VSCode调试必学:5分钟速成函数调用与参数传递优化
发布时间: 2024-12-11 20:49:19 阅读量: 2 订阅数: 12 

练习仪表盘:10分钟速成数据可视化达人!

# 1. VSCode调试快速入门
在本章中,我们将快速地了解Visual Studio Code(VSCode)的基本调试功能,并介绍如何设置和启动一个简单的调试会话。VSCode不仅仅是一个源代码编辑器,它还提供了强大的调试工具,这使得开发者能够高效地诊断和解决代码中的问题。
## 1.1 安装与配置调试环境
在开始调试之前,首先需要确保VSCode已安装,并且已经安装了适用于你的编程语言的扩展。例如,如果你是Python开发者,需要安装Python扩展。在VSCode的扩展市场中搜索并安装相应的扩展。
## 1.2 启动调试会话
在VSCode中启动一个调试会话非常简单。只需要在要调试的代码行左侧点击行号旁边的空白区域,就会出现一个红色的断点。通过点击侧边栏中的“运行和调试”按钮(或者按F5),就可以开始调试会话。程序将运行至第一行代码,并在断点处暂停。
## 1.3 调试面板的使用
调试面板是调试过程中的重要组成部分。通过它可以控制程序的执行流程,比如单步进入、单步跳过以及继续执行到下一个断点等。调试面板还会显示调用堆栈、变量、监视表达式等信息,帮助开发者更好地理解程序状态。
以上内容仅为入门级指南,后续章节将深入探讨VSCode的高级调试技巧,包括函数调用机制、参数传递优化以及复杂案例分析等。本章为后续内容奠定了基础,帮助读者快速上手并理解VSCode的调试能力。
# 2. 理解函数调用机制
### 2.1 函数的定义与声明
函数是程序中完成特定任务的代码块。在编程中,函数定义了如何将输入转化为输出。它是一种封装好的、可重复使用的代码块。
#### 2.1.1 函数的基本构成
函数基本构成包括函数名、返回类型、参数列表(可选)以及函数体。下面是一个简单的函数定义示例:
```c
int add(int a, int b) {
return a + b;
}
```
在上述代码中,`add` 是函数名,它表明了函数的功能;`int` 表示返回类型,这里是整数;`a` 和 `b` 是参数列表,它们是输入值;函数体是包含在大括号 `{}` 之间的代码。
#### 2.1.2 参数的传递方式
参数可以按值传递或按引用传递:
- **值传递**: 函数接收参数值的副本,原始数据保持不变。这意味着函数内部的改变不会影响外部的数据。
```c
void foo(int a) {
a = 10; // 这不会影响原始变量
}
```
- **引用传递**: 函数接收实际参数的引用,对参数的任何修改都会反映在原始数据上。
```c
void bar(int &a) {
a = 10; // 这将改变原始变量
}
```
### 2.2 调用栈的原理与应用
#### 2.2.1 调用栈的定义
调用栈是一个用来记录程序中函数调用历史的数据结构。它以栈的形式组织,每次调用函数时,一个新的栈帧(stack frame)会添加到调用栈的顶部。当函数返回时,相应的栈帧从栈顶移除。
#### 2.2.2 调用栈在函数调用中的作用
调用栈负责管理函数调用和返回的顺序,以及局部变量的存储。它使得函数可以在完成任务后返回到调用它们的地方,并能够处理多个函数嵌套调用的情况。
### 2.3 调用序列优化策略
#### 2.3.1 如何减少函数调用开销
减少函数调用开销通常可以通过以下方法实现:
- **内联函数**: 将函数的代码直接嵌入到调用处,减少调用开销。
- **尾递归优化**: 如果函数递归调用自身是最后一个操作,编译器可以优化以避免额外的栈帧开销。
#### 2.3.2 使用尾递归优化
尾递归是一种特殊的递归形式,在递归调用函数自身是函数的最后一个动作时出现。编译器可以优化尾递归以避免使用额外的栈帧。
下面是一个尾递归的示例:
```c++
int factorial(int n, int acc = 1) {
if (n <= 1) return acc;
return factorial(n - 1, acc * n); // 尾递归调用
}
```
在此例中,`factorial` 函数中的递归调用是尾递归。这使得编译器可以进行优化,避免了传统递归可能出现的栈溢出问题。
理解函数调用机制对于编写高效代码至关重要。通过理解调用栈以及如何优化函数调用序列,开发者能够创建更加高效和可维护的程序。在下一章中,我们将深入探讨参数传递的优化策略,以及如何在实际代码中应用这些原理。
# 3. ```
# 第三章:深入参数传递优化
深入探讨参数传递优化,我们需要了解参数传递的基本类型、选择和实践技巧,并掌握在调试中如何定位和解决参数传递问题。本章将详细介绍参数传递的类型与选择,分享优化实践技巧,并讨论如何有效利用VSCode调试工具来解决问题。
## 3.1 参数传递的类型与选择
### 3.1.1 值传递与引用传递的区别
在编程中,参数传递的两种主要类型是值传递(value passing)和引用传递(reference passing)。
- **值传递**:函数接收的是原始值的拷贝,对参数的任何修改都不会影响原始数据。在大多数语言中,基本数据类型如整数、浮点数等默认都是值传递。
- **引用传递**:函数接收的是数据的引用(或指针),对参数的修改将直接影响原始数据。引用传递常见于复杂数据类型,如对象、数组等。
引用传递在传递大量数据时效率更高,因为它避免了数据的复制。然而,这也可能导致代码的副作用,需要谨慎使用。
### 3.1.2 参数传递的性能影响
参数传递的性能影响主要体现在数据拷贝和内存使用上。值传递可能导致大量的数据拷贝,特别是在传递大型结构体或对象时。而对于引用传递,虽然可以避免拷贝,但需要注意引用的生命周期管理,防止悬挂引用或野指针的出现。
在性能敏感的应用中,我们应根据实际情况选择合适的参数传递方式,例如,在需要保护数据不可变性时采用值传递,在性能要求较高时考虑引用传递。
## 3.2 参数传递的实践技巧
### 3.2.1 避免不必要的参数复制
在处理大型数据结构时,我们应该尽量避免不必要的复制。一些常见策略包括:
- **返回新对象**:通过函数返回新的数据对象,而不是在函数内部复制。
- **使用指针或引用**:通过指针或引用传递数据,以减少数据拷贝。
例如,在C++中,可以使用常量引用传递参数以避免复制:
```cpp
void process_data(const vector<int>& data) {
// 处理数据,不修改原始数据
}
```
### 3.2.2 利用引用传递处理大数据
对于大数据对象,显式使用引用传递可以减少内存消耗和性能开销。例如,在Java中,可以使用`ArrayList`而不是数组,因为`ArrayList`是通过引用来操作的:
```java
void process_large_collection(ArrayList<Integer> collection) {
// 处理大数据集合,通过引用操作
}
```
在设计函数接口时,应该明确哪些参数是需要修改的,哪些仅是读取。这样可以更合理地使用引用传递,减少不必要的错误和性能损失。
## 3.3 调试中参数传递问题的定位与解决
### 3.3.1 常见参数传递错误分析
在进行调试时,经常会遇到由于参数传递错误导致的问题,如:
- **数据损坏**:错误地复制数据结构,导致内存损坏。
- **性能瓶颈**:大数据结构的复制导致性能瓶颈。
- **逻辑错误**:错误的引用传递导致了非预期的副作用。
### 3.3.2 使用VSCode调试器解决参数问题
使用VSCode调试器可以帮助我们快速定位和解决参数传递问题。通过设置断点,我们可以检查参数在传递过程中的值和内存地址变化。VSCode提供的监视窗口允许我们实时查看变量值和内存地址。
以下是一些具体的调试步骤:
1. 设置断点,在函数调用前后检查参数值。
2. 使用调用栈窗口来查看函数调用顺序。
3. 使用监视窗口来观察特定变量的值和引用。
4. 分析内存快照来检查是否存在数据损坏或内存泄漏。
通过这样的调试流程,我们可以逐步定位问题所在,并采取措施进行修复。接下来,我们将介绍如何在VSCode中利用断点和其他调试功能来进行更高级的调试工作。
```
# 4. VSCode中的高级调试技巧
## 4.1 断点的高级使用方法
### 4.1.1 条件断点
条件断点是一种高级调试技术,它允许开发者在特定条件满足时才停止执行代码,而不是简单地在某一行代码上设置断点。在VSCode中设置条件断点非常容易,只需右键点击编辑器左侧的行号区域,选择“添加条件断点”,然后输入一个布尔表达式。
例如,在调试一个数组遍历的场景时,你可能只关心当数组长度超过特定值时的情况。那么,你可以设置一个条件断点,当数组长度满足条件时才会触发。下面是如何设置条件断点的一个简单示例:
```javascript
// 假设有一个数组数组 arr,我们要在 arr 的长度达到1000时停止
let arr = new Array(1000).fill(0);
for (let i = 0; i < arr.length; i++) {
// ... 执行一些操作 ...
}
```
在VSCode的行号边栏中,找到你想要设置条件断点的行,右键点击后选择“添加条件断点”,然后输入类似 `arr.length >= 1000` 的条件表达式。现在,只有当这个条件为真时,程序才会在该行暂停执行。
### 4.1.2 日志点与监视点
日志点和监视点是VSCode中的另外两种高级调试工具。日志点允许你在不中断程序执行的情况下记录调试信息,而监视点则允许你监控变量或表达式的值,并在值发生变化时停止程序的执行。
创建日志点的方法和条件断点类似。你需要在代码中的适当位置右键点击并选择“添加日志点”,然后输入你希望记录的信息。日志点会在代码执行到该位置时输出日志信息,但不会使程序停止。
监视点更适用于监视变量或表达式的值的变化。当你怀疑某个变量的值在程序执行过程中被错误地修改时,监视点可以提供帮助。在监视点被触发时,程序会在该点停止执行。
## 4.2 调试视图的深度应用
### 4.2.1 Call Stack窗口的使用
Call Stack(调用栈)窗口在调试过程中显示当前程序的调用栈信息。它可以帮助开发者理解程序执行的上下文,特别是当程序陷入复杂的函数嵌套调用时。
要使用Call Stack窗口,在VSCode的调试视图中找到并点击“调用栈”标签。这会显示出当前执行栈的所有函数调用,你可以点击其中的任一帧来查看该帧的局部变量和表达式的值。
使用Call Stack窗口的一个经典场景是当你遇到异常或者错误调用时,通过查看调用栈可以快速定位到问题发生的源代码位置。调用栈中的每一项都包含一个函数名称和它的源文件位置信息,双击可以跳转到对应的代码行。
### 4.2.2 Watch和Variables窗口技巧
Watch窗口允许开发者监视和评估表达式,而Variables窗口则显示当前作用域的变量列表及其值。这两个窗口是调试过程中理解程序状态的关键工具。
在Watch窗口中,你可以输入任何有效的表达式,并实时观察它的值变化。这对于理解复杂数据结构或在循环和条件语句中跟踪变量的变化特别有用。
Variables窗口则提供了程序当前作用域下所有变量的视图,它自动更新显示当前帧中的变量值。通过Variables窗口,你可以进行变量值的修改操作,这在某些情况下可以用来测试不同的代码路径。
## 4.3 性能分析与调优
### 4.3.1 使用CPU分析工具
VSCode提供了内置的CPU分析工具,这对于定位程序中的性能瓶颈非常有帮助。通过CPU分析,开发者可以看到函数调用的时间花费,找出最耗费CPU资源的部分。
要使用CPU分析工具,你需要首先确保已安装了相应的VSCode扩展,如“Debugger for Chrome”或“Python”等,取决于你所开发的语言。接下来,启动调试会话,并在调试工具栏中点击“开始性能分析”按钮(通常是一个小钟表图标)。VSCode会开始记录CPU使用情况,并在调试结束后提供详细报告。
### 4.3.2 内存泄漏检测与优化
内存泄漏是长时间运行的应用中经常遇到的问题,它会导致程序逐渐消耗掉越来越多的内存资源,最终导致性能下降或程序崩溃。幸运的是,VSCode提供了工具来帮助开发者检测和诊断内存泄漏。
要检测内存泄漏,通常需要对程序进行一系列的内存快照和比较。在VSCode中,你可以使用“JavaScript Heap Diff”扩展来捕获堆内存快照,并比较不同时间点的内存使用情况,找出泄漏的源头。
在内存泄漏的检测和调优过程中,注意观察程序的内存分配和释放模式。查找那些持续增长的内存分配,特别是那些“孤立”的对象,没有其他对象引用它们,但它们的内存没有被释放。找出这些对象并分析为什么它们没有被垃圾回收器正确处理,通常可以揭示内存泄漏的原因。
在分析内存泄漏问题时,VSCode的内存分析工具可能会提供对象引用链的视图,这有助于理解为什么某些对象不能被垃圾回收。通过这个视图,你可以追踪对象之间的引用关系,找到和修复导致内存泄漏的代码部分。
以上内容提供了VSCode中高级调试技巧的详细介绍,包括条件断点和日志点的设置、调用栈和变量监视窗口的深度使用,以及使用VSCode的性能分析工具进行CPU分析和内存泄漏检测的方法。通过这些技巧,开发者可以更高效地诊断和解决程序中的问题,提升代码质量和性能。
# 5. 实际案例分析与技巧总结
## 5.1 复杂项目中的函数调用优化实例
在处理复杂项目时,性能优化是确保应用稳定运行的关键。函数调用作为代码执行的基本单元,优化它们可以带来显著的性能提升。
### 5.1.1 大规模数据处理优化
大数据处理在很多应用中很常见,如机器学习、数据挖掘等。在这些场景中,函数调用的优化策略通常涉及到减少不必要的数据拷贝和内存占用。
```python
def process_large_data(data):
# 使用生成器避免一次性加载大量数据到内存
for chunk in chunks(data, chunk_size=1024):
# 在这里处理每个数据块
yield process_chunk(chunk)
def process_chunk(chunk):
# 这里是处理单个数据块的逻辑
pass
```
在这个例子中,`process_large_data`函数使用了生成器来逐块处理数据,避免了将整个数据集加载到内存中,这对于大规模数据集来说是一个常见的优化技术。
### 5.1.2 API服务的性能调优
API服务的性能调优重点在于减少延迟和提高吞吐量。合理设计函数和处理并发请求可以大幅改善API性能。
```python
from concurrent.futures import ThreadPoolExecutor
def handle_request(request):
# 处理单个请求
pass
def api_service(requests):
with ThreadPoolExecutor(max_workers=10) as executor:
# 分发请求到工作线程池
executor.map(handle_request, requests)
```
使用线程池(如`ThreadPoolExecutor`)可以同时处理多个请求,提高API服务的并发处理能力,减少请求的响应时间。
## 5.2 调试技巧的综合应用
调试技巧在开发过程中起着至关重要的作用,特别是在多线程或并发程序中,正确地应用调试技巧可以快速定位问题。
### 5.2.1 多线程程序的调试策略
在多线程程序中,正确的调试策略是使用条件断点和日志点来监控线程间的状态和交互。
```javascript
// JavaScript 示例代码
function threadFunction() {
while(true) {
// 关键线程操作
console.log('Thread activity');
// 使用条件断点监视特定状态
}
}
// 设置条件断点,当线程条件满足时触发
```
通过条件断点,可以监控到线程何时达到特定的状态,这对于理解线程行为和调试多线程程序中的死锁等问题非常有帮助。
### 5.2.2 异常处理与日志记录的最佳实践
在复杂应用中,异常处理和日志记录是调试和问题追踪的关键部分。
```python
import logging
def some_function():
try:
# 尝试执行可能抛出异常的操作
pass
except Exception as e:
# 记录异常信息
logging.error(f'An error occurred: {e}')
some_function()
```
在上面的Python代码示例中,使用`try-except`块来捕获可能发生的异常,并通过日志记录错误信息,这对于后续问题的诊断和调试至关重要。
## 5.3 快速学习与持续优化的技巧
在IT行业,技术更新迅速,快速学习新技术和持续优化现有知识是保持竞争力的重要手段。
### 5.3.1 快速掌握新工具的方法
快速学习一个新工具通常包括三个步骤:理解其基本使用、阅读官方文档和实践案例。
```markdown
1. 了解新工具的基本使用方法。
2. 阅读官方文档,掌握工具的高级功能和最佳实践。
3. 实践应用:尝试解决实际问题,通过实践加深理解。
```
通过这个过程,即使是最复杂的工具,也可以在短时间内达到熟练使用。
### 5.3.2 代码审查与团队协作中的调试技巧
代码审查是保证代码质量的重要环节。在团队协作中,使用调试技巧来辅助代码审查可以提高审查的效率和效果。
```markdown
- 使用代码审查工具(如Gerrit或GitHub Pull Requests)来标注问题。
- 在审查中,提出改进建议,而不是仅仅指出错误。
- 分享调试经验,帮助团队成员提高调试能力。
```
代码审查的过程不仅要找出问题,更重要的是分享知识和改进团队的整体技术水平。
在这一章节中,通过实例分析,我们学习了复杂项目中函数调用优化的实际应用,调试技巧在多线程和异常处理中的应用,以及快速学习和优化代码的策略。这些内容不仅适用于有经验的开发者,同样能够为初学者提供指导。接下来,我们将在下一章中深入探讨性能分析与调优的高级主题。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
VSCode 专栏深入探讨了函数调用和参数传递,提供了一系列全面的指南和技巧。它涵盖了从基础知识到高级应用的各个方面,旨在帮助开发者掌握 VSCode 中这些关键概念。专栏包含专家建议、实用技巧、常见陷阱分析和性能优化策略,使开发者能够提升代码效率、避免错误,并优化函数调用和参数传递。此外,它还提供了案例分析和实战宝典,帮助开发者在实际项目中应用这些技巧,提升代码质量和开发效率。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Zynq裸机LWIP初始化基础】:一步步带你入门网络配置

# 摘要
本论文旨在探讨Zynq硬件平台与LWIP协议栈的集成与配置,以及在此基础上进行的进阶网络应用开发。文章首先介绍了Zynq硬件和网络配置的基本概念,随后深入解析了LWIP协议栈的起源、特点及其在嵌入式系统中的作用。接着,详细阐述了LWIP协议栈的安装、结构组件以及如何在Zynq平台上进行有效配置。在交互基础方面,文章讲述了Zynq平台网络接口的初始化、LWIP网络接口的设置和网络事件的处理。随后,通过LWIP初始
金蝶云星空实施要点:项目管理与执行策略,一步到位!
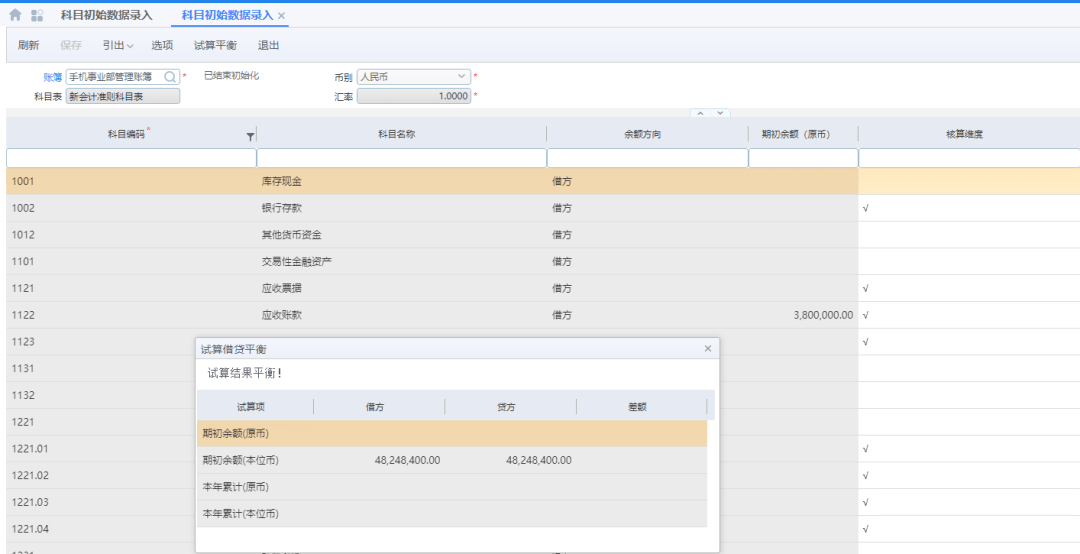
# 摘要
本文系统地介绍了金蝶云星空的概述、核心价值、项目管理策略、实施准备工作、执行过程中的策略、项目监控与评估,以及未来的发展展望与优化措施。通过对项目管理理论基础的深入探讨,包括项目管理的基本概念、方法论、以及风险管理策略,本文揭示了金蝶云星空项目管理的独特性及其在实施准备阶段和执行过程中的关键执行策略。同时,文章详细说明了如何通过项目监控和评估来确保项目成功,并对金蝶云星空的未来发展趋势进行
非接触卡片性能提升:APDU指令调优的六大策略

# 摘要
本文系统探讨了APDU指令的基础知识、性能优化理论、以及调优实践。首先概述了APDU指令的结构和通信流程,并强调了性能优化的理论原则。随后,本文深入讨论了指令集的精简与重构、缓存与批处理策略、多线程与异步处理
STAR CCM+流道抽取案例分析:复杂流道挑战的7种解决方案
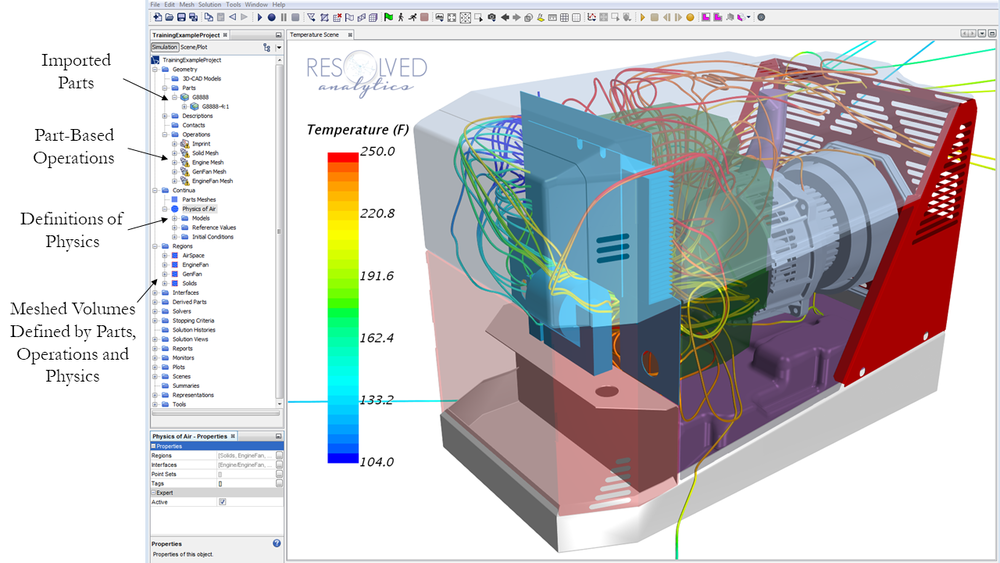
# 摘要
本论文首先介绍了STAR CCM+软件在流道分析中的基础应用,探讨了流体力学理论在流道设计中的关键作用以及数值分析方法在流道抽取中的重要性。随后,通过实际案例分析了STAR CCM+软件在创建基本流道模型、网格划分优化、结果评估与优化策略中的技
国产安路FPGA PH1A芯片散热解决方案:热设计的黄金法则
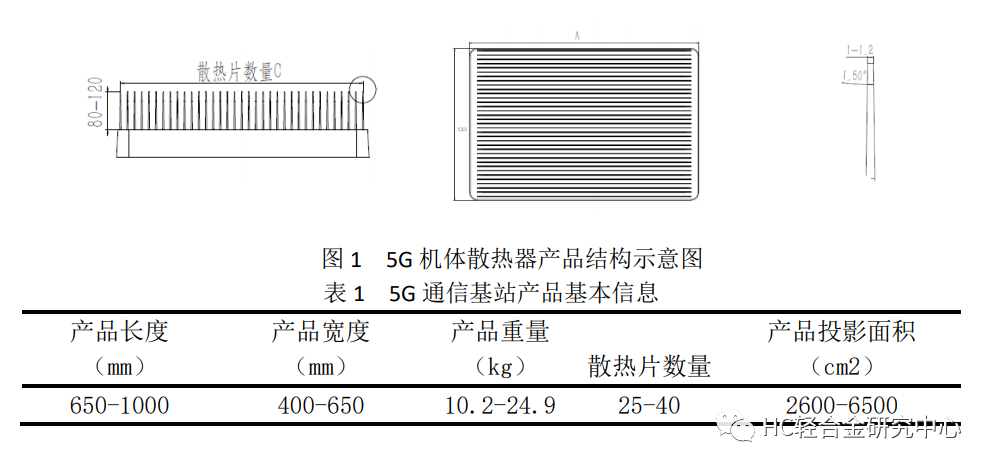
# 摘要
国产安路FPGA PH1A芯片作为一款先进的集成电路产品,在性能提升的同时,散热问题成为设计与应用过程中的关键挑战。本文首先概述了该芯片的基本情况,随后从理论和实践两个层面深入探讨了FPGA PH1A芯片的散热问题。文章详细分析了散热的基本原理、散热材料特性、热设计的重要性及其影响因素,并提供了散热实践指南,包括散热器选择、空气与液冷系统的实施及高效能散热技术应用。
【通讯效率提升攻略】:提升昆仑通态触摸屏与PLC通讯的4大策略

# 摘要
本文探讨了昆仑通态触摸屏与PLC通讯的基础知识和提升通讯效率的策略。首先介绍硬件连接优化,重点在于触摸屏与PLC接口类型的匹配、通讯线缆及接口的选择标准,并提供硬件布线的最佳实践和抗干扰措施。接着,本文分析了软件通讯参数配置的重要性,涵盖触摸屏和PLC端口的设置与优化。此外,文章详述了通讯故障的诊断方法和故障类型,以及如何使用监控工具进行通讯效率的监控和瓶颈定位。最后,
【代码复用,模块化开发】:微信小程序组件化提升效率与维护性的秘诀
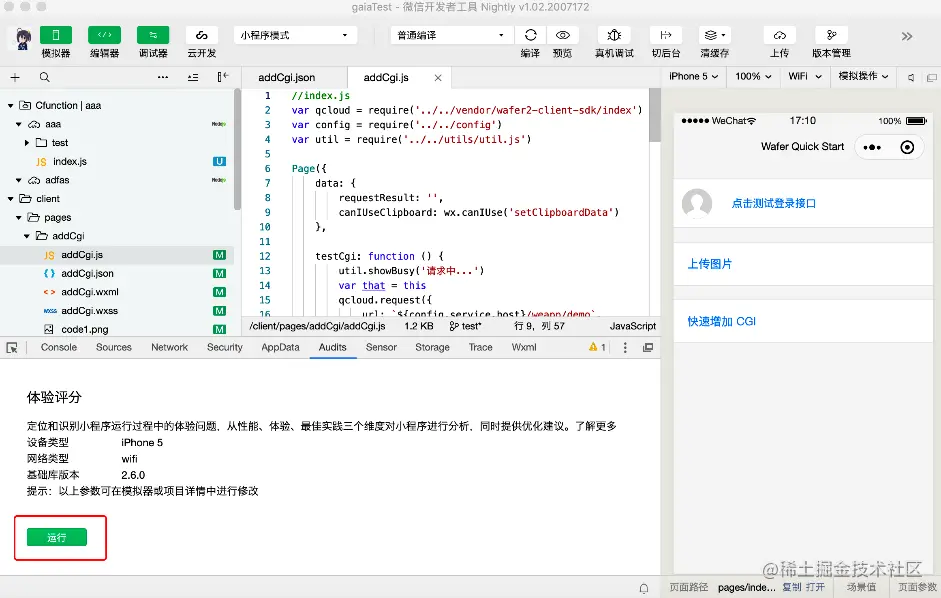
# 摘要
微信小程序组件化的概念及其优势是提升开发效率和维护性的重要方法。本文详细阐述了微信小程序的组件化架构,包括组件的定义、分类、组件间通信机制,以及组件的生命周期和性能优化。通过实践指南,本文指导读者如何创建自定义组件、实现组件的复用和管理,以及如何进行组件集成与测试。深入探索组件
平面口径天线增益计算:掌握这7步,提升天线性能不再难
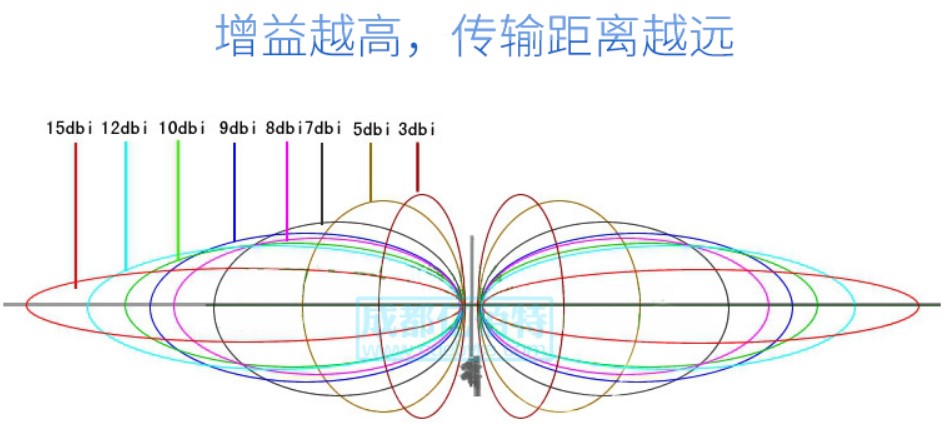
# 摘要
本文系统地探讨了平面口径天线增益的计算基础、理论解析及计算步骤。首先介绍了天线增益的基本概念、重要性以及影响信号传播的因素。然后,详细分析了天线辐射模式与增益的关联性,包括主瓣宽度、旁瓣水平与不同辐射模式下增益的特性。接下来,本文阐述了天线模型建立、数学模型与仿真计算方法,并通过实际测量数据验证计算结果的准确性。最后,文章提出了增益提升策略,分析了天线设计优化技巧及其在实际案例中
CST816D电源管理详解:一次性解决微控制器电源规格疑惑

# 摘要
CST816D电源管理涉及对设备供电系统的深入理解和优化控制。本文首先概述了CST816D的电源管理功能,然后对电源规格进行了详细解析,包括电压和电流要求、管理模块功能以及硬件接口的布局设计。文章进一步通过实践案例,提供电源设计布局建议,探索电源管理软件应用,并讨论了故障排查与性能优化策略。在高级应用部分,本文研究了动态电源调节技术,探讨了电源管理在物
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )