Xerces-C++从零到英雄:基础知识与进阶技巧全面剖析
发布时间: 2024-09-28 13:36:31 阅读量: 118 订阅数: 46 

xerces-c-3.2.3.zip
# 1. Xerces-C++简介与安装
## 1.1 Xerces-C++概述
Xerces-C++是一个广泛使用的开源XML解析库,由Apache软件基金会提供支持。它能够解析XML文档并将其转换成C++程序中的数据结构,支持多种XML标准,包括DOM, SAX, 和Schema。Xerces-C++广泛应用于需要处理XML数据的应用程序中,因其良好的性能和广泛的平台兼容性而受到开发者青睐。
## 1.2 安装Xerces-C++
为了使用Xerces-C++,首先需要进行安装。Xerces-C++支持多种操作系统,包括Windows、Linux和Mac OS。安装过程可以根据操作系统的不同而略有差异,但通常涉及以下步骤:
1. 下载Xerces-C++源代码或预先构建的二进制包。
2. 解压缩下载的文件。
3. 在解压目录中执行`configure`脚本,生成适合您操作系统的构建文件。
4. 编译安装源代码,或直接安装二进制包。
以下是针对Linux系统的安装示例代码:
```bash
tar xzf xerces-c-3.x.x.tar.gz
cd xerces-c-3.x.x
./configure --prefix=/usr/local/xerces-c
make
make install
```
确保在安装之前您的系统上已经安装了编译工具,如gcc和make。安装完成后,可以通过在C++代码中包含Xerces-C++的头文件以及链接相应的库文件来进行编程。
1. 包含头文件:`#include <xercesc/util/PlatformUtils.hpp>`
2. 链接库文件:在编译时需要链接到`-lxerces-c`
通过以上步骤,Xerces-C++环境就可以在您的开发项目中使用了。接下来的章节将深入探讨Xerces-C++的核心概念以及如何进行配置和优化。
# 2. Xerces-C++核心概念解析
## 2.1 文档对象模型(DOM)基础
### 2.1.1 DOM的组成和结构
文档对象模型(DOM)是XML文档的一个抽象表示,允许程序和脚本动态地访问和更新文档的内容、结构和类型。DOM作为一个层次化的树形结构,它将XML文档的各个组成部分映射为节点(Node),从而允许开发者以编程方式操作这些节点。
在DOM结构中,顶层节点被称为根节点,通常是文档(Document)节点。文档节点下可能包含多个子节点,例如元素节点(Element)、文本节点(Text)、注释节点(Comment)等。每个节点都可能有子节点,形成一个层次化的树状结构。
DOM的这种结构使得开发者可以通过节点的层级关系进行导航,无论是向上访问父节点,还是向下遍历子节点,都能方便地实现对XML文档的解析和生成。
### 2.1.2 DOM节点类型及操作
DOM定义了多种节点类型,每种节点类型都对应XML文档的一个特定部分。下面列出了一些常见的DOM节点类型:
- **Document节点**:代表整个文档。
- **Element节点**:表示XML文档中的一个元素。
- **Text节点**:包含元素或属性中的文本内容。
- **Comment节点**:代表XML文档中的注释。
- **Attribute节点**:表示元素的属性。
节点类型之间可以进行多种操作,包括创建新节点、获取节点信息、修改节点属性和值、以及添加或删除节点。例如,要创建一个新的元素节点并添加到文档中,可以执行如下步骤:
```cpp
DOMImplementation *impl = DOMImplementationRegistry::getDOMImplementation();
DOMDocument *doc = impl->createDocument("***", "example", NULL);
DOMElement *root = doc->getDocumentElement();
DOMElement *child = doc->createElement("child");
root->appendChild(child); // 将新元素添加为根节点的子节点
```
在上面的代码中,我们首先创建了一个新的XML文档对象,然后获取了文档的根节点,并创建了一个新的子节点,最后将这个新的子节点添加到根节点的子节点列表中。DOM提供的这种操作方式,为动态地构建和修改XML文档结构提供了强大的编程接口。
## 2.2 XML解析技术的实践应用
### 2.2.1 XML解析流程概述
XML解析是处理XML文档的核心过程,其目标是将XML文档转换为应用程序可以方便使用和操作的数据结构。XML解析流程通常包含以下几个基本步骤:
1. **加载XML文档**:首先,需要将XML文档加载到解析器中。这可以通过文件读取、网络读取或者其他数据源获取实现。
2. **验证XML文档**:如果XML文档包含Schema或DTD,解析器将进行文档有效性验证。
3. **构建DOM树或事件流**:解析器根据设置,可以选择构建DOM树或创建事件流。在事件驱动模型(如SAX)中,解析器会触发一系列事件;而在DOM模型中,解析器会构建一个节点树。
4. **操作和处理数据**:对构建的DOM树或接收的事件流进行分析和处理,进行数据提取、更新或验证等操作。
5. **清理资源**:完成操作后,需要清理解析过程中占用的资源,如内存、文件句柄等。
### 2.2.2 事件驱动解析(SAX)与DOM解析对比
事件驱动解析(SAX)和DOM解析是两种流行的XML解析技术,它们在处理XML文档时各有特点。
**SAX解析**采用流式处理模型,解析器在读取XML文档时,会生成一系列的事件(如元素开始、元素结束、文本内容等),应用程序通过注册事件处理器来响应这些事件。SAX的优势在于处理大型文件时内存消耗较小,解析速度快。但是SAX不支持随机访问文档节点,也不便于实现XML的验证。
```cpp
class MyHandler : public xml::sax::Handler {
public:
void startElement(const XMLCh* const uri, const XMLCh* const localname, const XMLCh* const qname, const Attributes& attrs) override {
// 处理元素开始事件
}
void characters(const XMLCh* const ch, const XMLCh* const start, const XMLCh* const end) override {
// 处理文本内容事件
}
// 其他事件处理函数...
};
xml::sax::Parser parser;
MyHandler handler;
parser.setFeature(XMLUni::fgSAX2CoreNameSpaces, true);
parser.setFeature(XMLUni::fgSAX2CoreValidation, true);
parser.setContentHandler(&handler);
parser.parse("example.xml");
```
**DOM解析**则会将整个XML文档加载到内存中,并构建一个层次化的DOM树。DOM解析模型便于随机访问和修改文档结构,也支持通过Schema验证XML文档。但其缺点是内存消耗较大,对大型文档的处理效率较低。
```cpp
DOMImplementation *impl = DOMImplementationRegistry::getDOMImplementation();
DOMDocument *doc = impl->createDocument("***", "example", NULL);
// 此处进行DOM节点操作...
```
根据应用需求的不同,开发者可以选择最适合的解析策略。例如,对内存敏感且需要快速遍历文档的应用程序可能会选择SAX,而需要频繁修改XML文档的应用程序则可能更倾向于使用DOM。
## 2.3 Xerces-C++的配置与优化
### 2.3.1 配置Xerces-C++环境
Xerces-C++是高性能的XML解析库,使用它之前,需要正确配置开发环境和运行时环境。以下是配置Xerces-C++的基本步骤:
1. **安装Xerces-C++库**:首先需要从Xerces-C++官方网站下载并安装库文件。
2. **设置环境变量**:设置系统的`PATH`和`LD_LIBRARY_PATH`环境变量,以确保系统能找到Xerces-C++的执行文件和库文件。
3. **配置编译器**:在编译项目时,需要指定Xerces-C++头文件和库文件的路径。例如,在使用GCC编译器的情况下,可以通过添加`-I`选项指定头文件路径,通过添加`-L`选项指定库文件路径,通过添加`-l`选项指定库文件名称。
```bash
g++ -I/usr/local/include -L/usr/local/lib -lxerces-c myapp.cpp -o myapp
```
在上述命令中,`-I/usr/local/include`表示头文件在`/usr/local/include`目录下,`-L/usr/local/lib`表示库文件在`/usr/local/lib`目录下,`-lxerces-c`告诉链接器链接`libxerces-c`库。
### 2.3.2 性能调优技巧
在使用Xerces-C++处理XML文档时,通过调整配置和优化使用方式,可以显著提高程序的性能和效率。以下是一些性能优化的技巧:
- **选择合适的解析器**:根据需求选择合适的解析器,例如`XercesDOMParser`或`XERCESXMLReader`。
- **使用输入和输出过滤器**:对于大型XML文件的处理,可以使用输入和输出过滤器来减少内存消耗。
- **避免重复验证**:如果应用程序不需要对每个文档进行验证,可以在解析之前禁用验证。
- **优化内存使用**:通过重置`DOMDocument`或在解析过程中删除不必要的节点来优化内存使用。
- **利用并发解析**:在多核处理器上,可以通过并发解析的方式来提高处理速度。
```cpp
// 示例:禁用验证
DOMConfigurable *configurable = parser->getDomConfig();
configurable->setParameter(XMLUni::fgDOMComments, true);
configurable->setParameter(XMLUni::fgDOMDatatypeNormalization, true);
configurable->setParameter(XMLUni::fgDOMElementContentWhitespace, true);
configurable->setParameter(XMLUni::fgDOMNamespaces, true);
configurable->setParameter(XMLUni::fgDOMValidation, false);
configurable->setParameter(XMLUni::fgXMLOverlay, true);
```
在该示例代码中,我们通过设置`DOMConfigurable`对象的参数来调整Xerces-C++解析器的行为。例如,通过设置`fgDOMValidation`为`false`,我们可以禁用文档的XML Schema验证,以减少解析过程中CPU和内存的消耗。调整这些参数可以针对具体的应用场景对Xerces-C++的性能进行微调。
通过上述配置和优化技巧,开发者可以大幅提升Xerces-C++应用程序的性能,尤其是在处理大规模XML数据时。
# 3. Xerces-C++高级功能开发
## 3.1 XML Schema验证技术
### 3.1.1 Schema基础与Xerces-C++支持
XML Schema是W3C推荐的一种XML文档的模式语言,它被用来定义XML文档的结构、内容和数据类型。它比DTD具有更强的表达能力,可以对XML文档中的元素和属性进行更详细的约束。
Xerces-C++提供了对XML Schema的全面支持。它允许开发者使用Schema来验证XML文档的结构和内容。开发者可以通过加载Schema定义,并将其应用到XML文档解析过程中,从而确保文档遵循预定的规则和约束。
在Xerces-C++中,可以通过使用Schema处理器来读取和加载Schema文件。Schema处理器支持多种Schema语言,包括W3C的XML Schema以及RELAX NG。
### 3.1.2 验证过程详解及案例演示
验证过程涉及两个主要步骤:加载Schema定义并验证XML文档。以下是验证过程中各个阶段的详细说明:
1. **加载Schema定义**:首先,需要创建一个Schema处理器实例,并使用该实例来加载Schema定义。Schema定义通常保存在`.xsd`文件中。
2. **配置解析器**:接下来,配置XML解析器以使用已加载的Schema定义。这意味着当解析器遇到XML文档时,它将使用Schema定义来校验文档的结构和数据。
3. **执行验证**:最后,解析器在解析XML文档的过程中,会自动应用Schema定义进行验证。如果文档符合Schema定义,则验证成功;否则,将报告验证错误。
以下是一个简单的代码示例来演示如何在Xerces-C++中进行Schema验证:
```cpp
// 创建 Schema 实例
XercesDOMParser *parser = new XercesDOMParser;
DOMLSParser *lsParser = new DOMLSParserImpl(parser);
// 加载 Schema 定义
try {
XMLCh const * schemaFileName = XMLString::transcode("mySchema.xsd");
SchemaGrammar* schemaGrammar = SchemaParser::loadGrammar(schemaFileName, new DOMLSInputSource(),
SchemaSymbols::DOM LS gramMax);
Schema* schema = new SchemaImpl(schemaGrammar);
lsParser->setSchema(schema);
XMLString::release(&schemaFileName);
} catch (const OutOfMemoryException&) {
// 处理内存不足异常
} catch (const XMLException& toCatch) {
// 处理 XML 异常
}
// 解析 XML 文档并进行验证
try {
XMLCh const * xmlFileName = XMLString::transcode("myDocument.xml");
l
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Xerces介绍与使用》专栏全面介绍了Xerces-C++ XML解析库。从快速入门到高级应用,专栏涵盖了Xerces-C++的各个方面,包括核心概念、最佳实践、数据交换、SAX和DOM处理、事件驱动模型、性能优化、内存管理、安全性、字符编码、定制解析器、远程解析和解析器选择。通过深入的分析和实用技巧,专栏为开发者提供了全面了解和有效使用Xerces-C++的指南,帮助他们解决XML解析中的各种挑战,提高开发效率并构建健壮可靠的XML处理解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
93K缓存策略详解:内存管理与优化,提升性能的秘诀

# 摘要
93K缓存策略作为一种内存管理技术,对提升系统性能具有重要作用。本文首先介绍了93K缓存策略的基础知识和应用原理,阐述了缓存的作用、定义和内存层级结构。随后,文章聚焦于优化93K缓存策略以提升系统性能的实践,包括评估和监控93K缓存效果的工具和方法,以及不同环境下93K缓存的应用案例。最后,本文展望了93K缓存
Masm32与Windows API交互实战:打造个性化的图形界面
# 摘要
本文旨在介绍基于Masm32和Windows API的程序开发,从基础概念到环境搭建,再到程序设计与用户界面定制,最后通过综合案例分析展示了从理论到实践的完整开发过程。文章首先对Masm32环境进行安装和配置,并详细解释了Masm编译器及其他开发工具的使用方法。接着,介绍了Windows API的基础知识,包括API的分类、作用以及调用机制,并对关键的API函数进行了基础讲解。在图形用户界面(GUI)的实现章节中,本文深入
数学模型大揭秘:探索作物种植结构优化的深层原理
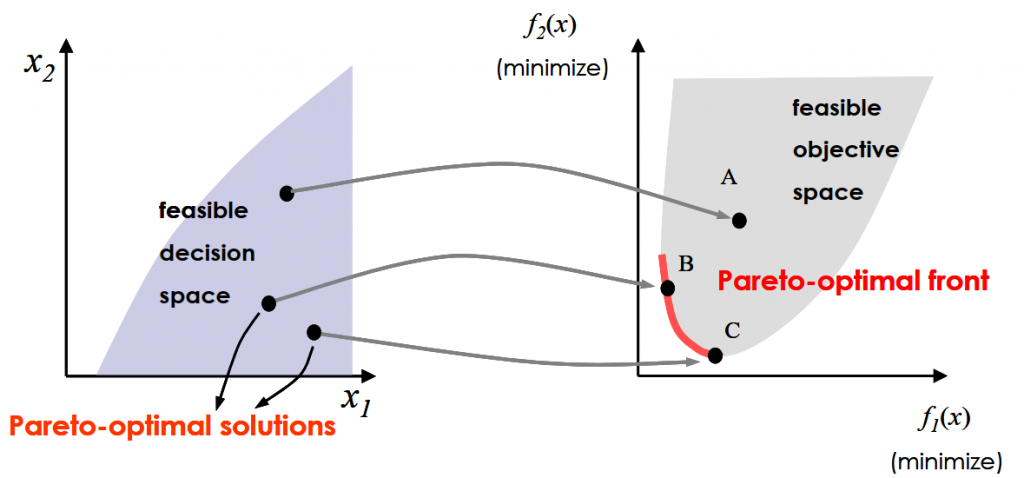
# 摘要
本文系统地探讨了作物种植结构优化的概念、理论基础以及优化算法的应用。首先,概述了作物种植结构优化的重要性及其数学模型的分类。接着,详细分析了作物生长模型的数学描述,包括生长速率与环境因素的关系,以及光合作用与生物量积累模型。本文还介绍了优化算法,包括传统算法和智能优化算法,以及它们在作物种植结构优化中的比较与选择。实践案例分析部分通过具体案例展示了如何建立优化模型,求解并分析结果。
S7-1200 1500 SCL指令性能优化:提升程序效率的5大策略

# 摘要
本论文深入探讨了S7-1200/1500系列PLC的SCL编程语言在性能优化方面的应用。首先概述了SCL指令性能优化的重要性,随后分析了影响SCL编程性能的基础因素,包括编程习惯、数据结构选择以及硬件配置的作用。接着,文章详细介绍了针对SCL代码的优化策略,如代码重构、内存管理和访问优化,以及数据结构和并行处理的结构优化。
泛微E9流程自定义功能扩展:满足企业特定需求

# 摘要
本文深入探讨了泛微E9平台的流程自定义功能及其重要性,重点阐述了流程自定义的理论基础、实践操作、功能扩展案例以及未来的发展展望。通过对流程自定义的概念、组件、设计与建模、配置与优化等方面的分析,本文揭示了流程自定义在提高企业工作效率、满足特定行业需求和促进流程自动化方面的重要作用。同时,本文提供了丰富的实践案例,演示了如何在泛微E9平台上配置流程、开发自定义节点、集成外部系统,
KST Ethernet KRL 22中文版:硬件安装全攻略,避免这些常见陷阱

# 摘要
本文详细介绍了KST Ethernet KRL 22中文版硬件的安装和配置流程,涵盖了从硬件概述到系统验证的每一个步骤。文章首先提供了硬件的详细概述,接着深入探讨了安装前的准备工作,包括系统检查、必需工具和配件的准备,以及
约束理论与实践:转化理论知识为实际应用
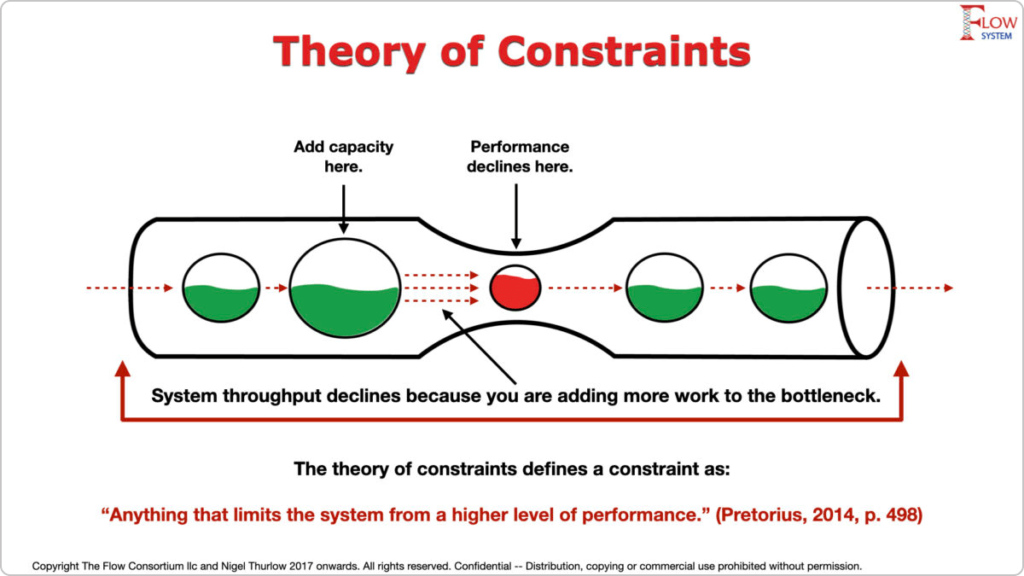
# 摘要
约束理论是一种系统性的管理原则,旨在通过识别和利用系统中的限制因素来提高生产效率和管理决策。本文全面概述了约束理论的基本概念、理论基础和模型构建方法。通过深入分析理论与实践的转化策略,探讨了约束理论在不同行业,如制造业和服务行业中应用的案例,揭示了其在实际操作中的有效性和潜在问题。最后,文章探讨了约束理论的优化与创新,以及其未来的发展趋势,旨在为理论研究和实际应用提供更广阔的
FANUC-0i-MC参数与伺服系统深度互动分析:实现最佳协同效果
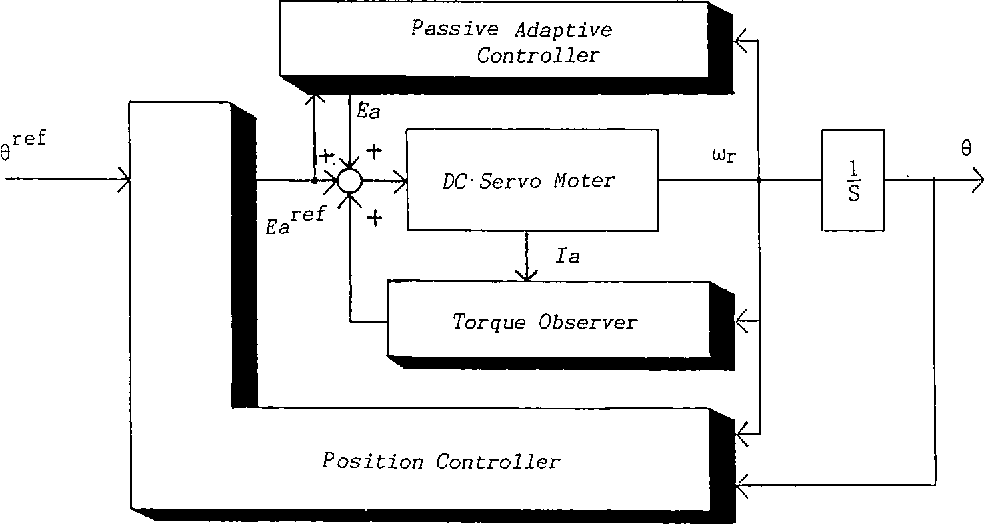
# 摘要
本文深入探讨了FANUC 0i-MC数控系统的参数配置及其在伺服系统中的应用。首先介绍了FANUC 0i-MC参数的基本概念和理论基础,阐述了参数如何影响伺服控制和机床的整体性能。随后,文章详述了伺服系统的结构、功能及调试方法,包括参数设定和故障诊断。在第三章中,重点分析了如何通过参数优化提升伺服性能,并讨论了伺服系统与机械结构的匹配问题。最后,本文着重于故障预防和维护策略,提
ABAP流水号安全性分析:避免重复与欺诈的策略
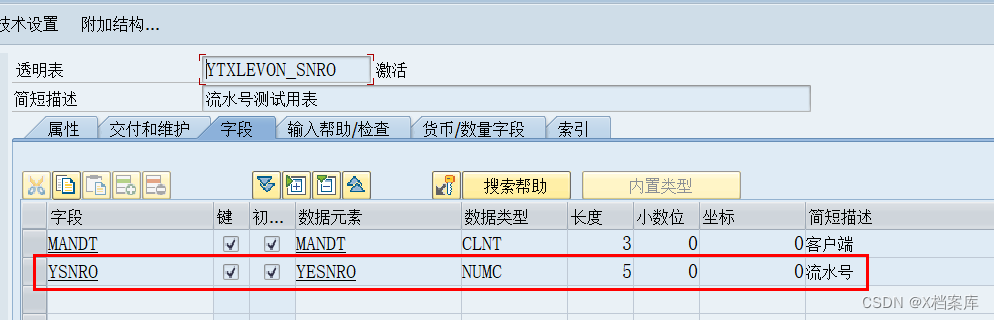
# 摘要
本文全面探讨了ABAP流水号的概述、生成机制、安全性实践技巧以及在ABAP环境下的安全性增强。通过分析流水号生成的基本原理与方法,本文强调了哈希与加密技术在保障流水号安全中的重要性,并详述了安全性考量因素及性能影响。同时,文中提供了避免重复流水号设计的策略、防范欺诈的流水号策略以及流水号安全的监控与分析方法。针对ABAP环境,本文论述了流水号生成的特殊性、集成安全机制的实现,以及安全问题的ABAP代
Windows服务器加密秘籍:避免陷阱,确保TLS 1.2的顺利部署
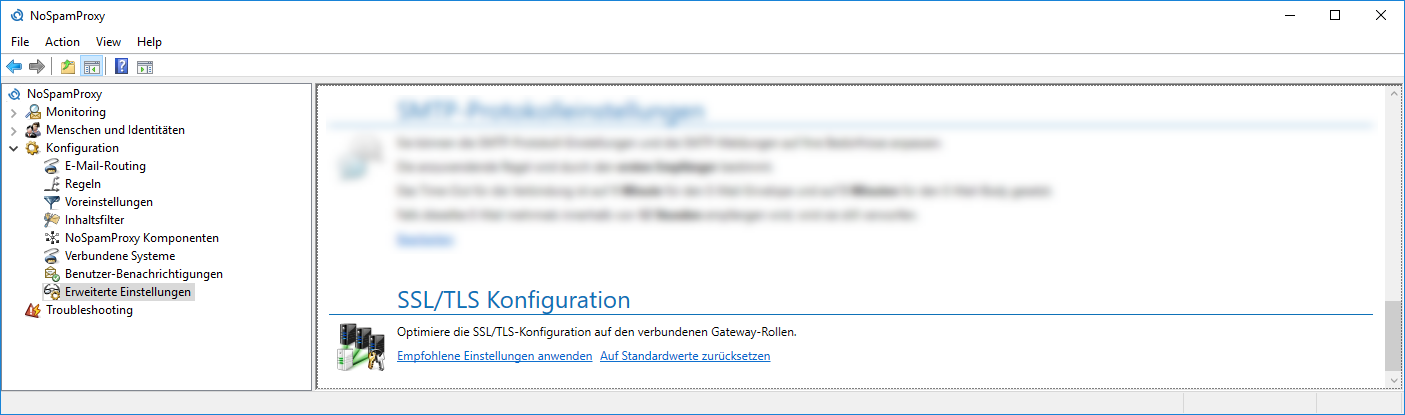
# 摘要
本文提供了在Windows服务器上配置TLS 1.2的全面指南,涵盖了从基本概念到实际部署和管理的各个方面。首先,文章介绍了TLS协议的基础知识和其在加密通信中的作用。其次,详细阐述了TLS版本的演进、加密过程以及重要的安全实践,这
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )