【深度学习盲点】:揭秘模型解释性障碍,打造可解释的AI未来
发布时间: 2024-09-02 02:51:37 阅读量: 112 订阅数: 47 

深度学习:培养学生的思维品质.pdf
# 1. 深度学习模型解释性的必要性
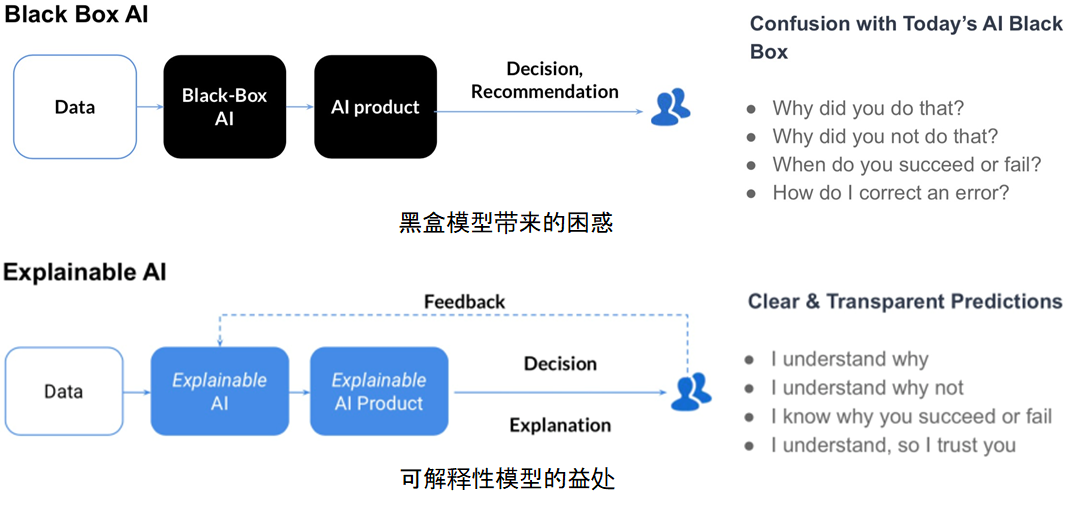
随着人工智能技术的快速发展,深度学习模型在各个领域得到了广泛的应用,从医疗诊断到自动驾驶,从金融风险评估到个性化推荐系统。然而,深度学习模型由于其复杂性和黑盒特性,常常让开发者和用户对其决策过程感到困惑,这种困惑直接导致了对模型的信任缺失。因此,深度学习模型的解释性变得尤为重要。
解释性不仅仅是帮助我们理解模型是如何工作的,它还涉及到如何增强模型的透明度,建立用户和AI系统之间的信任。此外,解释性在满足伦理法规要求、提升模型的可靠性和公正性方面也扮演着关键角色。
在这一章中,我们将深入探讨深度学习模型解释性的必要性,并分析它对AI技术发展的长远影响。我们将简要介绍模型透明度和信任的重要性,以及解释性对AI伦理和法规的影响,为理解深度学习模型解释性的重要性奠定基础。
# 2. 深度学习中的解释性理论基础
深度学习领域的快速发展带来了对复杂模型的广泛应用,但随着模型的深度和复杂度的提升,模型的决策过程变得更加不透明,即所谓的“黑盒”问题。为了建立用户对AI模型的信任,确保AI系统的公正性和责任性,模型解释性的研究变得尤为重要。本章节将深入探讨解释性在AI中的角色和重要性、模型解释性面临的障碍,以及解释性理论框架的构成。
## 2.1 解释性在AI中的角色和重要性
### 2.1.1 模型透明度和信任的建立
透明度是建立信任的关键要素之一。在AI决策过程中,如果缺乏透明度,用户可能会对AI做出的决策持怀疑态度。解释性提供了一种方法,将复杂模型的决策逻辑翻译成易于理解的形式,让用户能够理解AI的决策过程,从而建立起对模型的信任。
**案例分析:** 在医疗领域,使用深度学习模型进行疾病预测时,医生和患者需要了解模型的决策依据来建立信任。通过解释性技术,医生可以了解哪些因素对预测结果有重大影响,从而做出更明智的决策。
### 2.1.2 解释性对AI伦理和法规的影响
随着人工智能的广泛应用,伦理和法规问题日益凸显。解释性可以帮助确保AI系统符合伦理和法规要求,尤其是在涉及隐私、偏见和公平性的问题上。
**法规遵从:** 例如,在欧洲通用数据保护条例(GDPR)中,数据主体有权获得对其个人数据处理的解释。这意味着任何使用AI处理个人数据的组织都需要能够解释其模型的决策。
## 2.2 深度学习模型解释性障碍
### 2.2.1 黑盒模型的问题
深度学习模型,特别是神经网络,常常因为其复杂的内部结构而被视为“黑盒”。这种复杂性使得理解模型的内部工作机制变得非常困难。
**挑战:** 解释这些模型的挑战在于找到一种方法,能够在不牺牲太多性能的情况下,揭示模型的内部决策逻辑。
### 2.2.2 模型复杂性与可解释性之间的权衡
在深度学习中,模型的性能往往与其复杂性成正比。增加网络的深度和宽度可以提高预测精度,但同时也会降低模型的可解释性。因此,研究者在设计模型时需要在性能和可解释性之间进行权衡。
**权衡策略:** 一些策略如模型简化、蒸馏技术和模块化设计,被提出以在保持模型性能的同时提高其可解释性。
## 2.3 解释性理论框架
### 2.3.1 本地解释与全局解释的差异
在深度学习中,解释性可以分为本地解释(对单个预测的解释)和全局解释(对整个模型的解释)。
- **本地解释**关注于解释模型对特定输入的预测,例如,通过梯度上升法强调对分类结果影响最大的像素。
- **全局解释**则尝试理解整个模型的工作原理,这通常通过模型简化或提取高级特征来实现。
### 2.3.2 常见的解释性模型和方法
解释性模型和方法是多样的,主要可以分为以下几类:
- **模型特异性方法**:这类方法依赖于模型的内部结构,如神经网络的反向传播机制。
- **模型不可知方法**:这类方法不依赖于模型的内部结构,可以应用于任何类型的模型,例如局部可解释模型-附加树(LIME)。
- **可视化技术**:这类技术通过图像展示模型的特征激活,帮助解释模型预测结果的原因。
**代码示例:** 以下是一个使用LIME对图像分类模型进行本地解释的Python代码示例:
```python
import lime
import lime.lime_image
from keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions
from keras.preprocessing import image
import numpy as np
# 加载预训练的VGG16模型
model = VGG16()
# 加载一张图片
img_path = 'path_to_image.jpg'
img = image.load_img(img_path, target_size=(224, 224))
# 预处理图片
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
# 生成局部解释
explainer = lime.lime_image.LimeImageExplainer()
explanation = explainer.explain_instance(np.array(img), model.predict, top_labels=5, hide_color=0, num_samples=1000)
# 显示解释结果
temp, mask = explanation.get_image_and_mask(***_labels[0], positive_only=True, num_features=10, hide_rest=True)
img_bound = np.zeros((224, 224, 3))
img_bound[:, :, :] = (0, 0, 0)
img_bound[mask == 255] = img
print(explanation.local_pred[0])
# 显示图片
from skimage.segmentation import mark_boundaries
import matplotlib.pyplot as plt
plt.imshow(mark_boundaries(img_bound.astype('uint8'), temp))
plt.show()
```
在上面的代码示例中,LIME用于解释一个预训练的VGG16模型对特定图片的预测结果。代码首先加载并预处理了图片,然后通过LIME生成了该图片的局部解释。解释结果以图像的形式展示,其中高亮的部分表示对模型预测结果影响最大的区域。
通过这些方法,我们可以更深入地理解深度学习模型的决策机制,从而在必要时对模型做出调整,确保其更加符合预期的可解释性要求。
# 3. 深度学习模型解释性技术实践
## 3.1 特征重要性评估方法
### 3.1.1 基于梯度的方法
在深度学习模型中,理解各个特征对于模型输出的贡献程度是至关重要的。一种流行的方法是使用梯度相关的技术来评估特征的重要性。具体来说,梯度可以衡量损失函数相对于输入特征的敏感度,因而可以用来评价特征对预测结果的影响。
例如,对于图像识别任务,可以使用Saliency Maps方法。它通过计算模型输出对于输入图像的梯度来强调图像中的重要部分。
```python
import torch
import torchvision.models as models
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
from PIL import Image
import requests
from io import BytesIO
# 加载预训练的模型和图像
model = models.resnet50(pretrained=True)
model.eval()
url = '***'
response = requests.get(url)
img = Image.open(BytesIO(response.content))
# 将图片转换为模型输入的张量格式
def image_to_tensor(image):
preprocess = ***pose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
return preprocess(image).unsqueeze(0)
tensor_img = image_to_tensor(img)
tensor_img.requires_grad_(True)
# 通过模型预测和反向传播得到梯度
output = model(tensor_img)
output[0,torch.argmax(output)].backward()
# 提取梯度并可视化
gradients = tensor_img.grad[0]
saliency = torch.mean(gradients, dim=0)
saliency = torch.clamp(saliency, min=0)
# 将梯度可视化并显示图像
saliency_map = torch.unsqueeze(saliency, 0)
plt.imshow(saliency_map.detach().numpy().squeeze())
plt.show()
```
在这个代码示例中,首先加载了一个预训练的ResNet50模型。然后,对一张狗的图片进行了预处理,使其符合模型的输入要求。接着,通过模型得到预测并计算梯度。最后,可视化了梯度结果,突出显示了图像中的关键区域。参数说明包括图像预处理的具体步骤,这些步骤对于确保梯度计算的准确性至关重要。
### 3.1.2 基于扰动的方法
基于扰动的方法是另一种评估特征重要性的技术。与基于梯度的方法不同,基于扰动的方法通过在输入数据上进行小的改变,然后观察输出结果的变化,来评估特征的重要性。
比如,一个简单直观的方法是,随机地将输入特征置零或者替换为平均值,观察预测结果的变化。如果置零某个特征后,预测结果的变动较大,那么这个特征就被认为是重要的。
```python
# 以简单的线性模型为例展示扰动法
import numpy as np
# 假设x是输入特征,y是目标变量
x = np.random.rand(10) # 随机生成一些特征
y = 2 * x[0] + 3 * x[1] + 0.5 * x[2] + np.random.randn() * 0.1 # 假设真实的模型是 y = 2x1 + 3x2 + 0.5x3
# 扰动特征并重新预测
x_permuted = np.copy(x)
x_permuted[0] = 0 # 将第一个特征置零
y_permuted = 2 * x_permuted[0] + 3 * x_permuted[1] + 0.5 * x_permuted[2] + np.random.randn() * 0.1
# 计算预测变化
print("原始预测值:", y)
print("扰动后的预测值:", y_permuted)
print("预测变化:", y_permuted - y)
```
在这个例子中,首先随机生成了一个输入特征向量`x`和目标变量`y`。然后,通过将`x`的第二个元素置零(假设x[0]是重要的特征),我们得到了一个新的预测值。通过比较原始预测值和扰动后的预测值之间的差异,可以对特征的重要性进行定量分析。参数说明涉及了原始特征向量和目标变量的生成过程,以及如何通过简单操作模拟特征扰动。
## 3.2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨人工智能算法的可解释性,重点关注如何构建可解释的深度学习模型,提升企业合规性。文章涵盖了广泛的主题,包括:
* 使用 LIME 和 SHAP 等工具进行模型解释
* 金融行业确保 AI 决策透明度的策略
* 提升 AI 模型可解释性的方法
* 可解释 AI 的商业价值和用户信任提升策略
* 医疗 AI 透明决策的重要性
* 深度学习模型透明度的挑战和机遇
* 打造用户友好型 AI 解释平台
* 克服深度学习模型解释障碍的策略
* 自动驾驶中可解释性的作用
* 在机器学习中权衡模型可解释性和性能
* 向非技术人员解释 AI 模型的工作原理
* 揭示深度学习模型解释性障碍,打造可解释的 AI 未来
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Origin图表专家之路:坐标轴定制秘籍,5分钟提升图表档次
# 摘要
本论文系统回顾了Origin图表基础知识,深入探讨了坐标轴定制的理论基础,包括坐标轴元素解析、定制原则与设计以及高级定制技巧。通过实践操作章节,展示了如何打造定制化坐标轴,并详细介绍了基础操作、多轴图表创建与颜色及线型的定制。进阶技巧章节则聚焦于模板使用、编程化定制以及动态更新技术。最后,通过最佳实践案例分析,提供了科学研究和工程项目中坐标轴定制的实用范例
【WebSphere集群部署与管理】:构建企业级应用的高可用性秘诀
# 摘要
WebSphere集群作为一款成熟的商业应用服务器集群解决方案,为实现高可用性与负载均衡提供了强大的支持。本文旨在详细介绍WebSphere集群的基础架构和部署前的理论准备,通过分析集群组件和高可用性的基本原理,阐述集群部署的关键步骤及优化技巧。同时,我们探讨了集群的高级应用与管理,包括动态管理、自动化部署以及监控和日志分析的最佳实践。通过实际案例研究与行业应用分析,本文总结了WebSphere集群管理的最佳实践和未来发展趋势,以期为相关领域的研究与实践
DevExpress GridControl进阶技巧:列触发行选择的高效实现

# 摘要
本文深入探讨了DevExpress GridControl在应用程序中的应用与
Qt项目实践揭秘:云对象存储浏览器前端设计的5大要点

# 摘要
随着信息技术的发展,云存储已成为大数据时代的重要组成部分。本文首先介绍了Qt项目与云对象存储的基本概念,随后深入探讨Qt前端设计基础,包括框架核心概念、项目结构、模块化设计以及用户界面设计原则。在核心功能实现方面,文章详细说明了对象存储的RESTful API交互、文件管理界面设计及多租户支持和安全机制。接着,本文阐述了如何通过异步编程、事件驱动模型以及大数据量文件的处理策略来优化数据处理与展
LINQ查询操作全解:C#类库查询手册中的高级技巧
# 摘要
本文全面探讨了LINQ(语言集成查询)技术的基础知识、核心概念、操作类型、进阶技巧、实践应用以及在复杂场景和新兴技术中的应用。通过对LINQ查询表达式、核心操作类型以及与不
【SimVision-NC Verilog进阶篇】:专家级仿真与调试模式全面解析
# 摘要
本文详细介绍并分析了SimVision-NC Verilog仿真环境,探索了其在专家级仿真模式下的理论基础和高级调试技巧。文章从Verilog语法深入理解、仿真模型构建、时间控制和事件调度等方面展开,为仿真性能优化提供了代码优化技术和仿真环境配置策略。同时,探讨了仿真自动化与集成第三方工具的实践,包括自动化脚本编写、集成过程优化和CI/CD实施。综合案例分析部分将理论与实践结合,展示了S
案例分析:如何用PyEcharts提高业务数据报告的洞察力
# 摘要
PyEcharts是一个易于使用、功能丰富的Python图表库,它提供了多样化的图表类型和丰富的配置选项,使得用户能够轻松创建美观且交互性强的数据可视化报告。本文首先介绍PyEcharts的基本概念及其安装过程,然后深入探讨基础图表类型的应用、个性化配置和数据动态绑定方法。之后,本文将重点放在复杂图表的构建上,包括多轴、地图和
ADVISOR2002终极攻略:只需1小时,从新手到性能调优大师

# 摘要
本文全面介绍了ADVISOR2002软件的基础知识、操作技巧、高级功能、性能调优方法,以及其在不同领域的应用和未来发展趋势。第一章为ADVISOR2002提供了基础介绍和界面布局说明,第二章深入阐述了其性能指标和理论基础,第三章分享了具体的操作技巧和实战演练,第四章探讨了软件的高级功能和应用场景,第五章着重分析了性能调优的方法和策略,最后第六章展望了ADVISO
VisionMasterV3.0.0定制开发秘籍:如何根据需求打造专属功能
# 摘要
本文全面介绍了VisionMasterV3.0.0定制开发的全过程,涵盖需求分析、项目规划、系统架构设计、核心功能开发、高级功能定制技术以及测试与质量保证六个方面。通过深入理解用户需求,进行详细的项目规划与风险管理,本文展示了如何构建一个可扩展、可定制的系统架构,并通过实践案例展示了核心功能的定
【组合逻辑电路高级案例剖析】:深度解析复杂设计

# 摘要
组合逻辑电路是数字电路设计的核心组成部分,涵盖了从基本逻辑门到复杂功能电路的广泛领域。本文首先概述了组合逻辑电路的基本概念及其设计基础,强调了逻辑门的理解与应用,以及复杂逻辑函数的简化方法。随后,文章深入探讨
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )