【销售决策的数学引擎】:糖果配比案例分析与策略制定
发布时间: 2024-12-26 04:22:30 阅读量: 4 订阅数: 7 

# 摘要
本文综合分析了销售决策中的数学模型应用、糖果配比案例分析,以及销售策略的数学优化。首先,概述了销售决策过程,随后详细探讨了数学模型在销售预测、定价策略和库存管理中的实际应用。通过具体案例,本文说明了糖果配比设计的重要性和实施效果评估,以及如何通过数据分析和策略制定来优化销售结果。最后,本文展望了未来销售策略的发展趋势,包括人工智能、大数据以及可持续发展和跨界融合的影响。
# 关键字
销售决策;数学模型;库存管理;策略优化;人工智能;可持续发展
参考资源链接:[数学建模——糖果配比销售](https://wenku.csdn.net/doc/64ab9d6c2d07955edb5e2b56?spm=1055.2635.3001.10343)
# 1. 销售决策概述
销售决策是企业运营中的一项核心活动,其目的是为了在不断变化的市场环境中保持竞争力,实现产品或服务的可持续销售,并最大化利润。销售决策通常涵盖对市场趋势的分析、产品定价、销售渠道的选择、促销活动的策划以及客户关系管理等多个方面。良好的销售决策依赖于准确的市场信息、对消费者行为的深刻理解以及对竞争环境的敏感洞察。销售决策的质量直接影响到企业的经济效益和品牌形象,因此,对于决策者来说,制定科学合理的销售策略是至关重要的任务。
# 2. 数学模型在销售中的应用
在现代商业环境中,数学模型已经成为销售策略制定的重要工具。它们通过数据分析和预测帮助销售团队做出更加客观和精准的决策。本章节将深入探讨数学模型在销售预测、定价策略以及库存管理等方面的具体应用。
### 2.1 销售预测模型
#### 2.1.1 时间序列分析
时间序列分析是一种统计方法,用于分析按照时间顺序排列的数据点,以识别其中的模式、周期性和趋势。在销售预测中,时间序列模型可以基于历史销售数据预测未来的销售量。
```r
# 示例代码:使用R语言对销售数据进行时间序列分析
library(forecast)
sales_data <- ts(c(120, 132, 101, 134, 90, 230), frequency = 12, start = c(2020, 1))
fit <- auto.arima(sales_data)
forecast_result <- forecast(fit, h=3)
```
在上述示例中,我们使用R语言中的forecast包对一组虚构的月销售数据进行时间序列分析。`auto.arima`函数自动确定最佳的时间序列模型并拟合数据。`forecast`函数用于生成未来3个月的销售预测。参数说明:`ts`用于创建时间序列对象,`frequency`指定了数据的频率(这里是月度),`start`定义了时间序列的起始点。
#### 2.1.2 回归分析模型
回归分析模型通过建立一个或多个自变量和因变量之间的关系,来预测未来的销售趋势。这种模型特别适用于评估价格、促销活动、季节性因素等变量对销售量的影响。
```python
# 示例代码:使用Python进行回归分析
import statsmodels.api as sm
import pandas as pd
# 假设df是一个包含销售数据的pandas DataFrame
# 'Sales'是因变量,'Price'和'Promotion'是自变量
X = df[['Price', 'Promotion']]
y = df['Sales']
X = sm.add_constant(X) # 添加常数项
model = sm.OLS(y, X).fit()
print(model.summary())
```
在上述Python代码中,我们使用statsmodels库对销售数据进行线性回归分析。`sm.add_constant`函数为回归模型添加常数项,`sm.OLS`函数拟合普通最小二乘法模型,并通过`fit`方法生成预测结果。`model.summary()`则提供了详细的回归分析结果。
#### 2.1.3 机器学习预测模型
随着机器学习技术的发展,利用数据挖掘和预测模型来预测销售趋势变得越来越普遍。这些模型能够处理大量数据并识别复杂的模式,从而提供比传统统计方法更准确的预测。
```python
# 示例代码:使用Python中的随机森林模型进行销售预测
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 假设X和y是特征和目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
mse = mean_squared_error(y_test, predictions)
```
在这段代码中,我们利用scikit-learn库来训练一个随机森林回归模型。`train_test_split`用于将数据分为训练集和测试集,`RandomForestRegressor`则创建随机森林回归模型并进行训练,`predict`方法用于生成预测值,`mean_squared_error`用于计算预测的均方误差。
### 2.2 定价策略模型
#### 2.2.1 成本加成定价
成本加成定价是一种常见的定价策略,即在商品的成本上加上一定比例的利润来设定最终的销售价格。为了使价格更具竞争力,企业需要准确计算成本并合理设定利润率。
```markdown
| 产品 | 成本 | 利润率 | 定价 |
|------|------|--------|------|
| A | $10 | 30% | $13 |
| B | $20 | 20% | $24 |
```
在上表中,我们列出了两种产品A和B的成本、利润率和最终定价。通过这种方式,企业可以为不同的产品制定合适的销售价格。
#### 2.2.2 市场导向定价
市场导向定价考虑的是竞争对手的定价策略和市场需求的变化。企业通过市场调研来了解顾客对价格的敏感度和可接受范围,据此调整价格。
```mermaid
graph LR
A[收集市场信息] --> B[分析需求弹性]
B --> C[确定定价策略]
C --> D[实施定价]
D --> E[监控市场反应]
E --> A
```
在mermaid流程图中,我们展示了市场导向定价策略的实施流程。企业首先收集市场信息,然后分析需求弹性以确定合适的定价策略。实施定价后,企业需要不断监控市场的反应,并据此调整策略。
#### 2.2.3 竞争导向定价
竞争导向定价则是基于竞争对手的价格来设定自己的价格。企业分析竞争对手的定价,然后根据自身成本和市场定位来制定价格策略。
### 2.3 库存管理模型
#### 2.3.1 经济订货量模型
经济订货量(EOQ)模型是一种用于确定最经济订货量的库存管理方法。该模型可以帮助企业减少库存成本,同时确保不会因缺货而损失销售机会。
```markdown
| 参数 | 符号 | 值 |
|---------------|----------|------|
| 每次订货成本 | S | $100 |
| 年需求量 | D | 1000 |
| 单位商品成本 | C | $10 |
| 持有成本率 | H | 25% |
```
| 订货量 (Q) | 订货次数 (D/Q) | 总订货成本 (S x D/Q) | 总持有成本 (Q/2 x H x C) | 总成本 |
|------------|----------------|----------------------|----------------------------|--------|
| 100 | 10 | $1,000 | $125 | $1,125 |
| 150 | 6.67 | $666.67 | $187.50 | $854.17 |
| 200 | 5 | $500 | $250 | $750 |
在上表中,我们计算了不同的订货量对应的总订货成本、总持有成本和总成本。通过EOQ模型,企业可以确定一个最佳订货量,以最小化总成本。
#### 2.3.2 需求波动与库存控制
需求波动是指顾客购买行为的不确定性,这种波动对库存管理提出了挑战。企业需要通过动态调整库存水平来应对需求的变化。
```python
import numpy as np
# 假设需求数据是随机波动的
demand = np.random.normal(50, 10, size=12)
# 计算需求的移动平均值,用于预测未来的需求波动
demand_moving_avg = np.convolve(demand, np.ones(3)/3, 'valid')
# 基于移动平均值确定安全库存水平
safety_stock = 1.65 * np.std(demand_moving_avg)
```
在这段代码中,我们首先使用numpy库生成一组模拟的需求数据,然后计算需求的3个月移动平均值,并基于该移动平均值来确定安全库存水平。参数`1.65`是安全库存的常用系数,用于计算基于标准差的库存水平。
#### 2.3.3 多级库存系统优化
多级库存系统指的是由多个环节组成的库存系统,例如供应商、制造商、分销商和零售商。在这种系统中,库存管理的优化需要考虑整个供应链的协同效应。
```python
# 假设我们有一个包含多个库存环节的DataFrame
inventory_levels = pd.DataFrame({
'Supplier': [100, 110, 105],
'Manufacturer': [80, 70, 75],
'Distributor': [60, 65, 62],
'Retailer': [50, 45, 55]
}, index=['January', 'February', 'March'])
# 计算每月的总库存水平
total_inventory = inventory_levels.sum(axis=1)
# 分析库存水平的变化并优化
# 此处可以添加优化逻辑和算法,例如使用线性规划
```
在这个示例中,我们创建了一个包含不同库存环节的DataFrame,并计算了每月的总库存水平。接下来,可以基于这些数据进行更深入的分析,例如使用线性规划方法来优化库存分配。
以上就是第二章的详细内容,介绍了销售预测模型、定价策略模型以及库存管理模型中的应用,并通过代码块和流程图的方式进行了具体阐述。这些模型对于销售策略制定中的决策过程提供了科学的支持。在下一章,我们

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“数学建模——糖果配比销售”为主题,深入探讨了数学建模在糖果行业中的应用。专栏文章涵盖了广泛的主题,包括:
* 销售策略优化:利用模型挖掘市场潜力,制定最佳销售策略。
* 糖果配比优化:揭示需求与实施步骤,建立黄金配比法则。
* 模型驱动的销售革新:通过数学模型实现销售流程优化。
* 精准销售策略:深入剖析糖果配比预测模型,打造精准销售策略。
* 库存管理优化:提升糖果销售与利润,掌握库存管理的数学艺术。
* 市场趋势揭示:解读销售数据模型,把握糖果市场动向。
* 销售额提升:探索数学建模在糖果销售中的应用,提升销售额。
* 竞争力增强:解析糖果配比销售建模实践,提升行业竞争力。
* 未来预测:精通数学建模,抢占糖果市场先机。
本专栏旨在为糖果行业从业者提供实用且可操作的见解,帮助他们利用数学建模优化销售策略,提升市场份额,并为未来做好准备。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【掌握UML用例图】:网上购物场景实战分析与最佳实践

# 摘要
统一建模语言(UML)用例图是软件工程中用于需求分析和系统设计的关键工具。本文从基础知识讲起,深入探讨了UML用例图在不同场景下的应用,并通过网上购物场景的实例,提供实战绘制技巧和最佳实践。文中对如何识别参与者、定义用例、以及绘制用例图的布局规则进行了系统化阐述,并指出了常见错误及修正方法。
电源管理对D类放大器影响:仿真案例精讲
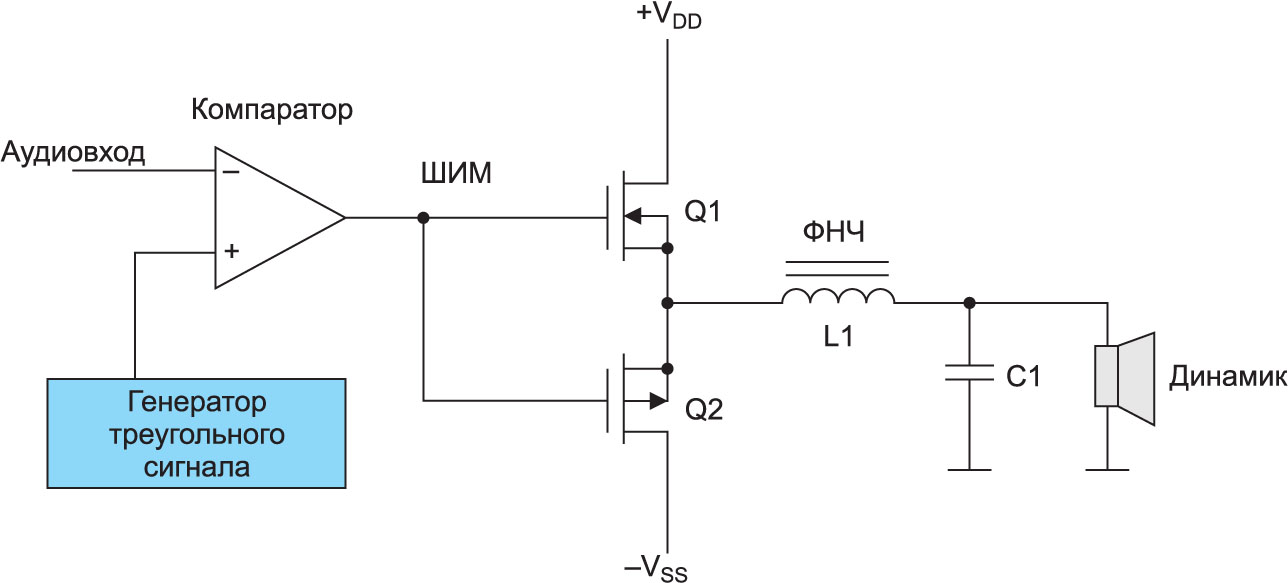
# 摘要
电源管理是确保电子系统高效稳定运行的关键环节,尤其在使用D类放大器时,其重要性更为凸显。本文首先概述了电源管理和D类放大器的基础理论,重点介绍了电源管理的重要性、D类放大器的工作原理及其效率优势,以及电源噪声对D类放大器性能的影响。随后,文章通过仿真实践展示了如何搭建仿真环境、分析电源噪声,并对D类放大器进行仿真优化。通过实例研究,本文探讨了电源管理在提升D类放大器性能方面的应用,并展望了未来新
【DirectX Repair工具终极指南】:掌握最新增强版使用技巧,修复运行库故障

# 摘要
本文对DirectX技术进行了全面的概述,并详细介绍了DirectX Repair工具的安装、界面解析以及故障诊断与修复技巧。通过对DirectX故障类型的分类和诊断流程的阐述,提供了常见故障的修复方法和对比分析。文章进一步探讨了工具的进阶使用,包括高级诊断工具的应用、定制修复选项和复杂故障案例研究。同时,本文还涉及到DirectX Repair工具的
全面解析:二级齿轮减速器设计的10大关键要点
# 摘要
本文全面阐述了二级齿轮减速器的设计与分析,从基础理论、设计要点到结构设计及实践应用案例进行了详细探讨。首先介绍了齿轮传动的原理、参数计算、材料选择和热处理工艺。接着,深入探讨了减速比的确定、齿轮精度、轴承和轴的设计,以及箱体设计、传动系统布局和密封润滑系统设计的关键点。文章还包含了通过静力学、动力学仿真和疲劳可靠性分析来确保设计的可靠性和性能。最后,通过工业应用案例分析和维护故障诊断,提出了二级齿轮减速器在实际应用中的表现和改进措施。本文旨在为相关领域工程师提供详尽的设计参考和实践指导。
# 关键字
齿轮减速器;传动原理;设计分析;结构设计;仿真分析;可靠性评估;工业应用案例
参
帧间最小间隔优化全攻略:网络工程师的实践秘籍

# 摘要
帧间最小间隔作为网络通信中的重要参数,对网络性能与稳定性起着关键作用。本文首先概述了帧间间隔的概念与重要性,随后探讨了其理论基础和现行标准,分析了网络拥塞与帧间间隔的关系,以及如何进行有效的调整策略。在实践章节中,本文详述了网络设备的帧间间隔设置方法及其对性能的影响,并分享了实时监控与动态调整的策略。通过案例分析,本文还讨论了帧间间隔优化在企业级网络中的实际应用和效果评估。最后,本文展望了帧间间隔优化的高级应
5G通信技术与叠层封装技术:揭秘最新研发趋势及行业地位

# 摘要
本文旨在探讨5G通信技术与叠层封装技术的发展及其在现代电子制造行业中的应用。首先概述了5G通信技术和叠层封装技术的基本概念及其在电子行业中的重要性。接着深入分析了5G通信技术的核心原理、实践应用案例以及面临的挑战和发展趋势。在叠层封装技术方面,本文论述了其理论基础、在半导体领域的应用以及研发的新趋势。最后,文章着重讨论了5G与叠层封装技术如何融合发展,以及它们共同对未来电子制造行业的
【Cadence设计工具箱】:符号与组件管理,打造定制化电路库
# 摘要
本文系统地介绍了Cadence设计工具箱的应用,从符号管理的基础技巧到高级技术,再到组件管理策略与实践,深入探讨了如何高效构建和维护定制化电路库。文中详细阐释了符号与组件的创建、编辑、分类、重用等关键环节,并提出了自动化设计流程的优化方案。此外,本文通过案例研究,展示了从项目需求分析到最终测试验证的整个过程,并对设计工具箱的未来发展趋势进行了展望,特别强调了集成化、兼容性以及用户体
TMS320F280系列电源管理设计:确保系统稳定运行的关键——电源管理必修课

# 摘要
本论文深入探讨了TMS320F280系列在电源管理方面的技术细节和实施策略。首先,概述了电源管理的基本理论及其重要性,接着详细分析了电源管理相关元件以及国际标准。在实践部分,文章介绍了TMS320F280系列电源管理电路设计的各个
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )