Power BI中的数据清洗和转换技巧
发布时间: 2023-12-21 00:46:36 阅读量: 102 订阅数: 32 
# 1. 引言
## 1.1 什么是数据清洗和转换
数据清洗和转换是数据分析中一个非常重要且不可或缺的步骤。在数据分析过程中,我们经常会遇到各种各样的数据质量问题,例如重复数据、缺失值、格式不一致等,这些问题会影响我们对数据的准确分析和建模。而数据清洗和转换就是对数据进行清理和修复,使其符合分析和建模的需求。
数据清洗主要包括去除重复数据、处理缺失值、格式化数据、过滤数据等操作。这些操作可以通过各种工具和编程语言实现,例如Power BI、Python、Java等。
数据转换是将原始数据转换成我们需要的格式和结构,以便更好地进行分析和建模。数据转换操作包括表格的合并和分割、数据列的拆分和合并、数据的分组和汇总、数据的提取和填充、数据的转置和透视等。
## 1.2 Power BI的数据清洗和转换功能的重要性
Power BI是一款强大的商业智能工具,提供了丰富的数据清洗和转换功能,可以帮助用户快速地清洗和转换数据,减少数据准备的时间和工作量。
Power BI的数据清洗和转换功能具有以下重要性:
- 提高数据质量:Power BI可以帮助我们快速地清理和修复数据中的问题,提高数据质量,从而获得准确和可靠的分析结果。
- 优化数据结构:Power BI可以将原始数据转换成我们需要的格式和结构,便于分析和建模。合并、拆分、汇总等操作可以帮助我们更好地理解和利用数据。
- 简化数据准备流程:Power BI提供了直观且易于使用的用户界面,可以方便地进行数据清洗和转换操作,减少数据准备的复杂性和时间成本。
- 提高工作效率:Power BI的数据清洗和转换功能可以帮助我们快速地处理大量数据,提高工作效率,使分析工作更加高效和精确。
在接下来的章节中,我们将介绍数据清洗和转换的一些常用技巧,并演示如何使用Power BI进行数据清洗和转换操作。
# 2. 数据清洗技巧
数据清洗是数据分析过程中的重要步骤,它涉及到处理数据中的不完整、不准确或不一致的部分。在Power BI中,数据清洗技巧可以帮助我们准备好数据,以便进行后续的数据分析和可视化工作。接下来,我们将介绍一些常用的数据清洗技巧,并结合示例演示它们在Power BI中的具体应用。
#### 2.1 去除重复数据
重复数据在实际数据分析中很常见,去除重复数据可以帮助我们确保数据的准确性和完整性。在Power BI中,使用Power Query可以方便地去除重复数据。下面是一个示例场景:
```python
# Python代码示例
import pandas as pd
# 创建一个包含重复数据的DataFrame
data = {'name': ['Alice', 'Bob', 'Alice', 'Bob', 'Alice'],
'age': [25, 30, 25, 30, 25]}
df = pd.DataFrame(data)
# 使用drop_duplicates方法去除重复数据
df.drop_duplicates(inplace=True)
# 打印处理后的DataFrame
print(df)
```
**代码总结:** 在这个示例中,我们创建了一个包含重复数据的DataFrame,并使用drop_duplicates方法去除重复数据,最后打印处理后的DataFrame。
**结果说明:** 经过去除重复数据操作后,我们得到了一个去除重复数据的DataFrame,确保了数据的准确性和完整性。
#### 2.2 处理缺失值
在数据分析中,经常会遇到缺失值的情况,需要对缺失值进行处理。Power BI提供了丰富的数据清洗功能,可以方便地处理缺失值。下面是一个示例场景:
```java
// Java代码示例
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
// 创建SparkSession
SparkSession spark = SparkSession.builder()
.appName("Handle Missing Values")
.config("spark.master", "local")
.getOrCreate();
// 读取包含缺失值的数据文件
Dataset<Row> df = spark.read()
.option("header", "true")
.csv("path/to/missing_values.csv");
// 使用na().fill方法填充缺失值
Dataset<Row> filledDf = df.na().fill("N/A");
// 打印处理后的数据
filledDf.show();
```
**代码总结:** 在这个示例中,我们使用SparkSession读取包含缺失值的数据文件,并使用na().fill方法填充缺失值,最后打印处理后的数据。
**结果说明:** 经过处理后,我们填充了数据中的缺失值,确保数据的完整性和可用性。
以上是数据清洗技巧的部分内容,在接下来的章节中,我们将继续介绍数据清洗和转换的其他技巧以及在Power BI中的应用。
# 3. 数据转换技巧
数据转换是将原始数据按照一定规则进行重新组织和处理的过程,可以根据分析需求进行数据的合并、拆分、汇总等操作。在Power BI中,数据转换是一个非常重要的环节,它可以帮助我们将数据变为可用于分析和可视化的形式。本章节将介绍一些常用的数据转换技巧,并通过示例代码演示其具体应用。
#### 3.1 表格的合并和分割
在现实场景中,我们常常会遇到需要合并和分割表格的情况。例如,我们有两个表格,一个表格中包含了客户的基本信息,另一个表格中包含了客户的购买记录,我们需要将这两个表格合并起来,以便进行进一步的分析和计算。
在Power BI中,我们可以借助Power Query实现表格的合并和分割。下面是一个示例代码,演示了如何将两个表格按照共同的字段进行合并:
```python
# 导入Power Query模块
from powerquery import PowerQuery
# 加载需要合并的表格
table1 = PowerQuery.load_table('table1.xlsx')
table2 = PowerQuery.load_table('table2.xlsx')
# 按照共同的字段合并表格
merge_table = PowerQuery.merge_tables(table1, table2, 'common_field')
# 输出合并结果
merge_table.show()
```
#### 3.2 数据列的拆分和合并
有时候,我们需要将某个数据列拆分为多个数据列,或者将多个数据列合并为一个数据列。例如,我们有一个包含了姓名的数据列,但是我们需要将其拆分为姓和名两个数据列。又或者,我们有多个包含了电话区号、号码等信息的数据列,但是我们需要将其合并为一个完整的电话号码数据列。
在Power BI中,我们可以使用Power Query的数据列拆分和合并功能来实现上述需求。以下是一个示例代码,演示了如何将一个包含了姓名的数据列拆分为姓和名两个数据列:
```python
# 导入Power Query模块
from powerquery import PowerQuery
# 加载包含姓名的表格
table = PowerQuery.load_table('table.xlsx')
# 拆分姓名数据列
table.split_column('name', ['first_name', 'last_name'])
# 输出拆分结果
table.show()
```
#### 3.3 数据的分组和汇总
数据的分组和汇总是数据分析中非常常见的操作。例如,我们有一个包含了销售记录的表格,其中包含了产品名称、销售数量和销售额等信息,我们需要根据产品名称进行分组,并计算每个产品的总销售数量和总销售额。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将介绍Power BI的入门知识和高级技巧,帮助读者快速上手并深入了解Power BI的各种功能和应用场景。从创建基本的数据报表、建立数据模型和关系、利用DAX函数进行数据分析,到数据清洗和转换技巧、高级数据可视化的创建、连接和整合不同数据源,以及数据安全和权限设置等方面内容都将涉及。此外,专栏还会介绍如何使用Power BI进行数据分析和趋势预测,以及Power BI桌面版与服务版之间的区别与应用场景。此外,专栏还将探讨Power BI在企业级BI解决方案中的角色与应用、自定义报表和可视化效果的实现,以及数据驱动的决策分析等内容。另外还会讲解数据模型优化与性能调优、构建动态参数化报表、故障排除与调试技巧,以及在大数据环境中的应用和与常见数据库系统的集成和优化。最后,本专栏还将介绍如何使用Power BI进行地理信息分析和地图可视化,以及Power BI在金融行业数据分析中的应用。无论你是初学者还是有一定经验的用户,都能在本专栏中找到对应自身需求的内容,帮助你更好地利用Power BI进行数据分析和可视化。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【SketchUp设计自动化】

# 摘要
本文系统地探讨了SketchUp设计自动化在现代设计行业中的概念与重要性,着重介绍了SketchUp的基础操作、脚本语言特性及其在自动化任务中的应用。通过详细阐述如何通过脚本实现基础及复杂设计任务的自动化
【科大讯飞语音识别:二次开发的6大技巧】:打造个性化交互体验
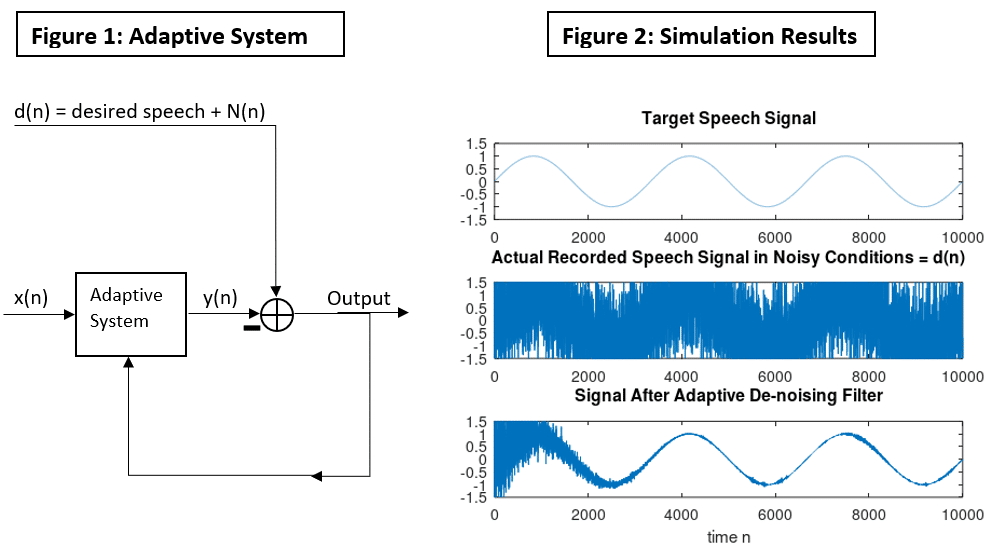
# 摘要
科大讯飞作为领先的语音识别技术提供商,其技术概述与二次开发基础是本篇论文关注的焦点。本文首先概述了科大讯飞语音识别技术的基本原理和API接口,随后深入探讨了二次开发过程中参数优化、场景化应用及后处理技术的实践技巧。进阶应用开发部分着重讨论了语音识别与自然语言处理的结合、智能家居中的应用以及移动应用中的语音识别集成。最后,论文分析了性能调优策略、常见问题解决方法,并展望了语音识别技术的未来趋势,特别是人工
【电机工程独家技术】:揭秘如何通过磁链计算优化电机设计

# 摘要
电机工程的基础知识与磁链概念是理解和分析电机性能的关键。本文首先介绍了电机工程的基本概念和磁链的定义。接着,通过深入探讨电机电磁学的基本原理,包括电磁感应定律和磁场理论基础,建立了电机磁链的理论分析框架。在此基础上,详细阐述了磁链计算的基本方法和高级模型,重点包括线圈与磁通的关系以及考虑非线性和饱和效应的模型。本文还探讨了磁链计算在电机设计中的实际应
【用户体验(UX)在软件管理中的重要性】:设计原则与实践

# 摘要
用户体验(UX)是衡量软件产品质量和用户满意度的关键指标。本文深入探讨了UX的概念、设计原则及其在软件管理中的实践方法。首先解析了用户体验的基本概念,并介绍了用户中心设计(UCD)和设计思维的重要性。接着,文章详细讨论了在软件开发生命周期中整合用户体验的重要性,包括敏捷开发环境下的UX设计方法以及如何进行用户体验度量和评估。最后,本文针对技术与用户需求平
【MySQL性能诊断】:如何快速定位和解决数据库性能问题

# 摘要
MySQL作为广泛应用的开源数据库系统,其性能问题一直是数据库管理员和技术人员关注的焦点。本文首先对MySQL性能诊断进行了概述,随后介绍了性能诊断的基础理论,包括性能指标、监控工具和分析方法论。在实践技巧章节,文章提供了SQL优化策略、数据库配置调整和硬件资源优化建议。通过分析性能问题解决的案例,例如慢
【硬盘管理进阶】:西数硬盘检测工具的企业级应用策略(企业硬盘管理的新策略)

# 摘要
硬盘作为企业级数据存储的核心设备,其管理与优化对企业信息系统的稳定运行至关重要。本文探讨了硬盘管理的重要性与面临的挑战,并概述了西数硬盘检测工具的功能与原理。通过深入分析硬盘性能优化策略,包括性能检测方法论与评估指标,本文旨在为企业提供硬盘维护和故障预防的最佳实践。此外,本文还详细介绍了数据恢复与备份的高级方法,并探讨了企业硬盘管理的未来趋势,包括云存储和分布式存储的融合,以及智能化管理工具的发展
【sCMOS相机驱动电路调试实战技巧】:故障排除的高手经验
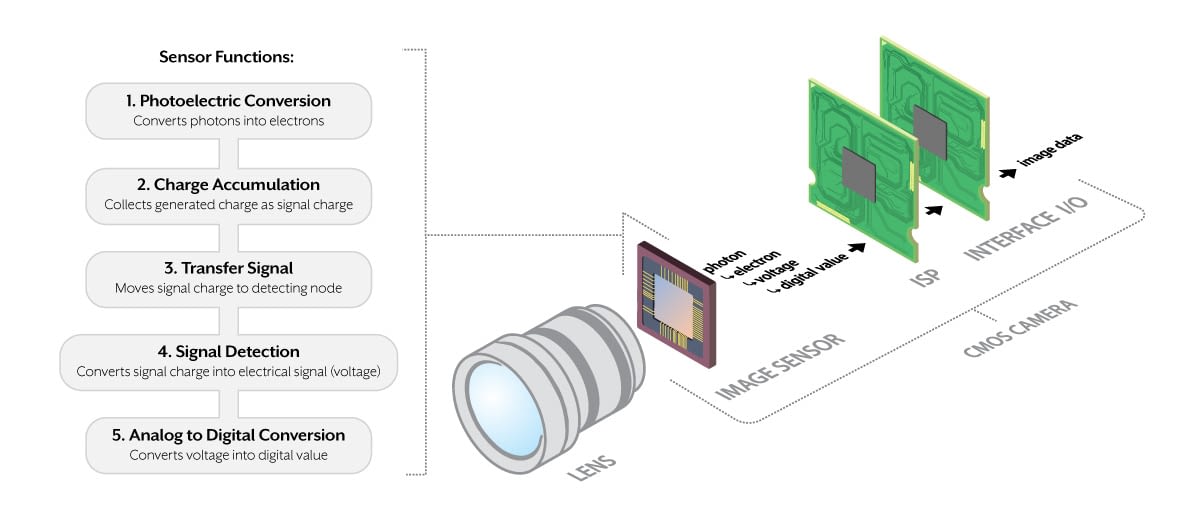
# 摘要
sCMOS相机驱动电路是成像设备的重要组成部分,其性能直接关系到成像质量与系统稳定性。本文首先介绍了sCMOS相机驱动电路的基本概念和理论基础,包括其工作原理、技术特点以及驱动电路在相机中的关键作用。其次,探讨了驱动电路设计的关键要素,
【LSTM双色球预测实战】:从零开始,一步步构建赢率系统
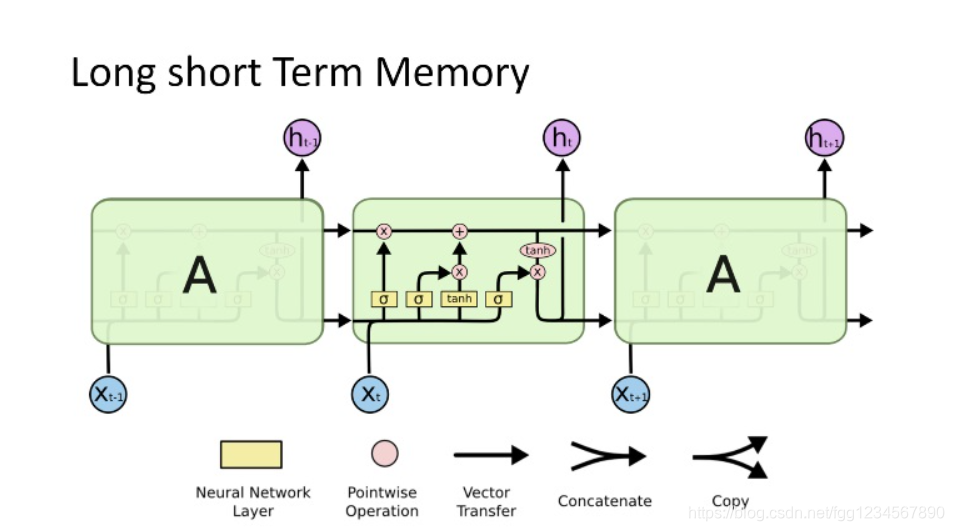
# 摘要
本文旨在通过LSTM(长短期记忆网络)技术预测双色球开奖结果。首先介绍了LSTM网络及其在双色球预测中的应用背景。其次,详细阐述了理
EMC VNX5100控制器SP更换后性能调优:专家的最优实践

# 摘要
本文全面介绍了EMC VNX5100存储控制器的基本概念、SP更换流程、性能调优理论与实践以及故障排除技巧。首先概述了VNX5100控制器的特点以及更换服务处理器(SP)前的准备工作。接着,深入探讨了性能调优的基础理论,包括性能监控工具的使用和关键性能参数的调整。此外,本文还提供了系统级性能调优的实际操作指导
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )