docutils与reStructuredText:文档编写的黄金搭档揭秘
发布时间: 2024-10-05 17:37:39 阅读量: 37 订阅数: 37 

docutils-rest-writer:docutils 的 reStructuredText 编写器
# 1. reStructuredText与docutils的诞生与融合
reStructuredText(reST)与docutils的结合开创了文档编写的全新维度。reST是一种易于阅读和编写的纯文本标记语言,旨在为文档编写提供简洁和结构化的方式。而docutils是一个Python库,它提供了将reST转换为其他格式(如HTML、LaTeX等)的工具。
## 1.1 文档标记语言的演变
在reST出现之前,多数文档标记语言要么过于复杂,要么不支持跨平台。随着开放源代码软件和协作的需求增长,诞生了一种简单且易于理解的标记语言。reST,作为这样的产物,迅速在技术写作领域获得了认可。
## 1.2 docutils的引入
在reST成功地吸引了大量用户后,它开始寻求一种方式来增强其功能,特别是转换为不同输出格式的能力。2002年,docutils项目诞生了,它提供了一个文档处理框架,能够解析reST标记并生成丰富的文档输出。
```python
# 代码示例:简单的reST文档和docutils转换
# reStructuredText文档示例
document = """
Title
A paragraph with some text.
# 使用docutils将reST转换为HTML
from docutils.core import publish_string
output = publish_string(document, writer_name='html')
print(output)
```
上述代码块展示了如何使用docutils的Python接口将一段简单的reST文档转换成HTML格式。这不仅展示了reST的简洁性,也体现了docutils强大的转换能力。在本章中,我们将探究更多关于reST和docutils的融合细节,以及它们如何改变了文档编写的现状。
# 2. reStructuredText语法基础详解
### 2.1 文本结构的标记
#### 2.1.1 标题和章节的创建
在reStructuredText中,标题和章节的创建遵循严格的层级规则。最简单的方式是使用下划线来分隔标题文本和下划线长度表示层级。例如:
```
第一章
第一节
子节一
```
上述代码表示了一个三级标题结构,第一节是一级标题,子节一是二级标题。这种层级结构有利于文档的清晰阅读,也可以通过在标题文本后加上换行符和相应数量的等号(=)或星号(*)、短横线(-)来创建标题。
需要注意的是,标题后面要空一行,以便docutils正确解析文档结构。
#### 2.1.2 列表、块引用和代码块的使用
列表分为无序列表和有序列表。无序列表使用星号(*)、加号(+)或短横线(-)来开始每一项,而有序列表使用数字或字母,后跟圆点(.)或括号())。
块引用是使用大于号(>)表示。对于嵌套的引用,可以增加一个大于号层级。例如:
```
> 这是一个块引用。
> > 嵌套的块引用
```
代码块则使用两个冒号(::)作为结束,换行后缩进的文本视为代码内容。如果代码块前有段落文本,那么段落与代码块之间需要一个空行,例如:
```
这是段落文本。
::
这是代码块
第二行代码
```
### 2.2 内联标记与解释型文本
#### 2.2.1 文本强调、链接和图像的嵌入
在reStructuredText中,文本可以使用星号(*)或下划线(_)进行强调,使用双星号(**)或双下划线(__)进行加粗。例如:
```
*强调文本***加粗文本**
```
链接可以分为内联和引用式两种。内联链接使用如下格式:
```
`文本 <***>`_
```
而引用式链接则为:
```
`文本`_ 和 .. _`目标`:
***
```
嵌入图像与链接类似,图像的URL前加上感叹号(!),例如:
```
.. image:: /path/to/image.png
:alt: alternate text
```
#### 2.2.2 注释和替换文本的处理
注释使用双点号(..)表示,它不会出现在生成的文档中。例如:
```
.. 这是一个注释。
```
替换文本功能则允许我们在文档中插入可替换的变量。使用如下格式:
```
|variable| 用实际值替换。
```
### 2.3 构建系统与文档转换
#### 2.3.1 构建系统的配置和选项
docutils提供了一个灵活的构建系统,允许用户定制输出。配置文件(通常是`.conf`)可以设置多种选项,包括默认文档模板、输出格式、编码和许多其他选项。
用户可以使用`rst2html.py`等命令行工具,并通过选项来指定配置文件,如:
```
rst2html.py --config-path=/path/to/config file.rst file.html
```
#### 2.3.2 文档格式的转换和输出
reStructuredText文档可以转换为多种格式,包括HTML、LaTeX、PDF等。这些转换通常由docutils的命令行工具执行。
例如,将`.rst`文件转换为HTML格式:
```
rst2html.py file.rst file.html
```
而转换为PDF格式,则可能需要先转换成LaTeX,然后使用LaTeX编译器进行处理:
```
rst2latex.py file.rst file.tex
pdflatex file.tex
```
通过这种方式,文档可以在不同的格式之间转换,满足不同场合的使用需求。
# 3. docutils核心功能与实践应用
## 3.1 文档解析和处理
### 3.1.1 解析流程和组件
在了解 `docutils` 的文档解析和处理的核心功能时,首先需要探讨其背后的解析流程和关键组件。`docutils` 通过其解析器对 reStructuredText 源文档进行处理,将其转换为一个内部文档结构,即文档树(document tree)。这个文档树是一个层次化的树状结构,代表了文档的逻辑结构。
解析流程通常从读取 reStructuredText 文档开始,经过预处理、解析和后处理三个阶段。在预处理阶段,文档会进行诸如行折叠和删除注释等操作,使得文档格式化为 `docutils` 所期望的统一格式。接下来是解析阶段,这一阶段的核心是将文本内容通过不同的解析器组件转换为文档树。最后的后处理阶段则包含了一系列的转换步骤,比如执行所有的自定义指令和角色等。
组件方面,`docutils` 拥有多个模块组件,例如:
- **Reader (读取器)**: 负责将原始文本文件读取为一个可处理的格式。
- **Parser (解析器)**: 对读取的文本进行语义解析,将结构化的内容转换为文档树。
- **Transform (转换器)**: 对文档树应用各种转换,为不同的输出格式做准备。
这些组件相互协作,将一个原始的 reStructuredText 文档解析并转换为适合输出格式的结构化数据。
### 3.1.2 文档树的访问和操作
解析完成后,我们得到了文档树,这是 `docutils` 的核心数据结构。文档树记录了文档的逻辑结构,包括标题、段落、列表等各个元素。通过访问和操作文档树,我们可以进行文档的生成、修改以及信息提取等操作。
要访问和操作文档树,可以使用 `docutils` 提供的 API。以下是一个简单的示例代码,展示了如何遍历文档树的节点并打印它们的类型:
```python
from docutils import nodes, parsers
from docutils.core import publish_parts
# 示例文本
text = """
Title
This is a paragraph.
# 将文本转换为文档树
parser = parsers.rst.Parser()
document = parser.parse(text.encode(), parsers.registry.make_parser_components())
# 遍历文档树的节点
def traverse_tree(node):
print(node.__class__.__name__)
for child in node.children:
traverse_tree(child)
traverse_tree(document)
# 输出:
# document
# title
# bullet_list
# list_item
# paragraph
```
在这个示例中,我们创建了一个简单的 reStructuredText 文档,并使用 `docutils` 的 `Parser` 类进行解析,得到一个文档树。然后,我们定义了一个递归函数 `traverse_tree` 来遍历树中的每个节点,并打印其类型。这有助于理解文档结构和进行后续的文档处理。
理解文档树的结构对于创建和管理文档至关重要,特别是在需要根据文档内容进行自定义操作时。通过这种方式,用户可以利用 `docutils` 的强大功能来编写自己的工具,以便对文档进行更深入的分析和处理。
## 3.2 文档生成与发布
### 3.2.1 生成HTML和PDF文档
`docutils` 使得文档生成变得简单高效,它支持多种输出格式,其中最常用的是 HTML 和 PDF。使用 `docutils`,开发者可以轻松将 reStructuredText 文档转换为这些格式,以适应不同的使用场景。
对于生成 HTML 文档,`docutils` 提供了 `html4css1` 样式表作为默认样式,也可以自定义样式表。生成 HTML 的过程涉及将文档树结构转换为 HTML 元素,并使用 CSS 进行样式设计。
下面是一个将 reStructuredText 文档转换为 HTML 的基本代码示例:
```python
from docutils.core import publish_parts
# 输入的 reStructuredText 文本
text = """
Title
This is a *simple* reStru
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 库 docutils,这是一个功能强大的文档自动化工具。从入门到精通,专栏涵盖了 docutils 的核心原理、源码解析、实战案例、国际化策略、安全性提升、代码同步、自定义样式、大型项目管理、版本控制协同、模板定制、性能优化和 API 文档生成等方面。通过深入的分析和实际案例,专栏旨在帮助读者掌握 docutils 的强大功能,并将其应用于各种文档自动化场景,提升文档编写效率和质量。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ESC-POS打印技术深度解析】:从基础到高级应用的全方位指南

# 摘要
本文全面介绍了ESC-POS打印技术,包括其命令集的构成与应用、打印机硬件接口的比较、数据传输与编码格式的组织方式。文章还深入探讨了ESC-POS打印技术在实际应用中的实践,如打印机初始化、文本与图形打印以及维护和故障排除。高级应用技术方面,文中阐述了图形处理技术、多语言和特
【无线网络安全】:提升WLAN安全性的加密认证最佳实践
# 摘要
无线网络安全是一个涉及多种技术和策略的复杂领域。本文从基础概念出发,深入探讨了无线网络安全标准的演变、加密技术的原理与应用,以及认证机制。通过对WLAN加密认证实践策略的分析,本文提供了实施安全策略和维护网络安全的指南。文章还讨论了无线网络安全的高级应用,如防范安全威胁、网络隔离和访客管理策略,并分析了企业级解决方案案例。最后,本文展望了新兴技术对无线网络安全
博通ETC OBU Transceiver:从基础到高级部署的全方位性能评估与安全分析
# 摘要
随着电子收费系统(ETC)的广泛应用,对ETC车载单元(OBU)收发器的性能和安全性要求日益提高。本文从博通ETC OBU收发器的概述入手,深入探讨了性能评估的理论基础和实践方法,并通过系统安全分析理论框架,详细分析了ETC系统可能面临的安全威胁及其性能评
【低频数字频率计信号处理秘密】:提升准确性与电磁兼容性

# 摘要
数字频率计作为测量频率参数的重要仪器,在工业、科研等领域扮演着关键角色。本文从基本原理与设计出发,详细探讨了频率测量技术的理论基础,包括时间间隔测量方法和直接频率计数方法。针对提升频率测量准确性,分析了测量误差的来源和准确性提升的理论依据,并着重论述了电磁兼容性设计原理,及其在硬件和软件设计中的实践应用。本文还介绍了频率信号处理技术,包括信号预处理、高精度算法以及后处理与误差校正
联想RD450X 231鸡血BIOS优化:全面实战指南

# 摘要
本文针对联想RD450X 231服务器的BIOS优化提供了全面的分析与实践指导。首先概述了BIOS优化的基本概念及其对系统性能的影响,然后深入探讨了优化前的准备步骤,如硬件兼容性确认与当前BIOS备份。文章接着详细介绍了BIOS优化的基本原则,并通过实践操作部分深入解析BIOS界面设置,分享了提升系统性能的鸡血模式以及系统稳定性和故障排查技巧。此外,本文进一步探讨了高级BIOS配置
【掌握Packet Tracer】:网络工程师必备的10个实践技巧与案例分析
# 摘要
本论文详细介绍了Packet Tracer在网络技术教育和实践中的应用,从基础操作到网络安全管理技巧,系统地阐述了网络拓扑构建、网络协议模拟、以及故障排除的策略和方法。文章还讨论了如何通过Packet Tracer进行高级网络协议的模拟实践,包括数据链路层、网络层和应用层协议的深入分析,以及使用AAA服务和网络监控工具进行身份认证与网络性能分析。本文旨在提供给网
【OpenMeetings终极指南】:5大新特性深度剖析与部署策略
# 摘要
随着协同工作需求的增长,OpenMeetings作为一个开源的网络会议系统,通过提供新特性和改进用户体验,持续增强其市场竞争力。本文首先概述了OpenMeetings的架构特点和安装部署流程,随后深入分析了新版本的功能亮点、技术细节以及这些更新如何显著提升用户交互和系统性能。安全
【从理论到实践的飞跃】:AUTOSAR TPS实践指南与案例分析

# 摘要
本文系统介绍了AUTOSAR TPS(Test Platform Specification)的基础知识、理论框架、开发工具和方法、实际应用案例,以及在实践过程中遇到的问题解决与优化策略。首先,文中回顾了AUTOSAR的历史和目的,阐述了TPS的定义、功能
SAP用户账户管理自动化:批量创建与维护流程的终极指南
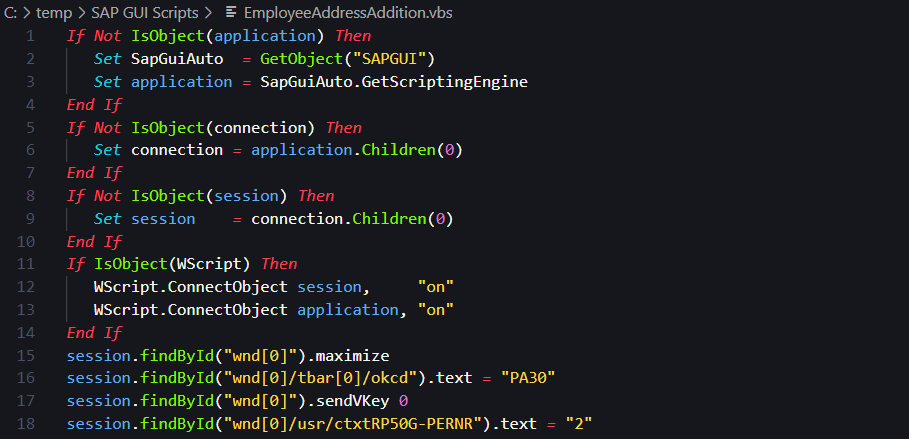
# 摘要
随着企业信息化水平的提升,高效管理SAP用户账户成为企业运营的关键。本文详细介绍了SAP用户账户管理的基础知识,探讨了自动化账户创建流程的理论和实践,包括用户角色与权限架构、批量创建流程设计原则,以及实践中的脚本开发和系统整合方法。进一步,本文分析了批量维护技术,如账户信息批量更新、动态权限管理和监控,以及自动化脚本的高级
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )