JavaFX图表数据挖掘:数据模式识别与图表的协同工作
发布时间: 2024-10-23 14:43:07 阅读量: 19 订阅数: 31 

图表毕业设计—(包含完整源码可运行).zip
# 1. JavaFX图表基础与数据模式识别概述
## JavaFX图表基础
JavaFX是一种用于构建丰富客户端应用的开源框架,图表是JavaFX中用于展示数据图形化的重要组件。基础的图表类型包括折线图、柱状图和饼图等,适用于不同的数据分析和展示场景。理解这些图表组件的基础属性和如何将数据绑定到它们,对于开发出功能丰富且直观的应用是至关重要的。
## 数据模式识别的必要性
数据模式识别是数据挖掘的一个关键步骤,它从原始数据中识别出有意义的模式或结构。在JavaFX图表中引入数据模式识别,可以帮助用户更好地理解数据背后的趋势和关联。在接下来的章节中,我们将探索如何在JavaFX中应用模式识别技术,从大量的数据集中提取有价值的信息,并以直观的图表形式展现出来。这将增强数据的可视化表现力,同时提供更深层次的数据分析能力。
以上内容为文章第一章的内容概览,后续章节将围绕JavaFX图表组件详细展开,以及如何利用数据模式识别技术,为开发者提供更强大的数据分析工具。
# 2. JavaFX图表组件与数据绑定
### 2.1 JavaFX图表组件介绍
JavaFX提供了一整套图表组件,这些组件使得数据的可视化变得简单而强大。它们不仅可以帮助开发者轻松创建静态图表,还能实现动态的数据更新。
#### 2.1.1 基本图表类型和应用场景
JavaFX的图表组件可以分为几类:线形图(LineChart)、条形图(BarChart)、饼图(PieChart)、散点图(ScatterChart)等。每种图表类型适用于不同的数据展示场景。
- **线形图**:适合展示数据随时间变化的趋势,如股票价格的波动。
- **条形图**:用于比较不同类别的数据大小,例如各地区销售业绩对比。
- **饼图**:用于展示各部分占总体的比例,如市场份额分析。
- **散点图**:用来观察两个变量之间的关系,如房价与地理位置的关系。
#### 2.1.2 JavaFX图表组件的属性和事件
JavaFX图表组件有丰富的属性和事件可供开发者使用。组件的属性允许开发者调整图表的外观和行为,如颜色、字体、轴标签等。事件则是图表对用户交互的响应,比如当用户点击图表上的数据点时触发的事件。
```java
// 示例代码:设置图表的一些属性
lineChart.setTitle("Stock Prices Over Time");
lineChart.getXAxis().setLabel("Date");
lineChart.getYAxis().setLabel("Price in USD");
lineChart.setLegendVisible(false);
// 示例代码:为图表添加交互事件
lineChart.setOnMouseClicked(event -> {
if (event.getClickCount() == 2) {
// 双击事件处理逻辑
}
});
```
### 2.2 JavaFX中的数据绑定技术
#### 2.2.1 数据绑定的基本概念和优势
数据绑定是指将界面组件的属性直接绑定到数据模型的属性上,当数据模型发生变化时,界面组件会自动更新。这种方式的优点是减少了手动更新界面的代码,提高了程序的响应性和可维护性。
#### 2.2.2 实现数据绑定的步骤和方法
实现数据绑定通常涉及到以下步骤:
1. 定义数据模型,实现属性的getter和setter方法。
2. 创建界面组件,并设置其属性。
3. 使用JavaFX提供的数据绑定机制,将界面组件的属性与数据模型的属性绑定。
```java
// 示例代码:实现数据绑定
ObjectProperty<Number> value = new SimpleObjectProperty<>(100);
Label label = new Label();
// 绑定Label的文本属性到value
label.textProperty().bind(Bindings.format("Value: %s", value));
// 当value更新时,label也会自动更新
value.set(200);
```
### 2.3 JavaFX图表与数据模型的协同
#### 2.3.1 数据模型的构建和管理
数据模型是图表组件的数据来源,构建良好的数据模型是实现高效数据绑定的关键。数据模型需要设计合理,能够反映出业务逻辑,并且易于管理和维护。
#### 2.3.2 图表组件与数据模型的绑定实例
下面是一个简单的实例,展示如何创建一个线形图,并将其数据源绑定到一个数据模型上。
```java
// 创建数据模型
XYChart.Series<Number, Number> series = new XYChart.Series<>();
series.setName("Data Series");
// 将数据模型绑定到线形图
lineChart.getData().add(series);
```
在JavaFX中,数据绑定机制非常灵活。开发者不仅可以在属性级别进行绑定,还可以在数据模型和界面组件之间进行更复杂的绑定操作。通过这些技术手段,图表组件能够根据数据模型的变化而动态更新,从而实现高效的数据可视化。
以上所述是JavaFX图表组件和数据绑定的基础知识,接下来的章节将继续深入探讨如何在实际开发中应用这些技术,以及如何通过JavaFX图表和数据模式识别算法来实现更高级的数据可视化与分析。
# 3. 数据模式识别算法的理论基础
## 3.1 模式识别的基本概念
### 3.1.1 模式识别的任务和分类
模式识别是计算机视觉和机器学习领域的一个核心分支,涉及从数据中检测、识别和分类信息模式。任务通常包括特征提取、分类器设计和决策制定。模式可以是图像、声音、文本等,识别过程通常可分为以下几个步骤:
1. 数据采集:从现实世界中采集信息。
2. 预处理:提高数据质量,可能包括噪声消除、标准化等。
3. 特征提取:识别数据中最重要的特征或属性。
4. 训练:使用一组已知的训练数据集对分类器或算法进行训练。
5. 评估:使用测试集来评估所训练模型的性能。
6. 应用:将训练好的模型应用于新的数据集以进行预测。
模式识别算法主要分为两种类型:监督式和非监督式。监督式学习算法需要已标注的训练数据,而无监督式学习算法则不需要。
### 3.1.2 主要模式识别算法概述
模式识别算法种类繁多,这里选取几个有代表性的进行介绍:
- **线性判别分析(LDA)**:一种监督式学习方法,用于多类别分类。LDA尝试找到一个线性组合的特征,这个线性组合能够最大化类间差异,同时最小化类内差异。
- **K-最近邻(K-NN)算法**:一种简单高效的分类算法,适用于多类问题。K-NN算法的工作是根据最近的K个训练样本来预测一个对象的类别。
- **支持向量机(SVM)**:一个强大的监督学习方法,用于分类和回归任务。SVM通过在数据空间中找到一个或多个超平面来实现分类。
- **主成分分析(PCA)**:一种常用的数据降维技术。PCA通过正交变换将可能相关的变量转换为一组线性不相关的变量,称为主成分。
以上算法各有优势,选择合适的算法通常取决于数据的特性以及任务的具体要求。
## 3.2 监督式学习算法
### 3.2.1 线性回归与逻辑回归
监督式学习算法包括线性回归和逻辑回归。
- **线性回归**用于预测连续值结果。基本思想是寻找一条线(或超平面)来拟合数据点,以此来描述输入变量与输出变量之间的线性关系。
- **逻辑回归**用于二分类问题,其输出是介于0和1之间的概率值。通过逻辑函数(如Sigmoid函数)将线性回归的输出映射到概率上。
### 3.2.2 支持向量机(SVM)
SVM通过寻找最优分割超平面(决策边界)来分类数据。一个良好的超平面是能够使得不同类别的数据之间的边界(或间隔)最大的超平面。在有噪声或数据重叠的情况下,SVM使用软间隔或者引入核技巧,允许某些数据点可以位于错误的一侧,从而增加模型的泛化能力。
## 3.3 非监督式学习算法
### 3.3.1 聚类算法(K-means, DBSCAN)
非监督式学习的目标是发现数据中的模式或分组,而不依赖于预先标记的数据。聚类算法是常用的非监督式学习算法之一。
- **K-means算法**:通过迭代寻找数据点的K个聚类中心,将数据点分配到离其最近的聚类中心所属的簇中。该算法通过最小化簇内距离的总和来优化聚类。
- **DBSCAN算法**(Density-Based Spatial Clustering of Applications with Noise):基于密度的聚类方法,可以发现任意形状的簇,并且能够处理噪声数据。DBSCAN将密集区域中的点聚集在一起,而将稀疏区域中的点标记为异常值。
### 3.3.2 主成分分析(PCA)
PCA是一种用于数据降维的技术,通过正交变换将数据转换到一个新的坐标系统,使得第一个坐标(第一主成分)具有最大的方差,第二坐标(第二主成分)次之,依此类推。PCA用于提取数据中最重要的特征,从而减少数据集的维度。
PCA的过程包括:
1. 计算数据集的均值,然后从每个数据点中减去对应的均值。
2. 计算协方差矩阵。
3. 计算协方差矩阵的特征值和特征向量。
4. 将特征向量按对应的特征值大小排序。
5. 选择前N个最大的特征值对应的特征向量,构成特征向量矩阵。
6. 利用选定的特征向量对原始数据进行转换,得到降维后的数据集。
PCA在图像处理、基因数据分析等领域有着广泛的应用。
以上章节内容为第三章:数据模式识别算法的理论基础的详细介绍,深入解析了模式识别的基本概念、监督式与非监督式学习算法,为后续章节的实践应用和高级应用打下了坚实的理论基础。在接下来的章节中,我们将更进一步探讨如何将JavaFX图表技术与模式识别算法相结合,实现更为复杂和智能的数据可视化应用。
# 4. 实践应用:JavaFX图表与模式识别
在之前的章节中,我们已经探讨了JavaFX图表的基础知识以及数据模式识别的基本理论。本章将深入实际应用,演示如何将JavaFX图表组件与模式识别技术结合起来,为用户提供直观的交互式数据分析工具。
## 4.1 JavaFX图表数据可视化
### 4.1.1 数据展示技巧和动态更新
当处理实时数据流时,动态更新图表显示是至关重要的。JavaFX提供了一套机制来实现图表的动态更新,能够实时展示数据变化。这不仅涉及到数据本身,还涉及到图表组件的更新策略。
```java
// 示例代码:更新图表数据
import javafx.application.Application;
import javafx.collections.FXCollections;
import javafx.collections.ObservableList;
import javafx.scene.Scene;
import javafx.scene.chart.LineChart;
import javafx.scene.chart.NumberAxis;
import javafx.scene.chart.XYChart;
import javafx.stage.Stage;
public class DynamicChartExample extends Application {
private static final int DATA_COUNT = 100;
private LineChart<Number, Number> lineChart;
private XYChart.Series<Number, Number> series = new XYChart.Series<>();
@Override
public void start(Stage primaryStage) {
// 初始化图表
lineChart = new LineChart<>(new NumberAxis(), new NumberAxis());
lineChart.setTitle("Dynamic Data Update Example");
lineChart.getData().add(series);
// 模拟数据生成和更新
ObservableList<XYChart.Data<Number, Number>> data =
FXCollections.observableArrayList(
(e) -> new Observable[]{e.getValueY()}
);
for (int i = 0; i < DATA_COUNT; i++) {
data.add(new XYChart.Data<>(i, Math.random() * 100));
}
series.setData(data);
// 创建场景和舞台
Scene scene = new Scene(lineChart, 800, 600);
primaryStage.setScene(scene);
primaryStage.show();
// 动态更新数据
new Thread(() -> {
for (int i = 0; i < DATA_COUNT; i++) {
// 模拟数据更新,可以替换为数据处理逻辑
data.get(i).setYValue(Math.random() * 100);
try {
Thread.sleep(100); // 暂停100毫秒,模拟实时更新延迟
} catch (InterruptedException ex) {
ex.printStackTrace();
}
}
}).start();
}
public static
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
JavaFX Charts(图表支持)专栏深入探讨了 JavaFX 中图表功能的方方面面。它提供了一系列全面且实用的指南,涵盖从基本图表技巧到高级数据可视化和交互性。专栏文章包括:
* 动态数据展示的 15 个技巧
* 交互式数据可视化应用构建指南
* 大数据集下响应速度优化的策略
* 动态图表数据更新的 10 个技巧
* 多系列数据比较的实现方法
* 柱状图和条形图的优劣对比
* 复杂数据比例分布展示的策略
* 成对数据关系的分析与展示
* 动态数据时序展示的技巧
* 自定义样式和元素的终极指南
* 增强用户体验的 7 大交互式图表控制技巧
* 让数据生动起来的 5 种动画效果
* 多语言环境下的数据可视化解决方案
* 报告和演示需求的满足之道
* 不同系统中保持一致性的秘诀
* 确保图表功能正确性和稳定性的最佳实践
* 嵌入现有 Java 应用的技巧
* 多个图表间联动实现的详细步骤
* 数据模式识别与图表的协同工作
* 数据与用户信息保护的全面指南
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
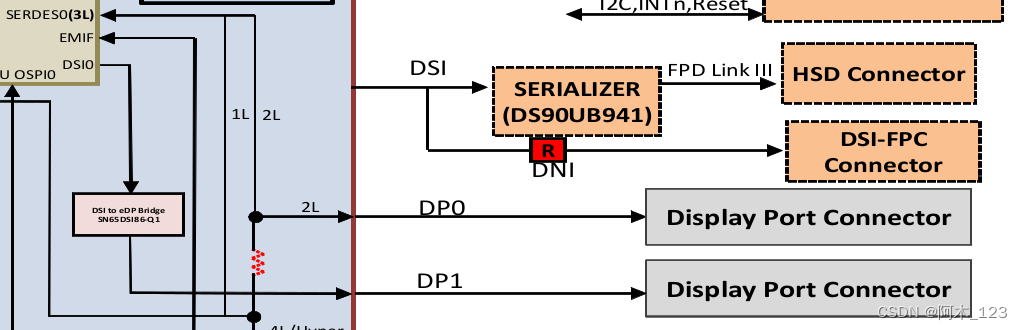
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )