【Visual Studio配置OpenCV:从小白到实战】:10步搞定OpenCV开发环境,新手也能轻松上手
发布时间: 2024-08-09 09:20:02 阅读量: 46 订阅数: 28 

配置方法:win64+vs_community2015_32位+opencv_x64位.docx

# 1. Visual Studio配置OpenCV简介**
Visual Studio是一个强大的集成开发环境(IDE),广泛用于C++和C#等编程语言的开发。通过在Visual Studio中配置OpenCV,开发人员可以轻松地利用OpenCV库的强大功能,进行图像处理、计算机视觉和机器学习等任务。
OpenCV是一个开源计算机视觉库,提供广泛的算法和函数,用于图像处理、特征提取、对象检测和识别。通过将OpenCV集成到Visual Studio中,开发人员可以方便地访问OpenCV库,并将其与其他Visual Studio功能相结合,例如调试、代码完成和版本控制。
# 2. OpenCV环境搭建
### 2.1 Visual Studio安装和配置
#### 2.1.1 Visual Studio版本选择
Visual Studio是微软开发的一款集成开发环境(IDE),用于开发各种应用程序。对于OpenCV环境搭建,需要选择合适的Visual Studio版本。
**推荐版本:**
* Visual Studio 2019
* Visual Studio 2022
**安装步骤:**
1. 前往微软官方网站下载Visual Studio安装程序。
2. 运行安装程序并按照提示进行安装。
3. 选择“自定义安装”选项,并确保选中“C++开发”组件。
#### 2.1.2 OpenCV扩展安装
安装Visual Studio后,需要安装OpenCV扩展以支持OpenCV开发。
**安装步骤:**
1. 打开Visual Studio,转到“扩展”菜单。
2. 搜索“OpenCV”扩展。
3. 找到并安装“OpenCV for Visual Studio”扩展。
### 2.2 OpenCV库的获取和安装
#### 2.2.1 OpenCV官网下载
从OpenCV官方网站下载OpenCV库是获取OpenCV库的直接方式。
**下载步骤:**
1. 前往OpenCV官方网站:https://opencv.org/
2. 选择“下载”选项卡。
3. 根据系统选择相应的OpenCV版本和平台(Windows、Linux、MacOS)。
4. 下载OpenCV库安装程序。
#### 2.2.2 第三方库管理工具
除了从官方网站下载,还可以使用第三方库管理工具来安装OpenCV库。
**推荐工具:**
* **vcpkg:**一个跨平台的C++库管理工具。
* **Conan:**另一个跨平台的C++库管理工具。
**安装步骤:**
1. 安装vcpkg或Conan。
2. 使用以下命令安装OpenCV库:
```
vcpkg install opencv
```
或
```
conan install opencv
```
### 2.3 环境变量的配置
#### 2.3.1 系统环境变量设置
系统环境变量用于在系统范围内配置OpenCV库的位置。
**设置步骤:**
1. 右键单击“此电脑”,选择“属性”。
2. 点击“高级系统设置”。
3. 在“系统属性”窗口中,点击“环境变量”按钮。
4. 在“系统变量”列表中,找到“Path”变量。
5. 点击“编辑”按钮,在“变量值”字段中添加OpenCV库的bin目录路径。例如:
```
C:\opencv\build\x64\vc16\bin
```
#### 2.3.2 Visual Studio项目环境变量
Visual Studio项目环境变量用于在特定项目中配置OpenCV库的位置。
**设置步骤:**
1. 在Visual Studio中打开项目。
2. 右键单击项目,选择“属性”。
3. 在“属性”窗口中,选择“VC++目录”选项卡。
4. 在“包含目录”字段中添加OpenCV库的include目录路径。例如:
```
C:\opencv\build\include
```
5. 在“库目录”字段中添加OpenCV库的lib目录路径。例如:
```
C:\opencv\build\x64\vc16\lib
```
# 3. OpenCV基础入门
### 3.1 OpenCV图像处理基础
#### 3.1.1 图像的读取和显示
OpenCV提供了`imread()`函数读取图像,该函数接受图像路径作为参数,并返回一个`Mat`对象,表示图像数据。`imshow()`函数用于显示图像,接受`Mat`对象和窗口名称作为参数。
```cpp
#include <opencv2/opencv.hpp>
int main() {
// 读取图像
cv::Mat image = cv::imread("image.jpg");
// 显示图像
cv::imshow("Image", image);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
```
**代码逻辑分析:**
* `cv::imread()`函数读取图像并将其存储在`image`变量中。
* `cv::imshow()`函数显示图像,窗口标题为"Image"。
* `cv::waitKey(0)`函数等待用户按下任何键,然后继续执行。
* `cv::destroyAllWindows()`函数关闭所有打开的窗口。
#### 3.1.2 图像的转换和处理
OpenCV提供了各种函数用于图像转换和处理,包括:
| 函数 | 描述 |
|---|---|
| `cv::cvtColor()` | 转换图像颜色空间 |
| `cv::resize()` | 调整图像大小 |
| `cv::blur()` | 对图像进行模糊处理 |
| `cv::threshold()` | 对图像进行阈值化 |
### 3.2 OpenCV计算机视觉基础
#### 3.2.1 人脸检测和识别
OpenCV提供了`cv::CascadeClassifier`类用于人脸检测,该类使用Haar级联分类器进行人脸检测。`cv::face::LBPHFaceRecognizer`类用于人脸识别,该类使用局部二值模式直方图(LBPH)算法。
```cpp
#include <opencv2/opencv.hpp>
int main() {
// 加载人脸检测分类器
cv::CascadeClassifier face_cascade;
face_cascade.load("haarcascade_frontalface_default.xml");
// 加载人脸识别器
cv::face::LBPHFaceRecognizer face_recognizer;
face_recognizer.load("face_model.xml");
// 读取图像
cv::Mat image = cv::imread("image.jpg");
// 人脸检测
std::vector<cv::Rect> faces;
face_cascade.detectMultiScale(image, faces);
// 人脸识别
std::vector<int> labels;
face_recognizer.predict(image, labels);
// 显示检测和识别结果
for (size_t i = 0; i < faces.size(); i++) {
cv::rectangle(image, faces[i], cv::Scalar(0, 255, 0), 2);
cv::putText(image, std::to_string(labels[i]), cv::Point(faces[i].x, faces[i].y - 10), cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 255, 0), 2);
}
// 显示图像
cv::imshow("Image", image);
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
```
**代码逻辑分析:**
* 加载人脸检测分类器和人脸识别器。
* 读取图像并进行人脸检测。
* 对检测到的人脸进行识别。
* 在图像上绘制检测和识别结果。
* 显示图像。
#### 3.2.2 物体检测和跟踪
OpenCV提供了`cv::ObjectDetector`类用于物体检测,该类使用深度学习模型进行物体检测。`cv::Tracker`类用于物体跟踪,该类使用各种跟踪算法。
```cpp
#include <opencv2/opencv.hpp>
int main() {
// 加载物体检测模型
cv::Ptr<cv::ObjectDetector> detector = cv::createDeepNeuralDetector(cv::dnn::Net::readFromDarknet("yolov3.cfg", "yolov3.weights"));
// 加载物体跟踪器
cv::Ptr<cv::Tracker> tracker = cv::TrackerKCF::create();
// 读取视频
cv::VideoCapture cap("video.mp4");
// 初始化跟踪器
cv::Rect2d bbox;
cap >> frame;
detector->detect(frame, bbox);
tracker->init(frame, bbox);
while (cap.read(frame)) {
// 检测物体
detector->detect(frame, bbox);
// 跟踪物体
tracker->update(frame, bbox);
// 绘制检测和跟踪结果
cv::rectangle(frame, bbox, cv::Scalar(0, 255, 0), 2);
// 显示图像
cv::imshow("Frame", frame);
cv::waitKey(1);
}
cap.release();
cv::destroyAllWindows();
return 0;
}
```
**代码逻辑分析:**
* 加载物体检测模型和物体跟踪器。
* 读取视频并初始化跟踪器。
* 在视频帧中检测和跟踪物体。
* 在帧上绘制检测和跟踪结果。
* 显示帧。
# 4. OpenCV实战应用**
**4.1 OpenCV图像处理实战**
**4.1.1 图像增强和滤波**
图像增强和滤波是图像处理中的基本操作,用于改善图像的视觉效果和提取有价值的信息。OpenCV提供了丰富的图像增强和滤波函数,可以满足各种图像处理需求。
* **图像增强:**
* **对比度和亮度调整:**cv2.convertScaleAbs()函数可调整图像的对比度和亮度,增强图像的细节和可视性。
* **直方图均衡化:**cv2.equalizeHist()函数通过重新分布图像的像素值,提高图像的对比度和动态范围。
* **伽马校正:**cv2.gammaCorrection()函数调整图像的伽马值,改变图像的亮度和对比度关系。
* **图像滤波:**
* **平滑滤波:**cv2.blur()函数使用均值滤波或高斯滤波平滑图像,去除噪声和模糊图像细节。
* **锐化滤波:**cv2.Laplacian()函数使用拉普拉斯算子锐化图像,增强图像边缘和纹理。
* **形态学滤波:**cv2.morphologyEx()函数执行形态学操作,如膨胀、腐蚀、开运算和闭运算,用于图像分割、对象提取和噪声去除。
**代码示例:**
```python
import cv2
# 图像读取
image = cv2.imread('image.jpg')
# 对比度和亮度调整
enhanced_image = cv2.convertScaleAbs(image, alpha=1.2, beta=20)
# 直方图均衡化
equalized_image = cv2.equalizeHist(image)
# 伽马校正
gamma_image = cv2.gammaCorrection(image, gamma=0.5)
# 平滑滤波
blurred_image = cv2.blur(image, (5, 5))
# 锐化滤波
sharpened_image = cv2.Laplacian(image, cv2.CV_64F)
# 形态学滤波(膨胀)
dilated_image = cv2.dilate(image, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
```
**4.1.2 图像分割和形态学**
图像分割是将图像划分为不同区域或对象的过程,而形态学是处理图像形状和结构的数学工具。OpenCV提供了强大的图像分割和形态学函数,用于提取图像中的感兴趣区域。
* **图像分割:**
* **阈值分割:**cv2.threshold()函数将图像像素分为两类,基于阈值进行二值化分割。
* **轮廓检测:**cv2.findContours()函数检测图像中的轮廓,提取对象的外围边界。
* **分水岭算法:**cv2.watershed()函数使用分水岭算法分割图像,将图像中的对象分隔开来。
* **形态学:**
* **膨胀:**cv2.dilate()函数扩大图像中对象的大小,填充孔洞和连接断开的区域。
* **腐蚀:**cv2.erode()函数缩小图像中对象的大小,去除噪声和细小物体。
* **开运算:**cv2.morphologyEx()函数使用膨胀和腐蚀操作的组合,去除噪声和分离对象。
* **闭运算:**cv2.morphologyEx()函数使用腐蚀和膨胀操作的组合,填充孔洞和连接对象。
**代码示例:**
```python
import cv2
# 图像读取
image = cv2.imread('image.jpg')
# 阈值分割
thresh, binary_image = cv2.threshold(image, 127, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, hierarchy = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 分水岭算法
segmented_image = cv2.watershed(image, markers=cv2.watershed(image, None, None, None, -1))
# 膨胀
dilated_image = cv2.dilate(image, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
# 腐蚀
eroded_image = cv2.erode(image, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
# 开运算
opened_image = cv2.morphologyEx(image, cv2.MORPH_OPEN, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
# 闭运算
closed_image = cv2.morphologyEx(image, cv2.MORPH_CLOSE, cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3)))
```
**4.2 OpenCV计算机视觉实战**
**4.2.1 人脸识别系统**
人脸识别是计算机视觉中的一项关键技术,用于识别和验证个人身份。OpenCV提供了先进的人脸识别算法,如Eigenfaces、Fisherfaces和LBPH,可以构建高效的人脸识别系统。
* **人脸检测:**cv2.CascadeClassifier()函数使用级联分类器检测图像中的人脸。
* **人脸识别:**cv2.face.EigenFacesRecognizer_create()、cv2.face.FisherFacesRecognizer_create()和cv2.face.LBPHFaceRecognizer_create()函数创建人脸识别器,训练模型并识别图像中的人脸。
**代码示例:**
```python
import cv2
import numpy as np
# 人脸检测器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 人脸识别器
recognizer = cv2.face.LBPHFaceRecognizer_create()
recognizer.read('trained_faces.yml')
# 视频捕获
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 人脸检测
faces = face_cascade.detectMultiScale(gray, 1.1, 5)
# 人脸识别
for (x, y, w, h) in faces:
roi_gray = gray[y:y+h, x:x+w]
label, confidence = recognizer.predict(roi_gray)
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(frame, str(label), (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
**4.2.2 物体追踪系统**
物体追踪是计算机视觉中另一项重要技术,用于跟踪图像或视频序列中的移动物体。OpenCV提供了多种物体追踪算法,如KCF、TLD和MOSSE,可以构建实时物体追踪系统。
* **物体检测:**cv2.TrackerKCF_create()、cv2.TrackerTLD_create()和cv2.TrackerMOSSE_create()函数创建物体追踪器,初始化追踪器并检测图像中的物体。
* **物体追踪:**追踪器update()函数更新追踪器的状态,并返回物体在当前帧中的位置。
**代码示例:**
```python
import cv2
# 视频捕获
cap = cv2.VideoCapture('video.mp4')
# 物体追踪器
tracker = cv2.TrackerKCF_create()
# 物体检测
ret, frame = cap.read()
bbox = cv2.selectROI('frame', frame, False)
tracker.init(frame, bbox)
while True:
ret, frame = cap.read()
if not ret:
break
# 物体追踪
success, bbox = tracker.update(frame)
if success:
(x, y, w, h) = [int(v) for v in bbox]
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
# 5.1 OpenCV深度学习
### 5.1.1 TensorFlow和Keras集成
OpenCV与TensorFlow和Keras等深度学习框架的集成,为计算机视觉和图像处理任务提供了强大的功能。
#### TensorFlow集成
TensorFlow是一个开源的深度学习框架,它提供了广泛的工具和库,用于构建和训练神经网络模型。OpenCV通过`cv2.dnn`模块提供了与TensorFlow的集成,允许用户直接在OpenCV应用程序中加载和执行TensorFlow模型。
```python
import cv2
import numpy as np
# 加载TensorFlow模型
model = cv2.dnn.readNetFromTensorflow("path/to/model.pb")
# 准备输入图像
image = cv2.imread("path/to/image.jpg")
blob = cv2.dnn.blobFromImage(image, 1.0, (224, 224), (104.0, 177.0, 123.0))
# 设置输入
model.setInput(blob)
# 执行前向传递
outputs = model.forward()
# 解析输出
result = np.argmax(outputs.flatten())
```
#### Keras集成
Keras是一个高级神经网络API,它建立在TensorFlow之上,提供了更高级别的抽象和更简单的API。OpenCV通过`cv2.keras`模块提供了与Keras的集成,允许用户直接在OpenCV应用程序中加载和执行Keras模型。
```python
import cv2
import numpy as np
# 加载Keras模型
model = cv2.keras.models.load_model("path/to/model.h5")
# 准备输入图像
image = cv2.imread("path/to/image.jpg")
blob = cv2.dnn.blobFromImage(image, 1.0, (224, 224), (104.0, 177.0, 123.0))
# 设置输入
model.input(blob)
# 执行前向传递
outputs = model.output()
# 解析输出
result = np.argmax(outputs.flatten())
```
### 5.1.2 图像分类和目标检测
OpenCV与深度学习框架的集成,使图像分类和目标检测等高级计算机视觉任务成为可能。
#### 图像分类
图像分类涉及将图像分配给预定义类别的任务。OpenCV提供了使用预训练模型或自定义模型进行图像分类的函数。
```python
# 使用预训练模型进行图像分类
classes = ["dog", "cat", "bird"]
model = cv2.dnn.readNetFromCaffe("path/to/deploy.prototxt.txt", "path/to/model.caffemodel")
image = cv2.imread("path/to/image.jpg")
blob = cv2.dnn.blobFromImage(image, 1.0, (224, 224), (104.0, 177.0, 123.0))
model.setInput(blob)
outputs = model.forward()
result = np.argmax(outputs.flatten())
print("Predicted class:", classes[result])
```
#### 目标检测
目标检测涉及在图像中识别和定位对象的任务。OpenCV提供了使用预训练模型或自定义模型进行目标检测的函数。
```python
# 使用预训练模型进行目标检测
classes = ["person", "car", "bicycle"]
model = cv2.dnn.readNetFromDarknet("path/to/yolov3.cfg", "path/to/yolov3.weights")
image = cv2.imread("path/to/image.jpg")
blob = cv2.dnn.blobFromImage(image, 1.0, (416, 416), (0, 0, 0), swapRB=True, crop=False)
model.setInput(blob)
outputs = model.forward()
for detection in outputs[0, 0]:
confidence = detection[2]
if confidence > 0.5:
class_id = int(detection[1])
x, y, w, h = detection[3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
cv2.rectangle(image, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 0), 2)
cv2.putText(image, classes[class_id], (int(x), int(y - 10)), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
```
# 6. OpenCV常见问题与解决方案**
**6.1 OpenCV编译和运行错误**
**6.1.1 缺少依赖库**
症状:编译或运行OpenCV程序时出现“找不到符号”或“无法解析外部符号”等错误。
解决方案:
1. 确保已安装所有必需的依赖库,如CMake、Boost和zlib。
2. 检查Visual Studio项目中的“链接器”设置,确保已将依赖库添加到“附加库目录”和“附加依赖项”中。
3. 使用第三方库管理工具,如vcpkg或Conan,来管理依赖项。
**6.1.2 环境变量配置错误**
症状:OpenCV函数无法找到或执行。
解决方案:
1. 检查系统环境变量中是否已正确设置OpenCV库的路径。
2. 检查Visual Studio项目的“属性”窗口中是否已正确配置环境变量。
3. 尝试重新启动Visual Studio或计算机。
**6.2 OpenCV图像处理和计算机视觉问题**
**6.2.1 图像加载失败**
症状:imread()或其他图像加载函数无法加载图像。
解决方案:
1. 检查图像路径是否正确。
2. 确保图像文件格式受OpenCV支持。
3. 检查图像文件是否损坏。
**6.2.2 算法执行结果不理想**
症状:OpenCV算法(如人脸检测或物体检测)的执行结果不符合预期。
解决方案:
1. 检查算法的参数是否正确设置。
2. 尝试使用不同的算法或调整算法参数。
3. 检查输入图像的质量和大小是否适合算法。
4. 确保算法已正确训练(如果需要)。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在为开发者提供全面的指南,帮助他们使用 Visual Studio 配置 OpenCV 并探索其图像处理功能。通过循序渐进的步骤,新手可以轻松上手 OpenCV 开发环境。专栏深入探讨了 OpenCV 图像处理的各个方面,从基本图像处理技术到高级应用和性能优化。此外,还介绍了 OpenCV 与机器学习、深度学习、云计算、移动开发、物联网、大数据分析和虚拟现实的结合,展示了 OpenCV 在广泛领域的应用潜力。通过本专栏,开发者可以掌握 OpenCV 图像处理的精髓,打造自己的图像处理应用,并解锁图像处理的无限可能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子打印小票的前端实现】:用Electron和Vue实现无缝打印

# 摘要
电子打印小票作为商业交易中不可或缺的一部分,其需求分析和实现对于提升用户体验和商业效率具有重要意义。本文首先介绍了电子打印小票的概念,接着深入探讨了Electron和Vue.js两种前端技术的基础知识及其优势,阐述了如何将这两者结合,以实现高效、响应
【EPLAN Fluid精通秘籍】:基础到高级技巧全覆盖,助你成为行业专家
# 摘要
EPLAN Fluid是针对工程设计的专业软件,旨在提高管道和仪表图(P&ID)的设计效率与质量。本文首先介绍了EPLAN Fluid的基本概念、安装流程以及用户界面的熟悉方法。随后,详细阐述了软件的基本操作,包括绘图工具的使用、项目结构管理以及自动化功能的应用。进一步地,本文通过实例分析,探讨了在复杂项目中如何进行规划实施、设计技巧的运用和数据的高效管理。此外,文章还涉及了高级优化技巧,包括性能调优和高级项目管理策略。最后,本文展望了EPLAN Fluid的未来版本特性及在智能制造中的应用趋势,为工业设计人员提供了全面的技术指南和未来发展方向。
# 关键字
EPLAN Fluid
小红书企业号认证优势大公开:为何认证是品牌成功的关键一步
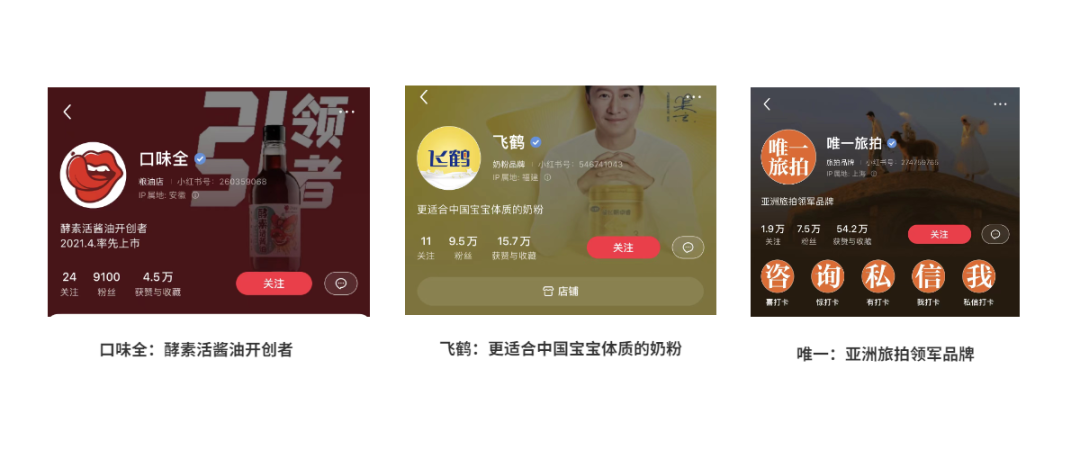
# 摘要
小红书企业号认证是品牌在小红书平台上的官方标识,代表了企业的权威性和可信度。本文概述了小红书企业号的市场地位和用户画像,分析了企业号与个人账号的区别及其市场意义,并详细解读了认证过程与要求。文章进一步探讨了企业号认证带来的优势,包括提升品牌权威性、拓展功能权限以及商业合作的机会。接着,文章提出了企业号认证后的运营策略,如内容营销、用户互动和数据分析优化。通过对成功认证案例的研究,评估
【用例图与图书馆管理系统的用户交互】:打造直观界面的关键策略
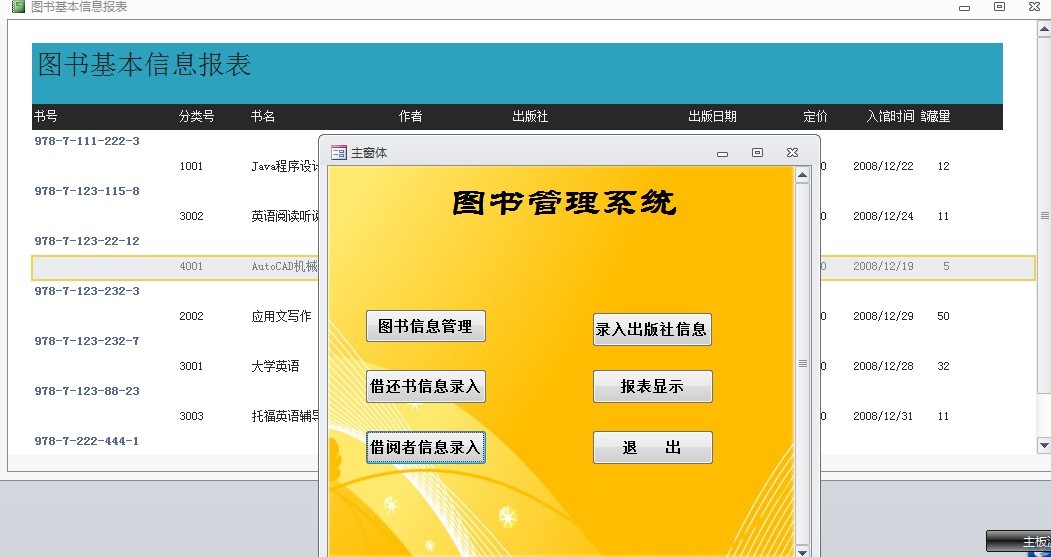
# 摘要
本文旨在探讨用例图在图书馆管理系统设计中的应用,从基础理论到实际应用进行了全面分析。第一章概述了用例图与图书馆管理系统的相关性。第二章详细介绍了用例图的理论基础、绘制方法及优化过程,强调了其在系统分析和设计中的作用。第三章则集中于用户交互设计原则和实现,包括用户界面布局、交互流程设计以及反馈机制。第四章具体阐述了用例图在功能模块划分、用户体验设计以及系统测试中的应用。
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
华为SUN2000-(33KTL, 40KTL) MODBUS接口安全性分析与防护

# 摘要
本文深入探讨了MODBUS协议在现代工业通信中的基础及应用背景,重点关注SUN2000-(33KTL, 40KTL)设备的MODBUS接口及其安全性。文章首先介绍了MODBUS协议的基础知识和安全性理论,包括安全机制、常见安全威胁、攻击类型、加密技术和认证方法。接着,文章转入实践,分析了部署在SUN2
【高速数据传输】:PRBS的优势与5个应对策略

# 摘要
本文旨在探讨高速数据传输的背景、理论基础、常见问题及其实践策略。首先介绍了高速数据传输的基本概念和背景,然后详细分析了伪随机二进制序列(PRBS)的理论基础及其在数据传输中的优势。文中还探讨了在高速数据传输过程中可能遇到的问题,例如信号衰减、干扰、传输延迟、带宽限制和同步问题,并提供了相应的解决方案。接着,文章提出了一系列实际应用策略,包括PRBS测试、信号处理技术和高效编码技术。最后,通过案例分析,本文展示了PRBS在
【GC4663传感器应用:提升系统性能的秘诀】:案例分析与实战技巧
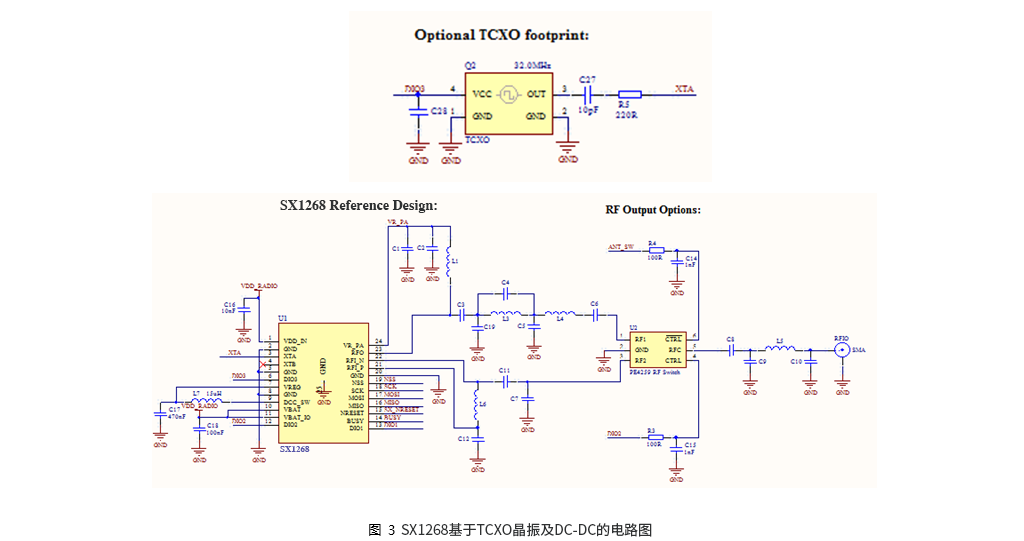
# 摘要
GC4663传感器是一种先进的检测设备,广泛应用于工业自动化和科研实验领域。本文首先概述了GC4663传感器的基本情况,随后详细介绍了其理论基础,包括工作原理、技术参数、数据采集机制、性能指标如精度、分辨率、响应时间和稳定性。接着,本文分析了GC4663传感器在系统性能优化中的关键作用,包括性能监控、数据处理、系统调优策略。此外,本文还探讨了GC4663传感器在硬件集成、软件接口编程、维护和故障排除方面的
NUMECA并行计算工程应用案例:揭秘性能优化的幕后英雄
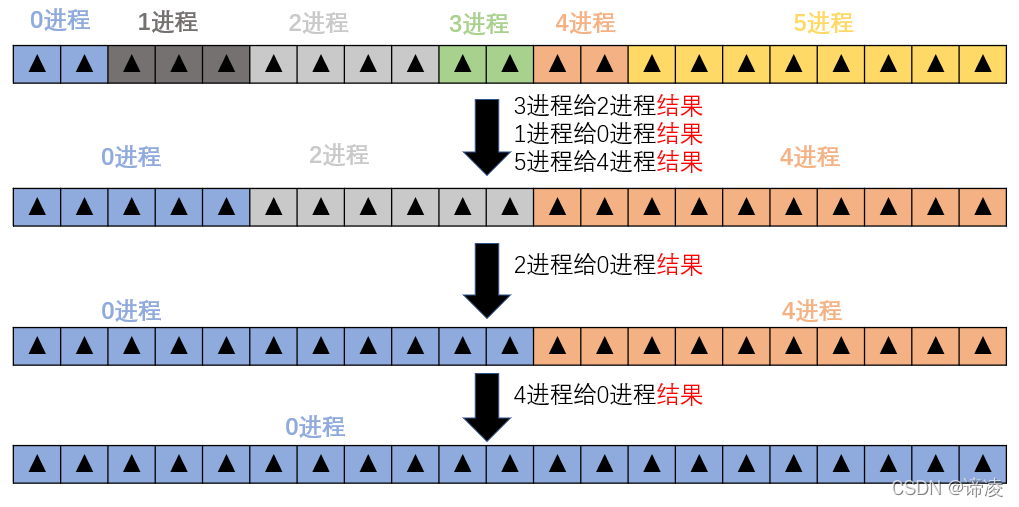
# 摘要
本文全面介绍NUMECA软件在并行计算领域的应用与实践,涵盖并行计算基础理论、软件架构、性能优化理论基础、实践操作、案例工程应用分析,以及并行计算在行业中的应用前景和知识拓展。通过探
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )