iOS逆向工程中常用的安全工具介绍及使用技巧
发布时间: 2024-02-21 09:46:31 阅读量: 50 订阅数: 30 

逆向工程所用到的一些工具
# 1. iOS逆向工程简介
## 1.1 什么是iOS逆向工程
在iOS开发领域,逆向工程是指对应用程序进行分析和解构,以揭示其内部运行机制和实现细节的过程。通过逆向工程,开发者可以深入了解应用程序的内部设计和功能实现方式,探索其潜在的安全漏洞,并进行定制化修改以达到特定需求。
## 1.2 逆向工程在iOS开发中的应用
iOS逆向工程可用于多种场景,如安全评估与加固、逆向分析与漏洞挖掘、破解与逆向定制开发等。通过逆向工程技术,开发者可以更好地理解第三方应用程序的实现细节,提升自身开发技能,优化应用性能,甚至发现应用中存在的安全隐患。
## 1.3 逆向工程的重要性和意义
逆向工程在iOS开发中扮演着重要的角色,不仅可以帮助开发者更好地理解行业相关技术和实践,还能加深对应用程序内部机制的认识,提高技术水平。通过逆向工程,开发者可以深入探索iOS平台的各种特性和API,掌握开发技巧,提升自身在移动应用开发领域的竞争力。
# 2. 常用的iOS逆向工程安全工具介绍
在iOS逆向工程的实践中,常用的安全工具具有不同的特点和功能,可以帮助开发者更好地进行应用程序的分析和调试。以下是一些常见的iOS逆向工程安全工具:
### 2.1 Cycript
Cycript是一种强大的动态分析工具,可以与iOS应用程序交互,并允许用户在运行时修改和控制应用程序的行为。它使用一种类似JavaScript的语法,可以让用户直接修改运行中的Objective-C代码。以下是Cycript的基本用法示例:
```javascript
// 打开Cycript终端
$ cycript -p 应用程序进程ID
// 修改变量值
cy# var targetVar = 123;
// 调用方法
cy# [targetObj methodName];
```
**总结:** Cycript是一种强大的动态分析工具,可以与iOS应用程序交互,并允许用户在运行时修改和控制应用程序的行为。
### 2.2 Frida
Frida是一种动态插桩工具,可以让用户实时调试、跟踪和修改运行中的iOS应用程序。它支持多种平台和语言,包括Python和JavaScript。Frida的高级功能包括Hooking、RPC、脚本化等,适用于各种逆向工程场景。
```python
import frida
# 通过Frida连接到应用程序进程
session = frida.attach('应用程序名称')
# 创建JavaScript脚本
script = session.create_script("""
rpc.exports = {
method_name: function () {
// 方法实现
}
};
""")
# 加载并执行JavaScript脚本
script.load()
# 调用JavaScript函数
result = script.exports.method_name()
```
**总结:** Frida是一种动态插桩工具,支持多种平台和语言,可以帮助用户实时调试、跟踪和修改运行中的iOS应用程序。
### 2.3 Hopper
Hopper是一种反汇编工具,可以将iOS应用程序的机器码反编译为人类可读的汇编代码。它提供了直观的用户界面和丰富的功能,可以帮助逆向工程师深入分析应用程序的内部逻辑。
**总结:** Hopper是一种反汇编工具,可以帮助逆向工程师将iOS应用程序的机器码反编译为人类可读的汇编代码。
### 2.4 IDA Pro
IDA Pro是一种著名的静态分析工具,广泛用于逆向工程和恶意代码分析。它支持多种处理器架构和文件格式,可以帮助用户深入分析应用程序的二进制代码,识别漏洞和隐藏功能。
**总结:** IDA Pro是一种静态分析工具,可以帮助用户深入分析应用程序的二进制代码,识别漏洞和隐藏功能。
### 2.5 Class-dump
Class-dump是一种工具,可以帮助用户导出iOS应用程序的Objective-C类定义。通过分析应用程序的类结构,开发者可以更好地理解应用程序的逻辑和设计。
**总结:** Class-dump是一种工具,可以帮助用户导出iOS应用程序的Objective-C类定义,帮助理解应用程序的结构。
### 2.6 LLDB
LLDB是Xcode集成的调试器,支持多种调试指令和功能,可以帮助开发者调试和分析iOS应用程序。LLDB还支持Python脚本,可以进行更高级的调试和分析操作。
```python
# 在LLDB中设置断点
(lldb) breakpoint set --name methodName
# 执行调试指令
(lldb) expr [targetObj methodName]
```
**总结:*

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入探讨iOS应用程序逆向工程的相关内容,旨在帮助读者全面了解和掌握这一领域的知识与技术。首先,我们会介绍iOS应用程序逆向工程的基本概念与简介,为读者打下坚实的理论基础。接着,将通过“使用Xcode进行iOS应用逆向工程入门指南”这一文章,带领读者逐步学习实践逆向工程的基本步骤。随后,我们会深入探讨如何使用Hopper Disassembler等工具进行iOS应用程序的逆向分析,帮助读者了解应用程序的内部结构和运行机制。此外,还会涉及到iOS代码混淆技术及其对应的反混淆方案,以及利用Cycript进行iOS应用程序的运行时调试等实用技术。最后,我们还将重点探讨应用逆向工程中对iOS安全漏洞的挖掘与利用,帮助读者更好地了解和应对潜在的安全风险。通过本专栏的学习,读者将能够全面提升对iOS应用程序逆向工程的认识与技能,为进一步深入研究和实践打下坚实基础。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NVIDIA ORIN NX性能基准测试:超越前代的关键技术突破
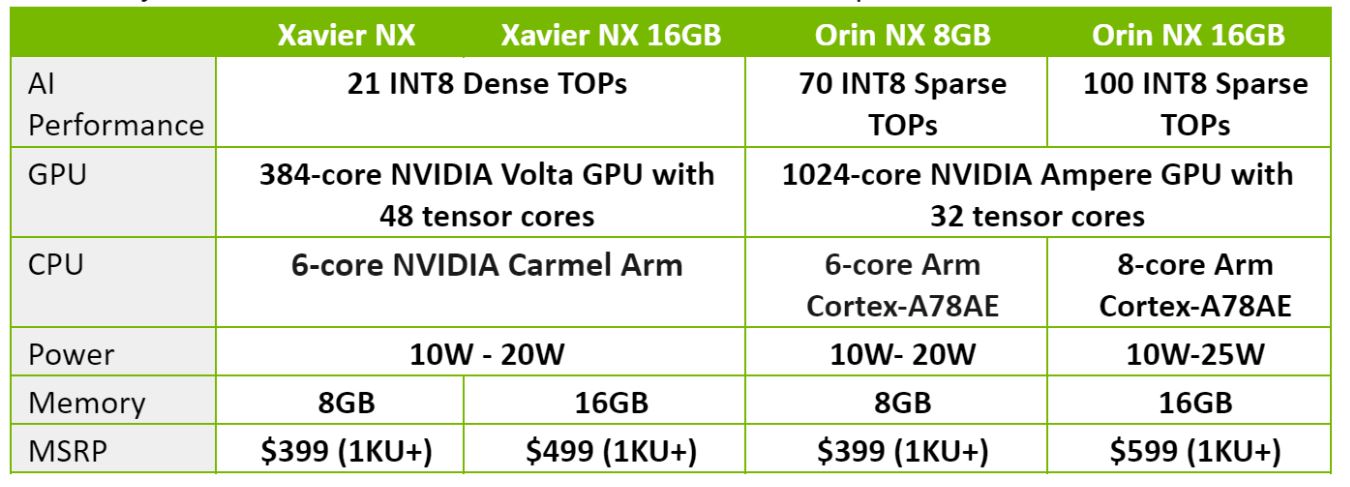
# 摘要
本文全面介绍了NVIDIA ORIN NX处理器的性能基准测试理论基础,包括性能测试的重要性、测试类型与指标,并对其硬件架构进行了深入分析,探讨了处理器核心、计算单元、内存及存储的性能特点。此外,文章还对深度学习加速器及软件栈优化如何影响AI计算性能进行了重点阐述。在实践方面,本文设计了多个实验,测试了NVI
图论期末考试必备:掌握核心概念与问题解答的6个步骤

# 摘要
图论作为数学的一个分支,广泛应用于计算机科学、网络分析、电路设计等领域。本文系统地介绍图论的基础概念、图的表示方法以及基本算法,为图论的进一步学习与研究打下坚实基础。在图论的定理与证明部分,重点阐述了最短路径、树与森林、网络流问题的经典定理和算法原理,包括Dijkstra和Floyd-Warshall算法的详细证明过程。通过分析图论在社交网络、电路网络和交通网络中的实际应用,本文探讨了图论问题解决策略和技巧,包括策略规划、数学建模与软件
【无线电波传播影响因素详解】:信号质量分析与优化指南
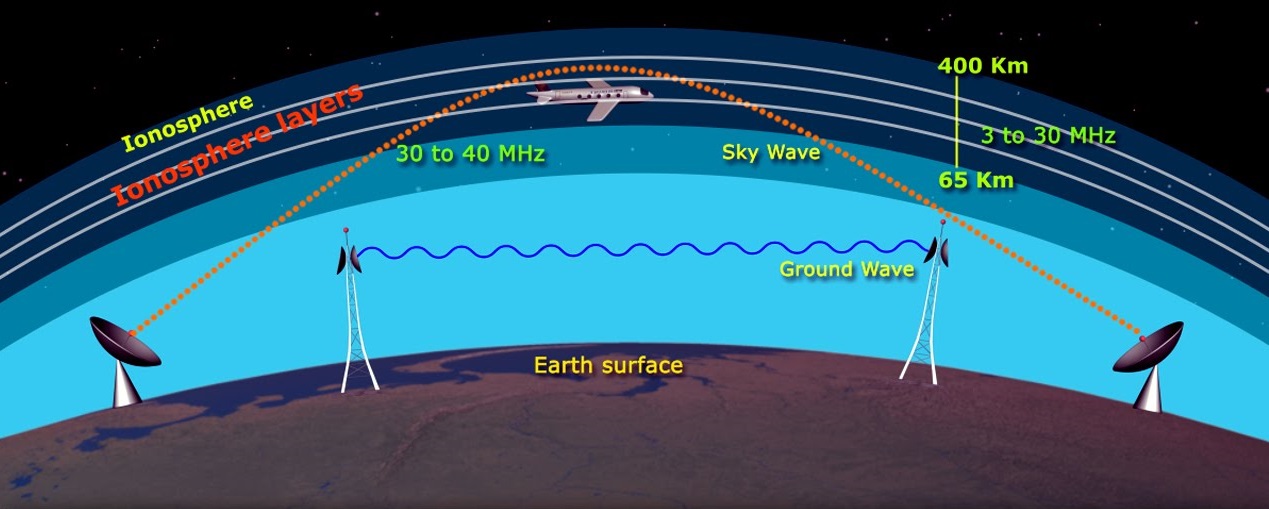
# 摘要
本文综合探讨了无线电波传播的基础理论、环境影响因素以及信号质量的评估和优化策略。首先,阐述了大气层、地形、建筑物、植被和天气条件对无线电波传播的影响。随后,分析了信号衰减、干扰识别和信号质量测量技术。进一步,提出了包括天线技术选择、传输系统调整和网络规划在内的优化策略。最后,通过城市、农村与偏远地区以及特殊环境下无线电波传播的实践案例分析,为实际应用提供了理论指导和解决方案。
# 关键字
无线电波传播;信号衰减;信号干扰;信号
FANUC SRVO-062报警:揭秘故障诊断的5大实战技巧

# 摘要
FANUC SRVO-062报警是工业自动化领域中伺服系统故障的常见表现,本文对该报警进行了全面的综述,分析了其成因和故障排除技巧。通过深入了解FANUC伺服系统架构和SRVO-062报警的理论基础,本文提供了详细的故障诊断流程,并通过伺服驱动器和电机的检测方法,以及参数设定和调整的具体操作
【单片微机接口技术速成】:快速掌握数据总线、地址总线与控制总线
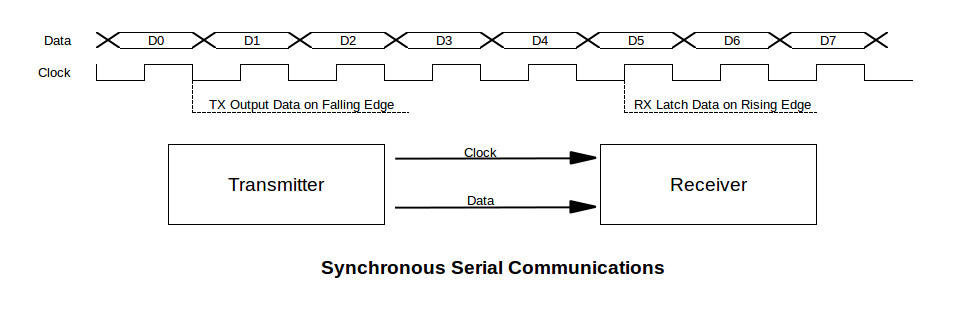
# 摘要
本文深入探讨了单片微机接口技术,重点分析了数据总线、地址总线和控制总线的基本概念、工作原理及其在单片机系统中的应用和优化策略。数据总线的同步与异步机制,以及其宽度对传输效率和系统性能的影响是本文研究的核心之一。地址总线的作用、原理及其高级应用,如地址映射和总线扩展,对提升寻址能力和系统扩展性具有重要意义。同时,控制总线的时序控制和故障处理也是确保系统稳定运行的关键技术。最后
【Java基础精进指南】:掌握这7个核心概念,让你成为Java开发高手

# 摘要
本文全面介绍了Java语言的开发环境搭建、核心概念、高级特性、并发编程、网络编程及数据库交互以及企业级应用框架。从基础的数据类型和面向对象编程,到集合框架和异常处理,再到并发编程和内存管理,本文详细阐述了Java语言的多方面知识。特别地,对于Java的高级特性如泛型和I/O流的使用,以及网络编程和数据库连接技
电能表ESAM芯片安全升级:掌握最新安全标准的必读指南
# 摘要
ESAM芯片作为电能表中重要的安全组件,对于确保电能计量的准确性和数据的安全性发挥着关键作用。本文首先概述了ESAM芯片及其在电能表中的应用,随后探讨了电能表安全标准的演变历史及其对ESAM芯片的影响。在此基础上,深入分析了ESAM芯片的工作原理和安全功能,包括硬件架构、软件特性以及加密技术的应用。接着,本文提供了一份关于ESAM芯片安全升级的实践指南,涵盖了从前期准备到升级实施以及后
快速傅里叶变换(FFT)实用指南:精通理论与MATLAB实现的10大技巧
# 摘要
快速傅里叶变换(FFT)是信号处理和数据分析的核心技术,它能够将时域信号高效地转换为频域信号,以进行频谱分析和滤波器设计等。本文首先回顾FFT的基础理论,并详细介绍了MATLAB环境下FFT的使用,包括参数解析及IFFT的应用。其次,深入探讨了多维FFT、离散余弦变换(DCT)以及窗函数在FFT中的高级应用和优化技巧。此外,本文通过不同领域的应用案例
【高速ADC设计必知】:噪声分析与解决方案的全面解读

# 摘要
高速模拟-数字转换器(ADC)是现代电子系统中的关键组件,其性能受到噪声的显著影响。本文系统地探讨了高速ADC中的噪声基础、噪声对性能的影响、噪声评估与测量技术以及降低噪声的实际解决方案。通过对噪声的分类、特性、传播机制以及噪声分析方法的研究,我们能
【Python3 Serial数据完整性保障】:实施高效校验和验证机制
# 摘要
本论文首先介绍了Serial数据通信的基础知识,随后详细探讨了Python3在Serial通信中的应用,包括Serial库的安装、配置和数据流的处理。本文进一步深入分析了数据完整性的理论基础、校验和验证机制以及常见问题。第四章重点介绍了使用Python3实现Serial数据校验的方法,涵盖了基本的校验和算法和高级校验技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )