VMware HA故障切换优化:关键因素,全面提升
发布时间: 2024-12-10 04:59:18 阅读量: 2 订阅数: 15 

VMware-HA-故障切换不成功的原因
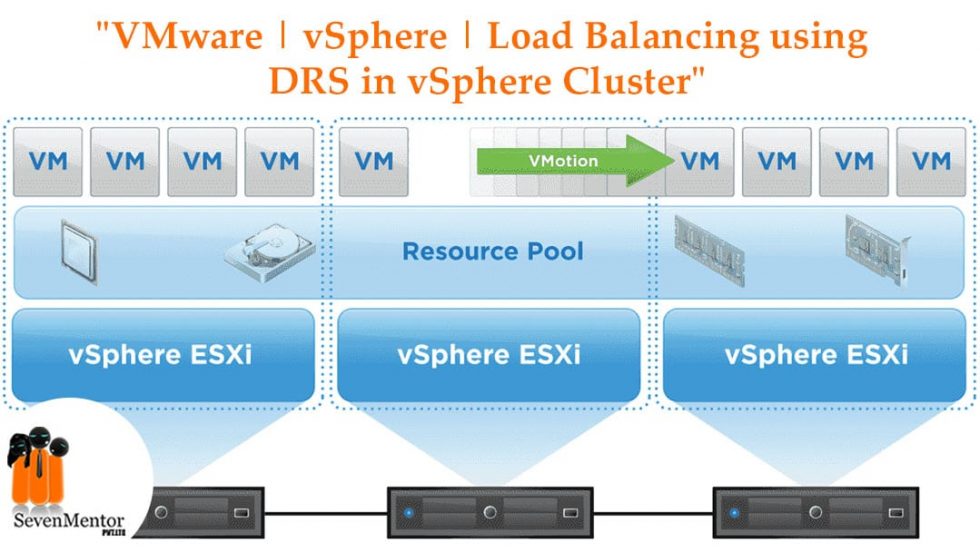
# 1. VMware HA基础及故障切换概述
在虚拟化技术广泛应用的今天,VMware HA(High Availability,高可用性)成为了保障关键业务连续性的重要解决方案。本章将带您进入VMware HA的世界,从基础概念讲起,到故障切换的过程及作用,帮助IT从业者构建高稳定性的虚拟环境。
## 1.1 HA的基本概念
HA是一种提高系统可用性和容错性的方法,它通过冗余手段来减少停机时间,确保在某个组件失效时能够快速切换到备份组件,维持业务连续性。
## 1.2 故障切换的重要性
在云计算环境中,故障切换是维持服务稳定性的关键机制。当主机或网络发生故障时,HA能够快速地将虚拟机迁移到健康的主机上,从而减少系统的整体宕机时间。
## 1.3 故障切换的工作原理
故障切换涉及多个阶段,包括故障的检测、虚拟机的迁移决策、以及迁移过程的执行。这一过程需要精心设计以保证快速且无缝的切换,以避免数据丢失或服务中断。
```markdown
- 本章小结:通过本章内容,读者将对VMware HA有一个整体的认识,并理解故障切换的基本概念及其在虚拟环境中的重要性。下一章将深入探讨VMware HA的关键配置和组件。
```
# 2. VMware HA的关键配置和组件
## 2.1 VMware HA的集群设置
### 2.1.1 集群资源需求分析
在虚拟化环境中,确保高可用性(HA)的关键之一是集群资源的合理配置。集群资源需求分析是一个复杂的过程,它涉及多个方面的考量。
首先,计算资源需求包括CPU和内存。虚拟机在主机间迁移时,计算资源必须充足,以确保最小化对服务的影响。CPU资源应考虑虚拟机的峰值工作负载,而内存则应预留足够的空间以支持虚拟机内存的快速增长。
其次,存储资源也是必须关注的领域。存储的读写速度直接影响到数据服务的连续性,因此要选择性能稳定、响应速度快的存储设备。此外,还应考虑到在主机故障时,数据能够在另一台主机上迅速可用。
在需求分析的过程中,不仅要考虑当前的业务需求,还要预见未来可能的扩展。这包括虚拟机数量的增加,以及业务负载的变化。通过模拟不同负载情况下的资源使用,可以在实际部署前评估并调整资源分配。
### 2.1.2 集群主机配置和要求
集群主机配置应满足特定的硬件标准和软件配置,以确保HA集群的稳定性。硬件方面,每台主机至少应有两块网卡,一块用于管理通信,另一块用于心跳信号和数据同步。同时,主机应该有足够数量的核心和内存,以支持在其上运行的虚拟机。
软件配置同样重要。VMware HA集群要求ESXi主机运行特定版本的vSphere软件,以确保集群通信、故障检测和恢复功能的兼容性。此外,主机还应配置成相同的网络设置,如子网、VLAN和DNS设置等,来保证主机间通信不受网络配置差异的影响。
每台主机还必须设置为HA集群的一部分,并且所有的主机都应有相同的角色配置,如主节点和辅助节点。这些设置确保在主机间进行故障切换时,虚拟机可以在任何主机上无缝启动。
在配置集群时,还需要考虑共享存储的访问权限。所有集群主机都必须能够访问并写入共享存储,以便在主机故障时进行数据恢复。
## 2.2 VMware HA的故障检测机制
### 2.2.1 主机故障检测策略
VMware HA能够通过故障检测机制及时识别并响应主机故障。故障检测策略包括心跳信号和资源监测两部分。心跳信号是集群内部通信的一部分,每台主机都会定期发送心跳信号以表明自己的健康状态。如果主机停止发送心跳信号,HA会认为该主机可能已经失败。
同时,HA会持续监测主机的资源使用情况,包括CPU、内存和存储I/O等。如果监测到的资源使用量超过设定的阈值,HA也会将其视为故障的迹象。这些阈值可以预先设定,以适应不同的业务需求和资源限制。
在主机故障的情况下,HA会尝试在其他可用主机上重新启动故障主机上的虚拟机,以减少业务中断时间。这种故障检测机制保证了高可用性集群能够快速响应主机级故障。
### 2.2.2 网络故障检测机制
除了主机故障外,网络故障也是需要重点考虑的。VMware HA通过监控网络连接的质量来判断网络故障。例如,VMware HA可以配置为检测网络的连通性,如果主机无法访问网络上的特定地址或端口,HA会将此情况视为网络故障的信号。
在检测到网络故障后,HA会采取预先定义的恢复措施。这些措施可能包括将受影响的虚拟机迁移到网络正常的主机上,或者在必要时重新配置网络连接。这种网络故障检测机制有助于保证网络层面的高可用性。
## 2.3 VMware HA的故障响应和切换过程
### 2.3.1 自动故障切换机制
VMware HA提供的自动故障切换机制对于保障关键业务的连续性至关重要。当集群中的某台主机出现故障时,故障切换流程自动启动。首先,集群会立即触发预定义的虚拟机重启策略。如果在重启虚拟机后,故障主机仍然无法恢复,集群会尝试在其他主机上重新启动这些虚拟机。
自动故障切换确保了在主机硬件失败、软件崩溃或其他导致主机无法运行虚拟机的事件发生时,虚拟机能够在尽可能短的时间内重新启动,从而大大缩短业务中断时间。这一过程对于金融、医疗和电信等对可靠性要求极高的行业尤为关键。
### 2.3.2 手动故障切换选项
尽管自动故障切换是VMware HA的默认行为,但VMware也提供了手动故障切换的选项,以允许管理员在特定情况下进行干预。手动故障切换可以用于计划内的维护操作,或者在自动故障切换失败时尝试其他恢复方案。
管理员可以使用vSphere Web Client来执行手动故障切换操作。操作步骤包括选择受影响的虚拟机,然后选择手动故障切换选项,系统会提示选择新的主机来启动虚拟机。手动故障切换提供了灵活的故障恢复方法,但同时也增加了人为错误的风险,因此管理员应当谨慎

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《VMware的高可用性与负载均衡配置》专栏深入探讨了VMware虚拟化环境中的高可用性和负载均衡技术。专栏文章涵盖了VMware负载均衡的原理、实操技巧、HA与DRS的联合优化、FT故障转移的解析、DRS的高级配置、监控工具选型指南、高可用性和负载均衡的测试分析、自动负载均衡的实现、以及数据一致性保障策略。通过深入浅出的讲解和案例分析,专栏旨在帮助读者掌握VMware虚拟化环境的高可用性和负载均衡配置,从而提升虚拟化环境的稳定性、性能和可扩展性。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【解密ISO 11898-2】:7大案例揭示CAN总线技术的实际应用
参考资源链接:[ISO 11898-2中文版:道路车辆CAN高速物理层标准解析](https://wenku.csdn.net/doc/26ogdo5nba?spm=1055.2635.3001.10343)
# 1. CAN总线技术概述
## 1.1 CAN总线的起源与定义
控制器局域网络(CAN)总线是一种广泛应用于电子控制单元(ECU)之间的可靠通信协议。它最初由德国博世公司为汽车内部网络通信开发,以取
Max-Log-MAP与SOVA:Turbo码性能与应用的双重视角

参考资源链接:[ Turbo码译码算法详解:MAP、Max-Log-MAP、Log-MAP与SOVA](https://wenku.csdn.net/doc/67u
【STM32F407终极指南】:7大技巧带你从新手到实战专家
参考资源链接:[STM32F407 Cortex-M4 MCU 数据手册:高性能、低功耗特性](https://wenku.csdn.net/doc/64604c48543f8444888dcfb2?spm=1055.2635.3001.10343)
# 1. STM32F407概述和开发环境搭建
## 1.1 STM32F407简介
STM32F407是由STMicroelectronics(意法
电子称校准秘籍:掌握这3个艺术级技巧,确保精准无误
参考资源链接:[梅特勒-托利多电子称全面设置教程](https://wenku.csdn.net/doc/10hjvgjrbf?spm=1055.2635.3001.10343)
# 1. 电子称校准的基础知识
## 1.1 校准的重要性
校准是确保电子称量设备精确性和可靠性的关键步骤。在日常使用过程中,多种因素如温度变化、机械磨损等可能导致电子称的读数偏离真实值。定期进行校准可以保证测量结果的准确性,符合行业标准和法律法规的要求。
## 1.2 校准的定义和目的
电子称校准是指使用已知精度的标准砝码或其他校准工具,对照电子称的显示值进行比对和调整,以消除误差或偏差,保证称量结果的准确可靠
坐标系统的秘密:Tecplot从笛卡尔到极坐标的高级应用解析

参考资源链接:[Tecplot入门教程:数据可视化与图形处理](https://wenku.csdn.net/doc/3e4i6cw3r9?spm=1055.2635.3001.10343)
# 1. Tecplot软件概览及坐标系统基础
## 1.1 Tecplot软件的介绍
Tecplot是一款广泛应用于科学和工程领域的数据分析和可视化软件。它提供了丰富的坐
SINAMICS S120电源模块详解:正确安装与维护的黄金法则

参考资源链接:[西门子SINAMICS S120伺服系统调试指南](https://wenku.csdn.net/doc/64715846d12cbe7ec3ff8638?spm=1055.2635.3001.10343)
# 1. SINAMICS S120电源模块概述
SIN
动态规划在MATLAB中的实现:案例分析与实用技巧

参考资源链接:[最优化方法Matlab程序设计课后答案详解](https://wenku.csdn.net/doc/6472f573d12cbe
揭秘DCDC-Boost电路仿真:10个案例深度分析与性能优化策略
参考资源链接:[LTspice新手指南:DC/DC Boost电路仿真](https://wenku.csdn.net/doc/1ue4eodgd8?spm=1055.2635.3001.10343)
# 1. DCDC-Boost电路仿真基础
## 1.1 电路仿真概述
电路仿真技术是一种利用计算工具模拟电路行为的过程,它能够帮助工程师在实际搭建电路前预测电路的性能。在电力电子领域,DCDC-Boost电路作为提
SINAMICS G120 CU240B-2_CU240E-2应用技巧: 参数手册中的隐藏功能全面挖掘

参考资源链接:[SINAMICS G120 CU240B/CU240E变频器参数手册(2016版)](https://wenku.csdn.net/doc/64658f935928463033ceb8af?spm=1055.2635.3
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )