【代码复用策略】:掌握在GitHub上构建模块化项目架构的方法,提升开发效率
发布时间: 2024-12-06 22:38:31 阅读量: 20 订阅数: 5 
# 1. 代码复用与模块化概念解析
在软件开发的世界里,代码复用和模块化是提高效率、增强可维护性和可读性的关键策略。代码复用指的是在不同部分的程序中重复使用同一段代码,以减少冗余和提高开发速度。模块化则是将复杂的程序分解为可以独立开发、测试和维护的小块,通常称为模块。模块化不仅仅是一种编程风格,它还涉及一系列的架构设计原则和模式,比如组件化、微服务和前后端分离等。
## 1.1 模块化的起源和意义
模块化的历史可以追溯到早期的编程实践,随着程序的复杂性增加,将大型系统分解为更小、更易管理的单元成为了必要。模块化有助于团队协作,因为它可以使得不同开发者或团队同时工作在系统的不同部分而不冲突。此外,模块化促进了代码复用,减少了重复工作,提高了效率和质量。
## 1.2 代码复用的现状与挑战
尽管代码复用带来了诸多好处,但在实际应用中也面临着挑战。例如,代码复用需要良好的设计决策来保证不同部分的代码易于理解、修改和维护。此外,代码复用也需要考虑依赖管理,确保代码库的稳定性和安全性。随着现代软件架构的发展,比如微服务架构的出现,开发者对代码复用和模块化的理解和实践有了更高的要求。
代码复用和模块化的深入探讨将在后续章节中继续展开,本文将为你提供一个坚实的基础,以理解这两个概念的重要性,并为下一章打下基础,详细介绍模块化项目架构的设计原则和实现技巧。
# 2. 模块化项目架构的设计原则
## 2.1 设计原则概述
### 2.1.1 单一职责原则
单一职责原则(Single Responsibility Principle,SRP)是面向对象设计中最重要的原则之一。它表明一个类应该只有一个引起它变化的原因,也就是说,一个类应该只有一项职责。当一个类承担的职责过多时,就等于把这些职责耦合在一起,一个职责的变化可能会削弱或者抑制这个类完成其它职责的能力。
为了实现这一原则,我们可以从以下几个方面入手:
- **模块划分**:将复杂的系统分解成多个小模块,每个模块专注于一个功能区域。
- **接口分离**:为不同职责提供不同的接口,保证类或者模块之间的解耦。
- **高内聚低耦合**:让模块之间的依赖尽可能少,同时确保模块内部的组件紧密联系。
代码示例:
```python
class UserAuth:
def login(self, username, password):
# 实现登录逻辑
pass
def logout(self):
# 实现登出逻辑
pass
class UserAccount:
def update_profile(self, user_data):
# 更新用户资料
pass
def change_password(self, old_password, new_password):
# 修改密码
pass
```
在这个示例中,`UserAuth` 类处理用户认证,而 `UserAccount` 类处理账户信息更新。它们各自负责不同的职责。
### 2.1.2 开闭原则
开闭原则(Open/Closed Principle,OCP)是指软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。这意味着当系统需要增加新的功能时,不需要对现有代码进行修改,而是通过扩展原有代码的方式来实现。
在设计阶段实现开闭原则,可以遵循以下方法:
- **抽象层的设计**:在系统中建立抽象层,定义稳定接口,并让具体实现层依赖于这些抽象接口。
- **配置管理**:将可变的配置与代码分离,通过配置文件、环境变量等方式提供可变部分,以实现系统功能的调整。
示例:
```python
class PaymentProcessor:
def process_payment(self, payment_details):
# 处理支付逻辑
pass
class PaymentProcessorFactory:
@staticmethod
def get_processor(payment_type):
if payment_type == "credit_card":
return CreditCardProcessor()
elif payment_type == "paypal":
return PayPalProcessor()
# 可以根据需要添加更多支付方式
raise ValueError("Unsupported payment type")
```
通过 `PaymentProcessorFactory` 可以轻松添加新的支付方式,而无需修改 `PaymentProcessor` 类的核心逻辑。
### 2.1.3 依赖倒置原则
依赖倒置原则(Dependency Inversion Principle,DIP)要求高层模块不应该依赖于低层模块,两者都应该依赖于抽象。此外,抽象不应该依赖于细节,细节应该依赖于抽象。这有助于减少模块间的耦合,使得模块具有更高的可复用性和可维护性。
实践依赖倒置原则的关键在于:
- **定义抽象接口**:为高层和低层模块定义统一的接口。
- **利用抽象接口**:用抽象接口替代具体的类实例,作为方法参数或类成员。
- **依赖注入**:通过构造函数、属性或方法将依赖注入到使用它们的类中。
示例:
```python
from abc import ABC, abstractmethod
class PaymentGateway(ABC):
@abstractmethod
def charge(self, amount):
pass
class CreditCardPaymentGateway(PaymentGateway):
def charge(self, amount):
# 实现信用卡支付
pass
class PayPalPaymentGateway(PaymentGateway):
def charge(self, amount):
# 实现 PayPal 支付
pass
class OrderProcessor:
def __init__(self, payment_gateway: PaymentGateway):
self.payment_gateway = payment_gateway
def process_order(self, order):
# 处理订单并使用 payment_gateway 进行支付
pass
```
以上代码展示了如何通过依赖注入实现依赖倒置,`OrderProcessor` 类依赖于 `PaymentGateway` 抽象接口,而不是具体的支付实现。
## 2.2 模块化架构的构建方法
### 2.2.1 组件化与服务化
组件化与服务化是构建模块化架构的两种不同方法,它们根据业务需求和应用规模来决定如何组织代码和资源。
组件化主要应用于前端技术栈中,它将一个大型的前端项目分解为可复用的组件。每个组件封装了自己独立的功能,拥有自己的样式和逻辑,这使得不同团队可以并行开发,并且可以跨项目复用组件。
服务化则是指将大型应用拆分成多个自治的服务,每个服务负责一部分业务逻辑,并通过网络协议相互通信。这种方法特别适用于大型企业级应用,可以提高系统的可维护性、可扩展性和灵活性。
### 2.2.2 微服务架构的引入
微服务架构是一种架构风格,它将应用构建为一套小型服务,每个服务运行在其独立的进程中,并使用轻量级的通信机制(通常是HTTP RESTful API)相互通信。微服务通常围绕业务能力组织,并通过自动化部署机制独立部署。
引入微服务架构的好处包括:
- **灵活的部署**:独立的服务可以独立部署,减少了部署的复杂性。
- **技术异构性**:允许使用最适合每项服务的技术栈。
- **可扩展性**:根据业务需求,可以独立地对服务进行水平扩展。
引入微服务架构需要注意的问题:
- **分布式系统的复杂性**:服务间的调用增加了系统的复杂度,需要处理服务发现、负载均衡等问题。
- **事务一致性**:保持跨服务的数据一致性是一个挑战。
- **网络延迟和可靠性**:网络的不稳定可能会影响服务间的交互。
### 2.2.3 前后端分离实践
前后端分离是一种开发模式,其中前端开发专注于用户界面和用户体验,而后端专注于服务器端逻辑和数据。前端和后端通过API接口进行交互,这样的分离可以让开发团队更加专注于自己的领域,同时提升开发效率。
前后端分离的优点:
- **并行开发**:前后端可以独立开发,缩短项目开发周期。
- **灵活的技术选择**:前端可以使用最前沿的技术,而后端可以保持稳定。
- **更好的可维护性和扩展性**:各个部分可以独立更新,无需彼此牵制。
前后端分离的实践要求:
- **清晰的接口定义**:前后端分离要求有一个清晰定义的接口契约。
- **状态管理**:在前后端分离的架构中,前端需要处理状态管理问题。
- **API网关**:合理利用API网关来处理跨服务的路由和认证问题。
## 2.3 代码复用的实现技巧
### 2.3.1 函数和方法的复用
函数和方法是编程中最基本的复用单元。在编写函数和方法时,应确保它们能够处理不同的输入并产生相应的输出,同时保证副作用最小化。遵循DRY(Don't Repeat Yourself)原则是实现函数和方法复用的关键。
为了更好地复用函数和方法,可以考虑以下技巧:
- **参数化**:通过参数化来支持不同的用例,增加方法的通用性。
- **编写工具函数**:创建通用的工具函数,可以在多个地方被调用。
- **高阶函数**:使用高阶函数(即接受其他函数作为参数的函数)可以增加代码复用性。
示例:
```python
def repeat_action(action, times):
for _ in range(times):
action()
def print_message(message):
print(message)
# 使用repeat_action复用函数
repeat_action(print_message, 3)
```
### 2.3.2 代码片段与模板的复用
代码片段和模板允许开发者复用通用的代码模式和结构。在不同的编程语言和框架中,这一概念有着不同的实现方式,比如C++的模板、Python的装饰器、以及Web开发中的模板引擎(如Jinja2、ERB)等。
代码片段复用的优点包括:
- **提高开发效率**:复用已有的代码片段可以减少重复劳动。
- **降低错误率**:重复使用经过测试的代码片段可以减少引入错误的几率。
- **保持一致性**:使用统一的代码片段可以让代码风格保持一致。
模板的复用可以通过以下方法:
- **模板库**:在项目中创建一个共享模板库,供团队成员使用。
- **代码生成器**:使用代码生成器工具来自动化创建模板实例。
- **模板语言**:在适当的项目中使用模板语言来定义可复用的布局和逻辑。
示例:
```jinja
<!-- Jinja2模板示例 -->
<html>
<head>
<title>{{ title }}</title>
</head>
<body>
<h1>{{ heading }}</h1>
<ul>
{% for item in list %}
<li>{{ item }}</li>
{% endfor %}
</ul>
</body>
</html>
```
### 2.3.3 库和框架的复用
库和框架是代码复用的高级形式,它们提供了一组封装好的功能和API,供开发者在多个项目中使用。复用库和框架不仅可以加快开发速度,还可以利用社区支持和已有的知识库。
库和框架复用的一些最佳实践:
- **选择合适的库和框架**:根据项目需求选择功能满足、维护良好且文档齐全的库和框架。
- **了解依赖管理**:正确管理项目依赖,避免版本冲突和安全漏洞。
- **贡献与反馈**:参与开源项目,为所使用的库和框架做贡献,有助于提升质量并从中学习。
示例:
```python
import requests
response = requests.get('https://api.example.com/data')
data = response.json()
# 使用requests库来发送HTTP请求
```
通过以上章节内容,我们对模块化项目架构的设计原则和代码复用的实现技巧有了初步的认识,这些知识将为我们构建高效的软件项目打下坚实的基础。接下来的章节,我们将具体探讨如何在实战项目中应用这些原则和技巧,并分析成功案例来加深理解。
# 3. GitHub项目模块化管理实践
## 3.1 版本控制与分支策略
版本控制是软件开发中不可或缺的一部分,它帮助开发者追踪代码变更历史、管理代码版本以及协同开发。在模块化项目管理实践中,版本控制与分支策略的选择尤其关键,它影响着项目的维护效率和开发流程的流畅度。
### 3.1.1 分支模型的选择
在进行模块化开发时,分支模型需要适应快速迭代和频繁合并的场景。目前业界常用的分支模型有Git Flow、GitHub Flow和GitLab Flow,其中GitHub Flow因其简洁性,常被推荐给希望简化流程的项目团队。
- **Git Flow**: 最早由Vincent Driessen提出,它包含一个主分支(master)和一个开发分支(develop),以及支持功能开发、发布和热修复的其他分支。这个模型适合于发布节奏较慢的项目,但在模块化项目中可能会因为复杂的分支合并而降低开发效率。
- **GitHub Flow**: 是一个更为轻量级的分支模型,核心概念是主分支(master)是随时可部署的状态,开发在功能分支上进行。所有的改动都通过Pull Request合并回主分支。这样的模型简单且适用于快速迭代的项目,尤其适合模块化的管理。
- **GitLab Flow**: 结合了Git Flow和GitHub Flow的优点,提供了不同的分支策略来适应不同的项目需求,比如生产环境分支、预发布环境分支以及功能分支。
### 3.1.2 版本号的规范与约定
版本控制不仅是代码的跟踪,还包括版本号的管理。一个清晰、可预测的版本号能够为项目提供额外的上下文信息,帮助开发者了解每个版本的特点和变更历史。
版本号通常遵循语义化版本控制(SemVer),其基本格式是`主版本号.次版本号.修订号`。主版本号表明不兼容的 API 修改,次版本号表明新增了向下兼容的功能,修订号则是向下兼容的问题修正。
### 3.1.3 Pull Request的工作流
Pull Request(PR)是GitHub上协同工作的重要机制。当开发者在一个分支上完成工作后,他们可以创建一个Pull Request,请求将分支的更改合并到主分支。
工作流通常如下:
1. 开发者在自己的分支上工作并提交更改。
2. 完成后,推送分支到远程仓库并创建一个Pull Request。
3. 团队成员审查代码,并讨论PR中的变更。
4. 如果PR通过审查,它将被合并到主分支。
PR流程确保代码质量,通过代码审查减少错误和提升代码复用性。
## 3.2 依赖管理与包管理工具
模块化开发常常伴随着依赖关系的增加,因此有效的依赖管理和包管理变得尤为重要。
### 3.2.1 依赖声明与锁定
现代项目通常会使用包管理工具如npm、yarn或pip来声明项目依赖。依赖声明通常在项目的配置文件中(如`package.json`、`requirements.txt`),这样其他开发者可以在项目中复用同样的依赖环境。
锁定依赖文件(如`package-lock.json`、`yarn.lock`)确保了在安装依赖时,所有开发者和部署环境中依赖的版本是一致的,防止了因版本不同导致的潜在问题。
### 3.2.2 使用包管理器自动化依赖管理
自动化依赖管理可以简化构建过程并减少人为错误。工具如npm和yarn支持依赖安装时的自动化操作,例如:
```bash
yarn install
```
这条命令会根据`package.json`文件中声明的依赖关系,自动下载并安装所有必需的依赖包,并根据`yarn.lock`文件确保安装版本的一致性。
### 3.2.3 模块发布与分发的策略
随着模块化开发的深入,模块的发布与分发策略也需合理规划。通常,这涉及到模块的版本管理、打包和分发机制。
- 版本管理:在模块开发中遵循SemVer规则,通过版本号来沟通模块的变化。
- 打包:将源代码打包成可分发的格式。例如,JavaScript模块可以被打包为一个或多个`*.js`文件。
- 分发:通过包管理器或者私有仓库分发模块。例如,使用npm发布模块到npm registry。
## 3.3 模块化开发的最佳实践
模块化开发的最终目标是创建可复用、可维护和可扩展的代码库。
### 3.3.1 编写可复用的代码模块
编写可复用的代码模块要求开发者遵循以下原则:
- **解耦**: 确保模块之间的依赖最小化。
- **单一职责**: 每个模块只负责一项任务。
- **清晰的API**: 提供明确定义的接口供其他模块使用。
### 3.3.2 模块间的通信与接口定义
模块间的通信主要通过定义清晰的接口来实现。接口定义需要明确输入输出参数、异常处理以及模块间的协作方式。
- **接口文档**: 使用工具如Swagger或JSDoc来生成和维护接口文档。
- **类型安全**: 利用TypeScript等强类型语言增强接口间的类型检查。
- **事件驱动**: 对于需要异步通信的模块,事件驱动的编程模型可以提供灵活的解决方案。
### 3.3.3 持续集成与持续部署(CI/CD)
持续集成(CI)和持续部署(CD)是现代软件开发中的重要实践,旨在加快软件交付的效率。
- **CI**: 自动化构建和测试代码以确保在合并更改到主分支前不会引入错误。
- **CD**: 自动化软件发布流程,确保代码变更能够快速且安全地部署到生产环境。
下面是一个简化的GitHub Actions配置示例,展示如何自动运行测试和部署应用:
```yaml
name: CI/CD Pipeline
on:
push:
branches: [ master ]
pull_request:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.8'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install flake8 pytest
if [ -f requirements.txt ]; then pip install -r requirements.txt; fi
- name: Lint with flake8
run: |
# stop the build if there are Python syntax errors or undefined names
flake8 . --count --select=E9,F63,F7,F82 --show-source --statistics
# exit-zero treats all errors as warnings. The GitHub editor is 127 chars wide
flake8 . --count --exit-zero --max-complexity=10 --max-line-length=127 --statistics
- name: Test with pytest
run: |
pytest
```
在上述配置中,无论是主分支的推送还是Pull Request的操作,都会触发CI/CD流程,从代码拉取、依赖安装、代码检查到测试执行,最终可以配置额外步骤以部署到服务器或者发布到仓库。
模块化项目的CI/CD流程确保了模块化开发的代码质量、提高了交付速度,同时也增强了项目的可维护性和可扩展性。
# 4. 模块化项目架构在实战中的应用
模块化项目架构不仅仅是一个抽象的概念,它在实际开发过程中扮演着重要的角色。在本章节中,我们将通过案例分析、不同规模项目中的应用以及项目的维护与演进三个方面,深入探讨模块化项目架构在实战中的应用。
## 4.1 案例分析:成功的模块化项目架构
### 4.1.1 项目背景与模块划分
每个成功的项目背后,都有一个精心设计的架构。例如,某在线教育平台为了应对不断变化的市场需求和技术挑战,决定进行模块化改造。项目首先对现有的系统功能进行彻底的分析,划分出核心模块和附加模块。核心模块包括用户认证、课程管理、支付系统等,这些模块稳定且对外部服务依赖较小;附加模块则包括推荐系统、实时通讯、第三方服务集成等,这些模块可能会频繁变更以适应业务需求。
### 4.1.2 架构实施过程
架构的实施过程是一个分步骤的活动,逐步推进。在该案例中,实施过程首先从定义清晰的模块接口开始,使用统一的通信协议,确保模块间的解耦。然后,每个团队负责一个或多个模块的开发,通过定义接口契约(如API规范)来保证模块间的通信。此外,项目实施过程中,自动化测试被赋予了重要的角色,以确保各个模块的质量。
### 4.1.3 效果评估与优化
模块化实施完成后,项目团队进行了详尽的测试和评估。通过性能测试、压力测试以及用户接受度测试等,团队可以量化地评估新架构带来的性能提升和功能改进。基于反馈,团队对模块进行了持续优化,改进接口设计,增强模块的独立性和复用性。评估结果表明,模块化架构显著提高了开发效率,并降低了维护成本。
## 4.2 模块化在不同规模项目中的应用
### 4.2.1 小型项目中的模块化实践
小型项目往往资源有限,但模块化同样重要。在小型项目中,可以采取更简洁的模块化策略,比如将数据库操作、业务逻辑、前端视图分别作为独立的模块来开发。这样,即便是在资源受限的情况下,也能保持项目的清晰结构,便于未来的扩展和维护。
### 4.2.2 大型项目中的模块化挑战与对策
大型项目面临的模块化挑战更为复杂,比如服务间的协调、数据一致性、模块依赖等问题。解决这些挑战需要采用更先进的架构模式,如微服务架构,来实现服务的独立部署和扩展。此外,团队可以采用领域驱动设计(DDD)来明确不同模块的业务边界和责任。通过服务网格(如Istio)来管理服务间的通信,也是处理大型项目模块化问题的有效对策。
### 4.2.3 多团队协作下的模块化协同
在大型组织或跨团队协作中,模块化协同是关键。每个团队应专注于特定模块的开发和优化,同时遵循共享的设计原则和接口规范。利用持续集成/持续部署(CI/CD)管道可以实现自动化测试和部署,确保模块间的兼容性。而代码库的模块化管理(如使用Lerna或Yarn workspaces)可以帮助同步各个模块间的依赖,保持项目的一致性。
## 4.3 模块化项目架构的维护与演进
### 4.3.1 代码重构与模块化演进
随着业务的发展和技术的更新,模块化项目架构也需要不断地进行演进。通过定期的代码审查和重构,可以逐步改进模块的设计,提升模块的独立性和复用性。在这个过程中,采用语义化版本控制(Semantic Versioning)来管理模块版本,使得变更更加可控。
### 4.3.2 架构文档与知识共享
良好的架构文档对于项目的长期维护至关重要。项目需要维护清晰的文档,描述每个模块的功能、接口和依赖关系。此外,团队间的知识共享机制(如定期的技术分享会、内部文档库)可以帮助新成员快速上手,并促进团队成员之间的交流。
### 4.3.3 应对技术债务的策略
技术债务是每个项目都会面临的挑战,模块化架构也不例外。有效管理技术债务的策略包括设立技术债务委员会,定期审查代码库并识别重构机会;投资于工具和技术更新,以减少未来的维护成本;实施代码审查和质量保证流程,防止技术债务的产生。
```mermaid
graph LR
A[开始代码审查] --> B[识别重构机会]
B --> C[评估重构成本]
C --> D[制定重构计划]
D --> E[实施重构]
E --> F[更新架构文档]
F --> G[技术债务审查]
G --> H[技术更新投入]
H --> I[工具改进]
I --> J[优化质量保证流程]
J --> K[结束代码审查]
```
通过以上策略,项目团队能够在保持项目稳定性的同时,逐步提升项目的质量和技术水平,降低长期的技术债务风险。
在实战中应用模块化项目架构时,案例分析、不同规模项目中模块化实践的适应性、以及架构维护和演进的策略都起着至关重要的作用。下一章,我们将讨论提升开发效率的代码复用高级技巧,这些技巧可以帮助开发者更有效地利用模块化架构的优势。
# 5. 提升开发效率的代码复用高级技巧
## 5.1 设计模式在代码复用中的应用
设计模式是软件开发中解决特定问题的通用模板。它们有助于代码复用,同时增加代码的可读性和可维护性。在这一节,我们将深入探讨几种常见的设计模式及其在实现代码复用中的价值。
### 5.1.1 常见设计模式的复用价值
设计模式可以分为三大类:创建型模式、结构型模式和行为型模式。每种类型包含一系列特定的设计模式,适用于不同的场景。
- **创建型模式**:这一类模式的复用价值在于如何创建对象,它隐藏了实例化过程的细节。比如单例模式保证一个类只有一个实例,并提供一个全局访问点;工厂模式则用于创建对象,无需指定将要创建的对象的具体类。
- **结构型模式**:这类模式关注如何组合类和对象以获得更大的结构。例如,代理模式在不改变一个对象的功能前提下,为该对象提供一个代理或占位符;适配器模式则允许将一个类的接口转换成客户期望的另一个接口。
- **行为型模式**:这类模式关注对象之间的职责划分,例如策略模式允许在运行时选择算法的行为;观察者模式定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知。
### 5.1.2 设计模式在架构中的作用
在软件架构中,设计模式不仅有助于提升代码的可维护性和灵活性,还能够促进团队成员间的沟通。使用设计模式能够降低复杂性,使得代码结构更清晰,更易于其他开发者理解和使用。
例如,使用工厂模式可以让客户端在不知道具体实现的情况下创建对象,这在依赖反转、依赖注入等架构模式中非常有用。同样,策略模式通过定义一系列算法,并把它们一个个封装起来,使得它们可以互相替换,算法的变化不会影响到使用算法的客户。
### 5.1.3 设计模式的实践案例分析
在实践中,设计模式的应用能够解决各种设计问题。以一个简单的电商平台为例,我们可以使用单例模式来管理数据库连接,确保整个应用中只有一个数据库连接实例,提高资源的使用效率。
再比如,如果我们正在开发一个具有复杂用户界面的应用程序,我们可以使用观察者模式来实现一个事件驱动的交互方式,当用户执行一个操作时(如点击按钮),观察者模式可以通知所有相关组件更新其状态。
## 5.2 代码自动化生成工具的使用
### 5.2.1 代码生成器的基本原理
代码生成器是自动化工具,它们根据给定的输入和规则生成源代码。这些工具可以极大地提高开发效率,特别是在需要生成大量重复性代码的情况下。
自动化代码生成工具通常基于模板,这些模板中包含了一系列的占位符,用于在生成代码时替换为具体的数据。生成器读取这些模板,并根据用户输入的数据替换模板中的占位符,最终输出定制化的代码。
### 5.2.2 自动化代码生成工具的选型与使用
在选择自动化代码生成工具时,需要考虑以下几个方面:支持的编程语言、模板的灵活性、社区支持、文档和教程的可用性。
例如,Yeoman是一个广泛使用的Node.js工具,用于构建脚手架系统。开发者可以创建Yeoman生成器来自动化项目的初始化过程,包括安装依赖、配置文件和生成项目基础结构。
另一个例子是Swagger Codegen,它可以根据API的OpenAPI(以前称为Swagger)规范自动生成API客户端库、服务器存根、API文档等。对于前后端分离的项目,这可以大幅减少编写大量样板代码的工作。
### 5.2.3 提高代码生成效率的技巧
为了提高自动化代码生成的效率,开发者应当根据项目的特点和需求,定制生成器的模板,并利用工具提供的配置选项来精细调整生成代码的行为。
例如,可以使用JHipster来快速生成基于Spring Boot和Angular/React/Vue的项目。JHipster提供了一套丰富的预定义问题集,用于收集项目的定制信息,然后根据这些信息生成项目的基础代码结构。此外,通过编写自己的JHipster模块或使用现有的社区模块,可以进一步提高定制化和自动化水平。
## 5.3 持续学习与代码复用
### 5.3.1 学习新框架和库的策略
在快速变化的技术领域,持续学习是保持技能相关性的关键。理解如何高效学习新框架和库,对于代码复用至关重要,因为这些工具和技术通常是代码复用的基石。
高效学习的策略包括:
- **理解原理**:比学习语法更重要的是理解框架或库的工作原理。这有助于在需要的时候进行适当的定制和优化。
- **实践驱动**:通过实际项目来学习新技术。将学到的新技术应用到真实的工作场景中,可以加深理解和记忆。
- **社区参与**:加入相关的开发者社区,如GitHub、Stack Overflow和Reddit等。社区可以帮助你快速获得反馈,并从其他开发者的讨论中学习。
### 5.3.2 社区贡献与代码复用的良性循环
积极参与开源项目,无论是通过贡献代码、报告问题还是编写文档,都可以为社区做出贡献。社区贡献不仅能帮助其他开发者复用和改进代码,而且可以增加开发者个人的可见度,为职业生涯带来潜在的好处。
贡献代码时,应当遵循项目的贡献指南,确保代码的质量和一致性。此外,良好的沟通技巧和团队协作精神也是社区贡献成功的关键因素。
### 5.3.3 如何从开源项目中学习代码复用
开源项目是学习代码复用的宝库。通过阅读和分析开源项目的代码,可以了解如何在大型应用中组织和复用代码。以下是几个学习策略:
- **阅读文档**:理解项目文档,包括设计决策、架构描述和API说明,这有助于理解代码复用的具体实践。
- **代码审查**:参与代码审查过程,可以让你了解其他开发者是如何处理代码复用问题的。
- **重构实践**:尝试对现有的开源项目进行重构,以提高代码复用。在这个过程中,你可以实践设计模式和编写高质量代码的最佳实践。
通过这些方法,开发者可以从开源项目中学习到高级的代码复用技巧,并将这些知识应用到自己的工作中,从而提升开发效率。
# 6. 未来趋势与模块化开发的展望
## 6.1 模块化开发的新趋势
模块化开发一直在随着技术的进步而进化,新趋势的出现为这一实践领域带来了新的活力和挑战。
### 6.1.1 领域驱动设计(DDD)的影响
领域驱动设计(Domain-Driven Design,DDD)强调以业务领域为核心,将软件模型与业务概念对齐。在模块化开发中,这意味着模块需要更紧密地反映业务领域的边界和职责,从而提高软件的业务适应性和灵活性。DDD 提倡的限界上下文(bounded contexts)概念有助于明确模块间的界限,减少耦合,增强模块独立性。
### 6.1.2 微前端架构的兴起
微前端架构是现代前端开发中的一个新趋势,它借鉴了微服务的概念,提倡将前端应用分解为小的、可独立部署的模块,每个模块都有自己的生命周期,但它们共同协作形成一个完整的用户界面。这种架构模式能够提升前端开发的可维护性、可扩展性,并且支持多团队并行开发,是模块化理念在前端领域的具体应用。
### 6.1.3 云原生应用与模块化
云原生应用利用了云计算的优势,如容器化(containerization)、微服务架构、无服务器计算(serverless computing)等。在云原生的语境中,模块化开发不仅关乎代码结构,还关乎服务的部署、监控、扩展和管理。容器化技术让模块化开发更加便捷,微服务架构在云环境中天然具有模块化特征,而 serverless 架构则进一步抽象了模块化单元,使其更加轻量级和高效。
## 6.2 面向未来的架构设计
架构设计是模块化开发的核心,它决定了系统能否适应未来的变化。
### 6.2.1 适应性与可扩展性的重要性
随着市场和技术的快速变化,软件架构需要具备高度的适应性和可扩展性。模块化架构通过定义清晰的接口和组件职责,使得系统能够灵活地添加新功能或进行优化升级。这种能力对于应对不断变化的业务需求和技术环境至关重要。
### 6.2.2 代码复用与安全性考量
在追求模块化和代码复用的同时,安全性的考量也不容忽视。模块化开发需要确保模块间的数据交换是安全的,防止数据泄露和未授权访问。此外,代码库的持续更新也要确保不会引入新的安全漏洞。这需要在模块化设计时考虑安全架构,并持续进行代码审查和安全测试。
### 6.2.3 模块化开发的标准化与规范化
随着模块化开发实践的普及,标准化与规范化变得尤为重要。行业组织和社区应推动建立模块化开发的标准,包括编程规范、接口定义、测试方法等。这样的标准化有助于提高不同团队和项目间的协作效率,减少不必要的重复工作,同时推动整个行业的技术进步。
## 6.3 结语:模块化开发的长远意义
模块化开发不仅仅是一种技术实践,它的长远意义远远超出了软件开发本身,对开发者、软件行业乃至整个社会都有着深远的影响。
### 6.3.1 对开发者个人职业成长的影响
模块化开发鼓励开发者深入理解业务逻辑,注重代码质量和系统设计。这种实践促进了开发者的专业成长,提高了个人在技术领域的竞争力。同时,模块化也为开发者提供了更多的职业选择和机会。
### 6.3.2 对软件行业发展的推动作用
模块化推动了软件开发效率的提升和质量的改进,进而推动了整个软件行业的发展。它降低了开发门槛,提高了创新速度,帮助行业更快地适应市场和技术的变化。
### 6.3.3 构建更高效的软件交付生态
模块化开发促进了代码的复用,减少了重复劳动,提高了软件交付效率。这种高效的开发模式是构建现代软件交付生态的重要基石,有助于打造更加敏捷、灵活和创新的企业。
模块化开发的未来充满着机遇与挑战,这一领域的发展势必会为IT行业带来更为深远的变革。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“GitHub项目的最佳实践与经验分享”专栏。本专栏旨在为开发人员提供有关在GitHub上管理项目和团队的宝贵见解和实践指南。
专栏文章涵盖了广泛的主题,包括:
* **高效协作的GitHub工作流程:**探索最佳实践,以优化团队协作和版本控制策略。
* **代码复用策略:**了解如何利用GitHub构建模块化项目架构,提高开发效率。
通过这些文章,您将获得提升GitHub项目管理技能所需的知识和技巧,从而提高团队效率、代码质量和项目成功率。
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MAC版SAP GUI安装与配置秘籍】:一步到位掌握Mac上的SAP GUI安装与优化
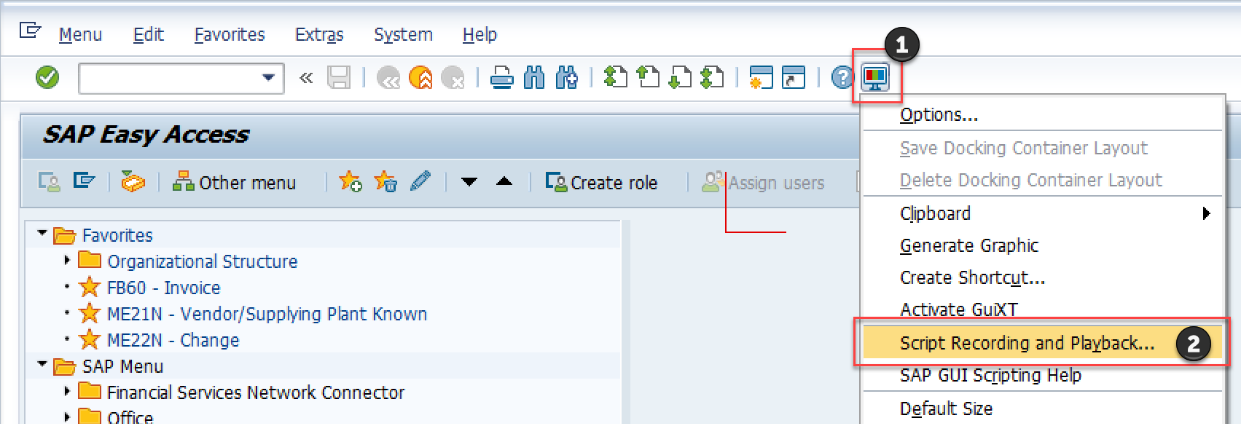
参考资源链接:[MAC版SAP GUI快速安装与配置指南](https://wenku.csdn.net/doc/6412b761be7fbd1778d4a168?spm=1055.2635.3001.10343)
# 1. SAP GUI简介及安装前准备
## 1.1 SAP G
BIOS故障恢复:面对崩溃时的恢复选项与技巧
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2018/P/j/8qyRn6Q1WEr2jdkn3h6Q/m4.jpg)
参考资源链接:[Beyond BIOS中文版:UEFI BIOS开发者必备指南](https://wenku.csdn.
硬件维修秘籍:破解联想L-IG41M主板的10大故障及实战解决方案
参考资源链接:[联想L-IG41M主板详细规格与接口详解](https://wenku.csdn.net/doc/1mnq1cxzd7?spm=1055.2635.3001.10343)
# 1. 硬件维修基础知识与主板概述
在硬件维修领域,掌握基础理论是至关重要的第一步。本章将介绍硬件维修的核心概念,并对主板进行基础性的概述,为后续更深入的维修实践奠定坚实的基
MSFinder数据处理:批量文件处理,效率提升50%的秘诀!

参考资源链接:[使用MS-FINDER进行质谱分析与化合物识别教程](https://wenku.csdn.net/doc/6xkmf6rj5o?spm=1055.2635.3001.10343)
# 1. MSFinder数据处理概述
## 1.1 数据处理的重要性
在现代IT行业,数据处理作为数据科学的核心组成部分,关系到数据分析的准确性和效率。MSFinder作为一种专门的处理工具,旨在帮
FEKO案例实操进阶:3个步骤带你从新手到实践高手

参考资源链接:[FEKO入门详解:电磁场分析与应用教程](https://wenku.csdn.net/doc/6h6kyqd9dy?spm=1055.2635.3001.10343)
# 1. FEKO软件概述与基础入门
## 1.1 软件简介
FEKO是一款用于复杂电磁场问题求解的高频电磁模拟软件,它提供了一系列先进的解决方案,包括基于矩量法(MoM)、多层快速多极子方法(MLFMM)、物
【ZKTime考勤数据库性能调优】:慢查询分析与优化策略

参考资源链接:[中控zktime考勤管理系统数据库表结构优质资料.doc](https://wenku.csdn.net/doc/2phyejuviu?spm=1055.2635.3001.10343)
# 1. ZKTime考勤系统概述
在当今数字化时代,考勤系统已经成为企业日常管理不可或缺
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )