运用SAP HANA数据库进行实时分析与处理
发布时间: 2024-04-13 05:25:13 阅读量: 108 订阅数: 70 

敏华控股:SAP HANA实时引擎助敏华提升财务分析和决策支持效率,改善盈利能力

# 1. SAP HANA数据库的背景与概述
SAP HANA数据库作为SAP公司的旗舰产品,是一款基于内存技术的关系数据库管理系统。其推出背景主要源于对传统磁盘存储系统性能瓶颈的挑战,为了满足企业对实时分析和处理的需求。HANA数据库具有内存数据库的优势,能够将数据加载到内存中进行处理,极大提升了数据处理速度。同时,HANA还具备强大的实时处理能力,能够支持企业级的实时报表分析和决策支持。
随着数字化转型的加速和大数据技术的兴起,SAP HANA数据库在企业应用中发挥着越来越重要的作用。其技术特点和优势为企业提供了更高效、更智能的数据处理解决方案,助力企业实时把握商业机会。
通过本章我们将深入了解SAP HANA数据库的背景、技术特点和应用优势,为后续章节的内容铺垫打下基础。
# 2. SAP HANA数据库的架构及特性
SAP HANA数据库作为一款内存数据库,其架构设计非常独特,结合了多种先进技术,使得其在数据存储与处理方面具有很高的效率和性能。
### 2.1 数据存储与处理
#### 2.1.1 In-Memory Computing
In-Memory Computing是SAP HANA数据库的核心特点之一,将数据完全存储在内存中,不再需要从磁盘读取数据,大大提升了数据处理速度。例如,以下是一个演示代码段,展示了如何在HANA中创建一个内存表:
```sql
CREATE COLUMN TABLE Products (
ProductID INT,
ProductName NVARCHAR(50),
Price DECIMAL(10, 2)
) WITH PARAMETERS ('memory_optimized' = 'true');
```
#### 2.1.2 Columnar Storage
SAP HANA采用列存储技术,将每列数据独立存储,使得查询时只需要读取相关列,减少了IO操作,提高了查询效率。下表展示了一个简单的列存储结构示例:
| EmployeeID | EmployeeName | Department | Salary |
|------------|--------------|------------|--------|
| 1 | Alice | HR | 5000 |
| 2 | Bob | IT | 6000 |
| 3 | Charlie | Sales | 4500 |
#### 2.1.3 Hybrid Data Storage
为了兼顾实时处理与成本效益,SAP HANA还支持混合存储结构,将热数据存储在内存中,将冷数据存储在磁盘中,有效降低了内存成本开销。以下是一个展示热数据与冷数据存储的比例示例:
```mermaid
pie
title 数据存储比例
slice 70% 热数据
slice 30% 冷数据
```
### 2.2 数据分析与处理引擎
#### 2.2.1 OLAP与OLTP一体化
SAP HANA实现了OLAP(联机分析处理)与OLTP(联机事务处理)一体化,使得数据分析与事务处理可以在同一数据库中进行,实现了实时数据处理和分析。下面是一个OLAP与OLTP结合的示例流程图:
```mermaid
graph LR
A[Transaction] -->|Real-time Analysis| B(Analysis)
B -->|Insight| C{Decision}
C -->|Transaction| A
```
#### 2.2.2 并行计算能力
SAP HANA数据库具备强大的并行计算能力,可以同时处理多个任务

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 SAP 系统的各个方面,从其结构和组件到数据管理和处理。专栏文章涵盖广泛主题,包括创建新用户、理解数据模型、数据字典和表管理、ABAP 编程、数据传输、批量数据处理、智能表单设计、事务处理、交易代码、角色和权限管理、工作流管理、批作业调度、数据备份和恢复、系统性能调优、系统补丁管理、ABAP 调试、数据迁移和转换、多语言支持、SAP HANA 数据库等。通过阅读本专栏,读者可以全面了解 SAP 系统,并获得宝贵的实践技巧,从而有效地使用和管理 SAP 系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
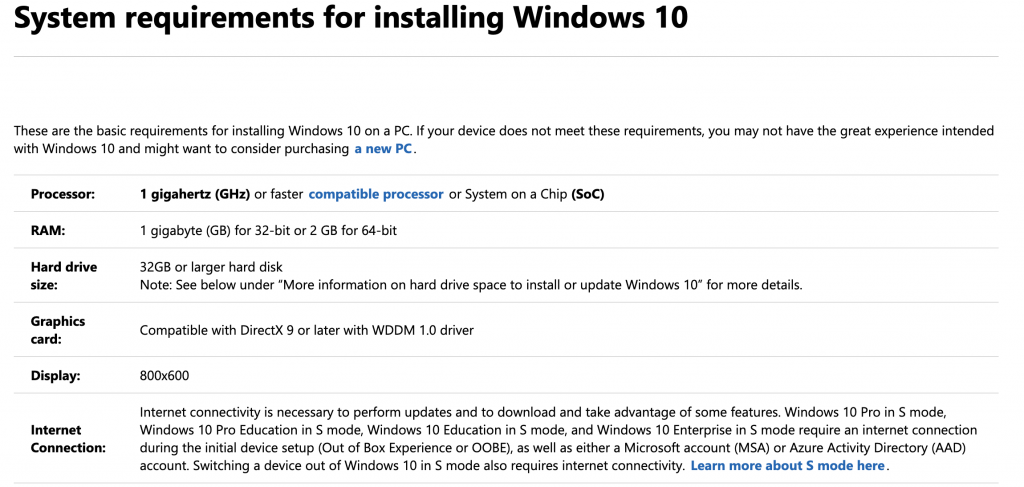
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
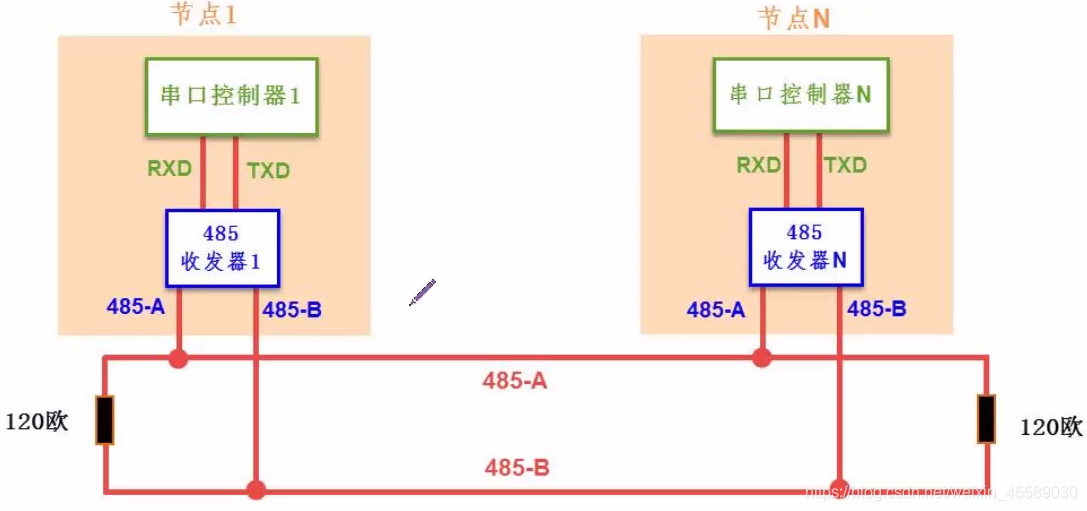
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
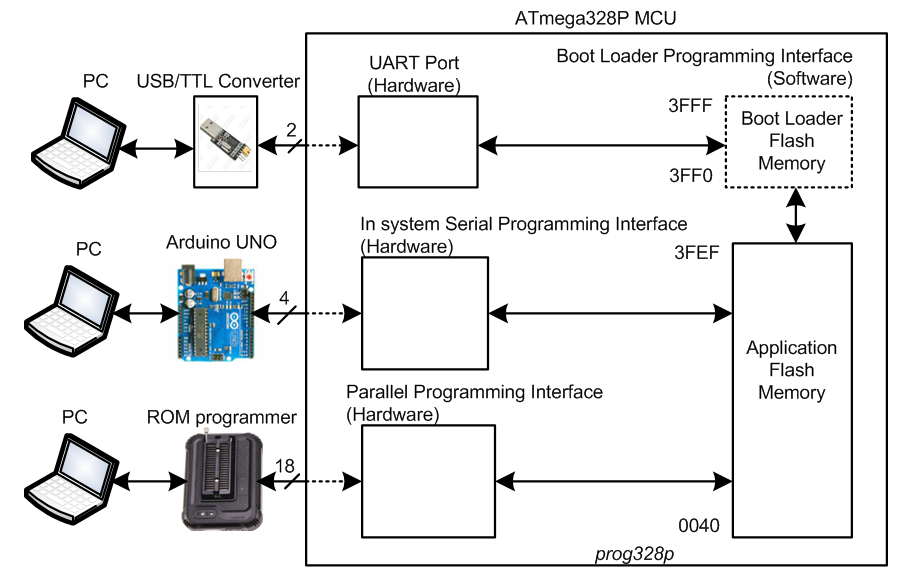
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )