图的表示方法及其在实际系统中的应用
发布时间: 2024-02-23 00:58:27 阅读量: 14 订阅数: 16 
# 1. 引言
## 1.1 图的概念和基本表示方法
图是一种数据结构,由节点(顶点)和连接这些节点的边组成。在图论中,图是研究顶点之间连接关系的数学结构,广泛应用于计算机科学领域。图可以表示各种实际系统中的数据结构,如社交网络、网络拓扑结构等。
### 图的基本概念
- **顶点(Vertex)**:图中的节点,可以表示为V。
- **边(Edge)**:连接顶点的线段,可以表示为E。
- **有向图(Directed Graph)**:边有方向的图。
- **无向图(Undirected Graph)**:边没有方向的图。
## 1.2 图在实际系统中的重要性和应用价值
图作为一种强大的数据结构,在实际系统中有着广泛的应用价值,常见的应用包括:
- **社交网络分析**:通过图的方式表示社交网络中的人与人之间的关系,实现好友推荐、群组发现等功能。
- **路径规划系统**:利用图的最短路径算法,帮助用户找到最优路径,如地图导航软件中的路线规划。
- **网络拓扑结构分析**:在计算机网络领域中,利用图表示网络设备之间的连接关系,帮助进行网络优化和故障排除等工作。
在接下来的章节中,我们将深入探讨图的表示方法、遍历算法、最短路径算法、最小生成树算法以及实际系统中的应用案例分析。
# 2. 图的基本表示方法
在图论中,图是由节点(顶点)和边组成的一种数据结构,常用于描述各种实际问题中的关系和网络结构。图的基本表示方法有邻接矩阵表示法、邻接表表示法和关联矩阵表示法。接下来将详细介绍这三种表示方法。
### 2.1 邻接矩阵表示法
邻接矩阵是一个二维数组,用于表示图中节点之间的连接关系。对于一个有n个节点的图,邻接矩阵是一个n x n的矩阵,其中matrix[i][j]表示节点i到节点j是否有边相连,通常用0和1表示。
```python
# 邻接矩阵表示法示例代码
class Graph:
def __init__(self, num_nodes):
self.matrix = [[0] * num_nodes for _ in range(num_nodes)]
def add_edge(self, node1, node2):
self.matrix[node1][node2] = 1
self.matrix[node2][node1] = 1
# 创建一个包含4个节点的图
graph = Graph(4)
graph.add_edge(0, 1)
graph.add_edge(1, 2)
graph.add_edge(2, 3)
graph.add_edge(3, 0)
# 输出邻接矩阵
for row in graph.matrix:
print(row)
```
**代码总结:** 邻接矩阵表示法适合稠密图,空间复杂度较高,但可以快速判断节点间的连接关系。
### 2.2 邻接表表示法
邻接表是一个以数组为主体的数据结构,每个节点对应一个链表,链表中存储和该节点相连的其他节点。邻接表表示法节约空间,适合表示稀疏图。
```python
# 邻接表表示法示例代码
from collections import defaultdict
class Graph:
def __init__(self):
self.adj_list = defaultdict(list)
def add_edge(self, node1, node2):
self.adj_list[node1].append(node2)
self.adj_list[node2].append(node1)
# 创建一个图并添加边
graph = Graph()
graph.add_edge(0, 1)
graph.add_edge(0, 2)
graph.add_edge(1, 2)
graph.add_edge(2, 3)
# 输出邻接表
for node, neighbors in graph.adj_list.items():
print(f"Node {node}: {neighbors}")
```
**代码总结:** 邻接表表示法适合稀疏图,节约空间,查找某节点的邻居较为高效。
### 2.3 关联矩阵表示法
关联矩阵是一个二维数组,其中行表示节点,列表示边,用1表示节点和边的关联。关联矩阵适合表示节点和边的关联程度较高的图。
关联矩阵表示法与邻接矩阵表示法类似,只是关联矩阵中的1表示节点和边的关联,而邻接矩阵中的1表示节点之间的连接关系。
以上是图的基本表示方法的介绍,不同的表示方法适用于不同类型的图,具体选择应根据实际需求和图的特点来决定。
# 3. 图的遍历算法及其应用
#### 3.1 深度优先搜索算法
深度优先搜索(DFS)是一种用于遍历或搜索树或图的算法。在这个算法中,首先访问起始顶点,然后探索尽可能深的分支,直到该分支不再有未探索的节点为止,然后回溯到前一个节点,再探索下一个分支。
```python
def dfs(graph, start, visited):
if start not in visited:
print(start)
visited.add(start)
for neighbor in graph[start]:
dfs(graph, neighbor, visited)
# 示例图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': [],
'D': [],
'E': ['F'],
'F': []
}
visited = set()
dfs(graph, 'A', visited)
```
**代码场景说明**:以上代码实现了一个简单的深度优先搜索算法,对给定的图进行深度优先遍历,并输出遍历顺序。
**代码总结**:深度优先搜索算法通过递归的方式实现,能够访问到图中所有的节点,并按照深度优先的顺序进行遍历。
**结果说明**:对于示例图,从顶点'A'开始进行深度优先搜索,输出顺序为A -> B -> D -> E -> F -> C。
#### 3.2 广度优先搜索算法
广度优先搜索(BFS)是另一种用于遍历或搜索图的算法。在这个算法中,首先访问起始顶点,然后逐层访问与起始顶点相邻的节点,直到所有节点都被访问。
```java
import java.util.*;
public void bfs(Map<Character, List<Character>> graph, char start) {
Queue<Character> queue = new LinkedList<>();
Set<Character> visited = new HashSet<>();
queue.offer(start);
visited.add(start);
while (!queue.isEmpty()) {
char current = queue.poll();
System.out.println(current);
for (char neighbor : graph.get(current)) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor);
visited.add(neighbor);
}
}
}
}
```
**代码场景说明**:以上Java代码展示了广度优先搜索算法的实现,通过队列实现广度优先遍历,以'起始顶点'开始遍历。
**代码总结**:广度优先搜索算法通过队列实现,确保了先访问到的节点会先被遍历,适合用于寻找最短路径等场景。
**结果说明**:对于示例图,从顶点'A'开始进行广度优先搜索,输出顺序为A -> B -> C -> D -> E -> F。
#### 3.3 遍历算法在实际系统中的应用案例
在实际系统中,遍历算法被广泛应用于图数据库的查询、社交网络分析、网络爬虫的页面抓取等场景。通过深度优先搜索和广度优先搜索等算法,可以高效地处理图结构数据,并实现各种应用功能。
# 4. 最短路径算法
在图论中,求解最短路径是一类重要的问题,常用的算法包括Dijkstra算法、Floyd-Warshall算法等,它们在各种实际系统中都有着广泛的应用。
#### 4.1 Dijkstra算法
Dijkstra算法是一种用来求解单源最短路径的算法,通过不断更新起始点到各个顶点的最短路径长度来找到最短路径。下面是Dijkstra算法的Python实现:
```python
import heapq
def dijkstra(graph, start):
distances = {node: float('infinity') for node in graph}
distances[start] = 0
pq = [(0, start)]
while pq:
current_distance, current_node = heapq.heappop(pq)
if current_distance > distances[current_node]:
continue
for neighbor, weight in graph[current_node].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(pq, (distance, neighbor))
return distances
# 示例图的邻接表表示
graph = {
'A': {'B': 5, 'C': 2},
'B': {'A': 5, 'C': 1, 'D': 3},
'C': {'A': 2, 'B': 1, 'D': 6},
'D': {'B': 3, 'C': 6}
}
start_node = 'A'
result = dijkstra(graph, start_node)
print("从节点 {} 开始的最短路径为: {}".format(start_node, result))
```
**代码总结:**
- Dijkstra算法通过维护一个优先队列来不断更新最短路径信息,直到找到所有节点的最短路径。
- 时间复杂度为O((V+E)logV),其中V为顶点数,E为边数。
**结果说明:**
输出的结果为从节点'A'出发到其他节点的最短路径长度,如从'A'到'C'的最短路径为2。
#### 4.2 Floyd-Warshall算法
Floyd-Warshall算法用于求解图中任意两点之间的最短路径,它采用动态规划的思想,逐步更新路径长度。下面是Floyd-Warshall算法的Java实现:
```java
public class FloydWarshall {
public static void floydWarshall(int[][] graph) {
int V = graph.length;
for (int k = 0; k < V; k++) {
for (int i = 0; i < V; i++) {
for (int j = 0; j < V; j++) {
if (graph[i][k] + graph[k][j] < graph[i][j]) {
graph[i][j] = graph[i][k] + graph[k][j];
}
}
}
}
}
public static void main(String[] args) {
int[][] graph = {
{0, 5, Integer.MAX_VALUE, 9},
{Integer.MAX_VALUE, 0, 3, Integer.MAX_VALUE},
{Integer.MAX_VALUE, Integer.MAX_VALUE, 0, 1},
{Integer.MAX_VALUE, Integer.MAX_VALUE, Integer.MAX_VALUE, 0}
};
floydWarshall(graph);
System.out.println("任意两点之间的最短路径长度如下:");
for (int i = 0; i < graph.length; i++) {
for (int j = 0; j < graph[0].length; j++) {
System.out.print(graph[i][j] + " ");
}
System.out.println();
}
}
}
```
**代码总结:**
- Floyd-Warshall算法采用三层循环逐步更新最短路径的长度。
- 时间复杂度为O(V^3),适用于稠密图。
**结果说明:**
输出的二维数组表示任意两点之间的最短路径长度,当某个值为Integer.MAX_VALUE时,表示两点之间没有直接连线。
#### 4.3 最短路径算法在网络规划中的应用
最短路径算法在网络规划领域有着广泛的应用,如路由器路由算法、网络传输等方面均离不开最短路径算法的支持。通过合理选择不同的最短路径算法,可以提升网络传输效率,优化网络结构设计。
通过以上介绍,我们了解了Dijkstra算法和Floyd-Warshall算法在求解最短路径问题中的应用方法及实现代码。
# 5. 最小生成树算法
在图论中,最小生成树是一个连通加权图的生成树中,所有边的权值和最小的生成树。最小生成树算法主要有Prim算法和Kruskal算法两种。
### 5.1 Prim算法
Prim算法是一种以顶点为基础的贪婪算法,从一个起始顶点开始,逐步构建生成树,每次选择与当前生成树相邻且权值最小的边所连接的顶点加入生成树中,直到覆盖所有顶点为止。
#### Prim算法实现(Python版本):
```python
def prim(graph):
num_vertices = len(graph)
INF = float('inf')
selected = [False] * num_vertices
min_weight = [INF] * num_vertices
min_weight[0] = 0
parent = [-1] * num_vertices
for _ in range(num_vertices):
u = -1
for i in range(num_vertices):
if not selected[i] and (u == -1 or min_weight[i] < min_weight[u]):
u = i
selected[u] = True
for v in range(num_vertices):
if graph[u][v] != 0 and not selected[v] and graph[u][v] < min_weight[v]:
parent[v] = u
min_weight[v] = graph[u][v]
return parent
# Example Usage
graph = [
[0, 2, 0, 6, 0],
[2, 0, 3, 8, 5],
[0, 3, 0, 0, 7],
[6, 8, 0, 0, 9],
[0, 5, 7, 9, 0]
]
result = prim(graph)
print(result)
```
#### Prim算法代码总结及结果说明:
- Prim算法采用贪婪策略,每次选择权值最小的边,保证生成的最小生成树总权值最小。
- 代码中给出了Prim算法的Python实现,并对一个示例图进行了测试。
- 运行结果将会输出最小生成树的父节点数组。
### 5.2 Kruskal算法
Kruskal算法是一种基于边的贪婪算法,将所有边按照权值递增的顺序排序,然后依次加入生成树中,若形成回路则舍弃,直到所有顶点都在生成树中。
#### Kruskal算法实现(Java版本):
```java
import java.util.Arrays;
class KruskalAlgorithm {
static class Edge implements Comparable<Edge> {
int src, dest, weight;
public int compareTo(Edge compareEdge) {
return this.weight - compareEdge.weight;
}
};
static class Subset {
int parent, rank;
};
int V, E;
Edge edges[];
KruskalAlgorithm(int v, int e) {
V = v;
E = e;
edges = new Edge[E];
for (int i = 0; i < e; ++i)
edges[i] = new Edge();
}
int find(Subset subsets[], int i) {
if (subsets[i].parent != i)
subsets[i].parent = find(subsets, subsets[i].parent);
return subsets[i].parent;
}
void union(Subset subsets[], int x, int y) {
int xroot = find(subsets, x);
int yroot = find(subsets, y);
if (subsets[xroot].rank < subsets[yroot].rank)
subsets[xroot].parent = yroot;
else if (subsets[xroot].rank > subsets[yroot].rank)
subsets[yroot].parent = xroot;
else {
subsets[yroot].parent = xroot;
subsets[xroot].rank++;
}
}
void kruskalMST() {
Edge[] result = new Edge[V];
int e = 0;
int i = 0;
for (i = 0; i < V; ++i)
result[i] = new Edge();
Arrays.sort(edges);
Subset[] subsets = new Subset[V];
for (i = 0; i < V; ++i)
subsets[i] = new Subset();
for (int v = 0; v < V; ++v) {
subsets[v].parent = v;
subsets[v].rank = 0;
}
i = 0;
while (e < V - 1) {
Edge next_edge = edges[i++];
int x = find(subsets, next_edge.src);
int y = find(subsets, next_edge.dest);
if (x != y) {
result[e++] = next_edge;
union(subsets, x, y);
}
}
for (i = 0; i < e; ++i)
System.out.println(result[i].src + " - " + result[i].dest + ": " + result[i].weight);
}
public static void main(String[] args) {
int V = 4;
int E = 5;
KruskalAlgorithm graph = new KruskalAlgorithm(V, E);
graph.edges[0].src = 0;
graph.edges[0].dest = 1;
graph.edges[0].weight = 10;
graph.edges[1].src = 0;
graph.edges[1].dest = 2;
graph.edges[1].weight = 6;
graph.edges[2].src = 0;
graph.edges[2].dest = 3;
graph.edges[2].weight = 5;
graph.edges[3].src = 1;
graph.edges[3].dest = 3;
graph.edges[3].weight = 15;
graph.edges[4].src = 2;
graph.edges[4].dest = 3;
graph.edges[4].weight = 4;
graph.kruskalMST();
}
}
```
#### Kruskal算法代码总结及结果说明:
- Kruskal算法通过对边进行排序,逐步选择权值最小的边,直到所有顶点都在生成树中。
- 代码中给出了Kruskal算法的Java实现,并对一个示例图进行了测试。
- 运行结果将输出最小生成树的各条边及其权值。
### 5.3 最小生成树算法在通信网络建设中的应用
最小生成树算法在通信网络建设中有着广泛的应用,通过构建最小生成树可以实现网络中节点之间的高效通信,降低通信成本,提高网络性能。在计算机网络、电信领域都有着重要的意义。
以上是最小生成树算法的介绍,包括Prim算法和Kruskal算法的原理、实现及应用。
# 6. 实际系统中的图表示方法应用案例分析
在实际系统中,图表示方法有着广泛的应用。下面将分别从社交网络分析、路径规划系统和网络拓扑结构分析三个方面进行案例分析。
#### 6.1 社交网络分析
社交网络分析是图论在实际系统中的重要应用之一。通过图的表示方法,可以将社交网络中的个体视为图中的节点,个体之间的关系视为图中的边,进而利用图的遍历算法、最短路径算法以及最小生成树算法等进行社交网络的分析和挖掘。比如,在推荐系统中利用用户之间的关系网络进行信息推荐,通过分析社交网络的拓扑结构来发现潜在的社区群体等。
#### 6.2 路径规划系统中的应用
路径规划系统是导航、物流配送等实际系统中的重要应用场景。在路径规划系统中,地图中的道路和交通节点可以被抽象成图的节点和边,利用图的最短路径算法可以快速有效地找到起点到终点的最优路径。同时,利用图的遍历算法可以进行全局范围的路线探索,为路径规划系统提供多样化的路径选择。
#### 6.3 网络拓扑结构分析
在计算机网络领域,网络拓扑结构分析是图表示方法的重要应用之一。通过将网络中的设备和连接关系抽象成图,可以利用图的遍历算法和最小生成树算法来分析网络中的拓扑结构,发现网络中的关键节点和环路,从而优化网络的布局和提高网络的稳定性和可靠性。
以上是实际系统中图表示方法应用案例的简要分析,实际应用中还可以根据具体场景灵活运用不同的图算法来解决实际问题。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏旨在深入探讨图论算法在实际系统中的应用,涵盖了图的表示方法、最短路径算法、拓扑排序、网络流、图着色、欧拉回路、汉密尔顿回路等多个领域。通过对Dijkstra算法、Floyd-Warshall算法、Ford-Fulkerson算法等经典算法的原理和实现进行解析,帮助读者深入理解各种图论算法的核心思想。同时,探讨了图嵌入算法在图数据挖掘中的应用,以及图着色问题在调度优化中的实际应用场景。通过专栏的阅读,读者将能够全面了解图论算法的原理、实现以及在不同领域中的应用,为其进一步深入学习和应用提供了重要参考。
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实战演练】通过强化学习优化能源管理系统实战
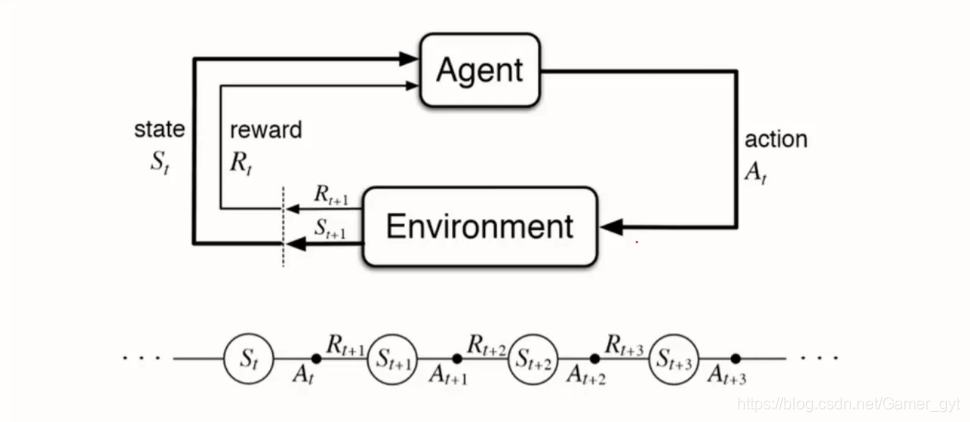
# 2.1 强化学习的基本原理
强化学习是一种机器学习方法,它允许智能体通过与环境的交互来学习最佳行为。在强化学习中,智能体通过执行动作与环境交互,并根据其行为的
【实战演练】综合案例:数据科学项目中的高等数学应用

# 1. 数据科学项目中的高等数学基础**
高等数学在数据科学中扮演着至关重要的角色,为数据分析、建模和优化提供了坚实的理论基础。本节将概述数据科学
【实战演练】python云数据库部署:从选择到实施
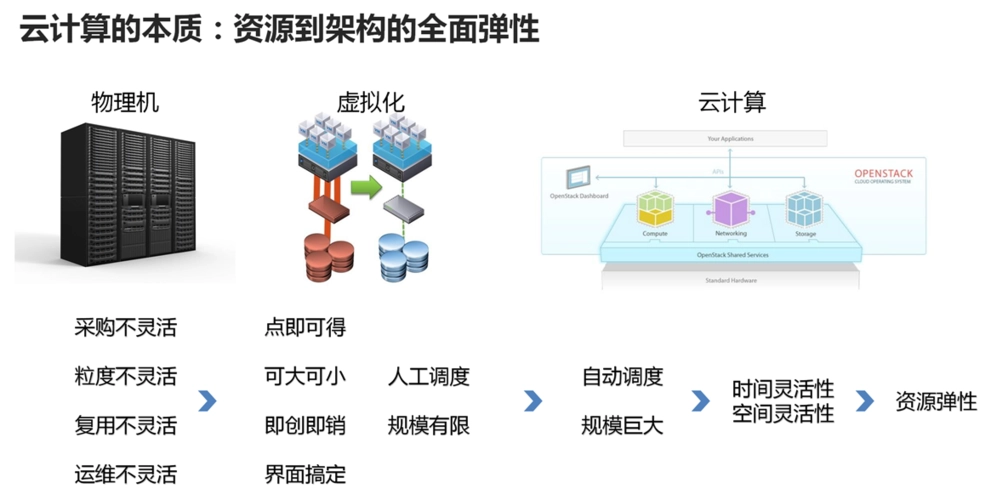
# 2.1 云数据库类型及优劣对比
**关系型数据库(RDBMS)**
* **优点:**
* 结构化数据存储,支持复杂查询和事务
* 广泛使用,成熟且稳定
* **缺点:**
* 扩展性受限,垂直扩展成本高
* 不适合处理非结构化或半结构化数据
**非关系型数据库(NoSQL)**
* **优点:**
* 可扩展性强,水平扩展成本低
【实战演练】深度学习在计算机视觉中的综合应用项目

# 1. 计算机视觉概述**
计算机视觉(CV)是人工智能(AI)的一个分支,它使计算机能够“看到”和理解图像和视频。CV 旨在赋予计算机人类视觉系统的能力,包括图像识别、对象检测、场景理解和视频分析。
CV 在广泛的应用中发挥着至关重要的作用,包括医疗诊断、自动驾驶、安防监控和工业自动化。它通过从视觉数据中提取有意义的信息,为计算机提供环境感知能力,从而实现这些应用。
# 2.1 卷积
【实战演练】使用Docker与Kubernetes进行容器化管理
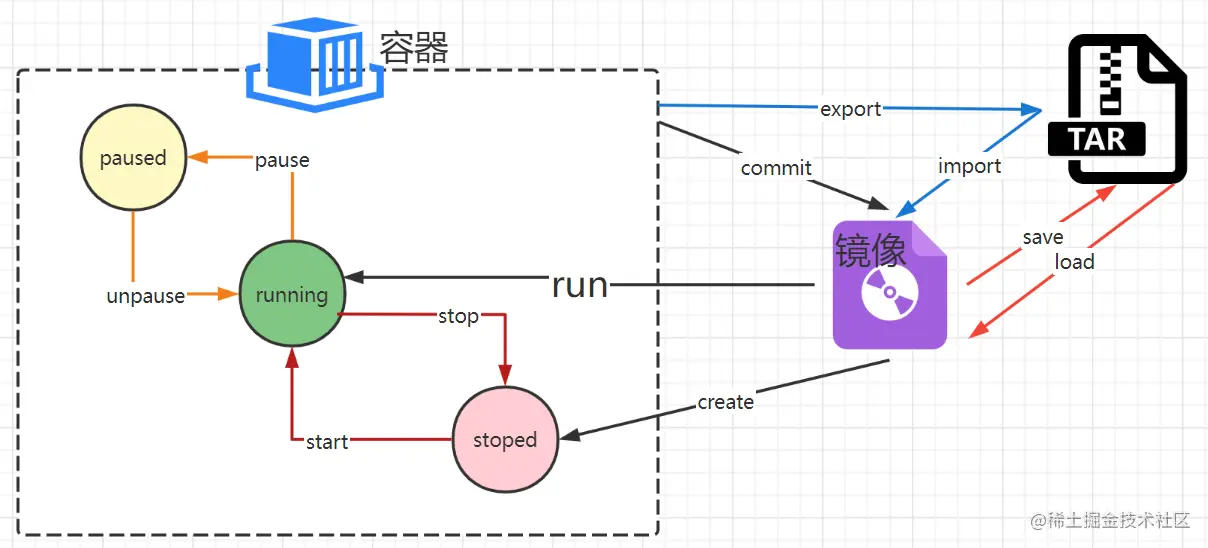
# 2.1 Docker容器的基本概念和架构
Docker容器是一种轻量级的虚拟化技术,它允许在隔离的环境中运行应用程序。与传统虚拟机不同,Docker容器共享主机内核,从而减少了资源开销并提高了性能。
Docker容器基于镜像构建。镜像是包含应用程序及
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】python远程工具包paramiko使用
# 1. Python远程工具包Paramiko简介**
Paramiko是一个用于Python的SSH2协议的库,它提供了对远程服务器的连接、命令执行和文件传输等功能。Paramiko可以广泛应用于自动化任务、系统管理和网络安全等领域。
# 2. Paramiko基础
### 2.1 Paramiko的安装和配置
**安装 Paramiko**
```python
pip install
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
【实战演练】使用Python和Tweepy开发Twitter自动化机器人

# 1. Twitter自动化机器人概述**
Twitter自动化机器人是一种软件程序,可自动执行在Twitter平台上的任务,例如发布推文、回复提及和关注用户。它们被广泛用于营销、客户服务和研究等各种目的。
自动化机器人可以帮助企业和个人节省时间和精力,同时提高其Twitter活动的效率。它们还可以用于执行复杂的任务,例如分析推文情绪或
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )