数据结构实践:文具店货品管理系统的高效策略
发布时间: 2025-01-05 14:20:14 阅读量: 9 订阅数: 11 

算法与数据结构课程设计 文具店的货品管理系统的设计.doc

# 摘要
本文探讨了数据结构在货品管理系统中的核心作用,深入解析了核心数据结构和算法,如栈、队列、树结构和图论,并分析了它们在管理系统中的实际应用。同时,详细讨论了货品管理系统数据库设计的原则和操作实践,包括索引技术、缓存机制、数据分析自动化等方面来提高数据处理和查询的效率。文章还探讨了系统开发过程中面临的挑战,如数据迁移、高并发处理和用户体验优化,并提出相应的解决方案。通过这些分析,本文旨在为货品管理系统提供理论依据和实践指导,以实现更高效的数据管理和更好的用户体验。
# 关键字
数据结构;算法解析;数据库设计;查询优化;系统开发;用户体验
参考资源链接:[文具店库存管理系统设计:算法与数据结构应用](https://wenku.csdn.net/doc/65v5sbh098?spm=1055.2635.3001.10343)
# 1. 数据结构在货品管理系统中的重要性
## 简介
在货品管理系统中,数据结构不仅是存储货品信息的基础,更是系统效率和功能实现的关键。合理选择和优化数据结构能够显著提升数据处理的速率,降低系统资源消耗,并直接影响到货品管理的效能与准确性。
## 数据结构的核心作用
数据结构包括数组、链表、栈、队列、树、图等,每种数据结构有其特定的用途。例如,栈和队列适用于处理具有先进先出(FIFO)或后进先出(LIFO)特性的货品数据,如生产调度和订单处理。树结构,特别是二叉搜索树,可以高效地进行货品信息的查找和排序操作。而图结构则适用于描述货品之间的复杂关系,如货品之间的物流配送路径。
## 实践意义
在实际的货品管理系统中,如何选择合适的数据结构至关重要。一个优秀的系统会根据货品管理的需求,设计出既能满足查询和存储需求又能优化处理速度的数据结构方案。通过精心设计的数据结构,不仅能够提高数据检索效率,还能提升整体系统的运行速度和稳定性,最终给用户带来更加顺畅的操作体验和高效准确的货品管理服务。
这一章节深入浅出地介绍了数据结构在货品管理系统中的重要性,为接下来详细介绍核心数据结构及其优化方式奠定了基础。
# 2. 核心数据结构与算法解析
## 2.1 栈和队列的基础理论与应用场景
### 2.1.1 栈的基本操作和实现机制
栈是一种后进先出(LIFO)的数据结构,它只有两个操作:压栈(push)和弹栈(pop),分别用于添加和移除栈顶元素。栈的应用非常广泛,如浏览器的后退功能、撤销操作等。
在程序中,栈可以通过数组或链表实现。使用数组时,有一个指针始终指向栈顶元素的位置,压栈操作是将元素放到指针的位置并更新指针,弹栈操作则是返回栈顶元素,并更新指针到下一个元素的位置。
下面是一个使用数组实现栈的简单示例:
```python
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return len(self.items) == 0
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
return None
def peek(self):
if not self.is_empty():
return self.items[-1]
return None
def size(self):
return len(self.items)
```
在实现栈时,需要特别注意栈溢出的情况,即当栈为空时执行弹栈操作,或者栈已满时执行压栈操作。
### 2.1.2 队列的原理及在管理系统的应用
队列是一种先进先出(FIFO)的数据结构,它有两个主要操作:入队(enqueue)和出队(dequeue)。队列常用于任务调度、缓冲处理、消息系统等领域。
队列可以通过数组或链表实现,其中,数组实现的队列需要两个指针,一个指向队首元素,另一个指向队尾元素的下一个位置。
下面是一个使用数组实现的简单队列示例:
```python
class Queue:
def __init__(self):
self.items = []
def is_empty(self):
return len(self.items) == 0
def enqueue(self, item):
self.items.append(item)
def dequeue(self):
if not self.is_empty():
return self.items.pop(0)
return None
def size(self):
return len(self.items)
```
在使用队列时,需要考虑的特殊情况是队列空时出队操作,以及队列满时入队操作。
## 2.2 树结构及其优化存储方式
### 2.2.1 二叉树与多叉树的区别和选择
二叉树是每个节点最多有两个子节点的树结构,其中左子树和右子树有明显的顺序之分。二叉树适用于需要快速查找和排序的场景,如二叉搜索树(BST)。
多叉树则是每个节点可以有两个以上子节点的树结构。在某些情况下,多叉树可以更有效地存储和管理数据,特别是当一个节点的子节点数量远超过两个时,如B树和B+树等。
选择二叉树还是多叉树取决于具体的应用场景和数据特性。如果数据的插入和查找操作非常频繁,且数据量不是非常大,二叉树通常能提供更快的操作速度。对于需要存储大量数据且对磁盘读写效率要求较高的情况,多叉树可能是更好的选择。
### 2.2.2 哈夫曼树在数据压缩中的应用
哈夫曼树是一种带权路径长度最短的二叉树,它是哈夫曼编码的基础,广泛应用于数据压缩领域。哈夫曼编码是一种变长编码方法,对于出现频率高的数据使用较短的编码,出现频率低的使用较长的编码。
构建哈夫曼树的过程是从底向上逐步合并权值最小的两个节点,形成一个新的节点作为它们的父节点,其权值是两个子节点权值之和,不断重复这个过程直到只剩下一个节点。
构建哈夫曼树的代码示例如下:
```python
import heapq
class Node:
def __init__(self, char, freq):
self.char = char
self.freq = freq
self.left = None
self.right = None
def __lt__(self, other):
return self.freq < other.freq
def build_huffman_tree(text):
frequency = {}
for char in text:
if char not in frequency:
frequency[char] = 0
frequency[char] += 1
priority_queue = [Node(char, freq) for char, freq in frequency.items()]
heapq.heapify(priority_queue)
while len(priority_queue) > 1:
left = heapq.heappop(priority_queue)
right = heapq.heappop(priority_queue)
merged = Node(None, left.freq + right.freq)
merged.left = left
merged.right = right
heapq.heappush(priority_queue, merged)
return priority_queue[0]
```
哈夫曼编码可以大幅减少数据的存储空间,尤其在进行文件压缩、网络传输等领域具有重要应用。
## 2.3 图论在货品流动分析中的应用
### 2.3.1 图的基本概念与表示方法
图是由一组顶点(节点)和一组连接顶点的边组成的数学结构,用于表示元素之间的关系。在货品管理系统中,可以将货品仓库看作顶点,而货品的运输路线看作边,以此来分析货品流动。
图有多种表示方法,常用的有邻接矩阵和邻接表。邻接矩阵是一种二维数组,图中的每行和每列对应一个顶点,矩阵中的元素表示两个顶点之间是否存在边。邻接表则是一个由链表或数组组成的列表,每个顶点对应一个链表,链表中存储与该顶点相连的其他顶点。
### 2.3.2 最短路径算法在货品调度中的应用
最短路径算法用于在加权图中找到两个顶点之间的最短路径,Dijkstra算法是最常见的算法之一。该算法适用于没有负权边的图,并可以处理有向图和无向图。
Dijkstra算法的步骤是:首先为所有节点设定一个初始距离值,然后在未访问的节点中选取距离最小的节点进行松弛操作。松弛操作指的是,通过当前节点更新其他节点到源点的距离,如果更新后的距离更短,则更新距离并标记该节点已访问。
以下是Dijkstra算法的简单代码示例:
```python
import heapq
def dijkstra(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
if current_distance > distances[current_vertex]:
continue
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'C': 2, 'D': 5},
'C': {'A': 4, 'B': 2, 'D': 1},
'D': {'B': 5, 'C': 1}
}
print(dijkstra(graph, 'A'))
```
在货品管理系统中,最短路径算法可以帮助优化货品调度,提高物流效率,降低运输成本。
# 3. 货品管理系统的数据库设计
在现代的货品管理系统中,数据库设计是保证系统稳定运行和高效数据处理的核心。一个结构合理、性能优良的数据库,不仅可以确保数据的准确性和一致性,还能提高查询效率和业务处理能力。本章节将深入探讨数据库设计的各个方面,包括数据库表结构设计原则、关系型数据库操作实践以及数据库备份与恢复策略。
## 数据库表结构的设计原则
数据库表结构的设计直接影响到系统的性能和维护性。合理的表结构设计可以减少数据冗余,提高数据处理速度,优化存储空间,同时还能增强系统的扩展性和灵活性。
### 货品信息表的设计与优化
货品信息表是货品管理系统中最为核心的数据结构之一,它需要存储货品的详细信息,包括但不限于货品名称、编号、规格、库存数量、价格等。设计这样的表结构,首先要考虑到信息的完整性、更新频率以及查询需求。
为了保证信息的完整性,货品信息表应包含所有必要的字段,并使用合适的字段类型。例如,货品编号字段应该设置为主键,以保证唯一性。此外,使用枚举类型或选择类型字段来存储固定范围内的数据(如货品状态或分类),可以减少数据输入错误,并提高查询效率。
在查询效率方面,可以针对常用的查询操作创建索引,如货品名称和分类字段,以加快查找速度。但是,索引数量和选择应当适度,过多的索引会增加数据维护成本和写入性能的负担。
在设计货品信息表时,还需考虑到未来可能的扩展需求。例如,如果将来需要跟踪货品的批次信息,应该预先设计相关字段。同时,应该避免过度设计,保持结构简洁,易于维护。
```sql
CREATE TABLE ProductInfo (
ProductID INT PRIMARY KEY AUTO_INCREMENT,
ProductName VARCHAR(100) NOT NULL,
ProductNumber VARCHAR(50) UNIQUE,
Specification VARCHAR(200),
Quantity INT DEFAULT 0,
Price DECIMAL(10, 2),
Category ENUM('Electronics', 'Clothing', 'Books', ...),
-- 添加其他相关字段,如批次信息等
INDEX idx_product_name (ProductName),
INDEX idx_category (Category)
);
```
上述SQL语句展示了创建货品信息表的基本结构,并包含了主键、唯一约束以及索引的创建。这样设计能够满足货品信息的存储需求,同时优化查询效率。
### 订单和库存管理表的设计要点
订单表和库存管理表是货品管理系统中不可或缺的部分,用于跟踪货品的销售和存储情况。订单表记录客户的购买信息,包括订单号、购买货品详情、数量、价格、客户信息以及订单状态等。库存管理表则记录货品的实时库存情况,以及货品的入库和出库记录。
设计订单表时,订单号应设置为主键,通常采用自增或 UUID 等方式生成,以保证每笔订单的唯一性。订单详情可以采用一对多的关系,使用子表来存储货品详情。这样不仅可以简化订单表结构,还能提高查询效率,尤其是在处理含有大量货品的订单时。
库存管理表的设计应该能够反映实时库存变化,并且便于记录货品的出入库操作。在表中应包含货品ID、操作类型(入库或出库)、操作数量、操作时间等字段。为了保证库存数据的准确性,库存管理表的操作过程应该是事务性的,确保每个操作要么完全成功,要么完全不发生。
```sql
CREATE TABLE Orders (
OrderID INT PRIMARY KEY AUTO_INCREMENT,
OrderNumber VARCHAR(50) UNIQUE,
CustomerID INT,
OrderStatus ENUM('Pending', 'Shipped', 'Delivered', 'Cancelled'),
-- 添加其他相关字段
FOREIGN KEY (CustomerID) REFERENCES Customers(CustomerID)
);
CREATE TABLE InventoryManagement (
InventoryID INT PRIMARY KEY AUTO_INCREMENT,
ProductID INT,
OperationType ENUM('In', 'Out'),
QuantityChange INT,
OperationTime DATETIME,
-- 添加其他相关字段
FOREIGN KEY (ProductID) REFERENCES ProductInfo(ProductID)
);
```
在上述SQL代码中,`Orders` 表用于存储订单信息,而 `InventoryManagement` 表用于跟踪货品的库存变化。通过使用外键约束,确保数据的一致性,同时将操作时间记录在案,以追踪库存变化历史。
## 关系型数据库的操作与实践
关系型数据库是货品管理系统中处理和存储数据的核心工具。通过使用结构化查询语言(SQL),数据库管理员和开发人员可以执行数据的增删改查(CRUD)操作,实现业务逻辑,并生成相应的报告。
### SQL语句在货品查询中的运用
SQL是关系型数据库管理的标准语言,用于管理和操作数据库中的数据。在货品管理系统中,SQL语句被广泛用于查询货品信息、订单详情以及库存状态等。
最简单的SQL操作是查询,通过`SELECT`语句可以实现。例如,查询所有货品的名称和价格,可以使用如下SQL语句:
```sql
SELECT ProductName, Price FROM ProductInfo;
```
如果需要根据特定条件查询数据,可以使用`WHERE`子句添加过滤条件。例如,查询价格超过某个阈值的所有货品:
```sql
SELECT ProductName, Price FROM ProductInfo WHERE Price > 100.00;
```
为了实现复杂的查询,可以使用联结(`JOIN`)操作,将多个表中的数据结合在一起进行查询。例如,要查看所有已发货订单的货品详情,可以将订单表与货品信息表联结:
```sql
SELECT o.OrderNumber, p.ProductName, p.Price, o.OrderStatus
FROM Orders o
JOIN ProductInfo p ON o.ProductID = p.ProductID
WHERE o.OrderStatus = 'Shipped';
```
在上述查询中,我们使用了内联结(`INNER JOIN`)来查询所有已发货订单的相关货品信息。通过这种方式,可以实现业务逻辑的复杂查询需求。
### 触发器和存储过程在业务逻辑中的实现
在货品管理系统中,为了保证数据的完整性和业务流程的自动化,常会使用数据库触发器和存储过程。触发器是一种特殊类型的存储过程,会在数据库表上的特定事件发生时自动执行,如 INSERT、UPDATE 或 DELETE 操作。它们通常用于实现数据校验、日志记录以及自动更新相关的业务规则。
```sql
DELIMITER $$
CREATE TRIGGER BeforeProductInsert
BEFORE INSERT ON ProductInfo
FOR EACH ROW
BEGIN
IF NEW.Price <= 0 THEN
SIGNAL SQLSTATE '45000' SET MESSAGE_TEXT = 'Price cannot be less than or equal to zero';
END IF;
END$$
DELIMITER ;
```
在上述代码示例中,创建了一个触发器`BeforeProductInsert`,用于在向`ProductInfo`表插入新记录之前检查价格字段。如果价格小于或等于零,则触发器会阻止插入操作并报错。
存储过程则是一组为了完成特定功能的SQL语句集,它存储在数据库中,可以由应用程序调用执行。存储过程可以包含复杂的逻辑,并且能够接收参数和返回结果集。例如,当需要生成订单和库存变动报告时,可以创建一个存储过程来处理这一流程。
```sql
DELIMITER $$
CREATE PROCEDURE GenerateOrderReport(IN startDate DATE, IN endDate DATE)
BEGIN
SELECT o.OrderNumber, o.OrderDate, o.OrderStatus, SUM(od.Quantity * od.Price) AS TotalValue
FROM Orders o
JOIN OrderDetails od ON o.OrderID = od.OrderID
WHERE o.OrderDate BETWEEN startDate AND endDate
GROUP BY o.OrderNumber;
END$$
DELIMITER ;
```
上述代码创建了一个名为`GenerateOrderReport`的存储过程,用于生成指定日期范围内所有订单的报告。通过指定开始和结束日期作为参数,存储过程执行联结操作和聚合函数,计算并返回订单总价值。
## 数据库的备份与恢复策略
数据库的备份和恢复是保证数据安全和业务连续性的重要策略。定期备份可以帮助系统在遇到数据丢失或损坏时迅速恢复,减少业务中断的时间和损失。
### 定期备份的重要性和方法
数据库的备份应该定期执行,并且备份策略要根据数据变化频率、业务重要性以及恢复时间目标(RTO)和恢复点目标(RPO)来制定。
常见的备份方法包括完全备份、增量备份和差异备份。完全备份是备份整个数据库,适用于首次备份或数据量不大时。增量备份仅备份自上次备份以来发生变化的数据,适用于数据变化频繁的场景。差异备份则备份自上次完全备份以来发生变化的数据,相比增量备份,恢复时间更短,但备份时间较长。
数据库管理员应根据实际情况选择合适的备份策略,并使用自动化工具定期执行备份任务。例如,在MySQL中,可以使用`mysqldump`工具来执行完全备份:
```bash
mysqldump -u username -p database_name > backup_file.sql
```
在上述命令中,`username`是数据库用户名,`database_name`是数据库名称,而`backup_file.sql`是备份文件的名称。
### 恢复策略和数据完整性保障
在数据丢失或损坏的情况下,及时而正确的恢复操作能够最大程度减少损失。恢复策略应该事先规划好,并在数据库备份时一起考虑。关键是要确保恢复过程的可靠性和数据的完整性。
在恢复数据时,首先应该确认备份文件的完好性,然后根据备份类型选择合适的恢复方法。对于完全备份,恢复操作相对简单,只需将备份文件导入数据库即可。但对于增量或差异备份,则需要先导入最近的完全备份,然后再依次导入相应的增量或差异备份。
```sql
mysql -u username -p database_name < backup_file.sql
```
上述命令使用`mysql`命令行工具将备份文件导入到指定的数据库中,恢复数据。数据库管理员应该在恢复过程中监控操作,确保所有数据正确恢复,并进行数据完整性的校验。
在执行恢复操作后,还需要检查相关的索引、触发器和存储过程等是否也得到正确的恢复,保证业务逻辑的完整性和数据的一致性。这可能需要重新创建或执行相关数据库对象的初始化脚本。
总之,货品管理系统的数据库设计必须综合考虑数据的存储需求、业务操作的复杂性和数据安全的重要性。通过合理设计表结构、充分利用关系型数据库的功能和制定合适的备份与恢复策略,可以确保系统的稳定性和数据的可靠性。
# 4. 高效的数据处理与查询优化
## 索引技术在提升查询效率中的角色
索引技术是数据库管理系统中用于提高数据检索速度的重要工具。通过索引,数据库可以迅速定位到数据表中记录的位置,而不需要进行全表扫描,大大提升了查询效率。索引的创建和维护是数据库性能优化的基石之一。
### 索引的创建和维护
创建索引时,我们需要考虑几个关键因素:
- **选择合适的列:** 索引应创建在经常作为查询条件的列上,例如,经常用于搜索、排序或分组的列。
- **考虑数据的唯一性:** 对于具有唯一值的列建立索引,通常可以提供更好的查询性能。
- **索引类型的选择:** 根据数据和查询的特点选择合适的索引类型,比如B-tree、Hash或者Full-text索引。
下面是一个创建索引的SQL示例:
```sql
CREATE INDEX idx_product_name ON products(name);
```
在这个例子中,我们为`products`表的`name`列创建了一个名为`idx_product_name`的索引。这个索引将会加快基于产品名称的查询速度。
创建索引后,也需要进行适当的维护:
- **定期重建索引:** 索引会随着数据的增删改而变得碎片化,定期重建索引可以优化索引结构,提高查询效率。
- **删除不必要的索引:** 过多的索引会占用额外的空间并且可能降低数据更新操作的效率,因此应当定期审查并删除不再需要的索引。
### 索引类型及其对性能的影响
索引类型的选择对数据库性能有着直接影响。最常用的索引类型包括B-tree、Hash以及Full-text索引。
- **B-tree索引:** 适用于全值匹配的查询以及最左前缀匹配,通常用于有序数据的检索,是最常见的索引类型。
- **Hash索引:** 提供快速的等值查询,但不支持范围查询,并且由于其哈希表的特性,它不保证有序。
- **Full-text索引:** 用于全文搜索,支持复杂的文本搜索查询,适用于文本类型的数据检索。
理解不同索引类型的特点,根据实际查询需求选择最合适的索引,是提高数据库查询性能的关键。
## 缓存机制的应用与效果评估
缓存是一种存储技术,它能够临时存储频繁访问的数据,从而减少数据库的访问次数,加快数据访问速度。在Web应用和数据库管理中,缓存已经成为提升性能的重要手段。
### 缓存策略与数据库性能
缓存策略通常涉及以下几个核心概念:
- **缓存命中率:** 表示缓存中数据被访问的频率,命中率越高,说明缓存的效果越好。
- **缓存失效策略:** 当缓存空间不足时,需要采用一定的算法淘汰旧的缓存数据,常用的缓存失效策略包括LRU(最近最少使用)和FIFO(先进先出)。
- **缓存穿透和缓存雪崩:** 这是两个影响缓存性能和数据库稳定性的问题,需要通过策略加以避免或减少影响。
例如,在Memcached或Redis中设置缓存失效策略可以保证缓存的效率:
```sh
# 设置键值过期时间
SETEX cache_key 500 100
```
上述命令设置了键`cache_key`的值为100,并且在500秒后过期。
### 常见缓存解决方案的比较
目前市场上有许多缓存解决方案,包括分布式缓存、内存数据库和传统缓存系统。常见的解决方案有Memcached、Redis和Ehcache等。下面是一个简单的比较表格:
| 特性 | Memcached | Redis | Ehcache |
|------------|-----------|---------|-----------|
| 数据类型 | 简单的键值对 | 字符串、列表、集合、有序集合等 | 键值对、可选的持久化 |
| 持久化 | 不支持 | 支持 | 支持(可选) |
| 复制 | 不支持 | 支持 | 不支持 |
| 多数据中心 | 不支持 | 支持 | 不支持 |
| 性能 | 高 | 高 | 中等 |
每种缓存解决方案都有其特点和使用场景,选择合适的产品要根据实际的应用需求和环境进行。
## 数据分析与报告生成的自动化
数据分析和报告生成是货品管理系统中不可或缺的一部分,自动化这些过程可以节省时间,提高效率,并为决策提供支持。自动化工具的使用减少了人工干预,确保了数据处理的一致性和准确性。
### 利用ETL进行数据抽取、转换和加载
ETL(Extract, Transform, Load)是一个重要的数据处理流程,用于将数据从源系统提取出来,经过转换使之适合目标环境,然后加载到目标系统中去。这个过程的自动化对于维护数据仓库和数据湖至关重要。
- **数据抽取:** 确定需要抽取的数据源,抽取数据可以来自不同的数据库或者文件系统。
- **数据转换:** 数据在加载前需要转换为适合目标系统的格式,包括清洗、格式化和数据类型转换等。
- **数据加载:** 将转换后的数据加载到目标数据库或者数据仓库中。
在实际应用中,可以使用像Talend、Informatica或开源的Apache NiFi等工具来实现ETL流程的自动化。
### 自动化报告工具的集成与效果监控
报告是展示数据分析结果的一种方式,通过集成自动化报告工具,可以实现报告的定期生成和分发。工具如Tableau、Power BI和Pentaho等都能够提供这样的服务。
- **报告模板的创建:** 预定义报告的布局和数据源,使得报告的生成更加迅速和规范。
- **报告的自动化分发:** 根据需要将报告自动发送给相关的利益相关者。
- **监控和报警:** 监控报告生成的过程,当发生错误或异常时,通过邮件、短信或应用内通知等方式进行报警。
自动化报告工具的使用不仅提高了工作效率,还能够确保数据的及时更新和准确传达。
通过实现数据处理和报告生成的自动化,货品管理系统可以更快地响应市场变化,更好地支持管理层的决策过程。
# 5. 系统开发与实践中的挑战与解决方案
在IT领域,尤其是货品管理系统开发过程中,我们经常面临着众多挑战。这些挑战可能源于技术的局限性、业务需求的不断变化,或是现有系统架构的性能瓶颈。如何应对和解决这些挑战,是衡量一个团队专业能力的重要指标。本章节将深入探讨在系统开发与实践中可能遇到的问题,并提供解决方案,以期帮助读者优化自身的产品和提升整体用户体验。
## 5.1 系统升级与数据迁移的策略
### 5.1.1 数据迁移过程中的常见问题及解决方案
在系统升级或迁移到新平台的过程中,数据迁移是一个不可避免的环节。数据迁移的复杂性往往与数据量的大小成正比,而且迁移过程中可能会遇到数据丢失、数据不一致、中断服务等问题。为了减少这些问题的发生,应采取以下策略:
- **详细规划:** 在开始迁移之前,制定详尽的数据迁移计划,包括数据量估算、迁移时间窗口、数据校验方法等。
- **逐步迁移:** 对于大规模的数据迁移,应采取分批次、分阶段的方式进行,以减少单次迁移的风险。
- **数据备份:** 迁移前做好数据备份,确保数据的安全性。
- **数据清洗:** 在迁移前进行数据清洗,确保迁移的数据是准确和完整的。
- **恢复策略:** 准备好数据迁移失败时的恢复策略和应急预案。
### 5.1.2 系统平滑升级的方法和实践案例
系统升级的目的是为了引入新的功能、提升性能或者修复已知的漏洞。为了保证升级过程中系统的稳定性和用户使用体验,以下是平滑升级的方法和实践案例:
- **蓝绿部署:** 同时运行两个生产环境,一个旧版本(绿),一个新版本(蓝)。升级时,直接切换流量到新版本,旧版本保持运行以备不时之需。
- **灰度发布:** 先将新版本部署到少部分用户中进行测试,逐步扩大覆盖范围。
- **回滚机制:** 升级过程中出现问题时,应有快速回滚到旧版本的能力,保证服务不中断。
- **监控升级过程:** 升级时需要密切监控系统性能和用户反馈,快速响应可能出现的问题。
## 5.2 高并发处理与系统性能优化
### 5.2.1 高并发场景下的数据结构优化
在高并发场景下,数据结构的选择和优化对于性能至关重要。一些常见的数据结构优化方法包括:
- **读写分离:** 通过主从复制等方式,将读和写操作分离到不同的服务器,减轻单点压力。
- **缓存应用:** 利用缓存系统(如Redis)减少对数据库的直接访问,提高数据读取速度。
- **异步处理:** 对于耗时的计算任务或外部服务调用,采用异步处理方式,避免阻塞主线程。
- **使用合适的数据结构:** 根据实际需求选择合适的数据结构,例如使用哈希表快速定位数据,使用队列处理任务序列等。
### 5.2.2 性能监控工具的使用和优化建议
为了确保系统在高并发下的稳定性和响应速度,性能监控工具的使用是必不可少的。以下是几种常见的性能监控工具以及优化建议:
- **Prometheus + Grafana:** Prometheus负责收集系统指标,Grafana提供可视化图表,方便实时监控和问题定位。
- **New Relic:** 提供应用性能管理(APM)解决方案,可以帮助开发者快速发现和解决性能瓶颈。
- **ELK Stack:** 通过Elasticsearch、Logstash和Kibana组合,可以对系统日志进行实时分析和可视化展示。
- **优化建议:** 结合监控工具提供的数据,定期进行性能调优。例如,通过分析瓶颈,调整数据库查询语句或优化代码逻辑。
## 5.3 用户体验与交互设计的优化
### 5.3.1 用户界面的友好性改进
用户体验的优化往往从界面友好性开始。以下是一些改进用户界面的方法:
- **简洁明了:** 减少页面元素,确保用户能快速找到所需信息。
- **一致性和标准:** 遵循设计原则和标准,保持界面元素的一致性,降低用户的学习成本。
- **响应式设计:** 确保界面在不同设备和分辨率下都能良好显示。
- **优化交互流程:** 分析用户交互流程,减少操作步骤,提供智能提示和快捷操作。
### 5.3.2 增强用户交互体验的技术与策略
用户交互体验的提升往往需要一些技术手段和策略的支持。例如:
- **实时反馈:** 在用户操作后提供即时反馈,如弹窗提示、进度条显示等。
- **个性化定制:** 根据用户历史行为和偏好提供个性化内容和推荐。
- **交互式帮助:** 设计交互式的帮助指南,引导用户更好地使用系统。
- **用户体验地图:** 创建用户体验地图,从用户视角出发,发现并解决体验问题。
在实践中,系统开发团队需要不断面对和解决这些挑战,以持续提升产品的稳定性和用户满意度。无论是数据迁移、性能优化还是用户体验改进,都需要有系统的方法和灵活的策略,才能在变化多端的IT行业中脱颖而出。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了文具店货品管理系统的设计,涵盖了从算法优化到数据结构实践、面向对象设计、数据库设计、系统分析、架构设计、异常处理、测试策略、敏捷开发、技术选型、版本控制、文档编写和性能监控等各个方面。通过对这些关键领域的深入解析,专栏旨在为读者提供全面的指导,帮助他们构建稳定、高效且可扩展的文具店货品管理系统。该专栏结合了理论知识和实际案例,为读者提供了在实践中应用这些概念所需的知识和技能。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
汽车电子EMC设计:遵循CISPR 25标准的终极指南(原理+应用挑战)

# 摘要
汽车电子EMC(电磁兼容性)设计是确保车辆在电磁干扰环境中可靠运行的关键技术。本文首先概述了汽车电子EMC设计的基本原则和策略,随后深入解析了CISPR 25这一行业标准,包括其历史演变、最新版本的影响以及对发射和抗扰度测试的具体要求。文中还探讨了EMC设计实践,强调了在硬件设计中的EMC优化、元件选择和布局的重要性,以及软件在EMC中的作用。最后,文章针对当前汽车电子EMC面临的挑战提出了分析与应对策略,并讨论了新兴技术对未来EMC设计
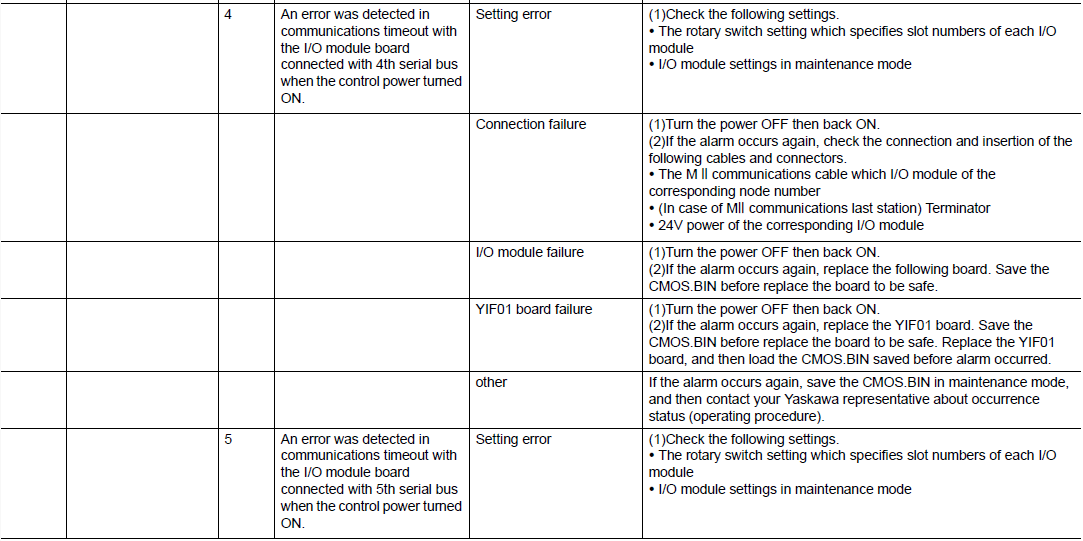
dx200并行IO故障快速诊断:电压极限椭圆问题深度解析
# 摘要
本文首先概述了dx200并行IO技术的基础知识,随后深入探讨了电压极限椭圆问题的理论基础及其在IO中的作用。文章分析了影响电压极限椭圆问题的多种因素,包括环境条件、硬件故障和软件配置错误,并提出了检测与监控的方法和策略。进一步,本文详细阐述了电压极限椭圆问题的诊断流程,包括现场快速诊断技巧、数据分析与问题定位,并分享了解决方案与案例分析。此外,文章还探讨了预防措施与维护策略,旨在通过
如何通过需求规格说明书规划毕业设计管理系统的功能模块:专家级解决方案

# 摘要
需求规格说明书在毕业设计管理中扮演着至关重要的角色,它确保了项目目标的明确性和可执行性。本文首先解释了需求规格说明书的构成和内容,包括功能性需求与非功能性需求的划分以及需求的优先级,随后探讨了其编写方法,如用户故事和用例图的制作,以及需求确认和验证过程。接着,文章分析了需求规格说明书的管理流程,包括版本控制、变更管理、需求追踪和跟踪。进一步地
高频电子线路实验报告编写精要:专家推荐的6大技巧与注意事项

# 摘要
本文旨在阐述实验报告撰写的目的、结构、格式要求及其重要性,并提供提高实验报告质量的实用技巧。文章详细介绍了实验报告的基础结构和格式规范,强调了标题与摘要撰写、主体内容编排、数据记录与分析的重要性。同时,本文也探讨了图表和引用的规范性,以及理论与实验结合、审稿与完善、创新点与亮点的呈现。针对实验报告中常见的问题,如错误避免、反馈利用和时间管理,文章提供了针对性的解决策略。本文旨在为撰写高质量的实验报告提供全面
AUTOSAR与UDS实战指南:最佳实践案例,深入解析与应用

# 摘要
本文旨在提供对AUTOSAR和UDS(统一诊断服务)的全面介绍和分析。首先,概述了AUTOSAR的基本原理和架构,以及其软件组件设计和工具链。接着,详细探讨了UDS协议的标准、服务、诊断功能及其在车辆网络中的应用。随后,文章通过实战案例分析,解释了AUTOSAR在嵌入式系统中的实施过程,以及UDS诊断功能的实现和测试
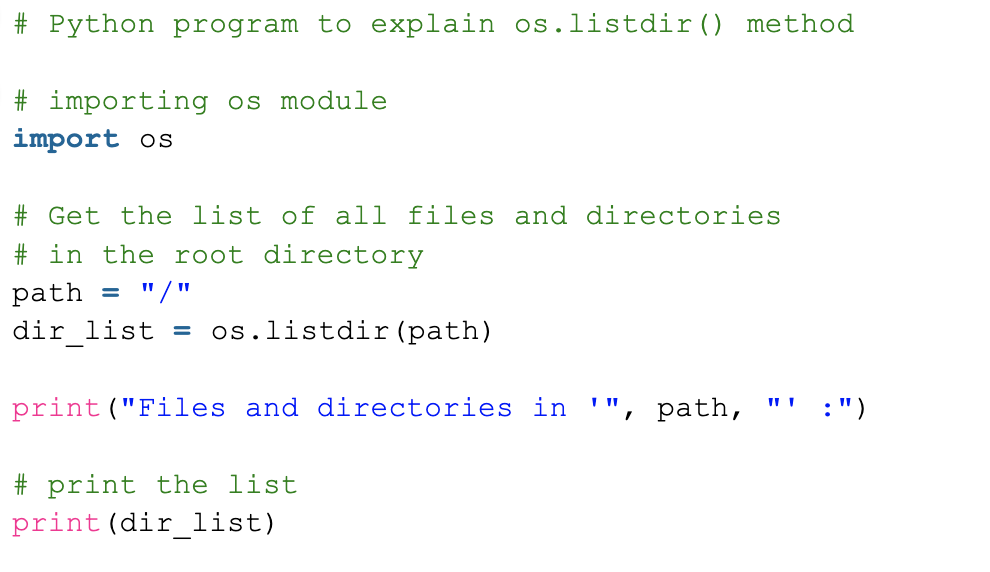
【Python入门至精通】:用Python快速批量提取文件夹中的文件名
# 摘要
本文系统回顾了Python语言的基础知识,并深入探讨了Python在文件系统操作方面的应用,包括文件和目录的管理、文件遍历、文件名提取等实战演练。进一步,文章介绍了在不同环境下的文件名管理技巧,特别是跨平台操作和云存储环境下的文件管理。最后,针对Python脚本编写中的常见错误和
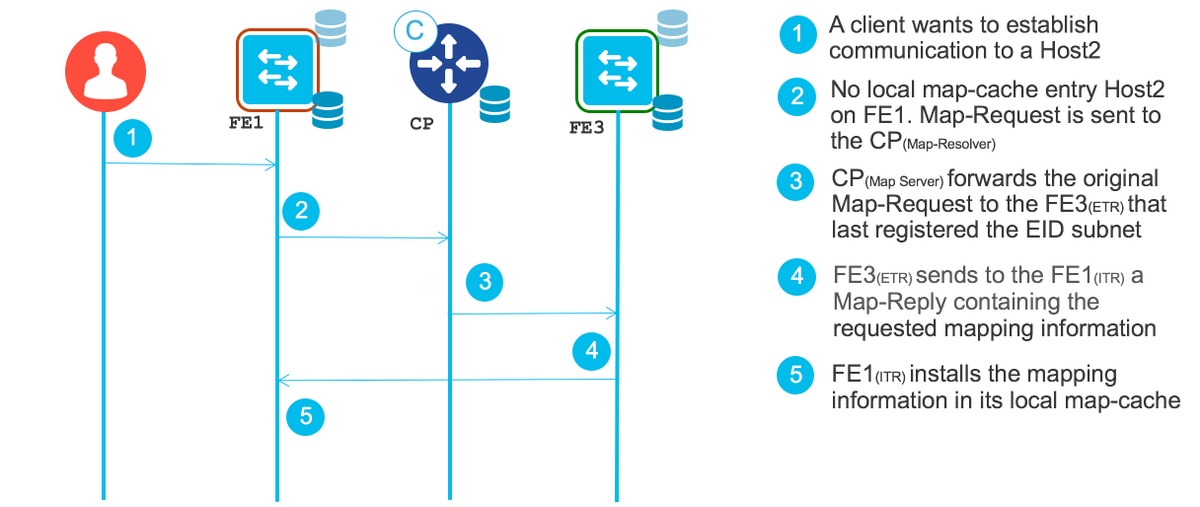
5G网络加速器:eCPRI协议深度剖析与应用案例
# 摘要
eCPRI(enhanced Common Public Radio Interface)协议作为无线网络领域内的重要技术标准,对于支持高速数据传输和降低网络延迟起到了关键作用。本文首先介绍eCPRI协议的背景与基础概念,然后详细分析其理论框架,包括技术标准发展、架构与组件、数据封装与传输。第三章深入探讨了eCPRI协议的实现细节,如配置管理、
AK8963通信协议详解:与主控芯片高效协同的秘密

# 摘要
本文系统性地介绍了AK8963通信协议的各个方面,从基础知识到高级应用,再到与主控芯片的高效协同工作,以及对协议未来展望和挑战的分析。首先概述了AK8963芯片的功能特点及其通信接口,随后深入探讨了寄存器操作、初始化配置和数据处理的实践方法。文章还详细论述了AK8963与主控芯片集成的驱动开发、性能优化以及在定位系统和智能行为
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )