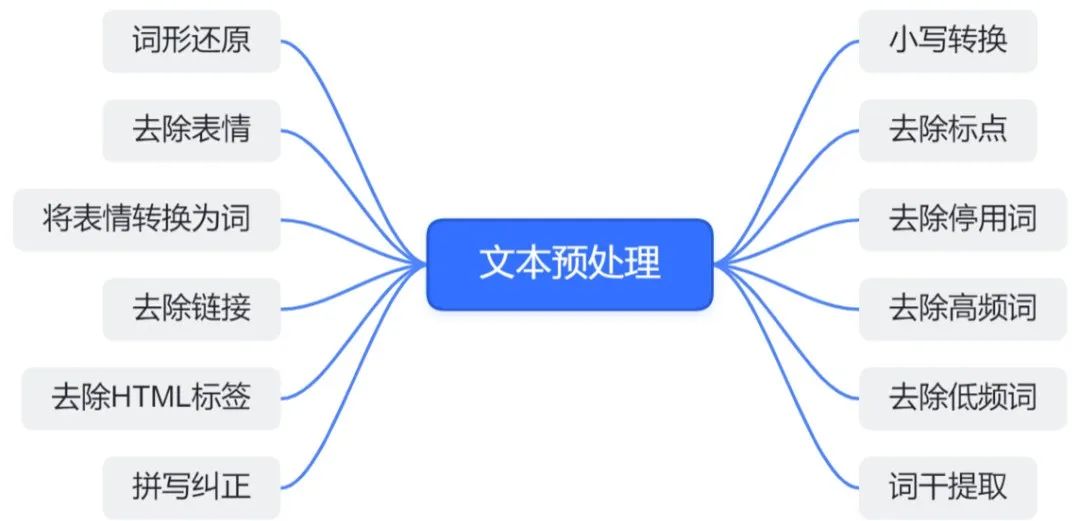
# 1. 跨语言自然语言处理概述**
跨语言自然语言处理 (NLP) 涉及在不同语言之间处理和分析文本数据。它允许组织跨越语言障碍进行有效沟通,并从多语言数据中提取有价值的见解。
跨语言 NLP 的关键挑战包括:
- **语言差异:**不同语言具有独特的语法、语义和文化背景,需要专门的处理技术。
- **数据稀疏性:**特定语言的文本数据可能有限,导致训练和评估模型的困难。
- **翻译错误:**机器翻译工具可能产生不准确或有偏差的翻译,影响 NLP 任务的性能。
# 2. Python和MATLAB自然语言处理库
### 2.1 Python自然语言处理库
Python拥有丰富的自然语言处理库,可满足各种NLP任务的需求。以下介绍三个最流行的库:
#### 2.1.1 NLTK
NLTK(Natural Language Toolkit)是一个广泛使用的Python NLP库,提供了一系列工具,包括:
- 文本分词和词性标注
- 句法分析和语义分析
- 机器学习算法和预训练模型
- 语料库和资源
**代码块:**
```python
import nltk
# 文本分词
text = "Natural Language Processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human (natural) languages."
tokens = nltk.word_tokenize(text)
print(tokens)
# 词性标注
tagged_tokens = nltk.pos_tag(tokens)
print(tagged_tokens)
```
**逻辑分析:**
* `nltk.word_tokenize()`函数将文本分词为单词或符号。
* `nltk.pos_tag()`函数对单词进行词性标注,确定每个单词的词性(例如,名词、动词、形容词)。
#### 2.1.2 spaCy
spaCy是一个高性能的NLP库,专注于速度和准确性。它提供以下功能:
- 预训练的语言模型
- 文本分词、词性标注和句法分析
- 命名实体识别
- 关系提取
**代码块:**
```python
import spacy
# 加载预训练模型
nlp = spacy.load("en_core_web_sm")
# 文本分词和词性标注
doc = nlp("Natural Language Processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human (natural) languages.")
for token in doc:
print(token.text, token.pos_)
# 命名实体识别
for ent in doc.ents:
print(ent.text, ent.label_)
```
**逻辑分析:**
* `spacy.load()`函数加载预训练的语言模型。
* `doc = nlp()`对文本进行处理,生成一个`Doc`对象,其中包含分词、词性标注和句法分析信息。
* `doc.ents`属性包含识别出的命名实体。
#### 2.1.3 Gensim
Gensim是一个专注于主题建模和词嵌入的NLP库。它提供以下功能:
- 文本预处理和特征提取
- 主题建模(LDA、LSI)
- 词嵌入(Word2Vec、GloVe)

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 和 MATLAB 之间的跨语言调用,揭示了其背后的交互机制,并提供了实用指南。通过一系列文章,专栏涵盖了数据共享、算法协作、性能优化、并行计算、跨平台交互、自动化技巧、数据类型转换、版本兼容性、安全性考量、图像处理、机器学习、数据分析、科学计算、金融建模、优化算法、图像识别和自然语言处理等方面的跨语言协作。专栏旨在帮助读者了解和掌握 Python 和 MATLAB 之间的无缝衔接,解锁跨语言协作的潜力,提升效率,并释放数据价值。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
编程圣诞树的艺术:掌握代码绘制与视觉创意技巧

# 摘要
编程圣诞树的艺术不仅展现了程序员的创意,也是对编程技能和视觉艺术感的考验。本文首先介绍了编程圣诞树的基本概念和艺术价值,然后详细探讨了实现圣诞树绘制的基础知识,包括选择编程语言和图形库,理解图形渲染原理,以及构建层次渲染逻辑。接着,文章分析了视觉创意和代码优化的实践,包括色彩搭配、装饰物添加、性能优化和兼容性测试。跨平台部署和分享环节讲述了程序的编译、打包和开源协作
KUKA外部轴配置数据管理:高效记录与分析的策略

# 摘要
本文全面介绍了KUKA外部轴的基础知识、数据记录与管理方法、数据分析技巧以及实践应用,并对未来趋势进行了展望。文章首先对KUKA外部轴的数据结构、记录格式标准和管理工具进行了深入探讨,并提出了高效数据记录的最佳实践和预防常见错误的方法。接着,文章详细分析了数据分析的理论基础、高级技术以及可视化技术,强调了它们在外部轴数据管理
从理论到实践:喇叭天线仿真案例的全方位分析与解读
# 摘要
喇叭天线作为高频通信领域的重要组成部分,其设计与仿真技术对于提高天线性能至关重要。本文首先概述了喇叭天线仿真技术的基础知识,接着深入介绍了喇叭天线的理论基础、设计原理以及辐射模式分析。第三章详细介绍了当前流行的仿真软件工具的选用、配置和操作方法。第四章阐述了喇叭天线仿真实践中的操作流程,包括仿真参数的设定、环境配置、执行监控、结果分析和优化设计。最后一章通过具体
【论文写作工具箱】:GBT7714格式参考文献生成器使用指南

# 摘要
本文对GBT7714格式参考文献生成器进行了全面的介绍和分析。首先概述了GBT7714格式参考文献生成器的基本概念及其在学术写作中的重要性,随后详细解读了GBT7714格式的历史背景、标准沿革、结构组成以及排版工具的选择。在实操指南部分,探讨了生成器的选择与安装过程、基本操作流程及常见问题的解决方法。进一步,本文深入探讨了生成器的高级应用,如自定义格式、批量处
【DCWS-6028-PRO命令行基础】:入门指南与常用命令解析
# 摘要
本文全面介绍了DCWS-6028-PRO命令行界面的基础操作和高级应用。第一章提供了命令行界面的概述,第二章则详细介绍了命令行操作的基础知识,包括命令结构、文件系统导航以及文件和目录的管理方法。第三章探讨了命令行环境的配置,重点讲解环境变量设置、提示符定制以及高级Shell配置技巧。第四章着重于命令行脚本的编写、调试和自动化任务管理,旨在帮助用户提升工作效率。最后,第五章聚焦于命令
高级定制DBGridEh:24小时掌握自定义绘制单元格
# 摘要
本文深入探讨了DBGridEh组件的自定义绘制机制和实践技巧。首先概述了DBGridEh的基础知识,随后深入分析了其自定义绘制的核心组件,API和方法以及绘制过程中数据与视图的同步方式。第三章展示了创建复杂单元格视觉效果、实现动态数据更新及高级绘制功能的实践技巧。进阶应用章节讲述了如何通过集成第三方控件、
【SMCDraw气路图绘制软件2.21版性能优化秘籍】:实现速度与效率的双重飞跃
# 摘要
本文介绍了SMCDraw气路图绘制软件的功能、性能优化理论与实践操作,并探讨了该软件的高级优化技巧及其未来展望。首先概述了SMCDraw软件的设计和基础性能评估方法,然后详细阐述了在不同模块上应用性能优化策略的步骤和效果,包括绘制引擎、图形渲染和用户界面的改进。此外,文章还探讨了代码级别的优化、数据库性能调优以及如何通过插件系统和定制
天线设计全攻略:从理论到实践,Ansoft场计算器案例分析
# 摘要
本文全面介绍了天线设计的基础理论、参数指标和实践应用。首先探讨了电磁波的产生、传播以及天线的工作原理,进而详细阐述了天线关键参数如增益、辐射方向图、输入阻抗等,并讨论了不同天线类型在具体应用场景中的选择。文章接着介绍了Ansoft HFSS软件中的场计算器在天线设计中的作用、操作环境以及模拟流程。通过具体案例,分析了单极天线、微带贴片天线和天线阵列的设计、优化和仿
数据中心加速器:DWC USB 3.0提升数据交换效率的策略

# 摘要
随着数据中心对效率和性能要求的提升,数据中心加速器技术显得愈发重要。DWC USB 3.0技术作为其中的佼佼者,因其高速的传输速率和优越的性能在硬件加速领域备受关注。本文详细探讨了DWC USB 3.0的基础技术规格、硬件加速原理以及DWC技术的独特优势。同时,本文提出了多种提升数据交换效率的策略,从系统级优化到应用层实践,再到实时监控
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )