优化Selenium脚本的调试与错误处理
发布时间: 2024-01-25 01:09:36 阅读量: 44 订阅数: 32 

selenium+python 对输入框的输入处理方法
# 1. Selenium脚本调试及错误定位
调试和错误定位是优化Selenium脚本的关键步骤之一。在调试过程中,我们需要定位常见的Selenium脚本错误,并使用断点和日志等工具进行调试。
### 1.1 定位常见的Selenium脚本错误
在Selenium脚本编写和执行过程中,常见的错误包括元素定位错误、页面加载慢或超时、未处理的弹窗等。了解并定位这些错误是调试过程的第一步。
### 1.2 使用断点和日志进行调试
在调试过程中,我们可以使用断点来暂停脚本的执行,以便观察代码的执行情况和变量的取值。通过观察断点处的执行情况,我们可以发现潜在的错误或逻辑问题。
另外,使用日志记录工具可以帮助我们定位错误。通过在代码中添加日志输出,我们可以记录脚本执行过程中的关键信息,帮助我们分析和调试错误。
### 1.3 借助浏览器开发者工具进行调试
浏览器开发者工具是Selenium脚本调试的有力工具之一。通过浏览器开发者工具,我们可以查看页面的HTML结构、CSS样式、JavaScript错误等信息,辅助我们定位问题。
在浏览器开发者工具中,我们可以使用元素检查器定位页面上的元素,并查看其定位方式和属性值是否正确。我们还可以在控制台中输出日志消息,帮助我们调试脚本的执行过程。
> 通过合理使用断点、日志和浏览器开发者工具进行调试,可以快速定位并解决Selenium脚本中的错误,提高脚本的可靠性和效率。在接下来的章节中,我们还将介绍其他优化方法和技巧,帮助您进一步提升脚本的质量和稳定性。
# 2. 日志记录与错误监控
在编写和调试Selenium脚本时,日志记录和错误监控是非常重要的步骤。通过正确设置日志记录的级别和格式,并使用专业的日志记录工具,可以帮助我们更好地监控脚本的执行过程,并及时发现和解决错误。
### 2.1 设置日志记录的级别和格式
在Selenium中,我们可以通过设置日志记录的级别和格式来控制日志的生成和展示。一般常用的日志级别有:DEBUG、INFO、WARNING、ERROR、CRITICAL。根据需要,我们可以选择合适的级别来记录日志。
```python
import logging
# 设置日志记录的级别
logging.basicConfig(level=logging.INFO)
# 添加自定义的日志记录器
logger = logging.getLogger(__name__)
# 设置日志的格式
formatter = logging.Formatter('[%(levelname)s] %(asctime)s - %(message)s')
handler = logging.StreamHandler()
handler.setFormatter(formatter)
logger.addHandler(handler)
# 使用日志记录器输出日志
logger.info("This is an information log.")
logger.warning("This is a warning log.")
logger.error("This is an error log.")
```
上述代码中,我们首先设置了日志记录的级别为INFO,然后创建了一个自定义的日志记录器logger,并设置了日志的格式为"[级别] 时间 - 消息"。接下来,通过调用logger的方法,我们可以记录不同级别的日志信息。
### 2.2 使用日志记录工具监控脚本执行过程中的错误
当我们运行Selenium脚本时,如果发生了错误,我们可以通过日志记录工具来监控并记录这些错误信息。常见的日志记录工具有Log4j、Log4Net等,具体的配置和使用方法可以根据实际情况选择和设置。
下面是一个使用Log4j进行日志记录的示例:
```java
import org.apache.log4j.Logger;
public class SeleniumTest {
private static final Logger logger = Logger.getLogger(SeleniumTest.class);
public static void main(String[] args) {
logger.info("This is an information log.");
logger.warn("This is a warning log.");
logger.error("This is an error log.");
}
}
```
上述示例代码中,我们首先导入了Log4j的Logger类,然后创建了一个名为logger的静态对象,并使用Logger.getLogger方法来获取Logger实例。接下来,通过调用logger的方法,我们可以记录不同级别的日志信息。
### 2.3 解读日志中的错误信息
当Selenium脚本发生错误时,我们可以通过查看日志中的错误信息来定位和解决问题。通常,具体的错误信息会在日志中以一定的格式进行记录,包括错误的类型、发生错误的位置以及相关的上下文信息。
示例如下:
```
[ERROR] 2021-09-20 10:30:45 - Element not found: #id-no-exist
```
上述错误日志中,"[ERROR]"表示错误的级别,"2021-09-20 10:30:45"表示错误发生的时间,"Element not found: #id-no-exist"表示错误的具体信息,即元素未找到,定位方式为"#id-no-exist"。
通过解读日志中的错误信息,我们可以快速定位脚本中的问题,并针对性地进行修复和优化。
总结:
在优化Selenium脚本的调试与错误处理过程中,日志记录和错误监控是非常重要的环节。通过合理设置日志记录的级别和格式,并使用专业的日志记录工具,我们可以更好地监控脚本的执行过程,并及时发现和解决错误。同时,通过解读日志中的错误信息,我们可以快速定位脚本中的问题,并进行针对性的修复和优化。
# 3. 优化定位元素操作
Selenium脚本执行过程中,经常涉及到对页面元素的定位操作,正确的定位策略对脚本的稳定性和性能都至关重要。本章节将介绍如何优化定位元素操作,以提高脚本的稳定性和执行效率。
#### 3.1 选择合适的定位策略
选择合适的定位策略是保证脚本稳定性的重要一环。在选择元素定位方式时,应优先考虑使用ID或class等唯一标识的属性进行定位,避免使用过于通用或易变的属性,如XPath中的绝对路径定位。
```python
# 举例:使用ID进行定位
element = driver.find_element_by_id('unique_id')
```
#### 3.2 避免使用过于具体的定位方式
过于具体的定位方式

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏将带领读者全面了解Selenium工具在Web自动化测试中的应用。从入门指南与基本概念开始,学习如何使用Selenium进行Web元素的定位和操作,以及执行简单的浏览器操作。随后,专栏将介绍如何运用Selenium进行网页导航和页面间的操作,处理多窗口和弹窗,并探讨处理框架和嵌套页面的技巧。进而,读者将学习如何利用Selenium进行网页截图和屏幕录制,以及使用Selenium Grid进行分布式测试。此外,专栏还将讨论针对移动应用的Selenium技术,演示与实践数据驱动测试,并探索性能和负载测试。最后,专栏还将介绍如何与持续集成和持续交付工具集成使用Selenium,并深入探讨Selenium与API测试的综合应用。此外,专栏还会讨论Selenium与BDD(行为驱动开发)的场景与实践,以及优化脚本的调试与错误处理技巧。通过本专栏,读者将能够构建可维护和可扩展的Selenium测试套件。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘雷达信号处理:从脉冲到频谱的魔法转换
# 摘要
本文对雷达信号处理技术进行了全面概述,从基础理论到实际应用,再到高级实践及未来展望进行了深入探讨。首先介绍了雷达信号的基本概念、脉冲编码以及时间域分析,然后深入研究了频谱分析在雷达信号处理中的基础理论、实际应用和高级技术。在高级实践方面,本文探讨了雷达信号的采集、预处理、数字化处理以及模拟与仿真的相关技术。最后,文章展望了人工智能、新兴技术对雷达信号处理带来的影响,以及雷达系统未来的发展趋势。本论文旨在为雷
【ThinkPad T480s电路原理图深度解读】:成为硬件维修专家的必备指南
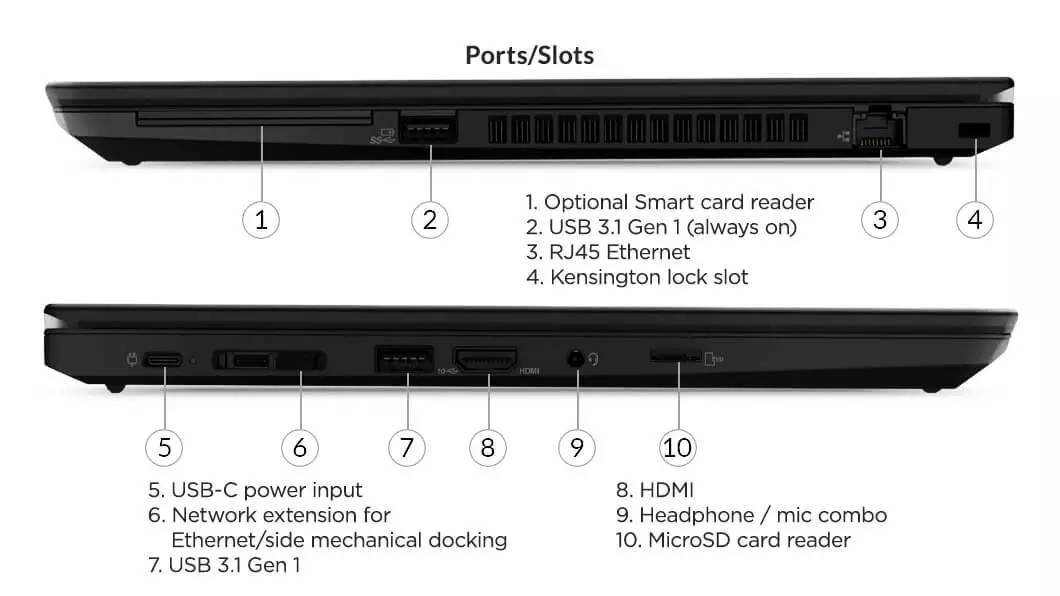
# 摘要
本文对ThinkPad T480s的硬件组成和维修技术进行了全面的分析和介绍。首先,概述了ThinkPad T480s的硬件结构,重点讲解了电路原理图的重要性及其在硬件维修中的应用。随后,详细探讨了电源系统的工作原理,主板电路的逻辑构成,以及显示系统硬件的组成和故障诊断。文章最后针对高级维修技术与工具的应用进行了深入讨论,包括
【移动行业处理器接口核心攻略】:MIPI协议全景透视
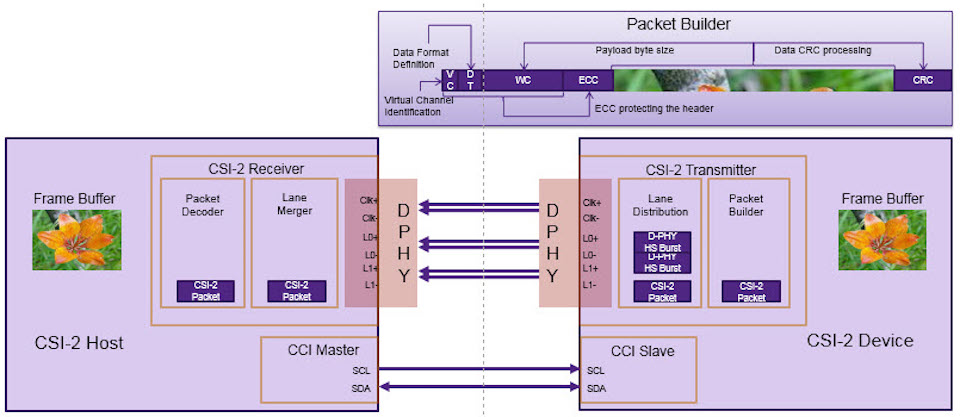
# 摘要
本文详细介绍了移动行业处理器接口(MIPI)协议的核心价值和技术原理,强调了其在移动设备中应用的重要性和优势。通过对MIPI协议标准架构、技术特点以及兼容性与演进的深入分析,本文展示了MIPI在相机、显示技术以及无线通信等方面的实用性和技术进步。此外,本文还探讨了MIPI协议的测试与调试方法,以及在智能穿戴设备、虚拟现实和增强
【编译器调优攻略】:深入了解STM32工程的编译优化技巧

# 摘要
本文深入探讨了STM32工程优化的各个方面,从编译器调优的理论基础到具体的编译器优化选项,再到STM32平台的特定优化。首先概述了编译器调优和STM32工程优化的理论基础,然后深入到代码层面的优化策略,包括高效编程实践、数据存取优化和预处理器的巧妙使用。接着,文章分析了编译器优化选项的重要性,包括编译器级别和链接器选项的影响,以及如何在构建系统中集成这些优化。最后,文章详
29500-2标准成功案例:组织合规性实践剖析

# 摘要
本文全面阐述了29500-2标准的内涵、合规性概念及其在组织内部策略构建中的应用。文章首先介绍了29500-2标准的框架和实施原则,随后探讨了
S7-1200_S7-1500故障排除宝典:维护与常见问题的解决方案

# 摘要
本文综述了S7-1200/S7-1500 PLC的基础知识和故障诊断技术。首先介绍PLC的硬件结构和功能,重点在于控制器核心组件以及I/O模块和接口类型。接着分析电源和接地问题,探讨其故障原因及解决方案。本文详细讨论了连接与接线故障的诊断方法和常见错误。在软件故障诊断方面,强调了程序错误排查、系统与网络故障处理以及数
无人机精准控制:ICM-42607在定位与姿态调整中的应用指南
# 摘要
无人机精准控制对于飞行安全与任务执行至关重要,但面临诸多挑战。本文首先分析了ICM-42607传感器的技术特点,探讨了其在无人机控制系统中的集成与通信协议。随后,本文深入阐述了定位与姿态调整的理论基础,包括无人机定位技术原理和姿态估计算法。在此基础上,文章详细讨论了ICM-42607在无人机定位与姿态调整中的实际应用,并通
易语言与FPDF库:错误处理与异常管理的黄金法则

# 摘要
易语言作为一门简化的编程语言,其与FPDF库结合使用时,错误处理变得尤为重要。本文旨在深入探讨易语言与FPDF库的错误处理机制,从基础知识、理论与实践,到高级技术、异常管理策略,再到实战演练与未来展望。文章详细介绍了错误和异常的概念、重要性及处理方法,并结合FPDF库的特点,讨论了设计时与运行时的错误类型、自定义与集成第三方的异常处理工具,以及面向对象中的错误处理。此外,本文还强
Linux下EtherCAT主站igh程序同步机制:实现与优化指南
# 摘要
本文首先概述了EtherCAT技术及其同步机制的基本概念,随后详细介绍了在Linux环境下开发EtherCAT主站程序的基础知识,包括协议栈架构和同步机制的角色,以及Linux环境下的实时性强化和软件工具链安装。在此基础上,探讨了同步机制在实际应用中的实现、同步误差的控制与测量,以及同步优化策略。此外,本文还讨论了多任务同步的高级应用、基于时间戳的同步实现、
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )