理解隐马尔可夫模型(HMM)的基本概念
发布时间: 2023-12-25 04:30:20 阅读量: 97 订阅数: 37 
# 1. 引言
## 1.1 HMM的起源与应用背景
HMM(Hidden Markov Model)是一种统计模型,被广泛应用于语音识别、自然语言处理、生物信息学等领域。HMM最早由Soviet mathematician Andrey Markov在20世纪初提出,用来描述具有概率转移特性的离散事件序列,其中事件的发生仅依赖于前一个事件。随后,L. E. Baum 和 T. Petrie 在1966年将HMM引入到模式识别领域,开启了HMM在实际应用中的发展之路。今天,HMM已成为统计建模、序列分析和模式识别中的重要工具之一。
## 1.2 本文内容概要
### 2. 马尔可夫链基础
马尔可夫链是随机过程中的一种基本模型,其状态在给定前一状态下的条件下,仅依赖于前一状态的过程。在本章节中,我们将介绍马尔可夫链的基本概念和特性。
#### 2.1 马尔可夫过程概述
马尔可夫过程是一种具有马尔可夫性质的随机过程,即未来状态的概率分布仅依赖于当前状态,与过去状态无关。这一性质被称为马尔可夫性质,通常通过转移概率描述状态间的转移。
#### 2.2 离散和连续状态空间
马尔可夫链可以具有离散的状态空间,也可以是连续的状态空间。在离散状态空间中,状态集合是有限的;而在连续状态空间中,状态集合是无限的,通常通过概率密度函数描述状态的转移。
#### 2.3 转移概率矩阵
马尔可夫链的状态转移可以通过转移概率矩阵表示。对于离散状态空间,转移概率矩阵描述了状态间的转移概率;对于连续状态空间,则使用转移概率密度函数描述状态的转移。
### 3. 隐马尔可夫模型介绍
隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述观察序列和隐藏状态之间的概率关系。HMM由隐藏的马尔可夫链和可见的输出组成,常用于对时间序列数据进行建模和分析。
#### 3.1 HMM的基本结构
HMM由三组参数组成:初始状态概率向量(π)、状态转移概率矩阵(A)和发射概率矩阵(B)。其中,初始状态概率向量描述了系统在各隐藏状态下的初始概率分布;状态转移概率矩阵描述了系统在各隐藏状态间转移的概率;发射概率矩阵描述了系统在各隐藏状态下生成各可见状态的概率。
#### 3.2 隐含状态和观察状态
在HMM中,隐藏状态(Hidden States)是不可直接观测到的状态,而可见状态(Observation States)是可以被观测到的状态。隐藏状态序列和观察状态序列之间存在概率关系,通过隐藏状态序列生成观察状态序列。
#### 3.3 发射概率和转移概率
在HMM中,发射概率表示在某个隐藏状态下观察到特定观察状态的概率;转移概率表示从一个隐藏状态转移到另一个隐藏状态的概率。这两种概率是HMM中的重要参数,决定了模型对观察序列的生成和状态转移的规律。
### 4. HMM的三个经典问题
隐马尔可夫模型(HMM)作为一种重要的概率图模型,涉及三个经典问题,它们分别是评估问题(Evaluation)、解码问题(Decoding)和学习问题(Learning)。接下来,我们将逐个介绍这三个问题及其解决方法。
#### 4.1 评估问题
评估问题是指在给定模型参数λ = (A, B, π)和观察序列O = (o1, o2, ..., oT)的情况下,计算观察序列O出现的概率P(O | λ)。其中,A是状态转移概率矩阵,B是观测概率矩阵,π是初始状态概率分布。评估问题的解决方法主要有前向算法和后向算法。下面是Python中使用前向算法解决评估问题的示例代码:
```python
def forward_algorithm(A, B, pi, O):
T = len(O)
N = len(A)
# 初始化alpha矩阵
alpha = np.zeros((T, N))
for i in range(N):
alpha[0][i] = pi[i] * B[i][O[0]]
# 递推计算alpha矩阵
for t in range(1, T):
for j in range(N):
alpha[t][j] = sum(alpha[t-1][i] * A[i][j] for i in range(N)) * B[j][O[t]]
# 计算观察序列概率
P_O = sum(alpha[T-1][i] for i in range(N))
return P_O
```
通过以上代码,我们可以计算出观察序列的概率。
#### 4.2 解码问题
解码问题是指在给定模型参数λ = (A, B, π)和观察序列O = (o1, o2, ..., oT)的情况下,确定最有可能的隐藏状态序列I = (i1, i2, ..., iT)。解码问题的经典算法是维特比算法(Viterbi algorithm),下面是Java中使用维特比算法解决解码问题的示例代码:
```java
public int[] viterbiAlgorithm(double[][] A, double[][] B, double[] pi, int[] O) {
int T = O.length;
int N = A.length;
double[][] delta = new double[T][N];
int[][] psi = new int[T][N];
// 初始化delta和psi矩阵
for (int i = 0; i < N; i++) {
delta[0][i] = pi[i] * B[i][O[0]];
psi[0][i] = 0;
}
// 递推计算delta和psi矩阵
for (int t = 1; t < T; t++) {
for (int j = 0; j < N; j++) {
double maxVal = 0;
int maxIndex = 0;
for (int i = 0; i < N; i++) {
double val = delta[t-1][i] * A[i][j];
if (val > maxVal) {
maxVal = val;
maxIndex = i;
}
}
delta[t][j] = maxVal * B[j][O[t]];
psi[t][j] = maxIndex;
}
}
// 回溯确定最优隐藏状态序列
int[] I = new int[T];
double maxProb = 0;
int maxIndex = 0;
for (int i = 0; i < N; i++) {
if (delta[T-1][i] > maxProb) {
maxProb = delta[T-1][i];
maxIndex = i;
}
}
I[T-1] = maxIndex;
for (int t = T-2; t >= 0; t--) {
I[t] = psi[t+1][I[t+1]];
}
return I;
}
```
以上Java代码展示了使用维特比算法进行解码问题的求解。
#### 4.3 学习问题
学习问题是指在给定观察序列O = (o1, o2, ..., oT)的情况下,估计最优的模型参数λ = (A, B, π)。学习问题的解决方法主要有Baum-Welch算法(也称为前向-后向算法)。下面是Go语言中使用Baum-Welch算法估计HMM参数的示例代码:
```go
func baumWelchAlgorithm(A, B, pi [][]float64, O []int, maxIters int) ([][]float64, [][]float64, []float64) {
T := len(O)
N := len(A)
for iters := 0; iters < maxIters; iters++ {
// 实现Baum-Welch算法的参数估计步骤
// ...
}
return A, B, pi
}
```
以上示例代码演示了使用Baum-Welch算法进行HMM参数估计的基本框架。
以上介绍了HMM中的三个经典问题以及它们的解决方法和代码实现。在实际应用中,根据具体问题需求和编程语言特性,可以灵活选择合适的算法和实现方式来解决HMM相关问题。
### 5. HMM的实际应用
隐马尔可夫模型在实际中有着广泛的应用,涵盖了多个领域,包括语音识别、自然语言处理和生物信息学等。下面将详细介绍HMM在这些领域的具体应用。
#### 5.1 语音识别
隐马尔可夫模型被广泛应用于语音识别领域。在语音识别中,输入的是声波信号,而输出是语音信号对应的文本信息。HMM可以用来建模语音的声学特征,将声学特征映射到文本信息,从而实现语音识别任务。通过训练HMM模型,可以识别不同发音之间的关联性,进而提高语音识别的准确性。
#### 5.2 自然语言处理
在自然语言处理领域,隐马尔可夫模型通常用于词性标注、命名实体识别和分词等任务。利用HMM可以对文本序列中的词性、实体和词语边界进行建模和预测。通过HMM模型,可以考虑上下文信息,从而提高自然语言处理任务的效果。
#### 5.3 生物信息学
在生物信息学中,HMM被应用于DNA序列分析、蛋白质结构预测和基因预测等领域。HMM可以对生物序列中的隐藏模式和结构进行建模,从而发现序列中的规律和特征。通过训练HMM模型,可以从生物序列中识别出重要的生物学信息,有助于科学家们理解生物序列的功能和结构。
以上介绍了HMM在语音识别、自然语言处理和生物信息学等领域的应用,表明了HMM作为一种强大的概率模型,在多个领域都具有重要的实际意义。
### 6. HMM的拓展与发展
在实际应用中,标准的隐马尔可夫模型可能无法很好地描述复杂的系统,因此人们对HMM进行了多方面的拓展与发展,以适用于不同领域的需求。
#### 6.1 高阶HMM
标准的HMM假设当前的隐藏状态仅依赖于前一个隐藏状态,即一阶马尔可夫链。而在实际问题中,有些情况下当前状态可能依赖于前几个状态,这时就需要使用高阶HMM。高阶HMM能够更好地捕捉系统状态之间的长程依赖关系,例如在自然语言处理中,可以用来建模语言的复杂结构和规律。
#### 6.2 连续混合HMM
标准的HMM假设观察状态是离散的,但在某些实际问题中,观察状态可能是连续的,这时就需要用到连续混合HMM。连续混合HMM将观察状态建模为连续的概率分布,这样可以更好地逼近真实世界的连续观察数据,如音频信号、图像等。
#### 6.3 HMM在深度学习中的应用
近年来,随着深度学习的兴起,人们开始探索如何将HMM与深度学习相结合,以提高模型的表达能力和预测精度。一种常见的方法是使用循环神经网络(RNN)作为HMM中的发射概率模型,以更好地捕捉时序数据中的复杂模式和规律。
以上是HMM的一些拓展与发展方向,这些方法的引入使得HMM能够更加灵活地应对不同应用场景的需求,并且为HMM在新领域的应用拓展了更广阔的可能性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
隐马尔可夫模型(HMM)是一种经典的概率模型,在多个领域具有广泛应用。本专栏将从入门指南开始,逐步深入理解HMM的基本概念,并探索其在文本处理、语音识别等领域的应用。同时,还将介绍HMM算法的实现与优化技巧,以及其在时间序列分析、预测、模式识别和行为建模中的应用。此外,我们将深入研究HMM在生物信息学、金融、经济、医学图像分析以及自动驾驶技术等领域的角色与应用。此专栏还将探讨HMM与机器学习、深度学习的融合应用,并说明HMM在智能语音助手、异常检测与故障诊断、图像处理和计算机视觉中的潜力。通过解析各种实例案例,本专栏旨在帮助读者更好地理解HMM的推断算法及前沿技术发展,同时掌握其在监督学习和无监督学习中的应用。无论您是机器学习和数据挖掘的初学者还是专业人士,本专栏都将为您提供全面而实用的知识,带您探索HMM的奥秘与应用前景。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【A*算法:旅行商问题的终极指南】:破解TSP,掌握高效智能寻路秘籍
# 摘要
旅行商问题(TSP)是一种典型的组合优化难题,寻找一条最短的路径访问一系列城市并返回起点。本文首先概述了TSP的历史和基本概念,并详细介绍了A*算法的基础理论,包括算法原理、评估函数的构建与数据结构的影响。接着,文章分析了A*算法在TSP问题建模中的应用,探讨了算法步骤、代码实现及实际案例。此外,本文还探讨了A*算法的优化策略、并行计算的可能性以及与其他算法的比较。最后,本
微服务架构全面指南:设计到部署的10个关键步骤
# 摘要
微服务架构已成为现代软件开发中的流行趋势,它促进了敏捷开发和持续部署,但也带来了新
【最优化秘籍】:北航教材深度解析与实践应用大全

# 摘要
最优化是数学和工程领域中应用广泛的课题,它在理论和实践层面均有广泛研究和应用。本文首先概述了最优化问题的数学模型,包括目标函数和约束条件的定义与分类。接着,本文介绍了不同类型的最优化算法,
【硬件对捷联惯导影响】:评估关键硬件性能提升的黄金法则
# 摘要
捷联惯导系统作为定位导航技术的关键部分,在多种领域中扮演着重要角色。本文首先介绍了捷联惯导系统的基础知识以及主要硬件组件。接着深入探讨了关键硬件性能对系统精度的影响,如陀螺仪和加速度计的选型与校准,中央处理单元(CPU)的处理能力和存储解决方案的优化。文中第三章着眼于硬件性能提升的理论基础和实践应用,分析了硬件性能的理论演进和通过实践案例进行优化。第四章
揭秘OV2735:图像传感器的11个实用技巧与最佳实践
# 摘要
OV2735图像传感器作为一款高分辨率图像捕获设备,在工业视觉系统集成、消费级产品优化及特殊环境应用中发挥着关键作用。本文全面介绍了OV2735的基础知识,包括其技术规格、工作模式、接口及电源管理。深入探讨了硬件设置、初始化校准以及软件应用,重点分析了驱动程序配置、图像处理算法集成和数据流管理。此外,文章还阐述了调试与测试的环境搭建、问题诊断解决以及性能评估与优化策略。最后
OCP-IP协议3.0实战指南:如何克服转矩制限的7大挑战
# 摘要
OCP-IP协议3.0作为一个重要的行业标准,对于提升系统性能与互操作性具有深远的影响。本文首先概述了OCP-IP协议3.0及其面临的挑战,然后深入探讨了其基本原理,包括架构解析、转矩制限的原理及其对性能的影响,以及通过理论分析与案例研究来解释转矩制限解决方案的实施。接下来,文章详细介绍了克服转矩制限的技术策略,这些策略包括硬件优化、软件算法改进以及系
【SIRIUS 3RW软启动器全解析】:掌握选型、应用与维护的终极指南
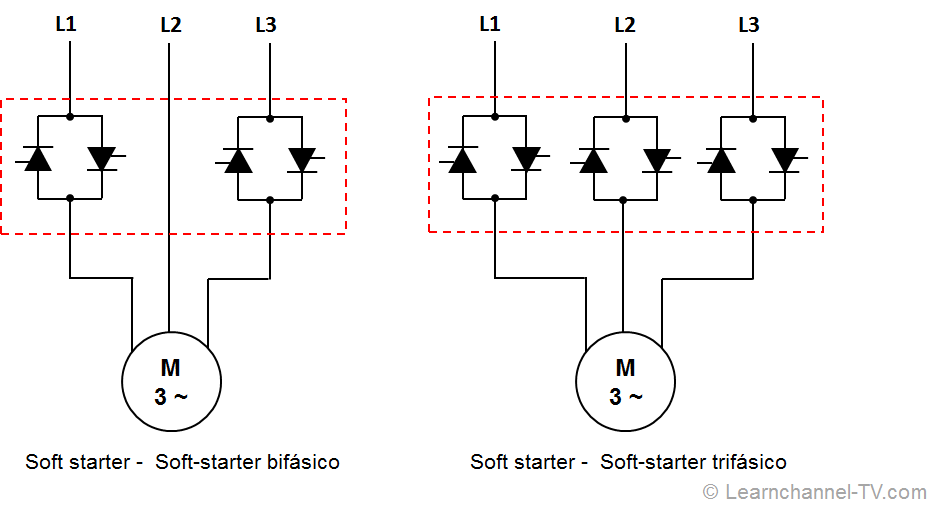
# 摘要
SIRIUS 3RW软启动器作为一种重要的工业控制设备,广泛应用于各种电气启动和控制场合。本文全面概述了SIRIUS 3RW软启动器的定义、功能以及应用领域。通过对选型指南的详细解读,本文为用户提供了系统选型的决策支持,包括技术参数的确定和环境因素的评估。此外,文章还分享了S
【5G技术深度分析】:如何构建无懈可击的认证基础架构

# 摘要
本论文全面阐述了5G技术的认证基础架构,涵盖其理论基础、实现、挑战以及实践案例分析。首先介绍了5G认证基础架构的概念、重要性和功能,并探讨了认证机制从3G到5G的演进和国际标准化组织的相关要求。随后,文章深入分析了5G认证在硬件和软件层面的实现细节,同时指出当前面临的安全挑战并提出相应的防护措施。通过案例分析,论文具体阐述了个人用户和企业认证实践,以及相应的部署与管理。最后,论文展望了人工智能和量子计
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )