深入R语言:parma包的7大高级特性及实际应用
发布时间: 2024-11-05 09:02:27 阅读量: 31 订阅数: 39 

pplpy:Parma多面体库(PPL)的Python包装器

# 1. parma包概述与基础安装
在数据分析与统计领域,R语言一直是不可或缺的工具,而`parma`包,作为R中一个功能丰富的数学和统计计算包,提供了强大的线性代数、统计分析、优化问题求解等功能。本章将从`parma`包的安装讲起,向读者介绍如何在R环境中进行基础的安装和设置,为后续章节深入学习和应用该包打下坚实基础。
## 安装与加载parma包
要安装`parma`包,仅需在R控制台执行以下命令:
```r
install.packages("parma")
```
安装完成后,通过`library`函数加载包:
```r
library(parma)
```
加载`parma`包后,我们可以使用其提供的各种函数和数据结构进行数学和统计分析。以下示例展示了如何创建矩阵并进行基本的线性代数运算:
```r
# 创建一个3x3的矩阵
A <- matrix(1:9, nrow=3, ncol=3)
# 计算矩阵的逆
A_inv <- solve(A)
# 输出逆矩阵
print(A_inv)
```
执行上述代码后,你将得到矩阵`A`的逆矩阵,这只是`parma`包强大功能的一个简单体现。在后续章节,我们将深入探讨`parma`包在数学运算、统计分析、数值计算等多个方面的高级应用。
# 2. parma包的数学和统计功能
## 2.1 线性代数运算
### 2.1.1 矩阵运算与分解
线性代数是数据分析和科学计算中的基石,parma包提供了丰富的线性代数运算功能,其中包括矩阵运算、矩阵分解等。对于矩阵运算,parma不仅涵盖了基础的加减乘除,还包括了矩阵的幂运算、行列式的计算以及矩阵的逆和伪逆计算。
具体到矩阵分解,常见的如LU分解、QR分解、特征值分解(Eigenvalue decomposition)等,在parma包中都有对应的函数可以调用。例如,`lu.decomposition`函数可以进行LU分解,`qr.decomposition`函数可以进行QR分解。
```r
# 示例代码,展示LU分解
m <- matrix(c(4, 3, 6, 3, 2, 1, 6, 1, 5), nrow=3, byrow=TRUE)
lu <- lu.decomposition(m)
print(lu)
# 执行逻辑:以上代码首先创建了一个3x3的矩阵m,然后使用lu.decomposition函数对该矩阵进行LU分解,并打印结果。
# 参数说明:matrix函数用于创建矩阵,nrow指定矩阵的行数,byrow指明矩阵按行填充。
# 分析:LU分解是将矩阵分解为一个下三角矩阵L和一个上三角矩阵U的乘积,这对于解线性方程组或者计算矩阵的行列式非常有用。
```
### 2.1.2 特征值和特征向量的计算
特征值和特征向量是研究矩阵性质的重要工具,parma包提供了`eigen`函数来计算矩阵的特征值和特征向量。例如:
```r
# 示例代码,展示特征值和特征向量的计算
eigen_values <- eigen(m)$values
eigen_vectors <- eigen(m)$vectors
print(eigen_values)
print(eigen_vectors)
# 执行逻辑:代码使用eigen函数计算矩阵m的特征值和特征向量,并分别打印。
# 参数说明:eigen函数返回一个列表,其中values为特征值,vectors为对应的特征向量。
# 分析:特征值描述了矩阵对线性变换的伸缩因子,特征向量描述了方向。在数据分析中,特征值分解常用于主成分分析和稳定性分析。
```
## 2.2 高级统计分析
### 2.2.1 多元统计方法
多元统计方法是处理多变量数据的强大工具。在parma包中,你可以找到诸如主成分分析(PCA)、因子分析、聚类分析等方法。例如,`pca`函数可以实现主成分分析:
```r
# 示例代码,展示PCA分析
pca_result <- pca(m)
# 执行逻辑:代码执行PCA分析,获取结果。
# 分析:PCA是降维技术中常用的一种方法,它可以揭示数据中的主要结构和变量间的相关性。
```
### 2.2.2 假设检验与显著性分析
假设检验是统计学中用于推断总体参数的重要方法。parma包提供了多种假设检验的函数,包括t检验、卡方检验等。例如:
```r
# 示例代码,展示t检验
x <- rnorm(100)
y <- rnorm(100, mean=0.5)
t_test_result <- t.test(x, y)
print(t_test_result)
# 执行逻辑:代码生成两个正态分布的随机变量x和y,然后进行两独立样本t检验。
# 参数说明:rnorm用于生成正态分布的随机数。t.test是R语言中进行t检验的函数。
# 分析:t检验用来确定两组数据是否有显著差异。该方法在比较实验组和对照组的平均值差异时十分常用。
```
## 2.3 数据模拟与抽样技术
### 2.3.1 随机数生成
在数据分析和统计建模中,生成随机数是模拟实验的基本需求。parma包支持从多种分布中抽取随机数,如正态分布、均匀分布等。例如:
```r
# 示例代码,展示随机数生成
random_normal <- rnorm(100)
random_uniform <- runif(100, min=0, max=1)
# 执行逻辑:代码生成100个服从标准正态分布和均匀分布的随机数。
# 参数说明:rnorm函数用于生成正态分布随机数,runif用于生成均匀分布随机数。min和max参数指定均匀分布的范围。
# 分析:随机数生成是模拟实验的基础,对于统计测试、机器学习中的数据增强等场景非常关键。
```
### 2.3.2 蒙特卡洛模拟方法
蒙特卡洛模拟是一种基于随机抽样的数值计算方法,用于解决复杂概率问题。parma包提供了基础的蒙特卡洛模拟功能,例如使用随机数模拟圆周率的计算。例如:
```r
# 示例代码,展示蒙特卡洛模拟
n <- 10000
x <- runif(n, min=-1, max=1)
y <- runif(n, min=-1, max=1)
points_inside <- sum(x^2 + y^2 <= 1)
pi_estimate <- 4 * points_inside / n
# 执行逻辑:代码随机生成n个点,计算这些点中有多少比例落在单位圆内,根据这个比例估算圆周率π的值。
# 参数说明:runif函数用于生成均匀分布随机数,min和max参数指定随机数的生成范围。
# 分析:蒙特卡洛方法通过随机抽样来模拟复杂系统的可能结果,是一种强大的数值计算工具。
```
在本章中,我们了解了parma包在数学和统计功能方面的强大能力,包括线性代数运算、高级统计分析以及数据模拟与抽样技术。接下来的章节,我们将探索parma包在高级数值计算中的应用,以及如何在数据分析中发挥作用。
# 3. parma包的高级数值计算
### 3.1 优化问题求解
在科学和工程领域,优化问题无处不在,从最小化成本到最大化效率,优化问题始终是提高效率和性能的关键。`parma`包为解决这些优化问题提供了丰富的工具,包括线性和非线性优化,以及多目标优化策略。
#### 3.1.1 线性与非线性优化
线性优化(线性规划)是最优化问题的一种,其目标函数和约束条件均为线性。`parma`包通过`linearoptimization`函数来解决线性优化问题。下面是一个简单的例子:
```R
# 安装并加载parma包
install.packages("parma")
library(parma)
# 定义目标函数系数
c <- c(3, 2)
# 定义线性约束矩阵和向量
A <- matrix(c(1, 1, 1, -1), nrow = 2, byrow = TRUE)
b <- c(10, 5)
# 线性优化求解
result <- linearoptimization(c, A, b)
# 输出结果
print(result)
```
在上述代码中,我们定义了一个目标函数系数向量`c`和一个约束矩阵`A`以及约束边界向量`b`。`linearoptimization`函数求解出满足约束条件下的最小化目标函数值及其对应的变量值。
非线性优化问题更为复杂,`parma`包提供了`nonlinearoptimization`函数,利用梯度下降法、拟牛顿法等算法进行求解。
```R
# 定义非线性目标函数
f <- function(x) {
return((x[1] - 1)^2 + (x[2] - 2)^2)
}
# 初始解
start <- c(0, 0)
# 非线性优化求解
result <- nonlinearoptimization(start, f)
# 输出结果
print(result)
```
在这个例子中,我们尝试最小化一个简单的二元非线性函数。`nonlinearoptimization`函数需要一个初始解作为起点,然后通过迭代方法来寻找全局最小值。
#### 3.1.2 多目标优化策略
多目标优化问题处理多个相互冲突的目标函数。`parma`包的`multiobjectiveoptimization`函数可以用来求解这类问题。
```R
# 定义多目标优化的目标函数向量
f1 <- function(x) { return(x[1] - 2) }
f2 <- function(x) { return(x[2] - 1) }
# 定义约束条件
A <- matrix(c(1, -1), nrow = 2, byrow = TRUE)
b <- c(3, 0)
# 多目标优化求解
result <- multiobjectiveoptimization(cbind(f1, f2), A, b)
# 输出结果
print(result)
```
在这个例子中,我们通过向量函数定义了两个目标函数,并且通过约束条件`A`和`b`定义了可行域。`multiobjectiveoptimization`函数将返回一组最优解(Pareto前沿),这些解在目标函数间取得了一种平衡。
### 3.2 数值积分与微分方程
数值积分与微分方程的求解在工程设计、物理模拟以及其他科学计算中有着广泛的应用。`parma`包提供了多种数值积分方法以及求解常微分方程的工具。
#### 3.2.1 高斯求积与数值积分技巧
数值积分在计算数学中是基础而重要的内容。高斯求积是一种有效的数值积分技术,`parma`包利用`gaussquadrature`函数提供这一方法。
```R
# 定义被积函数
f <- function(x) {
return(exp(-x^2))
}
# 高斯求积的节点和权重
nodes <- c(-sqrt(1/3), sqrt(1/3))
weights <- c(1, 1)
# 数值积分求解
result <- gaussquadrature(f, nodes, weights)
# 输出结果
print(result)
```
在这个例子中,我们通过已知的节点和权重对一个指数函数进行高斯积分,以求得其近似值。
#### 3.2.2 常微分方程求解器
常微分方程(ODE)是另一类在自然科学和工程中常见的数学模型。`parma`包提供了基于R6的ODE求解器,能够有效处理ODE问题。
```R
# 定义常微分方程
deq <- function(t, y) {
return(c(y[2], -y[1]))
}
# 初始条件
y0 <- c(1, 0)
t <- seq(0, 10, by = 0.1)
# ODE求解
result <- ode(y0, t, deq)
# 输出结果
print(result)
```
在这个例子中,我们定义了一个简谐振子的ODE,并指定了初始条件和求解时间区间。`ode`函数通过适当的数值方法(如龙格-库塔法)来求解微分方程,最终给出在指定时间点的解。
### 3.3 稳健估计与数据降维
在数据分析中,稳健估计和数据降维技术是应对异常值和减少数据维数的有效方法。`parma`包在这些方面也提供了强大的功能。
#### 3.3.1 稳健统计方法
稳健估计是在数据中存在异常值时仍能提供可靠估计的一种技术。`parma`包中的`robustestimation`函数可以帮助用户实现稳健统计估计。
```R
# 引入数据集
data(robustdata)
# 执行稳健估计
result <- robustestimation(robustdata)
# 输出结果
print(result)
```
在这个例子中,我们使用`robustestimation`函数对提供的数据集进行稳健统计估计。结果将返回稳健估计的结果,包括均值、方差等统计数据。
#### 3.3.2 主成分分析(PCA)及其他降维技术
主成分分析(PCA)是数据降维中应用广泛的技术之一。`parma`包通过`pca`函数提供了PCA的实现。
```R
# 引入数据集
data(iris)
# 执行PCA
result <- pca(iris)
# 输出结果
print(result)
```
在这个例子中,我们对鸢尾花数据集应用PCA技术,通过`pca`函数降维到主要成分,以可视化形式展示数据。
在上述章节中,我们探讨了`parma`包在高级数值计算方面的功能,包括优化问题的求解、数值积分与微分方程的求解,以及稳健估计与数据降维技术。`parma`包提供了一系列的函数和工具,能够有效地处理这些在数据科学领域中至关重要的问题。在接下来的章节中,我们将深入了解`parma`包在数据分析中的应用实例,以及它在编程特性和未来展望方面的能力。
# 4. parma包在数据分析中的应用
在数据分析领域,parma包提供了丰富的工具和函数,用以进行复杂数据的处理和分析。本章节将深入探讨parma包在时间序列分析、高维数据分析以及数据可视化方面的应用,并提供一些实践案例来展示如何将理论转化为实际操作。
## 4.1 时间序列分析
### 4.1.1 时间序列的建模与预测
时间序列分析是数据分析的重要分支,涉及到对数据随时间变化规律的理解和预测。在parma包中,时间序列的建模和预测可以通过其内置的时间序列函数来完成。
```r
library(parma)
# 示例数据集
data("AirPassengers")
time_series <- AirPassengers
# 建立时间序列模型,例如ARIMA模型
fit <- auto.arima(time_series)
# 进行短期预测
forecast <- forecast(fit, h=12)
# 绘制预测结果
plot(forecast)
```
在上述代码中,我们首先加载了parma包,并使用了内置的AirPassengers数据集。通过`auto.arima`函数自动选择了合适的ARIMA模型参数,并对未来12个周期进行了预测。最后,使用`plot`函数绘制了预测结果的图表。
### 4.1.2 季节性调整与周期性分析
时间序列数据往往包含季节性因素,这对于准确预测具有重要的影响。parma包提供了季节性调整和周期性分析的工具,帮助我们更好地理解数据的周期性模式。
```r
# 对数据进行季节性调整
seasonal_adjusted <- seasadj(fit)
# 分析周期性成分
periodogram <- spec.pgram(time_series, spans=c(3,5))
# 绘制周期性分析结果
plot(periodogram)
```
在上述代码段中,我们使用`seasadj`函数对预测模型的残差进行了季节性调整,以去除季节性影响。然后使用`spec.pgram`函数计算了时间序列的周期图,这有助于我们识别数据中的主要频率成分。通过绘图,我们可以直观地查看周期性成分的分布情况。
## 4.2 高维数据分析
### 4.2.1 聚类分析方法
在处理高维数据时,聚类分析是了解数据结构的重要工具。parma包中包含了多种聚类方法,如K-means、层次聚类等。
```r
# 使用K-means聚类方法
kmeans_result <- kmeans(data_matrix, centers=3)
# 层次聚类分析
hierarchical_result <- hclust(dist(data_matrix), method="complete")
# 绘制聚类树状图
plot(hierarchical_result)
```
在上面的代码中,首先使用`kmeans`函数对数据矩阵进行K-means聚类,并设置了聚类中心数为3。之后,使用`hclust`函数根据数据矩阵的距离矩阵进行层次聚类,并指定聚类方法为完全链接法。最后,通过绘制树状图来可视化层次聚类的结果。
### 4.2.2 维度缩减技术的应用
面对高维数据集,应用维度缩减技术能够帮助我们去除冗余信息,同时保留数据的重要特征。主成分分析(PCA)是一种广泛使用的降维技术。
```r
# 执行主成分分析
pca_result <- prcomp(data_matrix)
# 获取主成分的方差解释比例
variance_explained <- summary(pca_result)$importance["Proportion of Variance",]
# 绘制累积方差解释图
plot(cumsum(variance_explained))
```
上述代码通过`prcomp`函数对数据矩阵进行了PCA分析,并计算了各个主成分解释数据方差的比例。通过绘制累积方差解释图,我们可以直观地了解前几个主成分能够解释的总方差比例,从而决定需要保留的主成分数量。
## 4.3 数据可视化
### 4.3.1 高级绘图技术
数据可视化是数据分析中不可或缺的一部分。parma包不仅提供了标准的绘图函数,还支持创建高级的图形展示。
```r
# 创建三维散点图
library(rgl)
plot3d(time_series$x, time_series$y, time_series$z, type="s")
# 调整视图和光照
view3d(theta=30, phi=30)
light3d()
```
在以上代码中,使用了`rgl`包的`plot3d`函数创建了一个三维散点图,该图使用了三个变量`x`、`y`、`z`来展示数据点。通过`view3d`函数调整了视图角度,`light3d`函数设置了光照效果,从而增强了图形的立体感和可视化效果。
### 4.3.2 动画和交互式图形的应用
随着技术的发展,动画和交互式图形在数据可视化中变得越来越重要。parma包通过与其他包的整合,可以实现复杂的动画和交互式图形。
```r
# 使用ggplot2包创建交互式散点图
library(ggplot2)
library(plotly)
# 创建基础散点图
base_plot <- ggplot(data, aes(x, y)) + geom_point()
# 转换为交互式图形
interactive_plot <- ggplotly(base_plot)
# 显示交互式图形
print(interactive_plot)
```
在这段代码中,我们首先利用`ggplot2`包创建了一个基础的散点图,并指定了数据集和变量。然后,通过`ggplotly`函数将这个基础图转换成一个交互式图形,用户可以使用鼠标进行缩放、拖动等操作。最后,通过`print`函数在R环境中显示了这个交互式图形。
以上就是parma包在数据分析中应用的几个方面。从时间序列分析到高维数据处理,再到数据的可视化,parma包提供了一系列强大的工具,使得数据分析变得更加直观和高效。通过本章节的介绍,我们展示了如何将parma包的各个功能应用到实际的数据分析任务中,并通过代码示例来加深理解。
# 5. parma包的高级编程特性
## 5.1 自定义函数与接口
### 5.1.1 S4对象系统深入
S4对象系统是R语言中一种面向对象的编程体系,用于创建和操作复杂的数据结构。parma包充分利用了S4系统的优势,提供了一系列封装好的类和方法来支持高级计算和数据处理。深入理解S4对象系统,是高级编程和扩展parma包功能的关键。
在S4体系中,对象被划分为“类”,每个类都有自己的“槽”(slot)来存储数据,以及“方法”来定义对象的行为。例如,创建一个S4类的实例可以通过`new()`函数实现:
```R
setClass("MyClass", slots = c(x = "numeric", y = "character"))
myObject <- new("MyClass", x = 1:10, y = "example")
```
此处,我们定义了一个名为"MyClass"的类,该类有两个槽:一个是数值型的"x",另一个是字符型的"y"。然后我们创建了一个"MyClass"类的实例,并初始化了这两个槽。
parma包在进行矩阵运算和优化问题求解时,就大量使用了S4系统来定义各种数学对象和相应的计算方法。理解了S4系统,用户可以更灵活地扩展parma包,定义新的计算类和方法,进而处理更复杂的数据分析任务。
### 5.1.2 C++集成与性能提升
由于R语言本身的计算性能有限,parma包通过集成C++代码来提升关键计算部分的性能。C++的效率和灵活性使得复杂算法的执行速度大大提升,这对于大数据分析尤为重要。
为了在R中使用C++代码,可以利用`Rcpp`包来实现R和C++代码的无缝集成。首先需要安装和加载`Rcpp`包:
```R
install.packages("Rcpp")
library(Rcpp)
```
然后,用户可以编写C++代码,并将其封装成R函数。以下是一个简单的例子:
```cpp
// [[Rcpp::export]]
NumericVector addC(NumericVector a, NumericVector b) {
return a + b;
}
```
上述代码定义了一个C++函数`addC`,它接受两个`NumericVector`类型的向量,返回它们的和。通过`[[Rcpp::export]]`标记,我们可以使得这个函数在R中可用。
```R
sourceCpp('path_to_source_file.cpp')
result <- addC(1:10, 11:20)
print(result)
```
通过上述步骤,C++代码被编译并集成到R环境中。这个技术尤其适用于需要频繁计算或处理大规模数据的场景,如矩阵运算、统计分析等。
## 5.2 并行计算与多核处理
### 5.2.1 并行计算策略
在处理大规模数据集或进行复杂计算时,单核CPU的处理能力可能成为瓶颈。并行计算通过同时使用多个计算资源来提高计算效率,而parma包提供了对并行计算的支持,以提升数据处理的性能。
在R中,parma包可以利用多种并行计算策略,如多线程、多进程等。使用`parallel`包,可以创建并行集群和并行任务:
```R
library(parallel)
cl <- makeCluster(4) # 创建4个工作节点的集群
clusterExport(cl, c("x", "y")) # 导出变量到所有工作节点
clusterEvalQ(cl, library(parma)) # 在每个工作节点上加载parma包
```
此代码段展示了如何创建一个包含4个工作节点的集群,并将parma包加载到每个节点上。
为了在parma包中使用并行计算,需要明确指定并行策略并将其应用到特定的函数上。例如,使用`parApply`函数对矩阵进行并行计算:
```R
result <- parApply(cl, matrix_data, 1, function(row) {
# 在这里执行复杂的计算
})
```
### 5.2.2 多核编程实例
为了进一步理解并行计算在parma包中的应用,我们来构建一个简单的多核编程实例。假设我们有一个大型矩阵,需要计算它的每一列的某种统计量,如中位数。
我们可以使用`parallel`包的`parLapply`函数来并行处理这个任务:
```R
# 假设 matrix_data 是一个大型矩阵,每一列需要计算中位数
colMedians <- parLapply(cl, split(matrix_data, col(matrix_data)), function(col) {
median(col)
})
```
在这个例子中,我们将矩阵`matrix_data`按照列分割并分配到不同的工作节点上,每个节点计算自己分配到的列的中位数。最后,将结果合并起来。
这个例子展示了parma包如何与并行计算结合,以加速数据处理。并行计算策略的选择和实施对于提升计算效率至关重要,特别是在涉及大数据和复杂算法的场景下。
## 5.3 包的扩展与开发
### 5.3.1 开发者的视角
对于有志于扩展或贡献于parma包的开发者而言,掌握包的开发和维护的最佳实践是非常必要的。这不仅涉及到编写高质量的代码,还包括了文档编写、单元测试和版本控制等。
parma包的开发者需要熟悉R的包开发框架,比如如何在`DESCRIPTION`文件中声明依赖、如何组织源代码文件和文档。同时,开发者应当遵循编码规范,比如Google的R编程风格指南。
对于代码测试,使用`testthat`包进行单元测试是常见的做法。开发者可以编写测试脚本,自动验证函数的预期行为。例如:
```R
test_that("foo function works", {
expect_equal(foo(1), 1)
expect_error(foo("a"))
})
```
此处,我们定义了两个测试:第一个测试检查`foo`函数在输入为1时的输出是否为1,第二个测试检查输入非数值类型时函数是否抛出错误。
### 5.3.2 包的文档编写与测试
文档编写是包开发中不可或缺的一部分。良好的文档能够帮助用户了解如何使用包中的函数,以及函数的预期行为和参数说明。
parma包使用了Roxygen2风格的注释,这种风格可以直接在源代码中嵌入文档注释。例如:
```R
#' Calculate the median of a vector.
#'
#' This function takes a numeric vector as input and returns the median value.
#'
#' @param x A numeric vector.
#' @return The median value of the input vector.
#' @export
#' @examples
#' median(1:10)
#' @seealso \code{\link{mean}}
median <- function(x) {
# ...
}
```
上述代码中,我们使用了Roxygen2注释来编写一个函数的文档。这种注释包括了函数的简短描述、参数说明、返回值以及示例代码。
文档编写完成后,可以使用`roxygen2::roxygenise()`函数来生成和更新包文档。此外,包的维护者应当定期更新包的版本,并发布到CRAN上。在每次更新时,除了代码的改进外,也需要同步更新文档和测试,确保包的健壮性和易用性。
# 6. parma包的案例研究与未来展望
## 6.1 真实案例分析
### 6.1.1 生物信息学中的应用
在生物信息学领域,parma包可以应用于多种复杂计算任务,如基因组数据分析、蛋白质结构预测以及代谢网络建模等。以下是一个具体案例,介绍如何使用parma包来进行基因表达数据分析。
假设有一组基因表达数据,研究者需要识别出哪些基因在特定条件下的表达水平发生变化。首先,需要使用parma包进行数据预处理,包括标准化、缺失值处理以及批次效应校正。接着,应用主成分分析(PCA)来降维,并使用聚类分析方法探究基因表达模式。
```r
# 加载parma包
library(parma)
# 假设 gene_expression_data 是预先加载好的基因表达矩阵
# 数据预处理
expression_data_normalized <- normalizeData(gene_expression_data)
missing_values_handled <- handleMissingValues(expression_data_normalized)
# 主成分分析
pca_result <- performPCA(missing_values_handled)
# 聚类分析
cluster_result <- performClustering(pca_result)
```
聚类结果可以用于进一步的生物学解读,从而提供对生物过程深入的理解。
### 6.1.2 金融数据分析实例
在金融数据分析中,parma包同样发挥着重要作用。举个例子,在投资组合优化中,投资者可能希望根据历史收益数据和市场波动性,计算最优的资产配置。parma包中的优化算法可以帮助解决这一问题。
以下是一个简单的投资组合优化示例,其中包含优化过程中的步骤:
```r
# 假设 assets_returns 是包含不同资产历史收益率的矩阵
# 目标是最小化投资组合的风险,同时满足预期收益的要求
# 风险模型建立
risk_model <- computeRiskModel(assets_returns)
# 优化模型设定
optimization_model <- setupOptimization(risk_model, expected_return = 0.01)
# 求解优化问题
optimal_weights <- solveOptimization(optimization_model)
# 输出最优资产权重
print(optimal_weights)
```
这个优化过程将输出最优的资产配置权重,供投资者参考。
## 6.2 parma包的发展趋势
### 6.2.1 新版本更新内容
随着R语言的持续发展,parma包也在不断更新以保持其先进性和实用性。新版本的parma包预计将会包含一些关键更新,如对更大数据集的优化处理能力、更多的数学和统计功能,以及更高效的并行计算支持。
### 6.2.2 R语言生态中的地位与发展
parma包作为R语言生态系统中的重要组成部分,其地位和影响力预计将继续增长。随着数据科学的不断进步,尤其是在机器学习和大数据分析方面,parma包将继续扩展其功能,以适应日益增长的计算需求和数据分析的复杂性。
未来,parma包可能还会集成更多高级算法和机器学习模型,使其在数据科学领域应用更加广泛,并助力R语言继续保持其在统计编程语言领域的竞争力。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
该专栏深入介绍了 R 语言中功能强大的 parma 数据包,提供从初学者到高级用户的全面教程。通过一系列文章,专栏涵盖了 parma 的基本技巧、高级特性、实战演练、参数调优、高级过滤、统计分析、故障排除、必备技能、金融数据分析、机器学习预处理、时间序列分析、大数据处理、生物信息学应用、贝叶斯统计和高级绘图。专栏旨在帮助 R 语言用户充分利用 parma 的强大功能,提高数据分析和数据挖掘能力,并为金融、生物信息学和机器学习等领域的应用提供实用指南。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【CATIA V5复合材料设计终极指南】:从入门到专业设计的全攻略
# 摘要
CATIA V5作为一种先进的三维设计软件,在复合材料设计领域中扮演着重要角色。本文详细介绍了CATIA V5在复合材料设计中的应用,从基础知识、设计工具与环境、建模与分析到仿真与测试等方面进行了全面的探讨。通过对复合材料的分类、特性分析以及设计流程优化技巧的阐述,本文旨在提供给读者一个关于如何有效利用CATIA V5进行复合材料设计的实践指南。本文还通过案例研究,展示了复合材料在不同行业,如航空航天和汽车制造中的实际应用,并讨论了仿真技术在产品开发中的重要作用。关键字
# 关键字
复合材料设计;CATIA V5;机械性能分析;设计流程优化;结构分析与优化;仿真模拟
参考资源链接:
技术债务不再是问题:中控BS架构考勤系统的代码健康维护策略

# 摘要
本文全面探讨了中控BS架构考勤系统的设计、维护策略和性能优化。文章首先概述了中控BS架构的定义、优势以及技术债务的形成与影响,强调了代码健康维护的重要性。随后,深入讨论了代码健康维护的理论框架,包括策略设计原则、设计模式与重构方法,以及自动化测试和持续集成的实施。接着,通过实际案例分析,探讨了代码重构实践、测试驱动开发(TDD)的实施和持续部署(CD)与代码质量保证的策
程序员认证考点:字符串处理函数的编写技巧
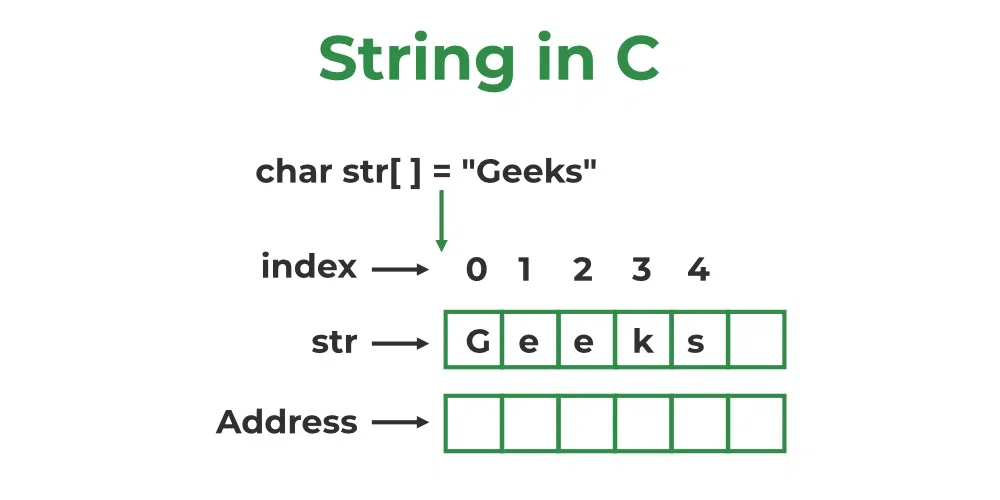
# 摘要
字符串处理作为编程中不可或缺的技能,对软件开发的各个方面都有深远影响。本文从字符串处理的基本理论讲起,详细介绍了字符串创建与销毁、查找与替换、分割与连接等基础操作,强调了正确内存管理的重要性。进一步,本文探讨了使用正则表达式、处理Unicode及多字节字符集,以及字符串的国际化和本地化等高级技术。性能优化部分着重于算法选择、内存管理和编译器优化,以提高字符串处理的效率
光传输安全新防线:保护ODU flex-G.7044免受网络攻击
# 摘要
随着光传输技术的不断发展,网络安全问题日益突出,ODU flex-G.7044作为一种先进的传输技术,其安全性和可靠性成为关注焦点。本文首先介绍了光传输与网络安全的基础知识,然后深入探讨ODU flex-G.7044技术的工作原理及其技术优势和应用场景。第三章分析了针对ODU flex-G.7044的网络攻击手段及其带来的风险,接着在第四章提出
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
无线定位算法安全防护指南:防范定位数据泄露的有效措施
# 摘要
无线定位技术在提供便捷服务的同时,也带来了严重的安全风险,尤其是定位数据的泄露问题。本文首先概述了无线定位技术及其潜在的安全风险,然后深入分析了定位数据泄露的途径与影响,包括信号截获、网络攻击
【跨领域视角】:探索S参数转换表在各行各业的应用
# 摘要
S参数转换表是现代电信、计算机科学及制造业中不可或缺的技术工具。本文首先介绍了S参数转换表的基础概念及其在射频系统中的作用,并详述了它在信号完整性分析、材料测试、机械设计和质量控制中的广泛应用。然后,探讨了S参数转换表在计算机科学领域中的应用,包括高速网络通信、计算机硬件设计和软件开发。最后,本文展望了S参数转换表在新
【TongWeb7事务管理与数据一致性】:业务数据安全的保障
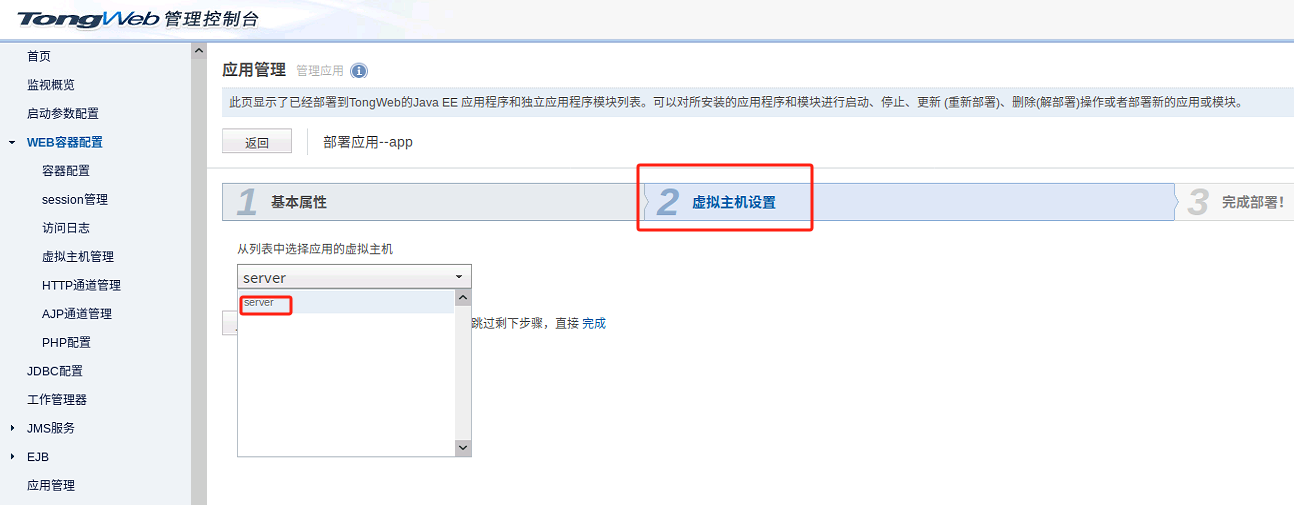
# 摘要
TongWeb7事务管理是确保企业级应用数据一致性和完整性的关键组成部分。本文首先介绍了事务管理的基础理论,包括事务的ACID属性、数据一致性的理论支持和隔离级别的分类。接着,探讨了TongWeb7在事务管理实践方面的高级特性和性能优化策略,如嵌套和分布式事务、事务日志及恢复机制。文章还深入分析了数据一致性在TongWeb7中的实现细节,包括锁机制、死锁预防和事务日志的管理。最后,针对业务数据安全进阶话题,本文讨论
【优化案例研究】:从问题到解决方案,PID控制系统的升级之旅
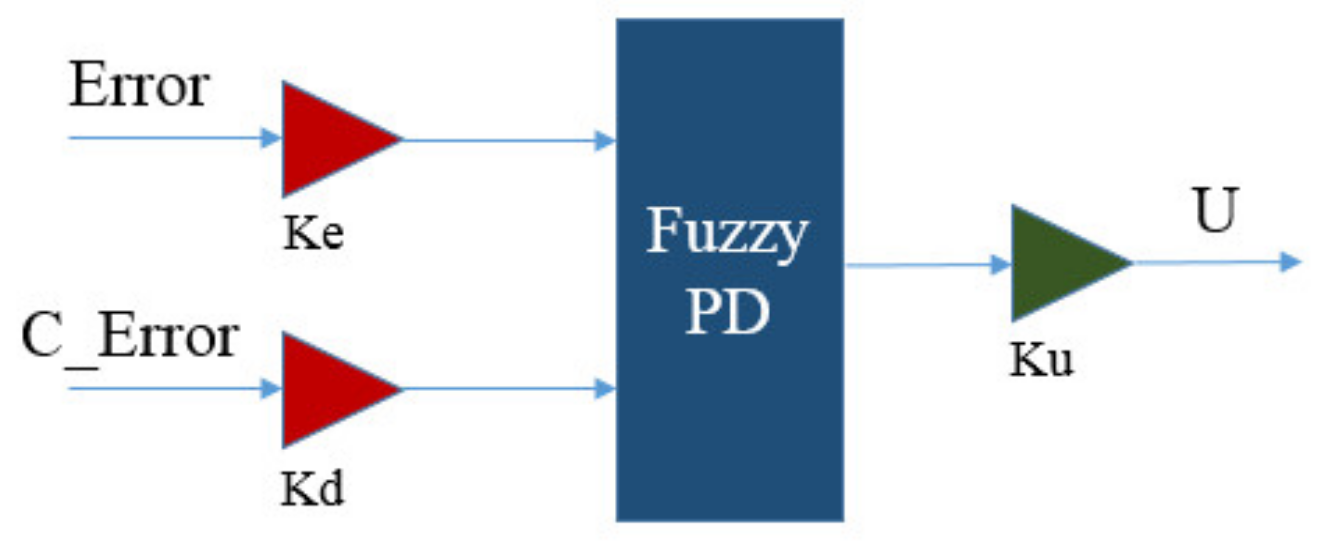
# 摘要
本文对PID控制系统进行了全面概述,深入解析了PID控制理论,包括控制器原理、数学模型构建以及参数意义。文章还探讨了PID控制器参数调节的经典方法、优化技术及自动调整策略。针对控制系统中常见的超调、稳定性问题以及噪声干扰,本文提供了理论分析和改进方法。对于非线性和复
【老旧系统升级】:如何为传统Delphi系统添加现代进度反馈
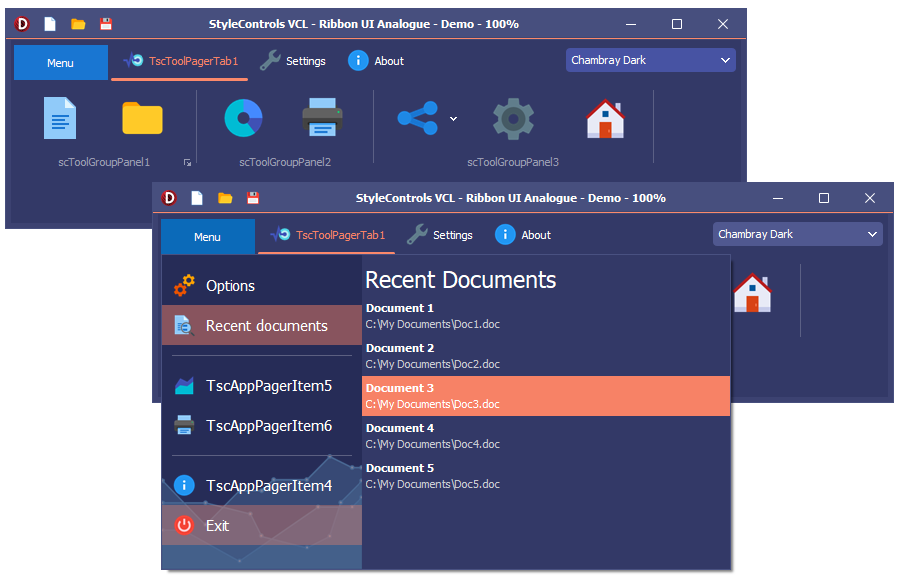
# 摘要
随着信息技术的快速发展,老旧系统的升级已成为维持企业竞争力的关键步骤。本文探讨了老旧Delphi系统升级的需求与挑战,回顾了Delphi的基础知识,强调了现代进度反馈机制的重要性,并提供了现代化改造的实践案例。文章详细讨论了老旧Delphi系统功能重构、进度反馈机制的集成,以及系统测试与优化的方法。最后
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )