




分布式事务管理:Spring Cloud事务解决方案揭秘


zfly:分布式事务 LCN实例 spring cloud
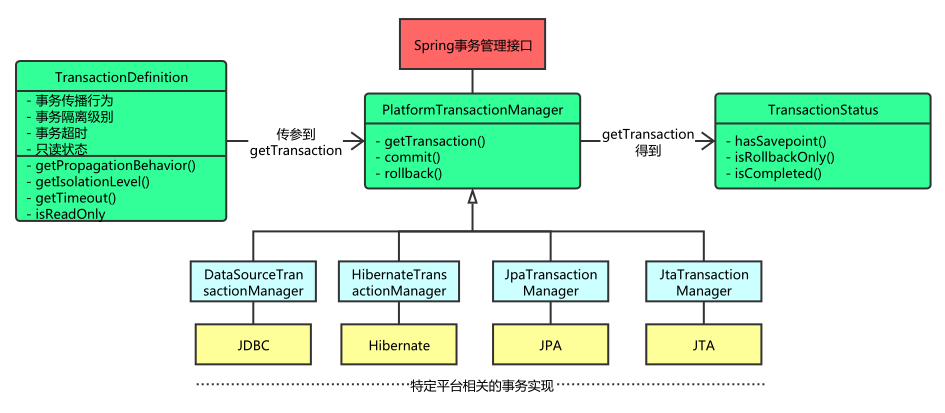
1. 分布式事务的挑战与需求分析
分布式系统中的事务管理是构建可靠服务架构的关键组成部分。随着微服务架构的普及,分布式事务的需求日益凸显,因为它们保证了跨多个服务和数据库的数据一致性。
1.1 分布式事务的必要性
在传统的单体应用中,事务被限制在单一数据库的边界内,能够简单地使用ACID(原子性、一致性、隔离性、持久性)原则来保证数据的完整性。然而,在分布式环境中,服务通常通过网络进行通信,依赖于多个数据库,这增加了数据一致性的复杂性。
1.2 分布式事务面临的挑战
分布式事务面临的主要挑战包括网络延迟、节点故障和数据一致性问题。网络的不确定性和服务的独立部署要求事务管理机制必须足够灵活,能够在不同服务和数据库间同步事务状态。
1.3 分布式事务的需求分析
为了满足企业级应用的需求,分布式事务解决方案需要提供以下关键特性:
- **高可用性:**解决方案必须能够在系统故障时恢复,保证数据一致性。
- **高性能:**必须最小化网络通信开销,避免对性能产生显著影响。
- **易用性:**操作应该简单直观,能够无缝地集成到现有的开发流程中。
通过分析这些挑战和需求,我们可以为分布式事务设计合适的策略和框架。下一章将深入探讨分布式事务的基础理论,为读者提供进一步理解分布式事务的坚实基础。
2. 分布式事务基础理论
分布式系统因其在扩展性、容错性以及高可用性方面的优势,已成为构建现代企业级应用的首选架构模式。然而,分布式事务作为分布式系统中的一个核心问题,其理论和实践的复杂性也不容忽视。接下来,本章将深入探讨分布式事务的基础理论,包括分布式系统的事务特性、不同事务模型以及分布式事务中常见的问题。
2.1 分布式系统的事务特性
2.1.1 本地事务与分布式事务的区别
在传统的单体应用中,事务通常局限于一个数据库或一组紧密耦合的数据资源中。这种事务被称为本地事务。本地事务的管理相对简单,因为它可以利用单一数据库系统提供的事务管理机制,例如ACID属性(原子性、一致性、隔离性、持久性)。
然而,在分布式系统中,由于资源分布在不同的节点上,一个事务可能涉及到多个网络调用和远程数据操作。这些操作跨越了多个服务和数据库,引入了复杂的协调和同步问题,这就是所谓的分布式事务。分布式事务需要保证跨越多个节点和系统的ACID属性,这大大增加了管理的复杂度。
分布式事务与本地事务的区别主要在于:
- 系统架构的不同:本地事务一般在单个数据库系统内完成,而分布式事务则需要跨多个数据库、服务或系统。
- 事务边界的不同:本地事务的边界是明确的,通常由单一数据库的事务管理器控制。分布式事务的边界是模糊的,可能包括多个服务和数据库。
- 数据一致性保障的不同:本地事务依赖于数据库的事务机制来保障数据一致性,而分布式事务需要额外的协调服务来实现。
2.1.2 CAP理论在事务管理中的应用
CAP理论是分布式系统设计中的一个基本原则,它指的是在分布式系统中,一致性(Consistency)、可用性(Availability)和分区容忍性(Partition tolerance)这三个要素最多只能同时实现两个。
在事务管理中,CAP理论的应用体现在:
- 一致性:所有的节点在同一时间看到的数据是一样的。在事务管理中,一致性要求当一个事务提交后,所有节点上的数据状态必须保持一致。
- 可用性:系统每个请求都能在有限的时间内得到响应。事务管理中的可用性要求事务操作能够在有限时间内完成并响应。
- 分区容忍性:系统能够应对网络分区的情况,即当网络不稳定导致某些节点之间的通信被中断时,系统仍然能够继续工作。
在实际应用中,分布式事务处理必须根据业务的需求和系统的实际环境,对CAP的三个要素进行权衡。例如,某些场景下可能会优先保证一致性,而牺牲一部分可用性。不同类型的事务模型和解决方案(如2PC和3PC)对CAP的不同侧面有不同的处理策略和优化方案。
2.2 分布式事务模型
2.2.1 两阶段提交(2PC)协议解析
两阶段提交(2PC)是一种广泛使用的分布式事务协议,它将分布式事务的提交过程分为两个阶段:
- 准备阶段(第一阶段):事务协调器询问所有参与事务的节点是否准备好提交事务。如果所有节点都返回“准备好”,则进入第二阶段;如果任何一个节点返回“未准备好”,则事务协调器指示所有节点回滚事务。
- 提交/回滚阶段(第二阶段):如果在准备阶段所有参与节点都返回“准备好”,协调器将向所有节点发送提交事务的指令,否则发送回滚事务的指令。
2PC虽然简单直观,但也存在明显的缺点,比如单点故障风险、同步阻塞问题以及性能开销较大等。
2PC协议的关键在于确保所有节点在任何情况下都能保持一致性,但这种强一致性协议的缺点是牺牲了系统的可用性和性能。
2.2.2 三阶段提交(3PC)协议解析
三阶段提交(3PC)是为了解决2PC存在的单点故障和阻塞问题而提出的改进协议。3PC将事务提交过程分为三个阶段:
- 预准备阶段:协调器询问所有参与者是否准备好进入提交阶段,参与者若准备好则返回“可以提交”响应。
- 准备阶段:协调器收集所有参与者的“可以提交”响应后,指示它们准备提交。此时即使协调器故障,参与者也会在超时后自行提交事务。
- 提交/中止阶段:如果协调器确认所有参与者都已经准备就绪,则通知它们提交事务;如果任何一个参与者未准备好或协调器未能收到准备就绪的确认,则通知所有参与者中止事务。
3PC协议相对2PC而言,通过引入预准备阶段来减少阻塞,并在协调器故障时能更好地处理中止事务的情况,但依然存在性能开销和复杂性较高的问题。
2.2.3 最终一致性模型分析
与强一致性模型不同,最终一致性模型允许系统在一段时间内处于不一致状态,但保证在没有新的更新操作的情况下,数据最终能够达到一致的状态。这种模型在分布式系统中被广泛应用,尤其是在需要高可用性和高分区容忍性的系统中。
最终一致性通常由以下几种方式实现:
- 读写时副本一致性:当写操作完成后,数据会异步复制到其他节点,读操作可以在任何节点上进行,但读取的数据可能是旧数据。
- 基于版本的冲突解决:每个数据项都有一个版本号,写操作基于最新的版本号进行,如果版本不一致,则需要解决冲突。
- 基于时间戳的一致性控制:系统为每个操作分配时间戳,通过时间戳来决定数据的最终一致性。
最终一致性模型的关键优势在于它允许系统在不牺牲可用性和分区容忍性的前提下,提供相对较为灵活的一致性保证。
2.3 分布式事务的常见问题
2.3.1 资源锁定与性能瓶颈
在分布式事务中,资源锁定是保证数据一致性的重要机制,但同时它也可能成为性能的瓶颈。资源锁定主要体现在:
- 锁定粒度:锁定的粒度可以是数据库表、行甚至更小的单位。锁定粒度越小,对并发性能的影响越小,但实现复杂度和开销越高。
- 锁定时长:锁定时间越长,对系统资源的占用和对并发操作的限制也越大。
- 分布式锁管理:在分布式环境

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
STM32F103C8T6寄存器操作全攻略:专业新手指导手册
【高级Matlab技巧】:如何通过优化提升财政收入预测精度
DSP28335实战教程:精通中断系统,解锁更多应用可能
IRT与Rasch模型:深度比较揭示两者的联系与差异
中兴OLT-C300深度剖析:掌握硬件架构与功能特性的终极指南
揭秘ISO 16232:汽车行业的清洁度标准(及其对质量控制的影响)
【Aspose.Words精通指南】:Word文档处理自动化全攻略
频谱仪远程控制信号传输优化:提升性能的终极策略
高效管理数据集:Unscrambler 11导入导出全攻略


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )




















