Hadoop入门及安装配置
发布时间: 2024-03-02 21:41:52 阅读量: 45 订阅数: 42 

Hadoop安装与配置
# 1. 简介
Hadoop是一个开源的分布式计算平台,主要用于存储和处理大规模数据。它基于Google的MapReduce论文和Google File System论文进行了实现,并且具有高可靠性、高扩展性和高效性的特点。在大数据领域,Hadoop已经成为一种标准的解决方案。
### 1.1 什么是Hadoop
Hadoop由Apache基金会开发,它包括一个分布式文件系统(HDFS)和一个用于分布式数据处理的编程模型——MapReduce。Hadoop的核心设计目标是在普通的硬件上创建可靠的、可扩展的性能。Hadoop具有高容错性的特点,能够自动处理节点故障。
### 1.2 Hadoop的作用和重要性
Hadoop的作用主要是存储和处理大规模数据,其重要性体现在以下几个方面:
- 大数据处理:Hadoop能够处理规模非常庞大的数据,为企业提供了快速、高效的数据处理能力。
- 分布式存储:Hadoop的分布式文件系统(HDFS)可以存储成百上千甚至更多的数据,并且具有高容错性。
- 平行计算:通过MapReduce,Hadoop可以在大规模数据集上进行高效的计算。
以上是关于Hadoop的简要介绍,接下来我们将详细介绍Hadoop的基础概念。
# 2. Hadoop基础概念
Hadoop作为一个大数据处理框架,其核心包括Hadoop分布式文件系统(HDFS)和MapReduce计算框架。在Hadoop集群中,所有数据都存储在HDFS中,而MapReduce则负责在数据节点上进行数据处理和计算。此外,Hadoop还使用YARN资源管理器来管理计算资源。
#### 2.1 分布式文件系统(HDFS)
HDFS是Hadoop的存储系统,具有高容错性和高吞吐量的特点。它将数据分布存储在集群中的多个节点上,同时提供了文件的高可靠性和高可用性。HDFS的架构包括一个NameNode和多个DataNode,NameNode负责管理文件系统的命名空间和存储元数据,而DataNode负责存储实际的数据块。
#### 2.2 MapReduce计算框架
MapReduce是Hadoop中用来进行大规模数据处理的计算模型和编程框架。它将数据处理过程分为两个阶段:Map阶段和Reduce阶段。在Map阶段,数据会根据键值对进行处理和排序;在Reduce阶段,经过Map阶段处理过的数据会被进一步处理和汇总。MapReduce框架通过并行处理来实现高效的数据处理能力。
#### 2.3 YARN资源管理器
YARN(Yet Another Resource Negotiator)是Hadoop 2.x引入的资源管理器,用于更好地支持Hadoop集群中的资源管理和作业调度。它将集群的资源管理和作业调度分离开,使得Hadoop集群能够运行更多类型的作业,并提供了更好的资源利用率。 YARN包括ResourceManager(集群上的资源管理器)和NodeManager(每个节点上的资源管理器)。
# 3. 安装Hadoop
在本章中,我们将介绍如何安装Hadoop,包括准备工作、下载Hadoop软件包以及配置Hadoop环境。
#### 3.1 准备工作
在安装Hadoop之前,需要进行一些准备工作,确保系统环境和软件版本符合Hadoop的要求。具体包括:
- 操作系统:Hadoop可以在多种操作系统上运行,包括Linux、Windows等。建议选择Linux系统,例如Ubuntu或CentOS。
- Java环境:Hadoop是基于Java开发的,所以需要安装Java环境。推荐安装JDK8或以上版本。
- 硬件要求:确保有足够的内存和存储空间。
#### 3.2 下载Hadoop软件包
接下来,我们需要从Hadoop官方网站下载最新版本的Hadoop软件包。可以访问[Hadoop官方网站](https://hadoop.apache.org/)下载稳定版本的Hadoop压缩包。
#### 3.3 配置Hadoop环境
下载完Hadoop软件包后,需要进行一些配置来使Hadoop在本地环境中正常运行。主要包括以下几个步骤:
- 解压缩Hadoop软件包:使用命令行或解压工具将下载的压缩包解压到指定目录。
- 配置环境变量:设置Hadoop的环境变量,包括JAVA_HOME、HADOOP_HOME等。
- 配置Hadoop文件:修改Hadoop配置文件,如core-site.xml、hdfs-site.xml等,指定Hadoop集群的一些配置信息。
以上是安装Hadoop的基本步骤,接下来我们将详细介绍如何配置Hadoop环境。
# 4. Hadoop集群配置
Hadoop的集群配置是使用Hadoop的重要部分,通过配置Hadoop集群,可以实现数据的分布式存储和计算任务的分布式处理。本章将介绍如何进行单节点和多节点Hadoop集群的配置。
#### 4.1 单节点Hadoop集群配置
在单节点Hadoop集群配置中,Hadoop的所有组件(包括HDFS、MapReduce和YARN)都将运行在同一台机器上。这种配置适合于开发和测试环境,以及小规模数据处理任务。
以下是单节点Hadoop集群配置的简要步骤:
1. 下载Hadoop软件包,并解压到指定目录。
2. 配置Hadoop环境变量,包括JAVA_HOME、HADOOP_HOME等。
3. 配置Hadoop的核心配置文件,如hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml等。
4. 格式化HDFS文件系统:执行命令 `hdfs namenode -format`。
5. 启动Hadoop集群:执行命令 `start-all.sh` 或分别启动HDFS和YARN组件。
#### 4.2 多节点Hadoop集群配置
在多节点Hadoop集群配置中,Hadoop的各个组件将分布式部署在多台机器上,通常包括主节点(NameNode、ResourceManager)、从节点(DataNode、NodeManager)以及辅助节点(SecondaryNameNode、JobHistoryServer)等。
多节点Hadoop集群配置的步骤如下:
1. 配置每台机器的环境变量和Hadoop软件包。
2. 在每台机器上设置Hadoop的配置文件,确保节点间能够相互通信和识别。
3. 配置主节点和从节点的角色,并启动HDFS和YARN组件。
在配置多节点Hadoop集群时,需要特别注意网络配置、节点间的SSH免密码登录、容错机制以及资源调度等问题。
通过以上步骤,可以成功搭建单节点和多节点Hadoop集群,实现数据存储和计算任务的分布式处理。
接下来,我们将深入了解Hadoop常用命令。
# 5. Hadoop常用命令
Hadoop作为一个分布式计算框架,提供了丰富的命令行工具,用于管理文件系统、执行MapReduce任务以及查看集群状态。本章将介绍一些常用的Hadoop命令及其用法。
#### 5.1 Hadoop文件系统操作命令
Hadoop提供了一系列命令用于管理HDFS文件系统,包括文件上传、下载、删除、查看文件内容等操作。以下是一些常用的Hadoop文件系统操作命令示例:
```bash
# 在本地文件系统中创建一个文本文件
echo "Hello, Hadoop!" > localfile.txt
# 将本地文件上传到HDFS
hadoop fs -put localfile.txt hdfs:///user/username/hdfsfile.txt
# 列出HDFS中指定目录下的文件
hadoop fs -ls hdfs:///user/username
# 从HDFS中下载文件到本地文件系统
hadoop fs -get hdfs:///user/username/hdfsfile.txt localfile_downloaded.txt
# 查看HDFS中文件的内容
hadoop fs -cat hdfs:///user/username/hdfsfile.txt
# 删除HDFS中的文件
hadoop fs -rm hdfs:///user/username/hdfsfile.txt
```
#### 5.2 MapReduce任务管理命令
在Hadoop中,我们可以使用命令管理MapReduce任务,如提交、查看任务状态、终止任务等。以下是一些常用的MapReduce任务管理命令示例:
```bash
# 提交一个MapReduce任务
hadoop jar WordCount.jar input_path output_path
# 查看正在运行的MapReduce任务列表
hadoop job -list
# 查看特定MapReduce任务的状态和进度
hadoop job -status job_id
# 终止一个正在运行的MapReduce任务
hadoop job -kill job_id
```
#### 5.3 Hadoop集群状态查看命令
除了管理文件系统和MapReduce任务,我们也需要查看Hadoop集群的状态信息,以便监控集群运行情况。以下是一些常用的Hadoop集群状态查看命令示例:
```bash
# 查看集群中活跃的节点列表
hadoop dfsadmin -report
# 查看Hadoop集群的整体健康状态
hadoop dfsadmin -printTopology
```
以上是Hadoop常用命令的简要介绍,通过这些命令,可以方便地管理Hadoop集群及其资源。接下来我们将通过实例演练来加深对这些命令的理解。
# 6. 实例演练
在本节中,我们将通过实例演示如何使用Hadoop进行实际任务处理,并进行任务分析与优化。
### 6.1 使用Hadoop处理WordCount示例
#### 场景说明
我们将使用Hadoop来处理一个经典的示例任务——WordCount,即统计一段文本中每个单词出现的次数。
#### 代码示例(Java)
```java
// WordCountMapper.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private final static LongWritable one = new LongWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String w : words) {
word.set(w);
context.write(word, one);
}
}
}
```
```java
// WordCountReducer.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
public void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
long sum = 0;
for (LongWritable val : values) {
sum += val.get();
}
context.write(key, new LongWritable(sum));
}
}
```
```java
// WordCountMain.java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCountMain.class);
job.setMapperClass(WordCountMapper.class);
job.setCombinerClass(WordCountReducer.class);
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
```
#### 代码执行
```bash
hadoop com.sun.tools.javac.Main WordCountMapper.java WordCountReducer.java WordCountMain.java
jar cf wc.jar WordCountMapper.class WordCountReducer.class WordCountMain.class
hadoop jar wc.jar WordCountMain input output
```
#### 结果说明
通过以上代码和执行步骤,我们可以在Hadoop上成功运行WordCount示例,并得到相应的统计结果。
### 6.2 分析并优化Hadoop任务
#### 场景说明
在实际应用中,Hadoop任务可能会面临性能瓶颈或资源利用不足的问题,我们需要对任务进行分析并进行优化。
#### 代码示例(优化部分)
```java
// 优化后的WordCountReducer.java
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Reducer;
public class OptimizedWordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
```
#### 优化结果说明
通过对Reducer进行优化,使用更适合实际情况的数据类型以及更高效的累加方式,可以显著提升WordCount任务的执行效率和性能。
以上就是使用Hadoop处理WordCount示例以及对Hadoop任务的分析与优化的实例演练部分的内容。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《大数据基础与应用》专栏深入探讨了大数据领域的核心技术和实际应用,涵盖了大数据存储、处理、分析等多个方面。专栏以《大数据存储技术综述》为开篇,系统介绍了Hadoop、Spark等开源框架的基本原理和应用。接着通过《Hadoop入门及安装配置》和《HDFS架构深入解析》让读者深入了解了Hadoop生态系统的核心组件及其工作机制。随后,《MapReduce编程模型简介》和《Spark快速入门指南》系统性地介绍了MapReduce和Spark的基本编程模型和使用方法。专栏更进一步讨论了实时数据处理和存储技术,包括《Spark Streaming实时数据处理》、《大数据清洗与预处理技术》、《实时数据处理:Kafka核心概念》等内容。在应用层面,《机器学习基础与大数据应用》、《数据挖掘算法概述及实践》以及《深度学习在大数据分析中的作用》帮助读者深入理解大数据在机器学习和数据挖掘领域的应用。最后,《大数据安全与隐私保护方法》和《容器化技术在大数据处理中的应用》为读者提供了大数据安全和容器化技术的相关知识。通过本专栏的学习,读者可以全面了解大数据基础知识及其在实际应用中的应用场景。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Quartus II USB Blaster驱动更新】:一步到位的故障排除流程
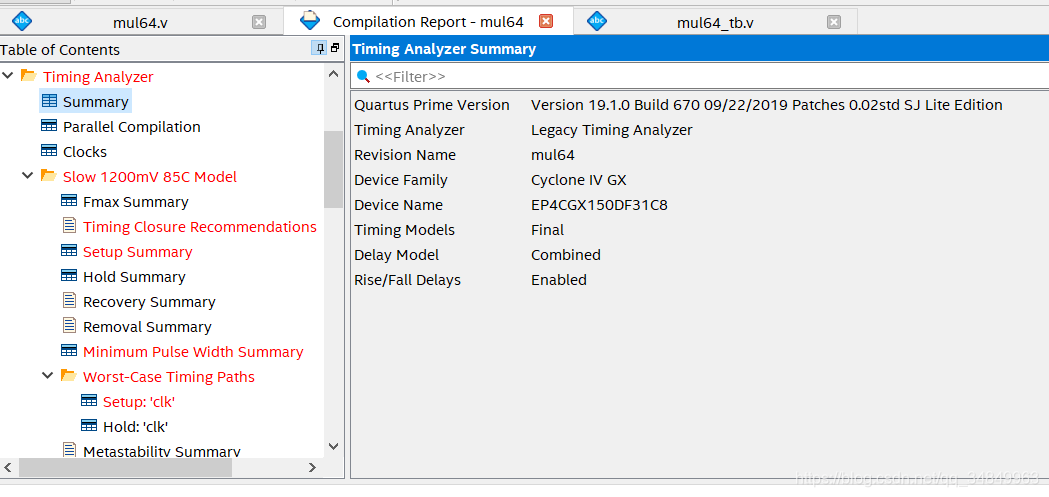
# 摘要
本文全面阐述了Quartus II USB Blaster驱动更新的各个方面。首先概述了驱动更新的必要性和应用场景,接着深入探讨了驱动的工作原理和与FPGA开发板的交互流程,以
ACIS SAT文件在逆向工程中的应用:从实体到模型的转换秘籍
# 摘要
本论文首先概述了ACIS SAT文件的结构和逆向工程的基础理论,随后深入探讨了ACIS文件的解析技术及其在三维模型重建中的应用。通过分析实体扫描技术、点云数据处理和三角面片优化,详细介绍了从ACIS数据到三维模型转换的实践操作。最后,论文探讨了逆向工程在实践中遇到的挑战,并展望了其技术发展趋势,包括技术革新、知识产权保护的平衡以及逆向工程在新兴领域的潜力。
# 关键字
ACIS SAT文件;逆向工程;点云数据;三维模型重建;技术挑战;发展前景
参考资源链接:[ACIS SAT文件格式详解:文本与二进制解析](https://wenku.csdn.net/doc/371wihxiz
GSM手机射频指标与用户感知:实现最佳性能与体验的平衡艺术
# 摘要
GSM技术作为移动通信领域的基础,其射频指标对用户感知有着重要影响。本文首先概述了GSM技术背景与射频指标,然后深入探讨了射频指标如何影响用户体验,包括信号强度、频段选择以及干扰和多径效应。接着,文章通过定性和定量方法评估了用户感知,并详细介绍了优化GSM手机射频性能的实践策略。此外,本文还分享了优化成功与失败的案例研究,强调了实践经验的重要性。最后,文章展望了未来技术发展趋势以及对用户体验提升和研究方
【C语言高阶应用】:sum函数在数据结构优化中的独门秘籍
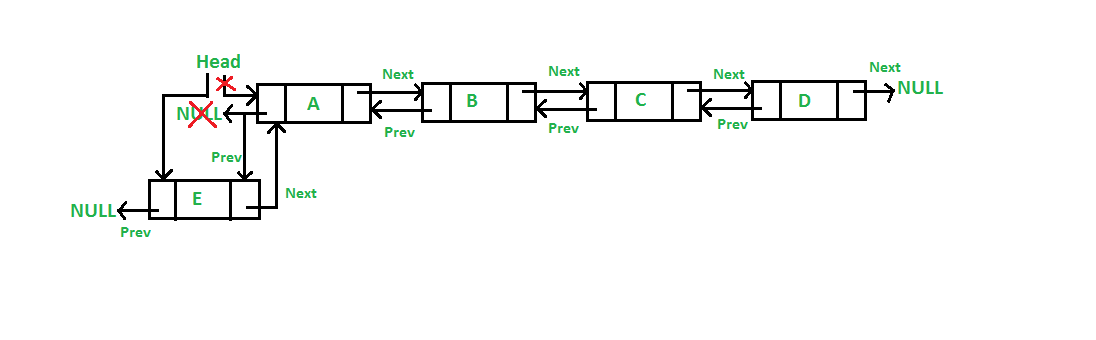
# 摘要
本文全面探讨了sum函数在不同类型数据结构中的应用、优化及性能提升。通过对sum函数在数组、链表、树结构以及图数据结构中的运用进行详细阐述,揭示了其在基础数据操作、内存优化和复杂算法中的核心作用。特别地,本文分析了如何通过sum函数进行内存管理和结构优化,以提高数据处理的效率和速度。文章总结了当前sum函数应用的趋势,并对未来数据结构优化的潜在方向和
【SYSWELD材料模型精确应用】:确保仿真准确性的关键步骤

# 摘要
SYSWELD材料模型是广泛应用于结构仿真中的重要工具,它通过理论基础、精确设置、实践应用及高级挑战的深入分析,为工程师提供了一套系统的方法论,以确保仿真结果的准确性和可靠性。本文首先概述了材料模型的基本概念及其在仿真中的作用,然后详细讨论了材料模型参数的来源、分类以及对仿真结果的影响。文章进一步探讨了材料属性的精确输入、校准
【Fluent UDF精通指南】:掌握核心技巧,优化性能
# 摘要
本文深入探讨了Fluent UDF(User-Defined Functions)的使用和编程技巧,旨在为CFD(计算流体动力学)工程师和研究人员提供全面的指导。文章首先介绍了Fluent UDF的基本概念、安装流程和编程基础,包括数据类型、变量、函数、宏定义以及调试方法。接着,本文深入讲解了内存管理、并行计算技巧和性能优化,通过案例研究展示了如何实现自定义边界条件和源项。此外,文章还介绍了Fluent UDF在工程应用中的实际操作,例如多相流、化学反应模型和热管理。最后,本文分享了实战技巧和最佳实践,包括代码组织、模块化、性能调优,并强调了社区资源的重要性以及终身学习的价值。
#
软件测试工具高效使用技巧:朱少民版课后习题的实战应用

# 摘要
本文全面探讨了软件测试工具的选型、测试用例的设计与管理、自动化测试工具的应用、缺陷管理与跟踪、测试数据管理与模拟工具以及测试报
【开关电源必修课】:MP2359工作原理与应用全解析
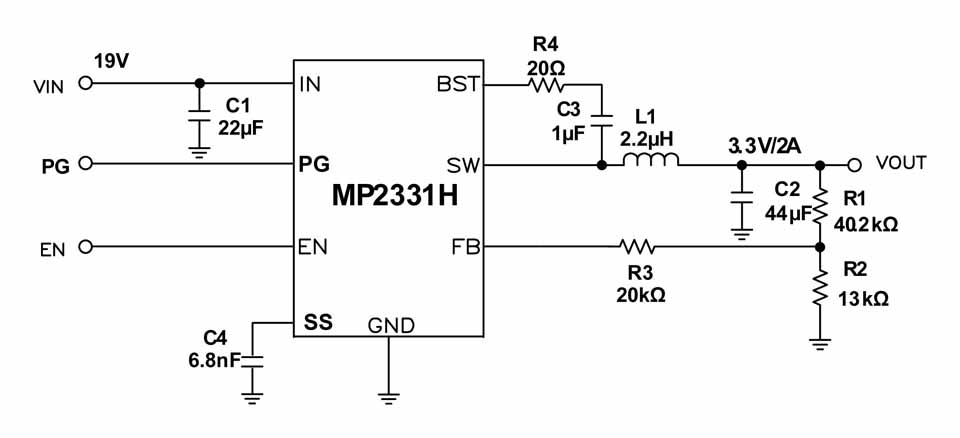
# 摘要
本文全面介绍了MP2359芯片的特性、工作原理、应用电路设计、调试优化技巧以及系统集成与应用实例。首先概述MP2359芯片的基本情况,随后详细阐述了其内部结构、工作模式和保护机制。文章接着深入探讨了MP2359在降压和升压转换器中的电路设计方法,并提供了实际设计案例。第四章专注于调试与优化技巧,包括效率提升、稳定性问题的调试以及PCB布局的指导原则。第五章讨论了MP2359在不同系统中的集成和创新应用,并分享了
【对位贴合技术难关攻克】:海康机器视觉案例深度剖析

# 摘要
本文首先概述了对位贴合技术及其在机器视觉领域的基础。随后,详细分析了实现对位贴合所需的关键技术点,并探讨了海康机器视觉在其中的应用和优势。针对技术难点,本文提出了精准定位、提高效率和适应复杂环境的解决方案。通过实践案例研究,展示了海康机器视觉在实际生产中的应用成效,并对其技术实现和效益进行了评估。最后,文章展望了对位贴合技术的未来发展趋势,重点介绍了海康机器视觉的创新突破与长远规
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )