Mycat 分库分表入门指南
发布时间: 2024-01-20 21:49:31 阅读量: 35 订阅数: 37 

mycat 分库分表
# 1. 什么是Mycat?
## 1.1 Mycat的概念和作用
Mycat是一个开源的数据库中间件,它基于MySQL协议,可以实现分库分表、读写分离等功能。它的主要作用是提供高性能和高可用的数据库访问服务,同时也简化了数据库架构的设计和管理。
Mycat通过将数据库中的数据水平划分成若干个库和表,将其分散存储在不同的物理服务器上,实现了数据的分布式存储和查询。它还可以根据业务需求,将读写操作分离到不同的服务器上,提高了数据库的并发处理能力。
## 1.2 Mycat的优势和特点
Mycat具有以下几个优势和特点:
- **高性能:** Mycat采用了多线程的方式处理数据库请求,并且使用了连接池和缓存等技术,提高了数据库的读写性能。
- **高可用:** Mycat支持主从复制和多节点部署,可以实现数据库的高可用性,在单个节点出现故障时,能够自动切换到备用节点,确保系统的持续可用性。
- **分布式存储:** Mycat支持水平分库分表,可以将数据分散存储在不同的物理节点上,提高了数据库的扩展性和负载均衡能力。
- **读写分离:** Mycat可以将读操作和写操作分离到不同的服务器上,提高了数据库的并发处理能力。
- **简化运维:** Mycat提供了简单易用的管理界面,可以方便地进行数据库的配置和管理,减少了运维工作的复杂性。
下面,我们将详细介绍Mycat的安装与配置。
# 2. Mycat的安装与配置
### 2.1 安装Mycat的准备工作
在安装Mycat之前,需要准备以下工作:
1. Java JDK的安装和配置,确保系统中已经安装了Java开发环境。
2. MySQL数据库,作为Mycat的后端存储数据库,需要提前安装好并启动。
3. 操作系统的选择,Mycat可支持Windows、Linux等多种操作系统,选择适合自己的操作系统进行安装。
### 2.2 Mycat的安装步骤
按照以下步骤安装Mycat:
1. 下载Mycat安装包,可以从Mycat官网(http://www.mycat.io)或者其他可靠的下载站点获取最新版本的Mycat安装包。
2. 解压Mycat安装包到指定目录,例如解压到`/opt/mycat/`。
3. 进入Mycat安装目录,修改`conf`目录下的`server.xml`文件,根据自己数据库的情况配置Mycat的参数,例如设置MySQL的连接地址、端口号、用户名、密码等。
4. 在Mycat安装目录下执行启动命令,例如在Linux下执行`./bin/mycat start`,在Windows下执行`bin\mycat.exe start`。
5. 使用数据库客户端连接到Mycat并进行测试,确保能够正常访问数据库。
### 2.3 Mycat的配置与参数说明
Mycat的配置主要在`conf`目录下的`server.xml`文件中进行,以下是一些常用配置参数的说明:
- `<user>`:用于配置Mycat的用户信息,包括用户名、密码、权限等。
- `<dataHost>`:用于配置后端MySQL数据库的连接信息,包括连接地址、端口号、最大连接数等。
- `<dataNode>`:用于配置数据库的分库分表策略,包括数据库的名称、表的数量、分片规则等。
- `<rule>`:用于配置Mycat的路由规则和负载均衡策略,可以根据需要设置不同的规则和策略。
除了配置文件之外,Mycat还提供了一些运行时参数,可以通过命令行参数或者在配置文件中进行配置。
以上是Mycat的安装与配置的基本步骤和参数说明,接下来我们将介绍Mycat的基本使用。
# 3. Mycat的基本使用
#### 3.1 连接Mycat数据库
Mycat作为一个中间件,用于连接应用程序与真实数据库之间,因此我们首先需要连接Mycat数据库。
在应用程序中,我们可以使用标准的JDBC连接来连接Mycat数据库。以下是Java代码示例:
```java
import java.sql.*;
public class MycatConnectionExample {
public static void main(String[] args){
String url = "jdbc:mysql://localhost:8066/testdb";
String user = "root";
String password = "password";
Connection connection = null;
try {
connection = DriverManager.getConnection(url, user, password);
System.out.println("成功连接到Mycat数据库!");
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
```
上述代码中,url就是连接Mycat数据库的URL,其中localhost表示Mycat所在的主机地址,8066表示Mycat的连接端口,testdb是要连接的数据库名。user和password分别表示Mycat的登录名和密码。
#### 3.2 基本的SQL语句操作
一旦我们连接到Mycat数据库,就可以执行SQL语句来操作数据了。Mycat支持大部分标准的SQL语法,包括查询、插入、修改和删除等操作。
以下是Java代码示例,演示如何执行基本的SQL语句:
```java
import java.sql.*;
public class MycatSQLExample {
public static void main(String[] args) {
String url = "jdbc:mysql://localhost:8066/testdb";
String user = "root";
String password = "password";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = DriverManager.getConnection(url, user, password);
statement = connection.createStatement();
// 查询数据
String querySql = "SELECT * FROM users";
resultSet = statement.executeQuery(querySql);
while (resultSet.next()) {
String username = resultSet.getString("username");
String email = resultSet.getString("email");
System.out.println("Username: " + username + ", Email: " + email);
}
// 插入数据
String insertSql = "INSERT INTO users (username, email) VALUES ('admin', 'admin@example.com')";
int rowsInserted = statement.executeUpdate(insertSql);
if (rowsInserted > 0) {
System.out.println("插入成功!");
}
// 更新数据
String updateSql = "UPDATE users SET email = 'newemail@example.com' WHERE username = 'admin'";
int rowsUpdated = statement.executeUpdate(updateSql);
if (rowsUpdated > 0) {
System.out.println("更新成功!");
}
// 删除数据
String deleteSql = "DELETE FROM users WHERE username = 'admin'";
int rowsDeleted = statement.executeUpdate(deleteSql);
if (rowsDeleted > 0) {
System.out.println("删除成功!");
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (resultSet != null) {
try {
resultSet.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (SQLException e) {
e.printStackTrace();
}
}
}
}
}
```
上述代码中,首先我们创建了一个Statement对象,用于执行SQL语句。然后,我们可以使用executeQuery方法执行查询操作,使用executeUpdate方法执行插入、更新和删除等操作。
#### 3.3 Mycat的常见命令与操作
除了使用SQL语句操作Mycat数据库外,Mycat还提供了一些常见的命令和操作,用于管理和维护Mycat服务器。
- **启动Mycat服务器**:使用命令`./mycat start`可以启动Mycat服务器。
- **停止Mycat服务器**:使用命令`./mycat stop`可以停止Mycat服务器。
- **重启Mycat服务器**:使用命令`./mycat restart`可以重启Mycat服务器。
- **查看Mycat服务器状态**:使用命令`./mycat status`可以查看Mycat服务器的当前状态。
- **配置Mycat服务器**:Mycat的配置文件位于Mycat安装目录下的conf文件夹中,可以通过编辑该文件来配置Mycat服务器的参数和规则。
- **监控Mycat服务器**:可以通过Mycat的监控平台来监控和管理Mycat服务器的运行状态和性能指标。
- **查看Mycat服务器日志**:Mycat的日志文件位于Mycat安装目录下的logs文件夹中,可以通过查看日志文件来排查和解决问题。
以上是一些常见的Mycat命令和操作,通过它们可以方便地管理和调整Mycat服务器的运行。
# 4. Mycat的分库分表策略
### 4.1 分库分表的概念与原理
在传统的单库单表架构下,随着业务数据的不断增长,数据库的性能和扩展性成为了瓶颈。而采用分库分表的策略可以有效地解决这些问题。分库指将数据按照一定的规则分散到多个数据库实例中,而分表则是将数据按照一定的规则分散到多个表中。通过将数据进行分散存储,可以降低单个数据库的负载和数据量,提高系统的可扩展性和性能。
分库分表的原理主要涉及两个关键技术:哈希算法和映射规则。哈希算法用于将数据进行分散存储,通过对数据的某个唯一标识进行哈希运算,得到一个哈希值,根据哈希值来确定数据存储的位置。映射规则则定义了数据分割的方法,可以根据业务需求进行灵活的配置,比如按照用户ID进行分表。
### 4.2 Mycat中的分库分表实现方式
Mycat作为一个开源的分布式数据库系统,提供了多种分库分表的实现方式。以下介绍了几种常用的方式:
#### 4.2.1 静态配置分库分表
静态配置分库分表是一种最简单的方式,通过在Mycat的配置文件中静态地指定数据库和表的划分规则。例如,可以设置数据根据用户ID的哈希值进行分库,根据创建时间进行分表。
示例配置:
```xml
<schema name="mycat_test">
<table name="user" dataNode="dn1,dn2,dn3">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</table>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1"/>
<dataNode name="dn2" dataHost="localhost2" database="db2"/>
<dataNode name="dn3" dataHost="localhost3" database="db3"/>
```
#### 4.2.2 动态配置分库分表
动态配置分库分表是一种更加灵活的方式,通过在业务逻辑中动态地指定数据库和表的划分规则。Mycat提供了一些特殊的SQL语句来进行动态配置,比如`/*!mycat:datanode db=dna1*/`和`/*!mycat:catlet=io.mycat.catlets.ShareJoinTableRouteEntrys */`等。
示例代码:
```java
// 设置数据源路由
// 根据用户ID的哈希值选择数据源
String sql = "/*!mycat:datanode db=dna1*/ select * from user where user_id = ?";
PreparedStatement ps = conn.prepareStatement(sql);
ps.setInt(1, userId);
ResultSet rs = ps.executeQuery();
```
#### 4.2.3 分片规则插件
Mycat还支持通过插件来实现分库分表的规则。通过编写自定义的插件,可以根据业务需求自定义分片规则和逻辑。这种方式可以更好地适应特定的业务场景。
示例代码:
```java
// 自定义分片规则插件
public class MyShardingRulePlugin extends ShardingRulePlugin {
@Override
public void init(MycatConfig conf) {
// 初始化配置
}
@Override
public boolean sqlExecutePrepare(String schema, boolean autocommit, ShardingProcessor processor) {
// 自定义分片规则的逻辑
// 根据特定业务需求进行分库分表
return super.sqlExecutePrepare(schema, autocommit, processor);
}
}
// 在Mycat的配置文件中添加插件配置
<mycat:schema name="mycat_test">
<table name="user" dataNode="dn1,dn2,dn3" rule="shardingRulePlugin">
...
</table>
</mycat:schema>
<mycat:rule type="shardingRulePlugin">
<property name="pluginClass" value="com.example.MyShardingRulePlugin" />
</mycat:rule>
```
### 4.3 分库分表的最佳实践
在实际应用中,分库分表需要根据具体的业务场景和需求进行设计和调优。以下是一些分库分表的最佳实践:
- 合理选择分片字段:选择合适的字段作为分片字段,确保分片均匀,避免热点数据倾斜和扩展困难。
- 设计合适的分片规则:根据业务需求,设计合适的分片规则,保证数据的一致性和查询的效率。
- 考虑水平扩展和容灾能力:分库分表可以将数据分散到多个节点上,提高系统的可扩展性和容灾能力。
- 配置合理的数据路由策略:根据实际的业务负载和数据分布情况,选择合适的数据路由策略,保证查询性能和可用性。
通过合理的设计和配置,可以充分发挥分库分表的优势,提升系统的性能和扩展能力。
以上是关于Mycat的分库分表策略的介绍,希望对你有所帮助!
# 5. Mycat的高可用与性能优化
### 5.1 Mycat的高可用架构介绍
- **背景介绍**
在分布式系统中,高可用性是一个重要的考虑因素。Mycat作为一个分布式数据库中间件,也需要具备高可用性来保障系统的稳定运行。Mycat提供了多种高可用架构方案,可以根据实际需求选择适合的方案。
- **常用的高可用架构方案**
1. 主备模式:通过一个主节点和一个备节点的方式实现高可用。主节点负责提供服务,备节点通过复制主节点的数据来保持与主节点的数据一致性,当主节点出现故障时,备节点会自动接管服务。这种方案简单可靠,但是备节点的数据可能不及时同步,造成数据的丢失或不一致。
2. 多主模式:通过多个主节点来提供高可用服务。每个主节点都独立提供服务,并通过复制机制来保持数据一致性。当某个主节点出现故障时,其他主节点可以继续提供服务。这种方案可以提高整体的系统吞吐量,但是需要注意数据的一致性和同步的问题。
3. 分布式模式:将数据分布到多个节点上,每个节点都可以提供独立的服务。通过数据分片和分片映射规则来实现数据的均衡分布和路由。这种方案可以提高系统的并发性能和扩展性,但是需要考虑数据的一致性和容错性。
- **高可用架构的选择**
选择适合的高可用架构方案,需要综合考虑系统的需求、数据的一致性要求、系统的稳定性和可扩展性等因素。在实际应用中,可以根据具体场景选择适合的高可用架构。
### 5.2 Mycat的性能优化与调优技巧
- **通过优化SQL语句来提升性能**
- 合理设计SQL语句,避免使用复杂的子查询或多层嵌套查询,可以将复杂的查询拆分为多个简单的查询,减少查询的复杂度。
- 学会使用索引,合理创建索引可以加速查询的速度。根据查询的特点选择合适的索引,同时避免过多的索引影响性能。
- 避免全表扫描,尽量使用条件查询,可以有效减少查询的数据量,提升查询效率。
- **调整Mycat的配置参数优化性能**
- 调整连接池的大小,可以根据实际并发情况调整最大连接数和最小连接数,以提升数据库的并发处理能力。
- 合理设置缓存大小,根据实际内存情况调整缓存大小,避免频繁的IO操作,提升查询的性能。
- 调整日志级别,只保留必要的日志信息,减少日志的输出量,可以提升系统的性能。
- **使用性能监控工具进行性能分析**
- 使用性能监控工具可以实时监控系统的性能指标,包括CPU使用率、内存使用率、网络流量等,可以及时发现性能瓶颈和问题,做出相应的优化调整。
- 在性能监控中,可以通过查看慢查询日志和数据库执行计划等信息,针对性的进行性能优化,提升系统的响应速度和吞吐量。
### 5.3 Mycat集群的部署和管理
- **Mycat集群的部署**
1. 架设多个Mycat节点:根据实际业务需要,可以部署多个Mycat节点来提供服务。每个Mycat节点都独立运行,通过配置合适的路由规则和分片映射,可以均衡地将请求分发到不同的节点上。
2. 使用负载均衡工具:在Mycat节点前面可以部署负载均衡工具,如Nginx、HAProxy等,将客户端的请求分发到多个Mycat节点上,提高系统的并发处理能力和可靠性。
- **Mycat集群的管理**
1. 监控集群的运行状态:定期监控Mycat集群的运行状态,包括连接数、数据读写情况、错误日志等,及时发现异常情况并进行处理。
2. 备份和恢复数据:定期备份Mycat集群中的数据,保证数据的安全性。在出现问题时,可以通过备份数据来恢复系统的运行。
3. 扩展集群的容量:根据实际业务需求,可以根据需要增加Mycat节点来提升系统的扩展性和性能。在扩展过程中需要注意数据同步和路由规则的调整。
希望以上内容对你有所帮助,希望你的文章写作顺利!
# 6. Mycat与业务实践
### 6.1 如何在业务中应用Mycat
Mycat是一个强大的数据库中间件,可以实现数据库的分库分表、读写分离等功能。在实际的业务场景中,我们可以通过以下步骤来应用Mycat:
1. **需求分析**:首先,我们需要对业务的数据库需求进行分析,判断是否需要进行分库分表或者读写分离的优化。
2. **架构设计**:根据需求分析的结果,设计Mycat的架构。考虑数据库的分片策略、读写分离策略以及高可用性的要求等。
3. **安装部署**:根据Mycat的安装与配置章节,完成Mycat的安装和部署工作。确保Mycat的配置文件中包含正确的数据库连接信息和相关参数设置。
4. **数据迁移**:如果需要进行分库分表,需要将业务数据迁移到分片数据库中。可以使用Mycat提供的数据导入工具或者自行编写脚本完成数据的迁移工作。
5. **代码适配**:根据业务的需求,对应用代码进行适配,使其能够与Mycat进行交互。可以通过配置数据源、调整SQL语句等方式实现。
6. **性能测试**:在应用上线之前,进行性能测试以验证Mycat的效果。可以通过模拟用户请求、压力测试等手段对系统进行测试,并进行性能调优。
7. **上线运维**:当系统经过测试无误后,可以将应用上线。在上线过程中,需注意监控Mycat的运行状态,及时处理异常情况,并进行日常的运维维护工作。
### 6.2 案例分析:Mycat在分库分表场景中的应用
我们以一个电商平台为例,介绍Mycat在分库分表场景中的应用。
**场景描述**:电商平台的用户量日益增加,原有的单库结构已经无法满足业务需求。为了提高系统的性能和可扩展性,决定对订单表进行分库分表。
**步骤**:
1. 需求分析:根据订单表的数据量和访问频率,决定将订单表按照订单ID进行分库分表。
2. 架构设计:选择分库分表策略,例如按照订单ID的哈希值将数据分散到多个数据库中。
3. 安装部署:在每个数据库中创建相应的表结构,配置Mycat的数据分片规则和路由规则。
4. 数据迁移:将原有的订单数据根据分库分表策略进行迁移,保证数据的一致性。
5. 代码适配:修改应用代码中的数据库连接信息和SQL语句,实现与Mycat的交互。
6. 性能测试:通过模拟用户请求和压力测试,验证系统的性能以及分库分表策略的有效性。
7. 上线运维:将应用上线,并监控Mycat的运行状态,及时处理异常情况。
### 6.3 Mycat的未来发展趋势和展望
Mycat作为一个开源的数据库中间件,具有强大的功能和广泛的应用场景。随着大数据、云计算等技术的快速发展,Mycat在未来有以下几个发展趋势和展望:
1. **更加完善的功能**:Mycat将继续开发和完善自身的功能,如支持更多数据库类型、更灵活的分库分表策略等,以满足不同行业和应用的需求。
2. **更高的性能和可扩展性**:Mycat将不断进行性能优化和调优,提高系统的稳定性和并发能力,以满足高并发场景下的需求。
3. **更广泛的应用场景**:随着云计算和大数据的普及,Mycat将在更多领域得到应用,如物联网、金融、电商等,为业务提供可靠的数据库中间件支持。
4. **更加友好的用户体验**:Mycat将进一步改进用户界面,提供更加友好和易用的管理工具,简化操作流程,降低使用门槛。
总之,Mycat作为一个强大的数据库中间件,在未来的发展中将继续发挥其巨大的潜力,为企业和开发者提供更好的数据库解决方案。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据库中间件Mycat 分库分表实操落地》专栏深入探讨了Mycat数据库中间件在分库分表实践中的应用。从入门指南、安装配置、数据分片策略到分布式事务处理、数据迁移同步、高可用架构等方面展开详尽讲解。同时,还包括了数据访问流程与调优、性能监控与调优、安全管理与访问控制、读写分离配置与优化、分布式锁与并发控制、SQL优化与执行计划分析、实时数据处理与流式计算、分布式数据库设计与实现、数据存储引擎选择与比较、大数据存储与分析方案以及网络安全与数据加密等内容。本专栏将帮助读者全面掌握Mycat数据库中间件的应用,从而在实际项目中能够更好地实施分库分表的解决方案,提升数据库系统的处理能力和安全性,实现数据存储与分析的高效应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
USB 3.0 vs USB 2.0:揭秘性能提升背后的10大数据真相

# 摘要
USB 3.0相较于USB 2.0在技术标准和理论性能上均有显著提升。本文首先对比了USB 3.0与USB 2.0的技术标准,接着深入分析了接口标准的演进、数据传输速率的理论极限和兼容性问题。硬件真相一章揭示了USB 3.0在硬件结构、数据传输协议优化方面的差异,并通过实测数据与案例展示了其在不同应用场景中的性能表现。最后一章探讨了US
定位算法革命:Chan氏算法与其他算法的全面比较研究
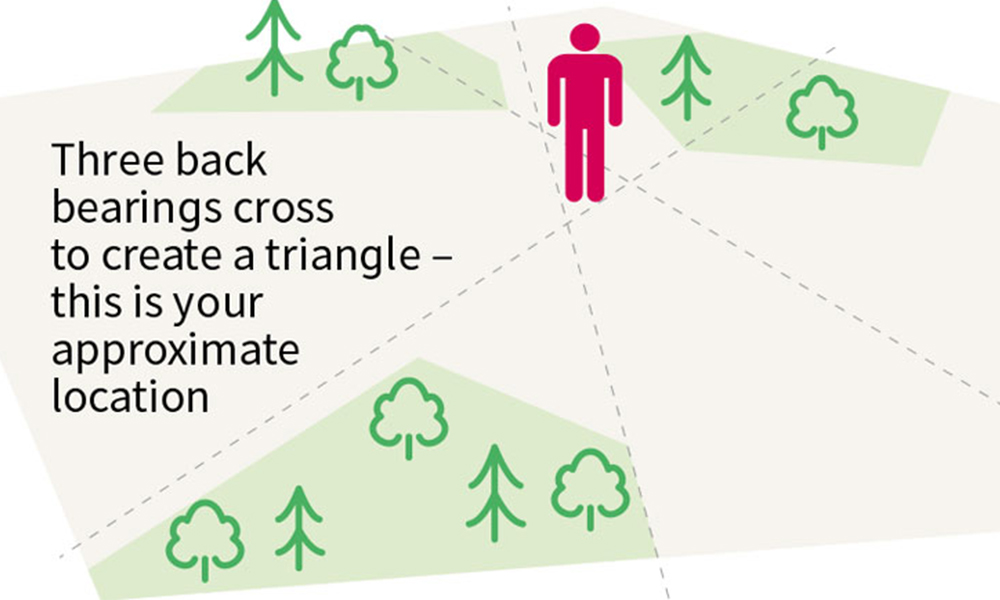
# 摘要
本文对定位算法进行了全面概述,特别强调了Chan氏算法的重要性、理论基础和实现。通过比较Chan氏算法与传统算法,本文分析了其在不同应用场景下的性能表现和适用性。在此基础上,进一步探讨了Chan氏算法的优化与扩展,包括现代改进方法及在新环境下的适应性。本文还通过实
【电力系统仿真实战手册】:ETAP软件的高级技巧与优化策略
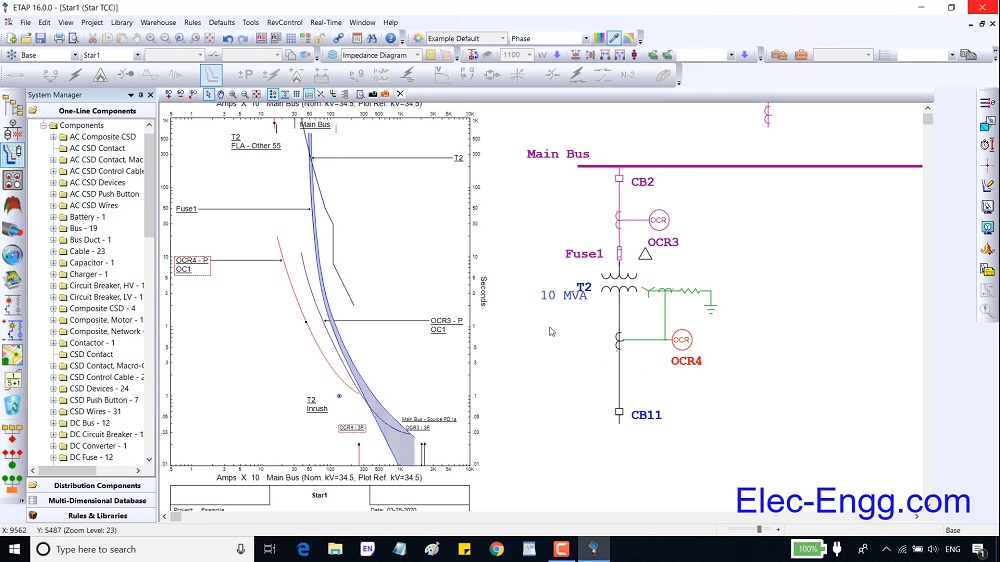
# 摘要
ETAP软件作为一种电力系统分析与设计工具,在现代电力工程中扮演着至关重要的角色。本文第一章对ETAP软件进行了概述,并介绍了其基础设置。第二章深入探讨了高级建模技巧,包括系统建模与分析的基础,复杂系统模型的创建,以及高级模拟技术的应用。第三章着重于ETAP软件的优化策略与性能提升,涵盖仿真参数优化,硬件加速与分布式计算,以及资源管理与仿真瓶颈分析。第四章
模拟精度的保障:GH Bladed 模型校准关键步骤全解析
# 摘要
GH Bladed模型校准是确保风力发电项目设计和运营效率的关键环节。本文首先概述了GH Bladed模型校准的概念及其在软件环境
故障不再怕:新代数控API接口故障诊断与排除宝典

# 摘要
本文针对数控API接口的开发、维护和故障诊断提供了一套全面的指导和实践技巧。在故障诊断理论部分,文章详细介绍了故障的定义、分类以及诊断的基本原则和分析方法,并强调了排除故障的策略。在实践技巧章节,文章着重于接口性能监控、日志分析以及具体的故障排除步骤。通过真实案例的剖析,文章展现了故障诊断过程的详细步骤,并分析了故障排除成功的关键因素。最后,本文还探讨了数控API接口的维护、升级、自动化测试以及安全合规性要求和防护措
Java商品入库批处理:代码效率提升的6个黄金法则

# 摘要
本文详细探讨了Java商品入库批处理中代码效率优化的理论与实践方法。首先阐述了Java批处理基础与代码效率提升的重要性,涉及代码优化理念、垃圾回收机制以及多线程与并发编程的基础知识。其次,实践部分着重介绍了集合框架的运用、I/O操作性能优化、SQL执行计划调优等实际技术。在高级性能优化章节中,本文进一步深入到JVM调优、框架与中间件的选择及集成,以及
QPSK调制解调误差控制:全面的分析与纠正策略
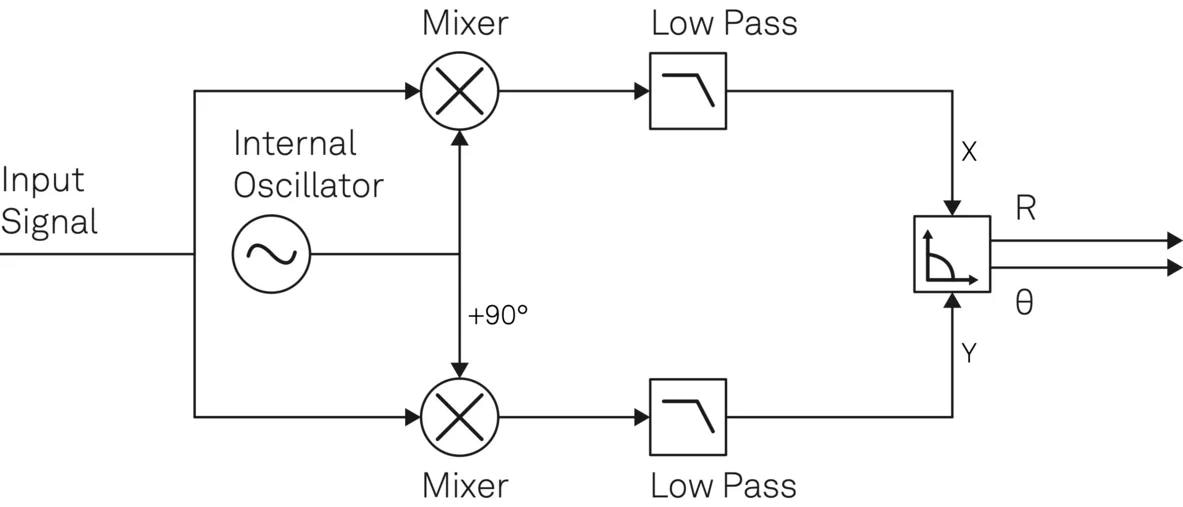
# 摘要
本文全面概述了QPSK(Quadrature Phase Shift Keying)调制解调技术,从基础理论到实践应用进行了详尽的探讨。首先,介绍了QPSK的基础理论和数学模型,探讨了影响其性能的关键因素,如噪声和信道失真,并深入分析了QPSK的误差理论。其次,通过实验环境的配置和误差的测量,对QPSK调制解调误差进行了实践分析
提升SiL性能:5大策略优化开源软件使用

# 摘要
本文针对SiL性能优化进行了系统性的研究和探讨。首先概述了SiL性能优化的重要性,并引入了性能分析与诊断的相关工具和技术。随后,文章深入到代码层面,探讨了算法优化、代码重构以及并发与异步处理的策略。在系统与环境优化方面,提出了资源管理和环境配置的调整方法,并探讨了硬件加速与扩展的实施策略。最后,本文介绍了性能监控与维护的最佳实践,包括持续监控、定期调优以及性能问题的预防和解决。通过这些方
透视与平行:Catia投影模式对比分析与最佳实践

# 摘要
本文对Catia软件中的投影模式进行了全面的探讨,首先概述了投影模式的基本概念及其在设计中的作用,其次通过比较透视与平行投影模式,分析了它们在Catia软件中的设置、应用和性能差异。文章还介绍了投影模式选择与应用的最佳实践技巧,以及高级投影技巧对设计效果的增强。最后,通过案例研究,深入分析了透视与平行投影模式在工业设计、建筑设计
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )