Linux文件IO的打开和关闭
发布时间: 2024-03-09 04:22:47 阅读量: 46 订阅数: 25 

linux下文件io的操作
# 1. 理解Linux文件IO的基础概念
## 1.1 什么是文件IO
文件IO(Input/Output)是指计算机处理数据的输入和输出操作。在Linux系统中,文件IO是指通过文件来进行数据的读取和写入操作,是与外部设备进行数据交换的一种方式。
## 1.2 Linux文件IO的基本原理
Linux系统中,一切皆文件,包括磁盘文件、终端设备、网络接口等,它们都可以通过文件IO的方式来进行数据的读写操作。在Linux中,文件IO遵循“一切皆文件”的原则,通过文件描述符和系统调用来实现。
## 1.3 文件IO的打开和关闭在Linux系统中的重要性
在Linux系统中,文件IO的打开和关闭操作非常重要。通过文件的打开操作,可以获取文件描述符,建立文件和程序之间的联系;而文件的关闭操作则会释放系统资源,避免资源泄露问题的发生。合理使用文件IO的打开和关闭操作可以提高程序的性能和稳定性。
# 2. 文件IO的打开操作
在本章中,我们将深入探讨文件IO的打开操作,并围绕文件描述符、文件表、`open()`函数的使用方法以及文件打开过程中涉及的系统调用和文件状态改变展开讨论。接下来让我们一起来深入了解文件IO的打开操作吧。
#### 2.1 文件描述符和文件表
在Linux系统中,每个打开的文件都关联着一个文件描述符,这个文件描述符是一个非负整数,用于唯一标识该打开的文件。当程序打开一个文件时,内核会为该文件分配一个文件表项,文件表项中包含了该文件的状态信息,如当前文件偏移量、文件的访问模式等。
#### 2.2 open()函数的使用方法
在Linux系统中,可以使用`open()`函数来打开一个文件,并获取其文件描述符。`open()`函数的原型如下:
```c
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
```
- `pathname`参数指定了要打开的文件路径
- `flags`参数指定了文件的打开方式,如只读、只写、读写等
- `mode`参数仅在创建文件时有效,用于指定文件的权限
#### 2.3 文件打开过程中涉及的系统调用和文件状态改变
在调用`open()`函数后,内核会进行一系列操作来处理文件的打开请求,包括查找文件、检查权限、分配文件描述符等。同时,文件的状态也会发生改变,如文件的打开次数会增加,文件的状态标志也会相应改变。
这就是文件IO的打开操作的基本概念和原理,接下来我们将会介绍文件IO的关闭操作。
# 3. 文件IO的关闭操作
在文件IO操作中,及时关闭文件是十分重要的,这样可以释放系统资源,避免资源泄露和文件损坏等问题。本章将详细介绍文件IO的关闭操作的相关内容。
#### 3.1 close()函数的作用和使用方法
在Linux系统中,使用`close()`函数来关闭一个文件描述符。其函数原型如下:
```c
#include <unistd.h>
int close(int fd);
```
- `fd`为待关闭的文件描述符。
调用`close()`函数后,系统会释放对应文件描述符的资源,并将其从文件描述符表中移除。下面是一个简单的示例:
```c
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
int main() {
int fd = open("example.txt", O_RDONLY);
if (fd == -1) {
perror("open");
return 1;
}
// 读取文件内容...
if (close(fd) == -1) {
perror("close");
return 1;
}
return 0;
}
```
在上面的示例中,首先打开了一个文件"example.txt"进行读取操作,之后使用`close()`函数关闭了文件描述符。在实际应用中,务必检查`close()`函数的返回值,以确保文件关闭操作是否成功。
#### 3.2 关闭文件对系统资源的释放
文件IO操作涉及到系统资源的管理,如果不及时关闭文件,将可能导致资源泄露,造成系统性能下降甚至系统崩溃。因此,在文件不再需要时,务必调用`close()`函数来关闭文件。
#### 3.3 文件关闭的注意事项和最佳实践
- 在文件IO操作结束后尽早关闭文件,避免资源浪费和泄露。
- 多次调用`close()`函数不会造成错误,但建议确保每个文件描述符只被关闭一次。
- 注意处理`close()`函数可能返回的错误,及时进行错误处理。
通过合理使用`close()`函数,可以有效管理文件IO操作中的系统资源,确保系统的稳定性和性能。
# 4. Linux文件IO的读取和写入
在本章中,我们将深入探讨Linux系统下文件IO的读取和写入操作。我们将介绍文件的基本读取和写入操作,讨论文件IO中的缓冲区和数据传输效率,以及提供一些性能优化和最佳实践的建议。
#### 4.1 读取文件的基本操作
在Linux系统中,可以使用open()函数打开文件,然后使用read()函数从文件中读取数据。read()函数从指定的文件描述符中读取数据,并将数据存储到指定的缓冲区中。下面是一个简单的Python示例,演示如何读取文件内容:
```python
# 打开文件
file = open('example.txt', 'r')
# 读取文件内容
data = file.read()
print(data)
# 关闭文件
file.close()
```
上述代码中,我们首先使用open()函数以只读模式打开名为example.txt的文件。随后,我们使用read()函数从文件中读取内容,并将其存储在变量data中。最后,我们关闭文件,以释放系统资源。
#### 4.2 写入文件的基本操作
类似地,我们可以使用open()函数创建或打开一个文件,并使用write()函数向文件中写入数据。write()函数将指定的数据写入文件,完成后数据将被保存到文件中。下面是一个Python示例,演示如何将内容写入文件:
```python
# 打开(或创建)文件
file = open('output.txt', 'w')
# 写入内容
file.write('Hello, World!')
# 关闭文件
file.close()
```
在上述示例中,我们使用open()函数以写入模式打开名为output.txt的文件,然后使用write()函数向文件中写入一行文本。最后,我们关闭文件,确保数据被正确地写入并释放系统资源。
#### 4.3 文件IO中的缓冲区和数据传输效率
值得注意的是,文件IO操作中的性能和效率受到缓冲区的影响。系统通常会使用缓冲区来优化IO操作,从而提高数据传输效率。在文件读取和写入过程中,缓冲区的大小和管理方式都会对性能产生重要影响。因此,在实际应用中,我们需要注意缓冲区的使用和优化,以获取更好的文件IO性能。
通过本节的学习,我们详细了解了Linux系统下文件IO的读取和写入操作。我们学习了基本的文件读取和写入方法,以及缓冲区对文件IO效率的重要性。在下一章中,我们将学习文件IO的错误处理和异常情况。
# 5. 文件IO的错误处理和异常情况
在文件IO操作过程中,可能会出现各种异常情况和错误码,正确处理这些异常情况是保证程序稳定性和可靠性的重要一环。本章节将介绍文件IO中常见的错误处理方式和解决方法。
### 5.1 文件打开失败的处理方式
当尝试打开一个文件时,有可能会因为文件不存在、权限问题或者其他原因导致打开失败。在实际编程中,我们需要对文件打开失败时进行合理处理,例如:
```python
try:
file = open("non_existent_file.txt", "r")
except FileNotFoundError:
print("File not found.")
except PermissionError:
print("Permission denied.")
except Exception as e:
print("An error occurred:", e)
```
**代码解析**:
- 尝试打开一个名为"non_existent_file.txt"的文件,如果文件不存在,会抛出`FileNotFoundError`异常,我们捕获并打印"File not found."。
- 如果文件存在但权限不足,会抛出`PermissionError`异常,我们捕获并打印"Permission denied."。
- 如果出现其他未知异常,使用`Exception`捕获并打印具体的错误信息。
### 5.2 文件关闭导致的异常情况处理
在关闭文件时也可能出现异常情况,例如文件已经被关闭、文件对象为`None`等情况。为避免可能的错误,我们在关闭文件之前需要做一些判断和处理:
```python
file = None
try:
file = open("example.txt", "r")
# 处理文件内容
finally:
if file is not None:
try:
file.close()
except Exception as e:
print("An error occurred while closing the file:", e)
else:
print("File is already closed.")
```
**代码解析**:
- 首先尝试打开文件"example.txt",处理文件操作。
- 在`finally`块中,判断文件对象是否为`None`,如果不为`None`,则尝试关闭文件。
- 如果关闭过程中出现异常,使用`Exception`捕获并打印错误信息;如果文件对象为`None`,则打印"File is already closed."。
### 5.3 文件IO操作时可能出现的错误码和解决方法
在文件IO操作中,系统可能会返回各种错误码以指示操作状态,常见的错误码包括:
- `EACCES`:权限不足。
- `ENOENT`:文件或目录不存在。
- `EIO`:IO错误。
针对不同的错误码,我们可以采取不同的解决方法,例如重试操作、权限检查、日志记录等方式。
以上是关于文件IO的错误处理和异常情况的具体内容,正确处理异常情况是保证程序稳定性和可靠性的关键一步,希望本章内容对您有所帮助。
# 6. 文件IO的性能优化和最佳实践
在文件IO操作中,性能优化和最佳实践对于提升系统整体性能至关重要。本章将介绍如何通过使用异步IO、优化文件读写缓冲以及遵循文件IO操作的最佳实践和注意事项来实现文件IO性能的优化。
### 6.1 使用异步IO提高文件操作性能
异步IO是一种能够在文件IO操作进行的同时执行其他操作的机制,它能够充分利用系统资源,提高IO操作的效率。在Linux系统中,可以通过使用libaio库来实现异步IO。以下是基于Python的异步IO示例代码:
```python
import asyncio
import aiofiles
async def async_file_io_operation():
async with aiofiles.open('example.txt', mode='r') as file:
data = await file.read()
# 进行其他耗时操作
# 调用异步IO操作
asyncio.run(async_file_io_operation())
```
上述示例中,通过使用aiofiles库实现了异步文件读取操作,同时可以在文件读取的过程中执行其他耗时操作,从而提高程序的整体性能。
### 6.2 文件读写缓冲的优化方法
在进行大文件读写操作时,合理配置读写缓冲区可以有效提高IO性能。在Python中,可以通过设置缓冲区大小来优化文件读写性能,示例如下:
```python
# 设置写缓冲区大小为4MB
with open('example.txt', mode='w', buffering=4096*1024) as file:
file.write('Lorem ipsum dolor sit amet, consectetur adipiscing elit...')
```
在上述示例中,通过设置写缓冲区大小为4MB,可以让系统在写入文件时采用更大的缓冲区,从而减少IO操作的次数,提高写入性能。
### 6.3 文件IO操作中的最佳实践和注意事项
在进行文件IO操作时,还需要遵循一些最佳实践和注意事项来确保系统稳定性和性能。例如,需要及时关闭文件以释放系统资源、对文件打开、读取、写入等操作进行异常处理、合理使用文件锁等。这些最佳实践和注意事项可以在一定程度上提高文件IO操作的性能和可靠性,保障系统正常运行。
以上是关于文件IO的性能优化和最佳实践的介绍,通过使用异步IO、优化文件读写缓冲以及遵循最佳实践和注意事项,可以有效提高文件IO操作的性能和稳定性。
希望这些内容能够帮助你更好地理解和应用文件IO操作的性能优化和最佳实践。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ISO20860-1-2008中文版:企业数据分析能力提升指南
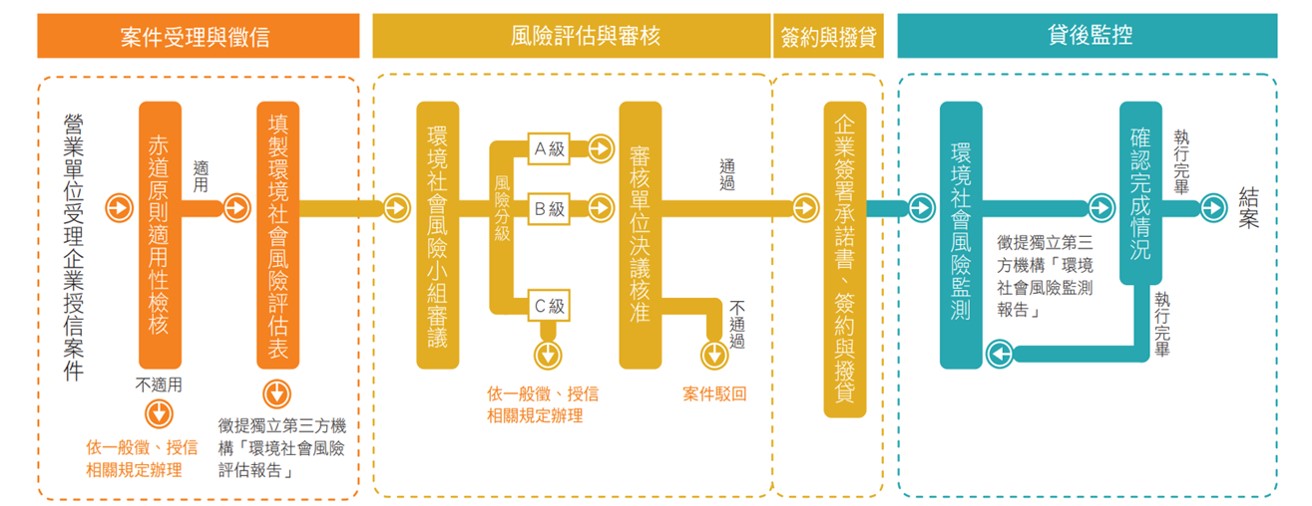
# 摘要
企业数据分析能力对于现代企业的成功至关重要。本文首先探讨了数据分析的重要性以及其理论基础,包括数据分析的定义、核心流程和不同分析方法论。接着,详细介绍了数据预处理技术、分析工具及数据可视化技巧。在实战应用方面,本文深入分析了数据分析在业务流程优化、客户关系管理和风险控制
提升设计到制造效率:ODB++优化技巧大公开

# 摘要
本文全面介绍并分析了ODB++技术的特性、设计数据结构及其在制造业的应用。首先,简要概述了ODB++的优势及其作为设计到制造数据交换格式的重要价值。接着,详细探讨了ODB++的设计数据结构,包括文件结构、逻辑层次、数据精度与错误检查等方面,为读者提供了对ODB++深入理解的框架。第三部分聚焦于ODB++数据的优化技巧,包括数据压缩、归档、提取、重构以及自动化处理流程,旨在提升数据管理和制造效率。第四章通过
【Shell脚本高级应用】:平衡密码管理与自动登录的5大策略

# 摘要
在数字化时代,密码管理和自动登录技术对于提高效率和保障网络安全至关重要。本文首先探讨了密码管理和自动登录的必要性,然后详细介绍了Shell脚本中密码处理的安全策略,包括密码的存储和更新机制。接着,本文深入分析了SSH自动登录的原理与实现,并
【启动流程深度解析】:Zynq 7015核心板启动背后的原理图秘密
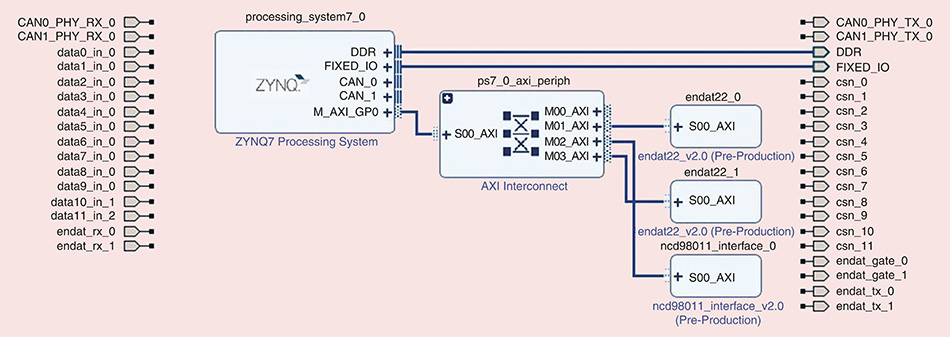
# 摘要
Zynq 7015核心板作为一款集成了双核ARM Cortex-A9处理器和可编程逻辑(PL)的片上系统(SoC),在嵌入式设计领域中扮演着重要角色。本文详细介绍了Zynq 7015核心板的启动过程,包括启动机制的理论基础、启动流程的深入实践以及启动问题的诊断与解决。通过对启动序
卫星导航与无线通信的无缝对接:兼容性分析报告

# 摘要
随着科技的发展,卫星导航与无线通信系统的融合变得越来越重要。本文旨在深入探讨卫星导航和无线通信系统之间的兼容性问题,包括理论基础、技术特点、以及融合技术的实践与挑战。兼容性是确保不同系统间有效互操作性的关键,本文分析了兼容性理论框架、分析方法论,并探讨了如何将这些理论应用于实践。特别地,文章详细评估了卫星导航系统
【客户满意度提升】:BSC在服务管理中的应用之道
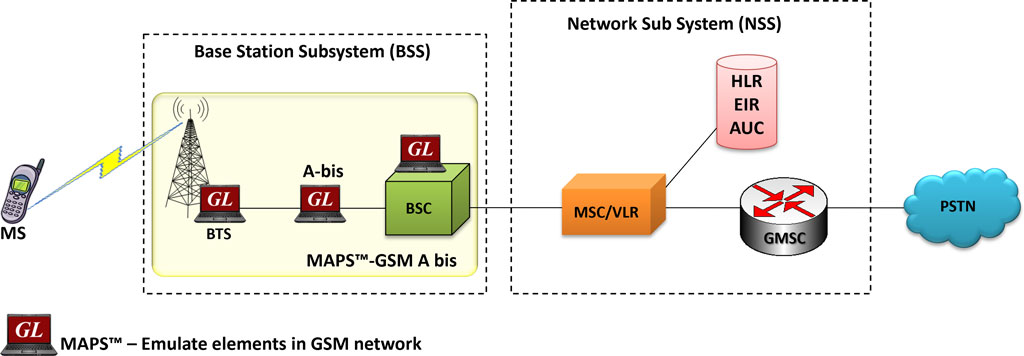
# 摘要
平衡计分卡(BSC)是一种综合绩效管理工具,已被广泛应用于服务管理领域以衡量和提升组织绩效。本文首先概述了BSC的理论基础,包括其核心理念、发展历史以及在服务管理中的应用模型。随后,文章深入探讨了BSC在实践应用中的策略制定、服务流程优化以及促进团队协作和服务创新的重要性。通过对行业案例的分析,本文还评估了BSC在提升客户满意度方面的作用,并提出了面对挑战的应对策略。最后,文章综合评价了BSC的优势和局限性,为企业如何有效整合BSC与服
【SR-2000系列扫码枪性能提升秘籍】:软件更新与硬件升级的最佳实践

# 摘要
本文对SR-2000系列扫码枪的性能提升进行了全面研究,涵盖软件更新与硬件升级的理论和实践。首先介绍了SR-2000系列扫码枪的基础知识,然后深入探讨了软件更新的理论基础、实际操作流程以及效果评估。接着,对硬件升级的必要性、实施步骤和后续维护进行了分析。通过案例分析,本文展示了软件更新和硬件升级对性能的具体影响,并讨论了综合性能评估方法和管理策略。最后,展望了SR-2000系列扫码枪的未来,强调了行业发展趋势、技术革新
鼎甲迪备操作员故障排除速成课:立即解决这8个常见问题
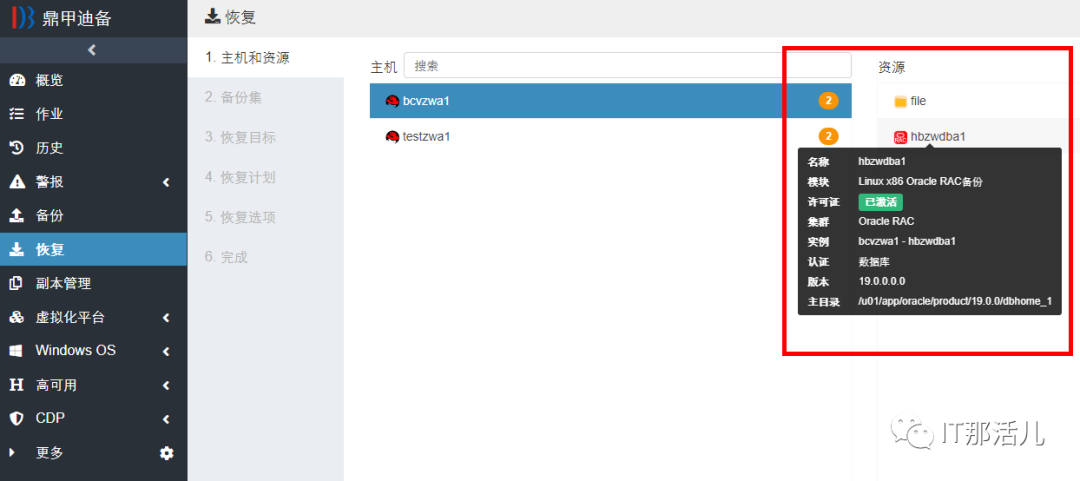
# 摘要
本文全面介绍了鼎甲迪备操作员在故障排除中的综合方法和实践。首先概述了故障排除的基础理论与方法,包括故障诊断的基本原理和处理流程,随后深入探讨了最佳实践中的预防措施和快速响应策略。文章通过具体案例分析,详细解读了系统启动失败、数据恢复、网络连接不稳定等常见问题的诊断与解决方法。进一步,本文介绍了使用专业工具进行故障诊断的
实时系统设计要点:确保控制系统的响应性和稳定性的10大技巧

# 摘要
实时系统设计是确保系统能够及时响应外部事件的重要领域。本文首先概述了实时系统的基本理论,包括系统的分类、特性、实时调度理论基础和资源管理策略。随后,深入探讨了实时系统设计的关键实践,涵盖了架构设计、实时操作系统的应用以及数据通信与同步问题。本文还着重分析了提升实时系统稳定性和可靠性的技术和方法,如硬件冗余、软件故障处理和测试验证。最后,展望了并发控制和新兴技术对实时系统
【IEEE 24 RTS系统数据结构揭秘】:掌握实时数据处理的10大关键策略
# 摘要
本文详细介绍了IEEE 24 RTS系统的关键概念、实时数据处理的基础知识、实时数据结构的实现方法,以及实时数据处理中的关键技术
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )