Dom4j在Java项目中的应用实践:从基础到高级技巧
发布时间: 2024-09-28 14:45:36 阅读量: 124 订阅数: 61 

# 1. Dom4j的基础知识介绍
## Dom4j简介
Dom4j(Document Object Model for Java)是一个功能强大的Java XML API,它广泛应用于Java编程语言中。Dom4j提供了一组易于使用的接口,用以处理XML文档。它支持DOM, SAX以及JAXP,同时也为开发者提供了许多便捷的工具,使得操作XML变得更加高效和方便。
## Dom4j的优势
使用Dom4j的优势在于它的简单性和灵活性。它允许开发者以面向对象的方式来处理XML文档,使得代码更加清晰易读。它在性能上也表现出色,特别是在处理大型XML文档时,它的内存消耗较低,处理速度快。此外,Dom4j还支持XPath和XSLT,使得数据查询和转换变得简单。
## Dom4j基本结构
Dom4j的核心是SAXReader,用于从各种来源加载XML文档。一旦文档被读取,Dom4j将文档解析成树状结构的Node对象,开发者可以利用这些对象进行各种操作,如创建、查询、修改等。后续章节将会详细讲解如何使用这些功能进行XML文档的操作和解析。
# 2. Dom4j的XML解析应用
### 2.1 Dom4j的解析原理和方法
#### 2.1.1 Dom4j的DOM解析方式
DOM(Document Object Model)解析方式是通过把XML文档转化成一个树形结构,每个节点代表XML文档中的一个部分。在Java中,通过Dom4j库的DOMReader类读取XML文件,可以将XML文档转换为SAXReader对象的Document类型。
```java
SAXReader reader = new SAXReader();
Document document = reader.read(new File("example.xml"));
```
在上述代码中,`SAXReader`用于读取XML文件并生成`Document`对象,它实际上是一个内存中的树状结构。每一个XML元素、属性和文本都可以作为节点被访问和操作。Dom4j的DOM方式解析具有操作方便、直观的优点,但是当处理大型XML文件时可能会消耗大量内存。
#### 2.1.2 Dom4j的SAX解析方式
SAX(Simple API for XML)是一种基于事件的解析方式。SAX在解析XML文件时不需要将整个文档加载到内存中,而是通过事件驱动模型边读边解析XML文档。
```java
XMLReader reader = XMLReaderFactory.createXMLReader();
reader.setContentHandler(new DefaultHandler() {
//覆写处理方法
});
reader.parse(new InputSource(new FileInputStream("example.xml")));
```
在以上代码中,`XMLReader`是处理SAX解析的主要类,通过覆写`DefaultHandler`的几个方法来处理XML文件中的不同事件(例如开始标签、结束标签、字符数据等)。
SAX解析方式适用于处理大型文件,因为它不会一次性把所有内容加载到内存中,但缺点是由于事件驱动模型的限制,无法进行随机访问。
#### 2.1.3 Dom4j的StAX解析方式
StAX(Streaming API for XML)解析是基于拉模型(Pull Model),类似于SAX的事件驱动解析,但控制权在应用程序中,程序通过迭代器方式读取事件,这种方式更灵活。
```java
XMLInputFactory factory = XMLInputFactory.newInstance();
XMLStreamReader reader = factory.createXMLStreamReader(new FileInputStream("example.xml"));
while (reader.hasNext()) {
int eventType = reader.next();
switch (eventType) {
case XMLStreamConstants.START_ELEMENT:
// 处理开始标签
break;
case XMLStreamConstants.CHARACTERS:
// 处理文本内容
break;
// 其他事件处理
}
}
reader.close();
```
StAX解析方式通过XMLStreamReader读取事件,并提供了更加直接的访问XML数据的方式。StAX比SAX更加灵活,因为它允许您向前和向后移动流,并且可以选择性地跳过某些元素。
### 2.2 Dom4j的XML操作应用
#### 2.2.1 创建和编辑XML文档
使用Dom4j创建和编辑XML文档是一个相对直观的过程。我们可以构建一个Document对象,并在此基础上添加各种节点(如元素、属性、文本等)。
```java
Document document = DocumentHelper.createDocument();
Element root = document.addElement("root");
root.addAttribute("version", "1.0");
Element child1 = root.addElement("child1");
child1.addText("This is child1 text");
```
以上代码创建了一个带有根元素和子元素的简单XML文档,同时为根元素添加了一个属性。Dom4j提供了很多便捷的方法来创建不同类型的节点,并且支持链式调用,使得XML构建过程更为简洁。
#### 2.2.2 XML文档的读取和写入
读取XML文档是解析的第一步,Dom4j通过SAXReader类或XMLEventReader类支持从不同类型的输入源读取XML。
```java
SAXReader reader = new SAXReader();
Document document = reader.read(new File("example.xml"));
```
写入XML文档时,Dom4j使用输出格式(OutputFormat)设置来定义输出的XML的格式,然后使用XMLOutputter类来写入输出。
```java
XMLOutputter xmlOutput = new XMLOutputter();
xmlOutput.setFormat(OutputFormat.createPrettyPrint());
xmlOutput.output(document, new FileWriter("output.xml"));
```
以上代码演示了如何将Document对象输出到文件,`XMLOutputter`类的`setFormat`方法可以定义输出格式,比如是否美化输出、缩进等。
#### 2.2.3 XML文档的查询和修改
查询XML文档通常涉及到查找特定的节点或属性。Dom4j通过XPath支持复杂的查询。
```java
NodeList nodes = document.selectNodes("//child1");
for (Iterator iter = nodes.iterator(); iter.hasNext(); ) {
Element element = (Element) iter.next();
// 处理找到的每个child1元素
}
```
以上代码演示了如何查找所有的`child1`元素。`selectNodes`方法接受一个XPath表达式,返回匹配的节点列表。
修改XML文档则需要定位到特定节点然后修改其内容或属性。
```java
Element root = document.getRootElement();
root.addAttribute("version", "2.0");
```
上述代码将根元素的`version`属性值修改为"2.0"。Dom4j提供了非常直观的API来进行节点和属性的添加、修改、删除等操作。
### 2.2.3 XML文档的查询和修改
通过Dom4j可以实现对XML文档的灵活查询与修改操作。这在数据转换和处理中非常关键。XML查询经常用到XPath语言,它允许我们基于特定模式匹配来检索文档中的数据。
```java
// 创建文档对象
Document document = DocumentHelper.createDocument();
// ... 文档内容构建 ...
// 使用XPath查询特定节点
Element root = document.getRootElement();
XPath xpath = XPathFactory.newInstance().newXPath();
String expression = "/root/child1";
NodeList nodes = (NodeList) xpath.evaluate(expression, root, XPathConstants.NODESET);
for (int i = 0; i < nodes.getLength(); i++) {
Node node = nodes.item(i);
// 对找到的每个node进行处理
}
```
在上面的代码块中,使用XPath表达式`"/root/child1"`来查询所有位于`root`元素下名为`child1`的子元素。`xpath.evaluate`方法返回匹配的节点列表(`NodeList`对象),之后可以通过迭代器进行遍历和处理。
对于修改XML文档,我们可以通过元素或属性的API进行操作。例如,更改节点文本或修改节点属性。
```java
// 假设已有一个Document对象
Element root = document.getRootElement();
// 修改属性
root.attribute("version").setValue("1.1");
// 修改文本内容
Element child = root.element("child1");
child.setText("Updated text");
```
在这段代码中,我们获取了根元素的`version`属性,并将其值更新为"1.1"。接着,我们通过`setText`方法更新了`child1`元素内的文本内容。
XPath的使用不仅限于查询,它也可以用于实现复杂的修改逻辑。在一些场景中,需要更新或删除满足特定条件的节点,这同样可以通过XPath表达式来实现。
```java
// 删除特定条件的节点
String deleteExpression = "//child1[attribute::id='123']";
document.valueOf(deleteExpression).delete();
```
在这个例子中,我们删除了所有具有id属性值为"123"的`child1`节点。注意,在实际操作之前,需要通过`document.valueOf`方法安全地验证XPath表达式的结果,以确保操作的准确性。
### 2.2.4 XML文档的验证和约束
XML文档的验证是确保文档结构与某个模式(Schema)或文档类型定义(DTD)相匹配的过程。使用Dom4j可以轻松地对XML文档进行这样的验证。
```java
SchemaFactory factory = SchemaFactory.newInstance("***");
Schema schema = factory.newSchema(new File("example.xsd"));
SchemaValidator validator = schema.newValidator();
```
在上述代码块中,首先创建了一个`SchemaFactory`实例,并通过工厂方法加载了一个XML Schema定义(XSD文件)。然后使用这个模式创建了一个`SchemaValidator`实例,这个验证器可以用来对XML文档进行校验。
```java
validator.validate(new StreamSource(new FileInputStream("example.xml")));
```
调用`validate`方法进行文档验证。如果XML文档不满足模式定义的要求,将会抛出异常。开发者可以根据这些异常来诊断和修复XML文档中的问题。
### 2.2.5 XML文档的转换和序列化
在处理XML文档时,经常需要将文档从一种格式转换为另一种格式,或者对文档进行序列化以便在不同的应用间传输。Dom4j支持将Document对象转换为字符串、流或其他格式。
```java
// 转换为字符串
String xmlString = document.asXML();
// 将Document对象写入到输出流中
XMLOutputter xmlOutputter = new XMLOutputter(Format.getPrettyFormat());
xmlOutputter.output(document, new FileWriter("output.xml"));
```
`document.asXML()`方法直接返回一个字符串形式的XML文档。`XMLOutputter`类提供了更多自定义输出格式的方法,例如,`Format.getPrettyFormat()`会美化输出格式,使其易于阅读。
转换成其他格式方面,Dom4j支持的范围包括JSON等。在某些情况下,转换为JSON格式可以简化数据结构,并便于前端开发。
```java
// 将XML文档转换为JSON格式
Element root = document.getRootElement();
String jsonOutput = new XMLToJSONConverter().convert(root);
```
这个例子展示了如何使用一个假想的`XMLToJSONConverter`类将Document对象中的数据转换为JSON格式。请注意,Dom4j自身不提供直接的XML到JSON的转换工具,但可以借助外部库或自定义代码实现这种转换。
以上第二章的内容探讨了使用Dom4j进行XML解析的各种应用,包括解析原理、DOM、SAX和StAX方法,以及创建、编辑、读取、写入、查询、修改和验证XML文档的详细操作。下一章将深入探讨Dom4j在Java项目中的实际应用,例如与Web框架的集成和数据处理等。
# 3. Dom4j在Java项目中的实践应用
## 3.1 Dom4j在Web项目的应用
### 3.1.1 Dom4j在Servlet中的应用
在Web项目中,Servlet通常需要处理XML格式的数据。Dom4j作为一种强大的XML处理库,能够帮助开发者以更加灵活的方式解析和操作XML。在Servlet中使用Dom4j时,首先需要加载XML文档:
```java
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
// ...
SAXReader reader = new SAXReader();
Document document = reader.read(new File("path/to/your/xmlfile.xml"));
```
接下来可以使用Dom4j提供的丰富API来遍历、查询和修改XML文档。例如,如果需要获取文档中的所有`<user>`元素,可以这样做:
```java
List<Element> userList = document.getRootElement().elements("user");
for (Element user : userList) {
String username = user.elementText("username");
String password = user.elementText("password");
// 进行其他操作...
}
```
以上代码段展示了如何读取XML文件,并遍历其中的`<user>`元素。这里的`elementText`方法用于获取指定元素的文本内容。
### 3.1.2 Dom4j在Struts2中的应用
在使用Struts2框架的Web项目中,Dom4j同样可以用来解析XML配置文件或动态生成的XML响应。假设我们要从Struts2的action中解析一份XML配置文件:
```java
import org.apache.struts2.ServletActionContext;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
// ...
String xmlContent = ServletActionContext.getServletContext().getResourceAsStream("/path/to/your/xmlfile.xml").toString();
SAXReader reader = new SAXReader();
Document doc = reader.read(new StringReader(xmlContent));
Element root = doc.getRootElement();
// 解析XML并执行相关操作...
```
在这段代码中,我们通过Struts2的`ServletActionContext`获取到资源文件流,并用Dom4j解析它。解析后,就可以根据需要对XML文档进行操作了。
### 3.1.3 Dom4j在Spring MVC中的应用
在Spring MVC中,Dom4j可用于处理请求参数以XML格式发送的数据。例如,我们可以在Controller中这样使用:
```java
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
// ...
@PostMapping("/parseXml")
public String parseXml(@RequestBody String xmlContent) {
try {
SAXReader reader = new SAXReader();
Document document = reader.read(new StringReader(xmlContent));
// 进行数据解析和处理...
} catch (DocumentException e) {
e.printStackTrace();
}
return "Success";
}
```
在这个例子中,我们通过`@RequestBody`注解接收一个XML字符串,并使用Dom4j解析它。随后,可以将解析出的数据用于业务逻辑处理。
## 3.2 Dom4j在数据处理中的应用
### 3.2.1 Dom4j在JSON解析中的应用
虽然Dom4j主要用于XML处理,但在一些场景下,我们可能需要解析JSON字符串。虽然JSON与XML在结构上有所不同,但Dom4j的一些类和方法在解析简单的JSON数据时也可以派上用场,尤其是对于那些结构类似于XML的JSON数据。
```java
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
// ...
String jsonString = "{\"user\":{\"username\":\"example\",\"password\":\"123456\"}}";
Document doc = DocumentHelper.parseText(jsonString);
// 进行进一步处理...
```
尽管我们使用了`DocumentHelper.parseText()`方法,实际上对于复杂或者格式不规则的JSON,建议使用专门的JSON解析库,如Gson或Jackson。
### 3.2.2 Dom4j在数据库操作中的应用
Dom4j不仅可以用于解析XML和处理JSON数据,还可以在数据库操作中发挥作用。比如,我们需要将数据库中查询出的数据导出为XML格式,可以使用Dom4j来构建XML文档:
```java
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
// 假设我们已经从数据库获取了数据
List<User> users = ...;
Document doc = DocumentHelper.createDocument();
Element root = doc.addElement("users");
for (User user : users) {
Element userElement = root.addElement("user");
userElement.addElement("username").setText(user.getUsername());
userElement.addElement("password").setText(user.getPassword());
// 添加其他字段...
}
// 输出XML字符串或保存到文件...
```
在上述代码中,我们构建了一个包含多个`<user>`元素的`<users>`元素的XML文档。这种场景下,Dom4j的作用就是数据结构化和导出。
### 3.2.3 Dom4j在文件操作中的应用
文件操作是任何项目的基础,而文件内容的读取和写入则可以借助Dom4j来实现。假设我们需要读取一个XML格式的配置文件,并进行更新:
```java
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.XMLWriter;
import java.io.File;
import java.io.FileWriter;
// ...
File xmlFile = new File("path/to/your/xmlfile.xml");
Document document = DocumentHelper.read(xmlFile);
Element root = document.getRootElement();
// 修改XML内容
Element user = root.element("user");
user.element("password").setText("newPassword");
// 将更新后的文档写回文件
FileWriter fileWriter = new FileWriter(xmlFile);
XMLWriter xmlWriter = new XMLWriter(fileWriter);
xmlWriter.write(document);
xmlWriter.close();
```
在这段代码中,我们读取一个XML文件并更新了用户的密码字段。通过Dom4j,操作XML文件变得非常直观。最后,我们使用`XMLWriter`将更改后的文档内容写回到文件中。
由于Dom4j的灵活性和强大的XML处理能力,在数据处理领域有着广泛的应用。无论是Web项目的文件操作、数据库数据导出,还是简单的JSON解析,Dom4j都能提供方便快捷的解决方案。然而,需要指出的是,对于复杂的数据转换和处理,使用专为JSON设计的库会更加高效。
在下一节中,我们将深入探讨Dom4j在Java项目中的高级技巧和优化方法,包括性能优化、安全应用技巧以及异常处理和调试方面的高级应用。
# 4. Dom4j的高级技巧和优化
在处理大型XML文件或对性能有严格要求的应用中,对Dom4j的深入掌握就显得尤为重要。第四章将着重讲解Dom4j的性能优化技巧、安全应用技巧以及异常处理和调试的高级技巧。
## 4.1 Dom4j的性能优化技巧
Dom4j作为一个功能强大的XML处理库,如果不加注意,很容易造成内存溢出和性能瓶颈。以下将介绍两种常见的性能优化技巧。
### 4.1.1 Dom4j的内存优化
处理大型的XML文件时,若一次性加载整个文档到内存中,会导致内存消耗巨大,甚至造成程序崩溃。为了优化内存使用,可以采取以下措施:
1. 使用SAX解析器:SAX是一种基于事件驱动的解析器,它不需要一次性加载整个文档到内存,而是按需读取文档的各个部分。
```java
import org.dom4j.io.SAXReader;
import org.dom4j.Document;
import org.xml.sax.InputSource;
public class SAXExample {
public Document parseXML(String filePath) throws Exception {
SAXReader reader = new SAXReader();
InputSource is = new InputSource(filePath);
Document document = reader.read(is);
return document;
}
}
```
在这个例子中,SAXReader的read方法接受一个InputSource对象,这允许我们逐步读取XML文件,而不是一次性加载整个文档。
2. 使用DocumentFactory:Dom4j提供了一个DocumentFactory机制,允许我们复用节点对象,减少内存的消耗。
```java
import org.dom4j.DocumentFactory;
public class CustomDocumentFactory extends DocumentFactory {
@Override
public Node createNode(String name) {
// Custom implementation to reuse node instances
return super.createNode(name);
}
}
```
### 4.1.2 Dom4j的解析效率优化
解析效率的优化,可以从减少不必要的操作和优化数据处理流程两方面入手:
1. 避免重复解析:多次解析相同的内容是毫无意义的,应尽量减少这种行为。
```java
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.XMLReader;
public class ReuseParser {
private XMLReader parser;
public ReuseParser(XMLReader parser) {
this.parser = parser;
}
public Element parseAndReturnElement(String xmlPath, String elementPath) throws Exception {
// Use the same parser instance to parse multiple times
Document document = parser.parse(new File(xmlPath));
Element element = document.getRootElement().element(elementPath);
return element;
}
}
```
2. 使用XPath来定位节点:直接使用XPath可以快速定位到特定节点,避免遍历整个文档。
```java
import org.dom4j.Document;
import org.dom4j.xpath.DefaultXPath;
import org.xml.sax.InputSource;
public class XPathExample {
public Object evaluateXPath(Document document, String xpathExpression) {
DefaultXPath xpath = new DefaultXPath(xpathExpression);
return xpath.valueOf(document);
}
}
```
## 4.2 Dom4j的安全应用技巧
在处理XML数据时,安全问题不容忽视。以下介绍两种常见的安全应用技巧。
### 4.2.1 Dom4j的XML注入防护
XML注入是一种常见的安全漏洞,攻击者通过输入特殊构造的XML片段来干扰应用程序的正常运行。为了避免XML注入,可以采取如下措施:
1. 过滤用户输入:对于所有用户输入的数据,需要进行严格的过滤和验证。
```java
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.DocumentSource;
import org.xml.sax.InputSource;
import org.xml.sax.XMLReader;
public class InputFilter {
private XMLReader xmlReader;
public InputFilter(XMLReader xmlReader) {
this.xmlReader = xmlReader;
}
public Document filterInput(String xmlString) throws DocumentException {
InputSource source = new InputSource(new StringReader(xmlString));
Document document = new DocumentSource(source, xmlReader).read();
// Add filters and security checks here
return document;
}
}
```
### 4.2.2 Dom4j的XSS攻击防护
XSS攻击指的是通过用户输入注入恶意脚本到网页中。为了预防XSS攻击,我们需要对输出进行编码:
```java
import org.dom4j.Element;
import org.dom4j.dom.DOMText;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
public class SafeText {
public Node createSafeText(String content) {
// Create a text node with encoded content to prevent XSS attacks
Document doc = ... // Obtain current document
Node textNode = doc.createTextNode(encodeForXML(content));
return textNode;
}
private String encodeForXML(String content) {
// Implement XML encoding for special characters
return content.replaceAll("[<>&]", new String[] {"<", "&", ">"});
}
}
```
## 4.3 Dom4j的异常处理和调试
在使用Dom4j处理XML时,正确处理异常和有效地进行调试是保证程序稳定运行的关键。
### 4.3.1 Dom4j的异常处理技巧
异常处理可以避免程序因错误处理不当而崩溃,以下是处理Dom4j异常的一个例子:
```java
import org.dom4j.DocumentException;
import org.xml.sax.SAXParseException;
public class ExceptionHandler {
public Document parseXML(String xmlPath) {
Document document = null;
try {
SAXReader reader = new SAXReader();
document = reader.read(xmlPath);
} catch (DocumentException e) {
if (e.getCause() instanceof SAXParseException) {
System.out.println("Parse error occurred at line " + ((SAXParseException) e.getCause()).getLineNumber());
}
} catch (Exception e) {
e.printStackTrace();
}
return document;
}
}
```
### 4.3.2 Dom4j的调试技巧
在开发过程中,有效的调试可以帮助我们发现并解决问题。可以使用日志记录关键信息,以帮助调试:
```java
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Dom4jDebugger {
public void debugXML(Element element) {
OutputFormat format = OutputFormat.createPrettyPrint();
XMLWriter writer = null;
try {
writer = new XMLWriter(System.out, format);
writer.write(element);
} catch (Exception e) {
e.printStackTrace();
} finally {
if (writer != null) {
try {
writer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}
```
以上章节介绍了Dom4j的高级技巧和优化方法,包括性能优化、安全应用以及异常处理和调试的技巧。理解并掌握这些技巧,可以在实际开发中显著提高工作效率和程序质量。
# 5. Dom4j的调试与问题解决
随着Dom4j在XML解析领域的广泛使用,开发者在实际开发过程中可能会遇到各种各样的问题。这一章节将重点介绍如何使用Dom4j进行调试,并解决遇到的常见问题,从而提高开发效率和代码质量。
## 5.1 使用日志记录调试信息
日志记录是调试程序时最基本也是最有效的方法之一。通过日志,开发者可以跟踪程序的执行流程,记录关键变量的状态,从而快速定位问题所在。
```java
import org.apache.log4j.Logger;
public class Dom4jDebugExample {
private static final Logger LOGGER = Logger.getLogger(Dom4jDebugExample.class);
public void parseXMLFile(String filePath) {
try {
SAXReader reader = new SAXReader();
Document document = reader.read(filePath);
// 解析XML文件的逻辑
***("XML文件解析完成,文件路径:" + filePath);
} catch (DocumentException e) {
LOGGER.error("解析XML文件发生异常", e);
}
}
}
```
## 5.2 使用断点调试
断点调试是一种更为直观的调试方式,允许开发者在代码的特定位置设置断点,程序会在运行到断点时暂停,此时可以检查变量的值、程序的执行路径等。
在IDE中,通常可以通过双击代码左边的空白区域来添加或移除断点。当程序运行到断点时,会自动暂停执行,此时可以逐行执行代码,观察程序状态。
## 5.3 常见问题解决方案
### 5.3.1 XML格式错误的处理
在处理XML文件时,我们经常会遇到格式错误的问题。使用Dom4j解析时,如果遇到格式问题,会抛出`DocumentException`异常。处理这类问题的最佳实践是:
1. 捕获异常,并给出清晰的错误信息。
2. 检查XML文件格式,确保文件编码、结构等符合XML规范。
3. 使用工具如XML验证器来检查文件。
```java
try {
Document document = reader.read(filePath);
} catch (DocumentException e) {
System.err.println("无法解析XML文件:" + e.getMessage());
// 可能需要更复杂的错误处理逻辑
}
```
### 5.3.2 解析性能优化
当处理大型XML文件时,可能会遇到性能瓶颈。以下是一些优化建议:
1. **使用合适的解析方式**:对于大型文件,应优先考虑使用SAX或StAX解析方式,因为它们采用事件驱动模型,不需要将整个文档加载到内存中。
2. **优化代码逻辑**:避免不必要的数据操作,如对每个节点的访问,应尽量减少。
3. **使用内存优化技术**:比如,使用池技术管理`SAXReader`对象,减少频繁创建对象的开销。
## 5.4 使用单元测试验证功能
单元测试是验证代码功能正确性的有效手段,尤其在处理复杂的XML操作时。通过编写单元测试,可以确保代码修改后的功能依然符合预期。
```java
import static org.junit.Assert.*;
public class Dom4jUnitTest {
@Test
public void testXMLParsing() {
SAXReader reader = new SAXReader();
try {
Document document = reader.read("path/to/your/test.xml");
Element rootElement = document.getRootElement();
// 对rootElement进行断言验证
assertEquals("expectedElementName", rootElement.getName());
} catch (DocumentException e) {
fail("解析XML时发生异常");
}
}
}
```
## 5.5 利用IDE工具进行调试
现代IDE(如IntelliJ IDEA、Eclipse)提供了强大的调试工具,开发者可以利用这些工具进行断点设置、变量监视、表达式评估等操作。
1. **断点设置**:直观地点击代码行号旁的区域设置断点。
2. **步进执行**:运行程序并到达断点后,使用“Step Over”、“Step Into”和“Step Out”功能进行逐步执行。
3. **变量监视**:在调试过程中,可以实时查看和修改变量的值。
4. **调用堆栈查看**:观察程序的调用堆栈,了解程序当前的执行位置。
## 5.6 小结
本章节介绍了Dom4j的调试与问题解决方法,包括日志记录、断点调试以及常见的性能优化和异常处理技巧。通过结合单元测试和IDE调试工具,开发者可以更高效地定位和解决问题,确保代码的质量和性能。这些技巧不仅适用于Dom4j,对于其他库和框架同样有效。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Dom4j介绍与使用》专栏深入探讨了Dom4j XML解析库,为开发人员提供了全面的指南。从新手入门到进阶技巧,专栏涵盖了Dom4j的各个方面,包括XPath实现、内存优化、对象映射、安全性分析和跨平台兼容性。此外,还介绍了Dom4j在Java项目中的实际应用,如大数据处理、Web服务和内容管理系统。通过深入的分析和示例,专栏帮助开发人员掌握Dom4j的强大功能,从而高效处理XML数据,并解决常见的内存泄漏问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单设计原理

# 摘要
扇形菜单作为一种创新的界面设计,通过特定的布局和交互方式,提升了用户在不同平台上的导航效率和体验。本文系统地探讨了扇形菜单的设计原理、理论基础以及实际的设计技巧,涵盖了菜单的定义、设计理念、设计要素以及理论应用。通过分析不同应用案例,如移动应用、网页设计和桌面软件,本文展示了扇形菜单设计的实际效果,并对设计过程中的常见问题提出了改进策略。最后,文章展望了扇形菜单设计的未来趋势,包括新技术的应用和设计理念的创新。
# 关键字
扇形菜
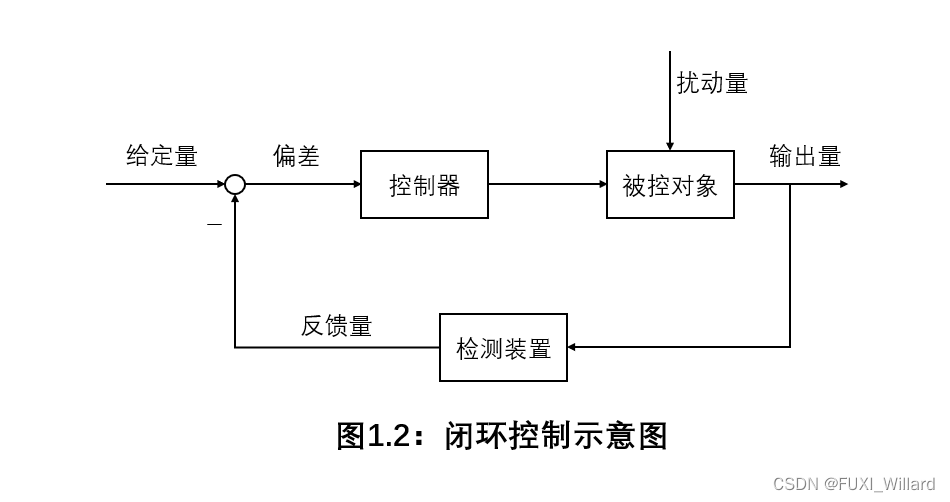
传感器在自动化控制系统中的应用:选对一个,提升整个系统性能
# 摘要
传感器在自动化控制系统中发挥着至关重要的作用,作为数据获取的核心部件,其选型和集成直接影响系统的性能和可靠性。本文首先介绍了传感器的基本分类、工作原理及其在自动化控制系统中的作用。随后,深入探讨了传感器的性能参数和数据接口标准,为传感器在控制系统中的正确集成提供了理论基础。在此基础上,本文进一步分析了传感器在工业生产线、环境监测和交通运输等特定场景中的应用实践,以及如何进行
CORDIC算法并行化:Xilinx FPGA数字信号处理速度倍增秘籍

# 摘要
本文综述了CORDIC算法的并行化过程及其在FPGA平台上的实现。首先介绍了CORDIC算法的理论基础和并行计算的相关知识,然后详细探讨了Xilinx FPGA平台的特点及其对CORDIC算法硬件优化的支持。在此基础上,文章具体阐述了CORDIC算法
C++ Builder调试秘技:提升开发效率的十项关键技巧
# 摘要
本文详细介绍了C++ Builder中的调试技术,涵盖了从基础知识到高级应用的广泛领域。文章首先探讨了高效调试的准备工作和过程中的技巧,如断点设置、动态调试和内存泄漏检测。随后,重点讨论了C++ Builder调试工具的高级应用,包括集成开发环境(IDE)的使用、自定义调试器及第三方工具的集成。文章还通过具体案例分析了复杂bug的调试、
MBI5253.pdf高级特性:优化技巧与实战演练的终极指南
# 摘要
MBI5253.pdf作为研究对象,本文首先概述了其高级特性,接着深入探讨了其理论基础和技术原理,包括核心技术的工作机制、优势及应用环境,文件格式与编码原理。进一步地,本文对MBI5253.pdf的三个核心高级特性进行了详细分析:高效的数据处理、增强的安全机制,以及跨平台兼容性,重点阐述了各种优化技巧和实施策略。通过实战演练案
【Delphi开发者必修课】:掌握ListView百分比进度条的10大实现技巧

# 摘要
本文详细介绍了ListView百分比进度条的实现与应用。首先概述了ListView进度条的基本概念,接着深入探讨了其理论基础和技术细节,包括控件结构、数学模型、同步更新机制以及如何通过编程实现动态更新。第三章
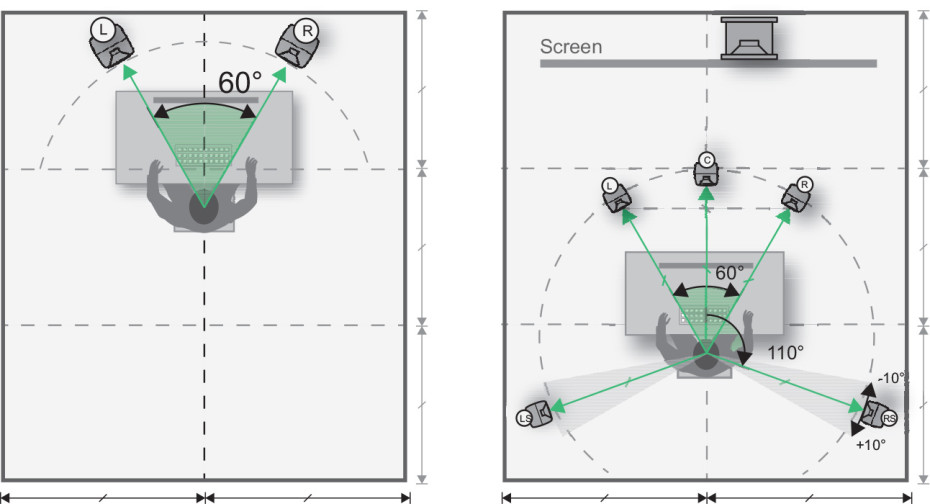
先锋SC-LX59家庭影院系统入门指南
# 摘要
本文全面介绍了先锋SC-LX59家庭影院系统,从基础设置与连接到高级功能解析,再到操作、维护及升级扩展。系统概述章节为读者提供了整体架构的认识,详细阐述了家庭影院各组件的功能与兼容性,以及初始设置中的硬件连接方法。在高级功能解析部分,重点介绍了高清音频格式和解码器的区别应用,以及个
【PID控制器终极指南】:揭秘比例-积分-微分控制的10个核心要点

# 摘要
PID控制器作为工业自动化领域中不可或缺的控制工具,具有结构简单、可靠性高的特点,并广泛应用于各种控制系统。本文从PID控制器的概念、作用、历史发展讲起,详细介绍了比例(P)、积分(I)和微分(D)控制的理论基础与应用,并探讨了PID
【内存技术大揭秘】:JESD209-5B对现代计算的革命性影响
# 摘要
本文详细探讨了JESD209-5B标准的概述、内存技术的演进、其在不同领域的应用,以及实现该标准所面临的挑战和解决方案。通过分析内存技术的历史发展,本文阐述了JESD209-5B提出的背景和核心特性,包括数据传输速率的提升、能效比和成本效益的优化以及接口和封装的创新。文中还探讨了JESD209-5B在消费电子、数据中心、云计算和AI加速等领域的实
【install4j资源管理精要】:优化安装包资源占用的黄金法则

# 摘要
install4j是一款强大的多平台安装打包工具,其资源管理能力对于创建高效和兼容性良好的安装程序至关重要。本文详细解析了install4j安装包的结构,并探讨了压缩、依赖管理以及优化技术。通过对安装包结构的深入理解,本文提供了一系列资源文件优化的实践策略,包括压缩与转码、动态加载及自定义资源处理流程。同时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )