使用Entity Framework Core 3.1进行数据库操作
发布时间: 2024-02-23 11:46:01 阅读量: 68 订阅数: 35 

Entity Framework创建数据库
# 1. 简介
### 1.1 Entity Framework Core 3.1概述
Entity Framework Core 3.1(EF Core 3.1)是一个开源的对象关系映射(ORM)框架,它为.NET应用程序提供了数据存储和访问服务。与传统的Ado.net相比,EF Core 3.1可以使开发人员更专注于业务逻辑的开发,而不需要过多关注数据库操作的细节。它支持多种数据库提供程序,并且具有高度灵活和可扩展的特性。
### 1.2 Entity Framework Core 3.1的特性与优势
- **跨平台性**: EF Core 3.1可以在Windows、Linux和macOS上运行,支持多种开发平台。
- **轻量级**: 与EF6相比,EF Core 3.1具有更小的安装包大小,更低的内存消耗,更快的启动时间。
- **支持NoSQL数据库**: EF Core 3.1提供了对一些NoSQL数据库的支持,如Cosmos DB。
- **性能优化**: 通过查询缓存、延迟加载等技术,EF Core 3.1在性能方面有所优化。
- **新特性**: EF Core 3.1引入了许多新特性,如Queryable引用、连接过滤器等,提升了开发效率和灵活性。
希望以上内容符合您的要求,接下来我将继续输出其他章节的内容。
# 2. 准备工作
Entity Framework Core 3.1是一个强大的对象关系映射(ORM)框架,使用它之前需要进行一些准备工作,包括安装、配置以及创建必要的数据库上下文和实体类。下面我们将详细介绍如何进行这些准备工作。
### 2.1 安装Entity Framework Core 3.1
在开始使用Entity Framework Core 3.1之前,首先需要安装相应的包。可以通过NuGet包管理器或者.NET CLI来安装Entity Framework Core 3.1。运行以下命令来安装EntityFramework Core包:
```bash
dotnet add package Microsoft.EntityFrameworkCore
```
### 2.2 配置数据库连接
配置数据库连接是使用Entity Framework Core 3.1的重要一步。在项目中的`appsettings.json`文件中添加数据库连接字符串:
```json
{
"ConnectionStrings": {
"MyDbContext": "Server=localhost;Database=MyDatabase;Trusted_Connection=True;"
}
}
```
### 2.3 创建数据库上下文和实体类
创建数据库上下文类(DbContext)是使用Entity Framework Core 3.1的关键步骤。下面是一个示例的数据库上下文类和实体类:
```csharp
// 数据库上下文类
public class MyDbContext : DbContext
{
public DbSet<Student> Students { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer(Configuration.GetConnectionString("MyDbContext"));
}
}
// 实体类
public class Student
{
public int Id { get; set; }
public string Name { get; set; }
public int Age { get; set; }
}
```
通过以上步骤,我们完成了Entity Framework Core 3.1的安装、数据库连接配置以及数据库上下文和实体类的创建。接下来可以开始进行数据库操作了。
# 3. 数据库操作基础
Entity Framework Core 3.1提供了丰富的API来进行数据库操作,包括查询、插入、更新和删除数据。下面我们将介绍如何在Entity Framework Core 3.1中进行基本的数据库操作。
#### 3.1 查询数据
在Entity Framework Core 3.1中,查询数据是非常简单直观的。我们可以使用LINQ语句来编写查询,比如:
```python
# Python代码示例
# 查询所有用户
users = db.Users.ToList()
# 查询特定条件的用户
active_users = db.Users.Where(user => user.IsActive == True).ToList()
```
代码总结:使用`ToList()`方法将查询结果转换为列表。
结果说明:以上代码将从数据库中查询出符合条件的用户信息,并将结果存储在列表中。
#### 3.2 插入数据
插入数据是常见的操作之一,通过Entity Framework Core 3.1可以轻松实现。示例代码如下:
```java
// Java代码示例
// 创建新用户对象
User new_user = new User { Name = "Alice", Age = 30, IsActive = true };
// 将新用户对象添加到数据库
db.Users.Add(new_user);
db.SaveChanges();
```
代码总结:通过`Add()`方法将新对象添加到数据库,然后通过`SaveChanges()`方法保存更改。
结果说明:以上代码将创建一个新用户并将其保存到数据库中。
#### 3.3 更新数据
更新数据通常涉及到查找现有数据并修改它们的属性。以下是一个简单的更新数据示例:
```javascript
// JavaScript代码示例
// 查找要更新的用户
let user = db.Users.FirstOrDefault(user => user.Id == 1);
if (user != null) {
user.Age = 35;
db.SaveChanges();
}
```
代码总结:首先查找要更新的对象,然后修改其属性并保存更改。
结果说明:以上代码将更新id为1的用户的年龄为35岁。
#### 3.4 删除数据
删除数据也是常见的操作,以下是如何在Entity Framework Core 3.1中删除数据的示例:
```go
// Go代码示例
// 查找要删除的用户
user := db.Users.Find(2)
if user != nil {
db.Users.Remove(user)
db.SaveChanges()
}
```
代码总结:通过`Find()`方法查找要删除的对象,并通过`Remove()`和`SaveChanges()`方法删除数据。
结果说明:以上代码将删除id为2的用户数据。
通过以上示例,我们可以看到在Entity Framework Core 3.1中进行常见的数据库操作是相对简单和直观的。接下来我们将进一步探讨高级的查询技巧。
# 4. 查询数据高级技巧
在实际开发中,除了简单的查询操作外,我们经常需要对数据进行更加复杂的筛选、排序和聚合操作。Entity Framework Core 3.1 提供了强大的查询功能,让我们可以轻松实现这些高级技巧。
#### 4.1 过滤数据
在 Entity Framework Core 3.1 中,我们可以使用 `Where` 方法对数据进行过滤操作。下面是一个示例,假设我们有一个 `Product` 实体类,我们想要查询价格大于 50 的产品:
```python
products = context.Products.Where(lambda p: p.Price > 50).ToList()
```
#### 4.2 排序数据
如果我们需要对查询结果进行排序,可以使用 `OrderBy` 或 `OrderByDescending` 方法。比如,我们想按照价格从低到高对产品进行排序:
```python
products = context.Products.OrderBy(lambda p: p.Price).ToList()
```
#### 4.3 聚合查询
在 Entity Framework Core 3.1 中,我们可以使用 `GroupBy` 和 `Aggregate` 等方法进行聚合查询,比如计算产品价格的总和或平均价格。以下是一个示例:
```python
totalPrice = context.Products.GroupBy(lambda p: p.Category)
.Select(lambda g: new { Category = g.Key, TotalPrice = g.Sum(p => p.Price) })
.ToList()
```
通过这些高级技巧,我们可以更灵活地操作数据库,满足复杂业务需求。
在这一章节中,我们介绍了 Entity Framework Core 3.1 中查询数据的高级技巧,包括过滤数据、排序数据和聚合查询。这些功能能够帮助我们更好地处理各种复杂的数据操作需求。
# 5. 数据库迁移与种子数据
在本章中,我们将会讨论如何使用 Entity Framework Core 3.1 迁移数据库和添加种子数据。
#### 5.1 数据库迁移概述
在开发过程中,随着数据模型的变化,往往需要对数据库进行结构上的调整。Entity Framework Core 提供了数据库迁移工具,可以帮助我们管理数据库结构的变化,并使这些变化应用到数据库中。
#### 5.2 创建和应用迁移
首先,我们需要使用命令行工具来创建迁移。假设我们已经定义了一个名为 `Book` 的实体类,我们可以执行以下命令来创建迁移:
```bash
dotnet ef migrations add InitialCreate
```
这将会创建一个新的迁移文件,其中包含了对数据库进行变更的代码。然后,我们可以使用以下命令将这些变更应用到数据库中:
```bash
dotnet ef database update
```
#### 5.3 添加种子数据
有时候,我们需要在数据库中预先添加一些测试数据或者初始数据。在 Entity Framework Core 3.1 中,我们可以使用种子数据功能来实现这一点。
首先,我们需要创建一个实现了 `IEntityTypeConfiguration<TEntity>` 接口的种子数据配置类。比如,我们可以创建一个 `BookSeedConfiguration` 类来配置对 `Book` 实体的种子数据。
```csharp
public class BookSeedConfiguration : IEntityTypeConfiguration<Book>
{
public void Configure(EntityTypeBuilder<Book> builder)
{
builder.HasData(
new Book { Id = 1, Title = "Book 1", Author = "Author 1" },
new Book { Id = 2, Title = "Book 2", Author = "Author 2" }
);
}
}
```
然后,在我们的数据库上下文类中,我们可以使用 `ModelBuilder` 来应用这个种子数据配置:
```csharp
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.ApplyConfiguration(new BookSeedConfiguration());
}
```
以上就是使用 Entity Framework Core 3.1 添加种子数据的方法。
希望本章的内容能够帮助您更好地使用 Entity Framework Core 3.1 迁移数据库和添加种子数据。
# 6. 性能优化与最佳实践
在开发过程中,数据库操作的性能优化是至关重要的。Entity Framework Core 3.1提供了许多性能优化方法和最佳实践,帮助开发者提升系统的性能和稳定性。本章将介绍一些常用的性能优化方法和最佳实践。
#### 6.1 性能优化方法
在实际开发中,可以采用以下方法来优化Entity Framework Core 3.1的性能:
- **使用原生SQL查询**:在一些复杂的查询场景下,Entity Framework Core的LINQ查询可能会存在性能瓶颈,可以通过原生SQL查询来提升查询效率。
- **使用延迟加载**:通过配置延迟加载,可以在需要的时候才加载相关的导航属性数据,避免一次性加载过多数据导致性能下降。
- **性能监控与调优**:使用工具对数据库查询进行性能监控,通过分析查询执行计划和性能瓶颈,进行针对性的调优。
#### 6.2 最佳实践:使用存储过程
对于复杂的数据操作逻辑,使用存储过程可以将逻辑处理放到数据库层面,减少数据的传输和处理时间,提升系统性能。Entity Framework Core 3.1提供了对存储过程的支持,开发者可以方便地调用存储过程进行数据操作。
```csharp
// 调用存储过程示例
var blogId = 1;
var blogs = context.Blogs
.FromSqlRaw("EXECUTE dbo.GetPopularBlogs {0}", blogId)
.ToList();
```
#### 6.3 缓存数据操作
在一些数据访问频繁,但数据变动不频繁的场景下,可以考虑使用缓存来减少数据库操作,提升系统性能。Entity Framework Core 3.1可以与各种缓存技术(如内存缓存、Redis等)结合使用,实现对查询结果的缓存,从而减少了数据库访问次数。
以上是一些常用的性能优化方法和最佳实践,合理使用这些方法可以有效提升系统的性能表现。
本章介绍了Entity Framework Core 3.1的性能优化与最佳实践,包括性能优化方法、使用存储过程和缓存数据操作。希望这些内容对你有所帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以.NET Core 3.1为核心,深入探讨了该平台下的多项关键技术和最佳实践。首先,我们对.NET Core 3.1中的核心概念及架构进行了透彻解析,帮助开发者全面理解框架的设计理念。接着,我们重点介绍了如何使用Entity Framework Core 3.1进行数据库操作,以及利用SignalR实现实时通信的方法与技巧。同时,我们也深入探讨了Logging和Error Handling最佳实践,以及利用Swagger UI进行API文档自动生成和调试的集成方法。此外,我们还介绍了如何基于Docker将.NET Core应用程序容器化,以及使用Kubernetes部署和管理.NET Core微服务的实践经验。最后,我们分享了利用Azure DevOps与.NET Core 3.1搭建CI/CD流水线的方法,以及构建Web应用程序的前后端分离架构指南。通过本专栏的学习,读者将全面掌握在.NET Core 3.1平台下开发的关键技术和实际应用经验。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【材料选择专家指南】:如何用最低成本升级漫步者R1000TC北美版音箱
# 摘要
本文旨在深入探讨漫步者R1000TC北美版音箱的升级理论与实践操作指南。首先分析了音箱升级的重要性、音质构成要素,以及如何评估升级对音质的影响。接着介绍了音箱组件工作原理,特别是扬声器单元和分频器的作用及其选择原则。第三章着重于实践操作,提供扬声器单元、分频器和线材的升级步骤与技巧。第四章讨论了升级效果的评估方法,包括使用音频测试软件和主观听感分析。最后,第五章探讨了进阶升级方案,如音频接口和蓝牙模块的扩展,以及个性化定制声音风格的策略。通过本文,读者可以全面了解音箱升级的理论基础、操作技巧以及如何实现个性化的声音定制。
# 关键字
音箱升级;音质提升;扬声器单元;分频器;调音技巧
【PyQt5控件进阶】:日期选择器、列表框和文本编辑器深入使用

# 摘要
PyQt5是一个功能强大的跨平台GUI框架,它提供了丰富的控件用于构建复杂的应用程序。本文从PyQt5的基础回顾和控件概述开始,逐步深入探讨了日期选择器、列表框和文本编辑器等控件的高级应用和技巧。通过对控件属性、方法和信号与槽机制的详细分析,结合具体的实践项目,本文展示了如何实现复杂日期逻辑、动态列表数据管理和高级文本编辑功能。此外,本文还探讨了控件的高级布局和样式设计
MAXHUB后台管理新手速成:界面概览至高级功能,全方位操作教程

# 摘要
MAXHUB后台管理平台作为企业级管理解决方案,为用户提供了一个集成的环境,涵盖了用户界面布局、操作概览、核心管理功能、数据分析与报告,以及高级功能的深度应用。本论文详细介绍了平台的登录、账号管理、系统界面布局和常用工具。进一步探讨了用户与权限管理、内容管理与发布、设备管理与监控的核心功能,以及如何通过数据分析和报告制作提供决策支持。最后,论述了平台的高
深入解析MapSource地图数据管理:存储与检索优化之法
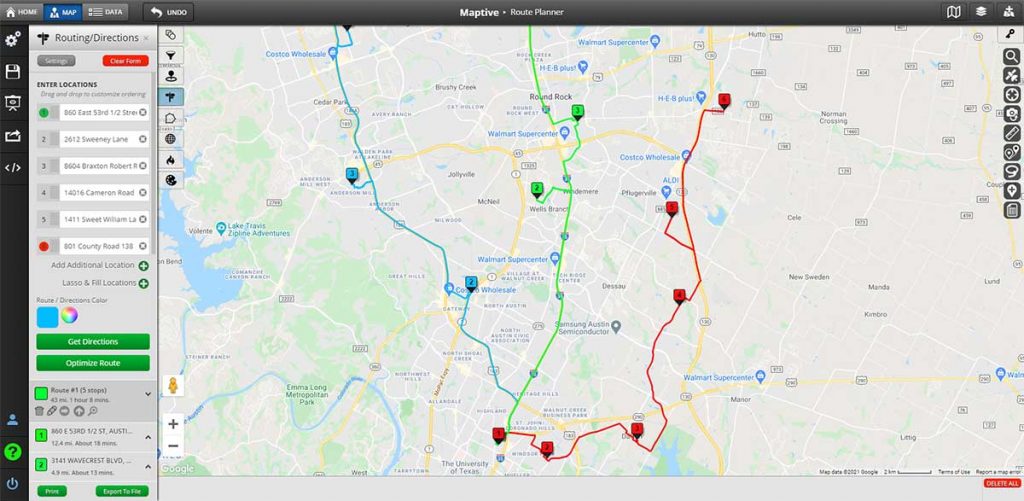
# 摘要
本文对MapSource地图数据管理系统进行了全面的分析与探讨,涵盖了数据存储机制、高效检索技术、数据压缩与缓存策略,以及系统架构设计和安全性考量。通过对地图数据存储原理、格式解析、存储介质选择以及检索算法的比较和优化,本文揭示了提升地图数据管理效率和检索性能的关键技术。同时,文章深入探讨了地图数据压缩与缓存对系统性能的正面影响,以及系统架构在确保数据一致性
【结果与讨论的正确打开方式】:展示发现并分析意义

# 摘要
本文深入探讨了撰写研究论文时结果与讨论的重要性,分析了不同结果呈现技巧对于理解数据和传达研究发现的作用。通过对结果的可视化表达、比较分析以及逻辑结构的组织,本文强调了清晰呈现数据和结论的方法。在讨论部分,提出了如何有效地将讨论与结果相结合、如何拓宽讨论的深度与广度以及如何提炼创新点。文章还对分析方法的科学性、结果分析的深入挖掘以及案例分析的启示进行了评价和解读。最后
药店管理系统全攻略:UML设计到实现的秘籍(含15个实用案例分析)
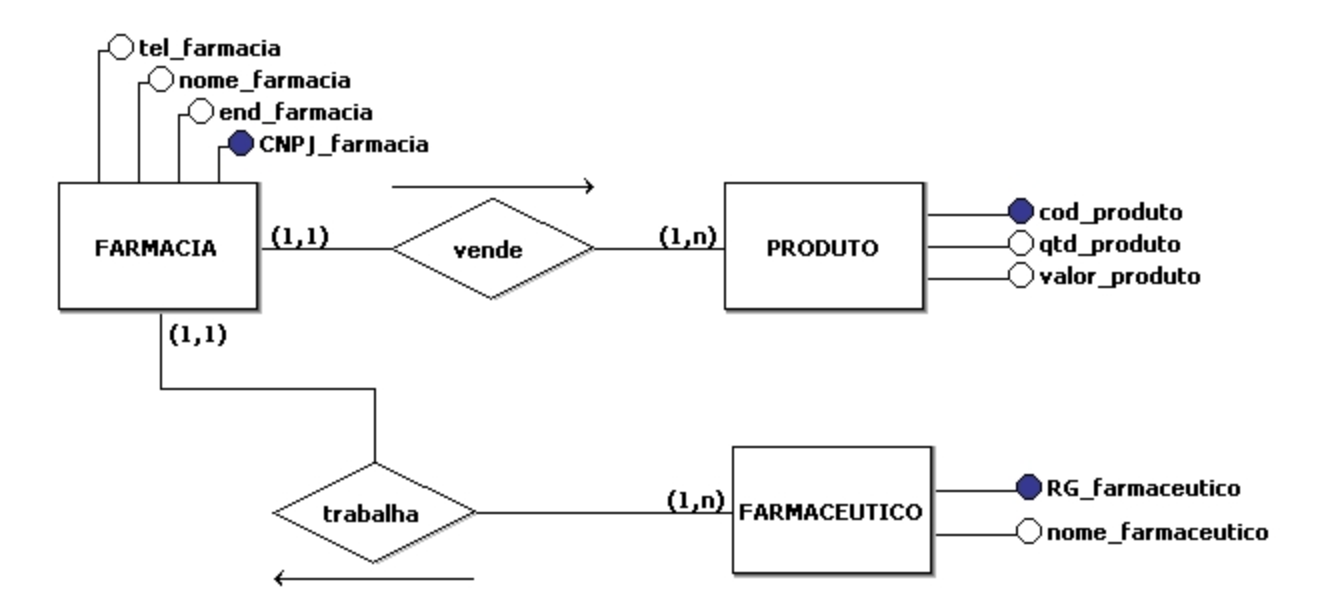
# 摘要
本论文首先概述了药店管理系统的基本结构和功能,接着介绍了UML理论在系统设计中的应用,详细阐述了用例图、类图的设计原则与实践。文章第三章转向系统的开发与实现,涉及开发环境选择、数据库设计、核心功能编码以及系统集成与测试。第四章通过实践案例深入探讨了UML在药店管理系统中的应用,包括序列图、活动图、状态图及组件图的绘制和案例分析。最后,论文对药店管理系统的优化与维护进行了讨论,提
【555定时器全解析】:掌握方波发生器搭建的五大秘籍与实战技巧
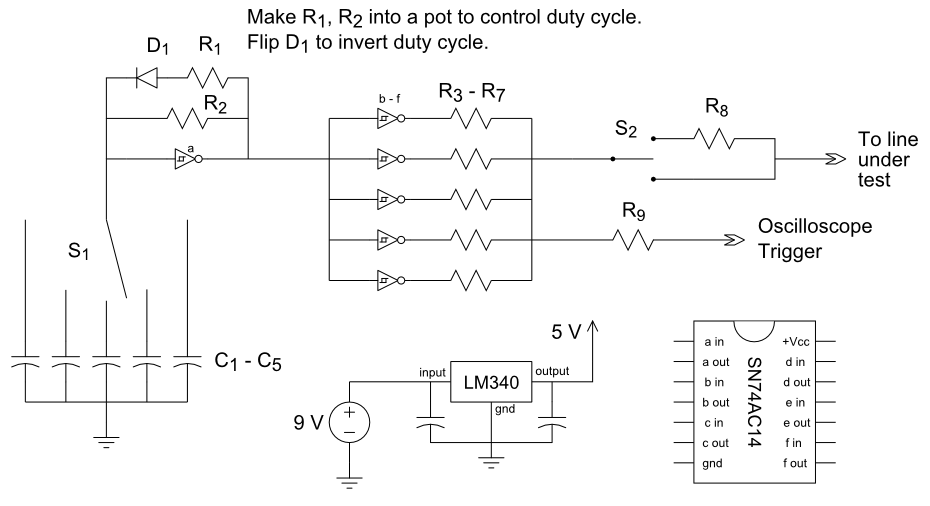
# 摘要
本文详细介绍了555定时器的工作原理、关键参数、电路搭建基础及其在方波发生器、实战应用案例以及高级应用中的具体运用。首先,概述了555定时器的基本功能和工作模式,然后深入探讨了其在方波发生器设计中的应用,包括频率和占空比的控制,以及实际实验技巧。接着,通过多个实战案例,如简易报警器和脉冲发生器的制作,展示了555定时器在日常项目中的多样化运用。最后,分析了555定时器的多用途扩展应用,探讨了其替代技术,
【Allegro Gerber导出深度优化技巧】:提升设计效率与质量的秘诀

# 摘要
本文全面介绍了Allegro Gerber导出技术,阐述了Gerber格式的基础理论,如其历史演化、
Profinet通讯优化:7大策略快速提升1500编码器响应速度
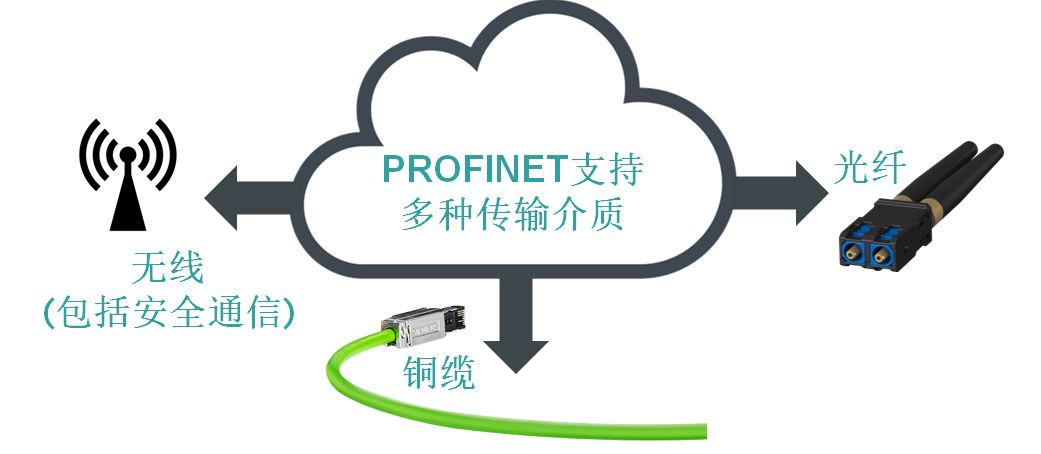
# 摘要
Profinet作为一种工业以太网通讯技术,其通讯性能和编码器的响应速度对工业自动化系统至关重要。本文首先概述了Profinet通讯与编码器响应速度的基础知识,随后深入分析了影响Profinet通讯性能的关键因素,包括网络结构、数据交换模式及编码器配置。通过优化网络和编码器配置,本文提出了一系列提升Profinet通讯性能的实践策略。进一步,本文探讨了利用实时性能监控、网络通讯协议优化以及预
【时间戳转换秘籍】:将S5Time转换为整数的高效算法与陷阱分析

# 摘要
时间戳转换在计算机科学与信息技术领域扮演着重要角色,它涉及到日志分析、系统监控以及跨系统时间同步等多个方面。本文首先介绍了时间戳转换的基本概念和重要性,随后深入探讨了S5Time与整数时间戳的理论基础,包括它们的格式解析、定义以及时间单位对转换算法的影响。本文重点分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )