【Java新手到高手之路】:构建Java知识体系的5大步骤
发布时间: 2024-09-24 23:08:42 阅读量: 194 订阅数: 44 

Java基础入门:构建系统化编程能力与应用实例指导

# 1. Java编程语言的入门基础
在本章中,我们将带您步入Java的世界,介绍这门语言的核心概念,为后续深入学习打下坚实的基础。我们将从Java的安装、基本语法、数据类型、运算符和控制流语句开始,这些都是Java编程的基石。通过本章,您将掌握Java程序的编写和运行流程,为进入更高级的主题打下坚实的基础。
## 1.1 Java的安装与运行环境搭建
Java的安装是学习的第一步,我们将介绍如何下载并安装Java开发工具包(JDK),配置环境变量,并设置IDE(如IntelliJ IDEA或Eclipse)来编写和运行Java程序。这部分内容着重于让初学者能够迅速开始Java编程之旅。
```java
// 示例代码:Hello World
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
## 1.2 Java基本语法和数据类型
在了解了如何搭建开发环境之后,本节将带您了解Java的基本语法,包括变量声明、基本数据类型、运算符和控制流语句。我们将解释Java中的每一种数据类型,以及它们在内存中的存储方式,帮助您掌握程序的基本构建块。
## 1.3 控制流程语句
控制流程语句是编程中的关键,它决定了程序的执行路径。您将学习if-else条件语句、switch-case多分支选择语句、for和while循环,以及它们在编程中的应用。通过实例代码,我们将解释这些语句是如何控制程序逻辑的。
通过本章的学习,您将能够理解Java程序的基本结构,并能够编写简单但功能完整的Java程序。这是学习Java编程语言的起点,也是后续深入探索Java世界的坚实基础。
# 2. ```
# 第二章:面向对象编程深入理解
## 2.1 类与对象的奥秘
### 2.1.1 类的定义与构造方法
在面向对象编程(OOP)中,类是定义对象属性和行为的蓝图。它是一个封装数据和函数的结构,允许开发者在不同的对象实例之间共享相同的代码。构造方法是一个特殊的类方法,用于在创建对象时初始化对象,即为对象成员变量赋初值。
构造方法的特点包括:
- 名称必须与类名相同。
- 没有返回类型,连void都没有。
- 通常用于初始化对象状态。
#### Java代码展示
```java
public class Car {
// 类的属性
private String brand;
private String model;
private int year;
// 构造方法,无参构造
public Car() {
}
// 带参构造方法
public Car(String brand, String model, int year) {
this.brand = brand;
this.model = model;
this.year = year;
}
// ...类的其他方法...
}
```
通过构造方法,我们可以在创建Car对象时立即设置品牌(brand)、型号(model)和生产年份(year)。
### 2.1.2 对象的创建与使用
对象是类的实例。当我们通过new关键字和类的构造方法创建对象时,内存会分配给新对象,并且构造方法会被调用。
#### Java代码展示
```java
public class Main {
public static void main(String[] args) {
// 使用无参构造方法创建Car对象
Car car1 = new Car();
// 使用带参构造方法创建Car对象
Car car2 = new Car("Toyota", "Corolla", 2020);
// 设置car2的属性
car2.setBrand("Honda");
car2.setModel("Civic");
car2.setYear(2021);
// 使用对象
System.out.println(car2.getBrand() + " " + car2.getModel() + " " + car2.getYear());
}
}
```
上面的示例中,我们创建了两个Car类的实例(对象)。第一个对象使用了无参构造方法,第二个对象使用了带参构造方法来初始化属性。
## 2.2 封装、继承和多态性
### 2.2.1 封装的原则与实现
封装是OOP的核心原则之一,指的是将对象的状态(属性)隐藏起来,并通过公共方法对外提供接口访问。封装不仅保护了对象内部的属性,还允许开发者控制属性的读写权限。
#### Java代码展示
```java
public class BankAccount {
// 私有属性,外部无法直接访问
private double balance;
// 构造方法
public BankAccount(double balance) {
this.balance = balance;
}
// 设置余额的方法,包含检查
public void setBalance(double newBalance) {
if (newBalance < 0) {
System.out.println("余额不能为负");
} else {
this.balance = newBalance;
}
}
// 获取余额的方法
public double getBalance() {
return balance;
}
}
```
在这个例子中,`balance`属性被设为私有,只能通过`setBalance`和`getBalance`方法进行操作,保证了数据的封装性。
### 2.2.2 继承的机制与应用
继承允许新创建的类(子类)继承一个已存在的类(父类)的属性和方法,从而实现代码的重用。在Java中,使用关键字`extends`表示继承。
#### Java代码展示
```java
public class Vehicle {
private String make;
private String model;
public Vehicle(String make, String model) {
this.make = make;
this.model = model;
}
public void start() {
System.out.println("Vehicle is started");
}
}
// Car继承了Vehicle
public class Car extends Vehicle {
private int numberOfDoors;
public Car(String make, String model, int numberOfDoors) {
super(make, model);
this.numberOfDoors = numberOfDoors;
}
public void start() {
super.start();
System.out.println("Car has " + numberOfDoors + " doors");
}
}
```
在这个例子中,`Car`类继承了`Vehicle`类,拥有了`Vehicle`的属性和方法。`Car`类还添加了`numberOfDoors`属性和自己的`start`方法。
### 2.2.3 多态性的实现与好处
多态是OOP中的另一个核心原则,意味着一个接口可以有多个实现。通过多态,同一个操作作用于不同的对象,可以有不同的解释和不同的执行结果。
#### Java代码展示
```java
public class Animal {
public void makeSound() {
System.out.println("Animal makes a sound");
}
}
public class Dog extends Animal {
@Override
public void makeSound() {
System.out.println("Dog barks");
}
}
public class Cat extends Animal {
@Override
public void makeSound() {
System.out.println("Cat meows");
}
}
// 使用父类类型的引用指向不同子类对象
public class Main {
public static void main(String[] args) {
Animal myDog = new Dog();
Animal myCat = new Cat();
myDog.makeSound(); // 输出: Dog barks
myCat.makeSound(); // 输出: Cat meows
}
}
```
在这个例子中,`Dog`和`Cat`类都是`Animal`类的子类,它们分别重写了`makeSound`方法。我们可以使用`Animal`类型的引用来指向`Dog`或`Cat`的对象,这就是多态性的表现。
多态性的好处包括:
- 代码的可扩展性:可以通过添加新的子类实现相同接口来扩展程序的功能,而不必修改现有代码。
- 代码的可维护性:可以在基类中修改通用的方法实现,无需触及使用这些方法的各个子类。
## 2.3 面向对象设计原则
### 2.3.1 SOLID原则概述
SOLID是五个面向对象设计原则的首字母缩写,它们是面向对象和类设计中的核心准则。每个原则都旨在解决软件开发中的特定问题,以提高代码的可读性、可维护性和灵活性。
这五个原则分别是:
1. 单一职责原则(Single Responsibility Principle, SRP)
2. 开闭原则(Open/Closed Principle, OCP)
3. 里氏替换原则(Liskov Substitution Principle, LSP)
4. 接口隔离原则(Interface Segregation Principle, ISP)
5. 依赖倒置原则(Dependency Inversion Principle, DIP)
#### 表格展示
| 原则名称 | 描述 |
| --- | --- |
| SRP | 一个类应该只有一个引起变化的原因 |
| OCP | 软件实体应该对扩展开放,对修改关闭 |
| LSP | 子类型必须能够替换掉它们的父类型 |
| ISP | 不应该强迫客户依赖于它们不使用的接口 |
| DIP | 高层模块不应该依赖低层模块,两者都依赖于抽象 |
遵循这些原则有助于开发出易于理解和维护的代码库,可以减少错误和提高软件质量。
### 2.3.2 设计模式的分类与应用
设计模式是在软件工程中解决特定问题的一般性解决方案。它们提供了经过验证的开发实践,有助于提高软件的灵活性、可维护性和可复用性。
设计模式主要分为三种类型:
1. 创建型模式:涉及对象实例化的模式,它们帮助创建对象的同时隐藏创建逻辑。
2. 结构型模式:涉及如何组合类和对象以获得更大的结构。
3. 行为型模式:涉及对象之间的职责分配和通信。
#### mermaid流程图展示
```mermaid
graph TD;
A[设计模式] --> B[创建型模式];
A --> C[结构型模式];
A --> D[行为型模式];
B --> B1[单例模式];
B --> B2[工厂模式];
C --> C1[适配器模式];
D --> D1[观察者模式];
```
以工厂模式为例,它提供了一种创建对象的最佳方式。在工厂模式中,创建对象的逻辑被封装在一个工厂方法中,客户端代码通过这个方法而不是直接实例化类来创建对象。
#### Java代码展示
```java
public interface Product {
}
public class ConcreteProduct implements Product {
// ...
}
public class ProductFactory {
public static Product createProduct() {
return new ConcreteProduct();
}
}
// 客户端使用工厂方法创建对象
public class Client {
public static void main(String[] args) {
Product product = ProductFactory.createProduct();
// ...
}
}
```
通过工厂方法,当产品类发生变化时,无需修改客户端代码,只需修改工厂类中的创建逻辑即可,这体现了开闭原则。
以上详细介绍了面向对象编程中的类与对象、封装、继承以及多态性的实现和好处,还探讨了SOLID设计原则以及设计模式的分类和应用。掌握这些知识点对于Java开发者来说至关重要,它们有助于编写出高质量、高效率、易于维护的代码。
```
# 3. Java核心类库的深入学习
## 3.1 Java集合框架
### 3.1.1 集合类的体系结构
Java集合框架是Java编程语言中一个非常重要的组成部分,它为处理对象集合提供了一个通用的编程模型。这个模型允许不同类型的集合以相同的方式被操作,而无需关心它们的内部实现细节。集合框架的主要接口包括List、Set和Map,它们各自有不同的实现类。
**List** 接口,例如ArrayList和LinkedList,提供了一个有序的集合,允许重复的元素。它们维护了插入顺序,提供了基于位置的快速访问和插入。
**Set** 接口,例如HashSet和TreeSet,不允许重复元素,用于存储一个不包含重复元素的集合。Set的实现基于数学中的集合理论,通常用于数学运算如交集、并集等。
**Map** 接口,例如HashMap和TreeMap,存储键值对,允许使用键来快速检索值。Map不保证顺序,但某些实现如LinkedHashMap维持了插入顺序。
这些集合类的体系结构从最顶层的Collection和Map接口开始,向下细分为List、Set、Queue等不同的子接口,以及Map的进一步细分,如SortedMap和NavigableMap。每种接口都有多个实现类,适应不同场景的需求。了解这些接口与实现类之间的关系,对于正确选择和使用集合框架至关重要。
### 3.1.2 List、Set、Map的使用与原理
以ArrayList和HashMap为例,深入了解它们的内部工作原理及其在实际使用中的特点。
**ArrayList**
ArrayList是List接口的一个典型实现。它底层使用数组结构来存储元素。当添加元素到ArrayList时,它会增长底层数组的大小,以便可以容纳更多的元素。ArrayList具有动态扩展数组的功能,但这种扩展操作在大量数据添加时会影响性能,因为每次扩展时都需要创建一个更大的新数组,并将所有现有元素复制到新数组中。
ArrayList的`get(index)`和`set(index, element)`方法可以在常数时间复杂度O(1)内访问和修改元素,而`add(E element)`和`remove(int index)`方法则可能需要线性时间复杂度O(n),因为涉及到数组元素的移动。
**HashMap**
HashMap是Map接口的一个主要实现,它基于散列技术实现快速的键值对存取。HashMap通过一个哈希函数,将键转换为数组中的索引位置。当两个不同的键被哈希到相同的索引时,会发生冲突。HashMap通过链接(链表)的方式来解决冲突,即当发生哈希冲突时,会将相同索引位置的键值对存储在一个链表中。
HashMap的`get(Object key)`和`put(K key, V value)`操作在理想情况下都可以在常数时间复杂度O(1)内完成,但最坏情况下,如果发生大量的哈希冲突,这些操作的时间复杂度会退化到线性时间O(n)。
**实践**
在编写代码时,通常推荐使用接口类型的引用,如`List`和`Map`,而不是具体的实现类。这样可以在不改变现有代码的情况下,替换不同的实现类,达到优化性能的目的。
```java
List<String> list = new ArrayList<>(); // 推荐使用接口类型
Map<String, Integer> map = new HashMap<>();
```
了解集合框架的原理不仅有助于选择合适的集合类型,还可以在性能分析和调优时提供重要的参考。在实际应用中,开发者应该根据集合元素的数量和操作特性,选择合适的集合实现来存储数据。
## 3.2 Java I/O系统深入探究
### 3.2.1 输入输出流的分类与层次
Java I/O系统是Java平台上处理数据输入输出(Input/Output)的一套完整的API。它被设计为分层的结构,分为字节流和字符流两大类,每类又包括输入流和输出流。
**字节流**
字节流用于读写二进制数据,如文件和网络数据传输。字节流的两个基础抽象类是InputStream和OutputStream。InputStream是所有字节输入流的父类,定义了用于读取数据的方法如`read()`, `read(byte[] b)`, `skip(long n)`, `available()`等。OutputStream是所有字节输出流的父类,提供了写数据的方法如`write(int b)`, `write(byte[] b)`, `flush()`, `close()`等。
**字符流**
字符流用于读写字符数据。字符流的两个基础抽象类是Reader和Writer。Reader类提供了读取字符的方法,而Writer类则提供了写入字符的方法。这些方法与字节流类中提供的方法类似,但它们操作的是字符数据。
**I/O流层次**
Java I/O流的设计采用了装饰者模式(Decorator Pattern),允许在运行时动态地将责任附加到对象上。这种设计提供了极大的灵活性。从顶层到底层,大致可以分为四层:
1. 字节流和字符流的顶层抽象类,如InputStream, OutputStream, Reader, 和 Writer。
2. 实现类,提供具体的功能实现,如FileInputStream, FileOutputStream, FileReader, 和 FileWriter。
3. 高级抽象类,如BufferedInputStream和BufferedOutputStream,提供缓冲功能来提高效率。
4. 装饰者类,如CipherInputStream和CipherOutputStream,提供额外的数据加密和解密功能。
Java I/O系统的这种分层结构使得它非常灵活,程序员可以根据需要进行组合,形成具有所需功能的I/O流。
### 3.2.2 文件操作与序列化机制
在Java I/O系统中,文件操作和对象的序列化是两个非常重要的功能。
**文件操作**
文件操作通常通过File类来实现,它是对文件系统中文件或目录的抽象表示。File类提供的方法允许创建、删除、重命名和检查文件或目录的存在。
```java
File file = new File("example.txt");
if (file.createNewFile()) {
System.out.println("File created: " + file.getName());
} else {
System.out.println("File already exists.");
}
```
文件的读写操作则需要通过FileInputStream、FileOutputStream、FileReader和FileWriter等流类来实现。
```java
FileWriter fileWriter = new FileWriter(file, true);
fileWriter.write("Hello, World!");
fileWriter.close();
```
**序列化机制**
序列化是一种将对象状态转换为可保存或传输的格式(如二进制流)的过程。在Java中,序列化使得对象可以在内存中创建,然后保存或传输到另一个内存位置,甚至保存到磁盘或通过网络传输,之后还能重建对象的状态。
对象序列化的类必须实现Serializable接口,以标记该类的对象可以被序列化。
```java
import java.io.Serializable;
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private int age;
// 构造方法、getter和setter方法
}
```
对象的序列化可以通过ObjectOutputStream的`writeObject()`方法完成,而反序列化则通过ObjectInputStream的`readObject()`方法。
```java
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"))) {
Person person = new Person("Alice", 30);
out.writeObject(person);
} catch (IOException e) {
e.printStackTrace();
}
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser"))) {
Person person = (Person) in.readObject();
System.out.println(person.getName() + " is " + person.getAge() + " years old.");
} catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
```
Java I/O系统提供了丰富的方法来处理文件和数据序列化,适用于从简单的文件读写到复杂的对象持久化存储的各种场景。
## 3.3 Java并发编程进阶
### 3.3.1 线程的创建与管理
在Java中,线程是执行任务的轻量级执行单元。Java提供了两种创建线程的方式:继承Thread类和实现Runnable接口。
**继承Thread类**
继承Thread类是创建线程的一种方式。你需要扩展Thread类并重写其`run()`方法。创建线程对象并调用`start()`方法启动线程。
```java
public class MyThread extends Thread {
public void run() {
System.out.println("Thread is running.");
}
}
MyThread t = new MyThread();
t.start();
```
这种方式简单明了,但不推荐使用,因为它不支持继承其他类来创建多继承,这在Java中是有限制的。
**实现Runnable接口**
实现Runnable接口是另一种创建线程的方式,也是推荐的方式。通过实现Runnable接口并实现`run()`方法,然后创建一个Thread实例,并将实现Runnable接口的对象传递给Thread的构造器。
```java
public class MyRunnable implements Runnable {
public void run() {
System.out.println("Runnable is running.");
}
}
Thread t = new Thread(new MyRunnable());
t.start();
```
这种方式更加灵活,允许你的类继续扩展其他类,并且更符合单一职责原则。
### 3.3.2 同步机制与并发工具类的使用
多线程编程的一个关键挑战是确保线程安全。当多个线程访问共享资源时,需要使用同步机制来保证数据的一致性和完整性。
**同步机制**
Java提供同步关键字`synchronized`来确保一次只有一个线程可以执行某个代码块。同步可以应用于方法或代码块。同步方法会自动获得对象锁,同步代码块则允许你指定获得哪个对象的锁。
```java
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized void decrement() {
count--;
}
public synchronized int getCount() {
return count;
}
}
```
**并发工具类**
Java并发API还提供了大量并发工具类,这些类位于java.util.concurrent包中,它们提供了比同步机制更高级的线程管理功能。例如,CountDownLatch、CyclicBarrier和Semaphore等。
这些工具类通过不同的方式解决并发问题,例如:
- **CountDownLatch** 允许多个线程等待直到计数器归零。
- **CyclicBarrier** 允许一组线程相互等待,直到所有线程到达一个共同的屏障点。
- **Semaphore** 用于限制对共享资源的访问数量。
```java
import java.util.concurrent.CountDownLatch;
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(3);
new Thread(() -> {
try {
System.out.println("Thread 1 finished");
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
System.out.println("Thread 2 finished");
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
new Thread(() -> {
try {
System.out.println("Thread 3 finished");
latch.countDown();
} catch (Exception e) {
e.printStackTrace();
}
}).start();
latch.await();
System.out.println("All threads have finished.");
}
}
```
通过使用这些并发工具类,可以更安全、更方便地管理线程之间的协作和通信。
总结Java并发编程进阶,线程的创建和管理是并发编程的基础,而同步机制和并发工具类的使用则是保障并发安全、实现复杂线程协作的关键。理解并熟练运用这些概念和技术,对于构建高效、可靠的多线程Java应用程序至关重要。
# 4. Java高级特性及框架应用
## 4.1 Java泛型的原理与实践
### 4.1.1 泛型的定义和类型擦除
泛型是Java语言中引入的一种参数化类型的机制,允许在定义类、接口和方法时使用类型参数。泛型使得代码可以被重用、类型安全,同时还能够避免类型转换的错误。
Java中的泛型是通过类型擦除来实现的,这意味着泛型信息在编译后不被保留。类型擦除是指在泛型类的字节码中,所有的泛型类型参数都会被替换为其上界(如果没有指定上界,则默认为Object)。这样做可以保证与旧的非泛型代码的兼容性。
类型擦除带来的一个影响是,你不能在运行时直接获得泛型的类型信息。例如,以下代码尝试在运行时检查一个泛型对象的类型,将会得到`ClassCastException`:
```java
List<String> list = new ArrayList<>();
Class<String> stringClass = list.getClass(); // 这里会发生ClassCastException
```
### 4.1.2 泛型在集合与方法中的应用
泛型在集合框架中的应用尤其广泛,如`List`、`Set`、`Map`等接口都有对应的泛型版本。泛型集合允许存储特定类型的对象,同时保证在使用时不会出现类型错误。例如:
```java
List<String> names = new ArrayList<>();
names.add("Alice");
// 下面一行代码会导致编译错误,因为不能添加非String类型的元素
// names.add(100);
```
泛型方法允许方法使用自己的类型参数,而不是类的类型参数。泛型方法使用`<T>`来指定类型参数。例如,创建一个泛型方法来交换两个变量的值:
```java
public static <T> void swap(T[] array, int i, int j) {
T temp = array[i];
array[i] = array[j];
array[j] = temp;
}
public static void main(String[] args) {
Integer[] numbers = {1, 2, 3};
swap(numbers, 0, 2);
System.out.println(Arrays.toString(numbers)); // 输出 [3, 2, 1]
}
```
在上述例子中,`swap`方法是泛型的,可以在不同类型数组上调用,实现元素交换的功能。
## 4.2 Java 8新特性详解
### 4.2.1 Lambda表达式与函数式接口
Java 8引入了Lambda表达式,它是一种简洁的表示可传递的匿名函数的方式。Lambda表达式极大地简化了需要提供函数对象的代码。
函数式接口是指只包含一个抽象方法的接口。Lambda表达式与函数式接口配合使用,可以将Lambda表达式赋给函数式接口的引用。例如,`java.util.function`包中的`Consumer`接口:
```java
Consumer<String> print = (s) -> System.out.println(s);
print.accept("Hello, Lambda!");
```
在上述代码中,`(s) -> System.out.println(s)`是一个Lambda表达式,它实现了`Consumer`接口的`accept`方法。
### 4.2.2 Stream API与集合的函数式操作
Stream API是Java 8的另一个亮点,它提供了一种高效且易于使用的处理数据的方式。Stream API允许以声明式操作数据集合,并支持并行处理。
```java
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
List<String> result = names.stream()
.filter(name -> name.startsWith("A"))
.collect(Collectors.toList());
```
在上述例子中,`filter`方法用于过滤出所有以"A"开头的名字。Stream API中的操作如`filter`、`map`、`reduce`等都支持链式调用,使得操作更加直观。
## 4.3 Spring框架的使用与原理
### 4.3.1 Spring核心概念与依赖注入
Spring是一个开源的Java平台,它提供了一套完整的编程和配置模型。Spring的核心概念之一是依赖注入(DI),这是一种设计模式,用于实现控制反转(IoC),减少组件之间的耦合度。
依赖注入可以通过构造函数注入、设值注入或接口注入实现。在Spring框架中,通常推荐使用构造函数注入,因为它能保证依赖的注入是必须的,并且可以在注入的参数上进行数据校验。
### 4.3.2 Spring MVC的工作流程与高级应用
Spring MVC是Spring提供的用于构建Web应用程序的模型-视图-控制器(MVC)框架。Spring MVC的工作流程包括前端控制器接收请求、处理器映射确定控制器、控制器处理请求、模型和视图解析以及最终的响应。
Spring MVC提供了许多高级特性,如类型转换、验证、数据绑定、国际化和静态资源处理等。Spring还提供了与RESTful服务交互的支持,通过使用注解如`@RestController`和`@RequestMapping`,开发者可以方便地构建RESTful应用程序。
```java
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
@GetMapping("/{id}")
public User getUserById(@PathVariable("id") Long id) {
return userService.getUserById(id);
}
@PostMapping("/")
public User createUser(@RequestBody User user) {
return userService.createUser(user);
}
}
```
在上述代码中,`UserController`类使用了`@RestController`注解,表明这是一个控制器,同时`@RequestMapping`和`@GetMapping`/`@PostMapping`注解用于映射HTTP请求到具体的方法上。这种方式允许开发者以声明式的方式编写控制器,清晰直观。
以上章节内容仅为本章部分介绍,更多细节将在本章节后续内容中展开。在后续的叙述中,我们将结合实例深入分析Java泛型的使用场景,探索Java 8新特性的强大功能,并进一步讲解Spring框架的高级特性,以及如何将这些特性应用于企业级项目中。
# 5. Java项目实战与性能优化
## 5.1 企业级Java项目构建
在企业级开发中,构建一个健壮、可扩展和易于维护的Java项目至关重要。项目构建不仅仅涉及到编码实践,还包括选择合适的开发工具、项目结构设计以及版本控制与项目管理。
### 5.1.1 项目结构与开发工具的选择
项目结构的设计应遵循Maven或Gradle这样的构建工具的标准目录结构,确保项目具有清晰的模块划分。例如,使用Maven的典型目录结构如下:
```
myproject/
|-- src/
| |-- main/
| | |-- java/
| | |-- resources/
| | `-- webapp/
| `-- test/
| `-- java/
`-- pom.xml
```
- `src/main/java`: 存放源代码的主目录。
- `src/main/resources`: 存放配置文件和静态资源。
- `src/main/webapp`: 如果是Web应用,存放JSP和JavaScript文件等。
- `src/test/java`: 存放测试代码。
- `pom.xml`: Maven项目的项目对象模型文件,包含项目的配置信息。
### 5.1.2 版本控制与项目管理实践
版本控制系统是协作开发的基础,它能够帮助团队成员跟踪代码变更、解决冲突以及管理项目版本。Git是最常用的版本控制系统,而GitHub、GitLab和Bitbucket是流行的代码托管平台。在实践中,应确保遵循良好的Git工作流程:
- `master` 或 `main` 分支作为项目的稳定版本,任何直接的代码更改都不应直接提交到这个分支。
- 使用功能分支(feature branch)来开发新功能或进行修改,完成后通过Pull Request合并到主分支。
- 在团队中推广代码审查(Code Review)文化,以保证代码质量。
对于项目管理,Jira和Trello等工具提供了任务跟踪、问题管理和敏捷开发的看板,非常适合进行项目管理和迭代规划。
## 5.2 Java性能调优技巧
Java应用在性能方面可能会遇到各种瓶颈,从垃圾回收到线程管理,都需要细致的调优。性能调优是一个持续的过程,需要深入理解JVM以及应用的运行机制。
### 5.2.1 垃圾回收机制与内存管理
JVM通过垃圾回收机制来自动管理内存,但在某些情况下,不当的内存管理可能会导致性能下降。了解不同垃圾回收算法的特点和使用场景对于优化至关重要。
常见的垃圾回收器有:
- Serial GC
- Parallel GC
- CMS GC
- G1 GC
- ZGC
理解这些垃圾回收器在不同代(Young Generation、Old Generation)和不同场景下的表现,可以帮助我们选择最合适的垃圾回收策略。
### 5.2.2 性能分析工具与优化策略
Java提供了一系列的工具来进行性能分析和诊断:
- JConsole:提供了基本的JVM监控和管理功能。
- VisualVM:提供了更高级的性能监控和故障排查能力。
- Flight Recorder:记录了Java应用的详细运行信息,可用于生产环境的性能分析。
使用这些工具可以帮助我们识别性能瓶颈,比如:
- CPU热点:找出消耗CPU最多的代码段。
- 内存泄漏:监控内存分配和回收情况,发现潜在的内存泄漏问题。
- I/O瓶颈:分析文件读写和网络I/O操作。
性能优化策略包括:
- 优化热点代码。
- 调整JVM启动参数,如堆大小、垃圾回收策略等。
- 使用缓存减少数据库访问和计算密集型任务的负担。
## 5.3 分布式系统与微服务架构
随着业务复杂性的增加,传统的单体应用越来越难以满足需求。分布式系统和微服务架构应运而生,它们提供了一种更好的方式来构建和管理复杂的应用。
### 5.3.1 分布式系统基础与挑战
分布式系统由多个通过网络互联的独立节点组成,它们协同工作,提供比单个系统更高的可用性、可靠性、可伸缩性和容错性。分布式系统的设计与实现面临诸多挑战:
- 一致性问题:在多个节点间维护数据一致性是挑战之一。
- 网络延迟:网络延迟和不确定性会影响系统的响应时间。
- 分布式事务:实现跨多个服务的事务一致性。
- 负载均衡:合理分配请求到各个节点,避免单点过载。
### 5.3.2 微服务架构模式与Spring Boot应用
微服务架构将应用程序拆分为一系列小型服务,每个服务围绕特定业务能力构建,并通过轻量级的通信机制进行交互。Spring Boot作为Spring框架的一部分,极大简化了微服务的开发与部署。
使用Spring Boot时,可以利用其自动配置和起步依赖简化项目设置。Spring Cloud提供了一系列工具来支持微服务架构:
- Eureka:服务发现机制。
- Ribbon:客户端负载均衡。
- Feign:声明式REST客户端。
- Hystrix:提供容错能力。
在实践中,微服务架构应注重服务间的通信和协作模式,以及如何通过服务网格(如Istio)来进一步加强服务治理能力。
通过上述内容,我们深入探讨了Java项目构建、性能调优以及分布式系统和微服务架构的知识,为Java开发人员在项目实战与性能优化方面提供了宝贵的信息和指导。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Java语言指南》专栏深入探讨了Java语言的各个方面,从入门到精通。专栏内容涵盖了Java编程基础、历史、流行原因、语法、面向对象编程、集合框架、内存管理、多线程编程、I/O系统、企业级开发、安全编程、数据库连接以及Java 8新特性。专栏旨在为Java新手提供全面指南,帮助他们掌握Java语言的精髓,并为Java高手提供深入的解析和最佳实践。通过阅读本专栏,读者可以构建坚实的Java知识体系,并提升他们的编程技能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
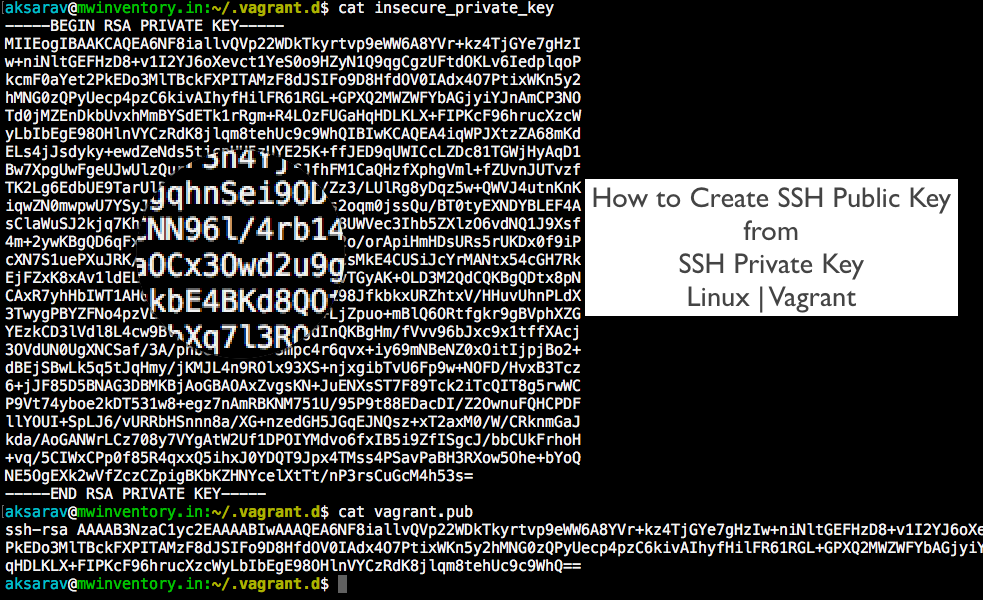
H3C交换机SSH配置安全宝典:加密与认证的实战技巧
# 摘要
本文旨在详细探讨SSH协议在H3C交换机上的应用和管理,包括SSH的基本配置、安全性能提升、故障排除以及性能优化等关键方面。文章首先介绍了SSH协议的基础知识和H3C交换机的相关概述,随后深入讨论了SSH服务的启用、用户认证配置以及密钥管理等基本配置方法。接着,文中分析了如何通过认证方式的深度设置、端口转发和X11转
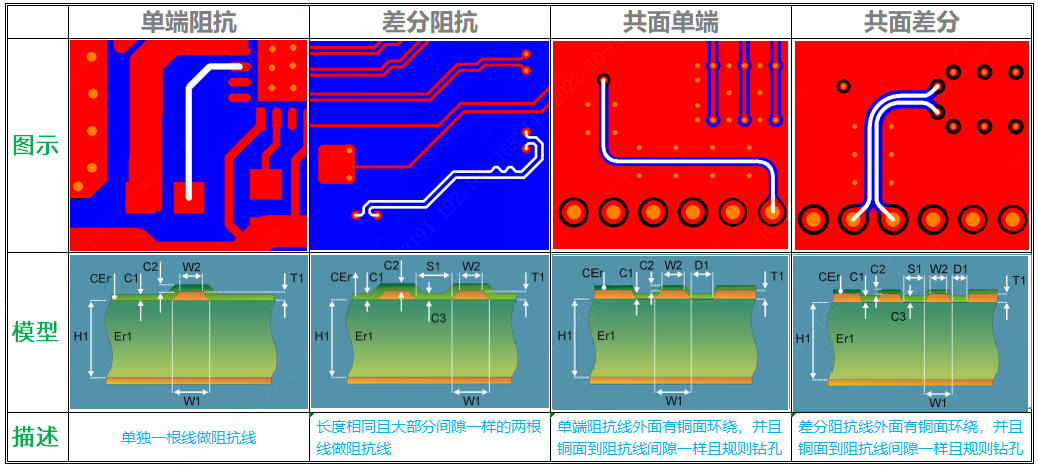
电路设计与NVIC库函数:提升嵌入式系统响应速度的关键技巧
# 摘要
本文深入探讨了嵌入式系统中NVIC库函数的角色及其对系统响应速度的影响。通过对NVIC基本功能、中断优先级管理、以及在电路设计中应用的分析,本文阐述了中断响应机制的优化和实时性、确定性的重要性。在电路设计的考量中,重点讨论了中断设计原则、系统时钟协同优化以及PCB布局对中断响应的影响。通过实践案例分析,探讨了NVIC在提升嵌入式系统响应速度中的应用和故障排除策略。
【编程高手必备】:掌握EMAC接口编程,精通AT91SAM7X256_128+网络开发

# 摘要
本论文对EMAC接口编程进行了全面的探讨,包括基础知识点、AT91SAM7X256/128+硬件平台上的初始化与配置、实战技巧、以及在特定网络开发项目中的应用。文章首先介绍了EMAC接口的基础知识,然后深入到AT91SAM7X256/128+微控制器的硬件架构解析,以及EMAC接口初始化的详细过程。第
【时间序列预测基础】:SPSS 19.00带你掌握趋势分析的秘密
# 摘要
时间序列预测在经济学、气象学、金融学等多个领域具有重要的应用价值。本文首先介绍了时间序列预测的基础概念,包括其重要性和应用范围。随后,文章详细阐述了使用SPSS 19.00软件进行时间序列数据的导入、基本分析和异常值处理。本研究深入探讨了时间序列预测模型的构建,包括线性趋势模型、ARIMA模型和季节性预测模型的理论基础、参数选择和优化。在此基础上,进一步探讨了S
用户体验提升秘籍:Qt平滑拖拽效果实现与优化

# 摘要
本论文详细探讨了在Qt框架下实现平滑拖拽效果的理论基础与实践方法。首先介绍了平滑动画的数学原理和Qt的事件处理机制,随后分析了设计模式在优化拖拽效果中的作用。第三章重点讲解了如何通过鼠标事件处理和关键代码实现流畅
【GAMIT批处理揭秘】:掌握10大高级技巧,自动化工作流程优化
# 摘要
本文全面介绍了GAMIT批处理的应用与技术细节,从基础知识到高级技巧,再到实际应用和未来趋势,提供了一套完整的GAM
死锁机制解析:四川大学试题回顾,终结死锁的四大策略!
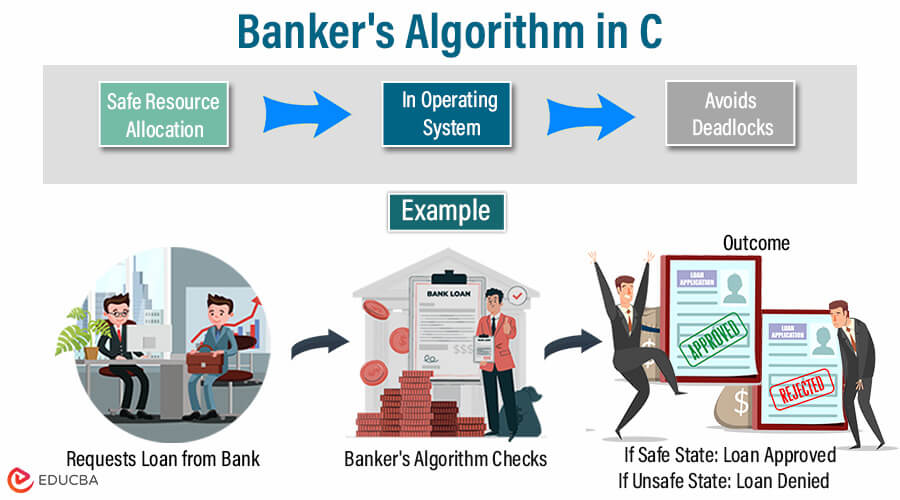
# 摘要
死锁是多任务操作系统中的一种现象,其中多个进程因相互竞争资源而无限期地阻塞。本文对死锁机制进行了详细解析,从死锁的定义和产生条件开始,深入探讨了死锁的基本概念和条件。通过分析银行家算法和资源分配图等理论模型,文章进一步阐述了预防和避免死锁的策略,包括资源的有序分配和非抢占资源分配策略。最后,本文提出了死锁的检测和恢复方法,并通过实例展示了如何综合运用多种
Linux服务器网络性能提升:10个解决方案深入分析

# 摘要
Linux服务器网络性能优化是确保高性能服务交付的关键,涉及理论基础、硬件升级、服务配置及监控和故障排查等多个方面。本文首先概述了Linux服务器网络性能的基本概念,然后深入探讨网络性能优化的基础理论,包括网络协议栈的作用、关键性能指标、内核参数调整以及网络接口的配置与管理
温度控制的艺术:欧姆龙E5CZ在工业过程中的最佳应用案例
# 摘要
本论文旨在介绍欧姆龙E5CZ控制器在温度控制领域的应用及其特性优势,并分析其在工业过程中的实际操作案例。通过温度控制理论基础的探讨,包括系统组成、基本原理、控制策略、传感器技术,本研究展示了如何选择和优化温度控制策略,并实现对温度的精确控制。同时,本论文还探讨了温度控制系统的优化方法和故障排除策略,以及工业4.0和新兴技术对温度控制未来发展的影响,提出了一系列创新性的建议和展望,以期为相关领域的研究和实践提供参考。
# 关键字
欧姆龙E5CZ控制器;温度控制;PID理论;传感器校准;系统优化;工业4.0;人工智能;无线传感网络
参考资源链接:[欧姆龙E5CZ温控表:薄型78mm,
封装设计进阶之路:从基础到高级的Cadence 16.2教程
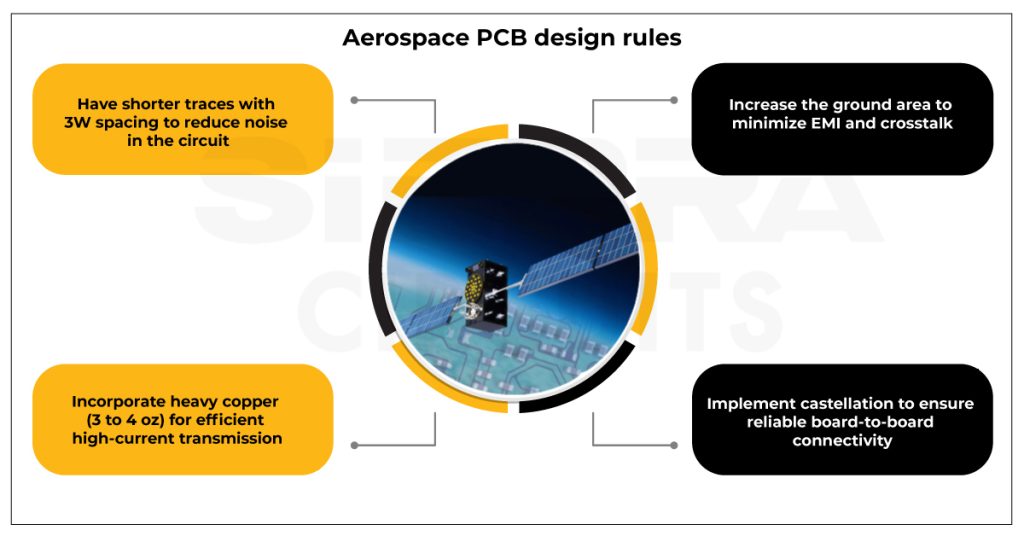
# 摘要
封装设计是集成电路制造的重要环节,本文首先概述了封装设计的基本概念,并介绍了Cadence工具的基础知识和操作。随后,详细阐述了基础及高级封装设计的实现流程,包括不同封装类型的应用、设计原则、Cadence操作细节、以及实践案例分析。文章还探讨了封装设计中的电气特性、热管理及可靠性测试,并提出了相应的分析和优化策略。此外,本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )