【PyTorch NLP工具包】:文本分类任务加速的关键技术解析
发布时间: 2024-12-11 18:44:01 阅读量: 2 订阅数: 14 

Vue + Vite + iClient3D for Cesium 实现限高分析
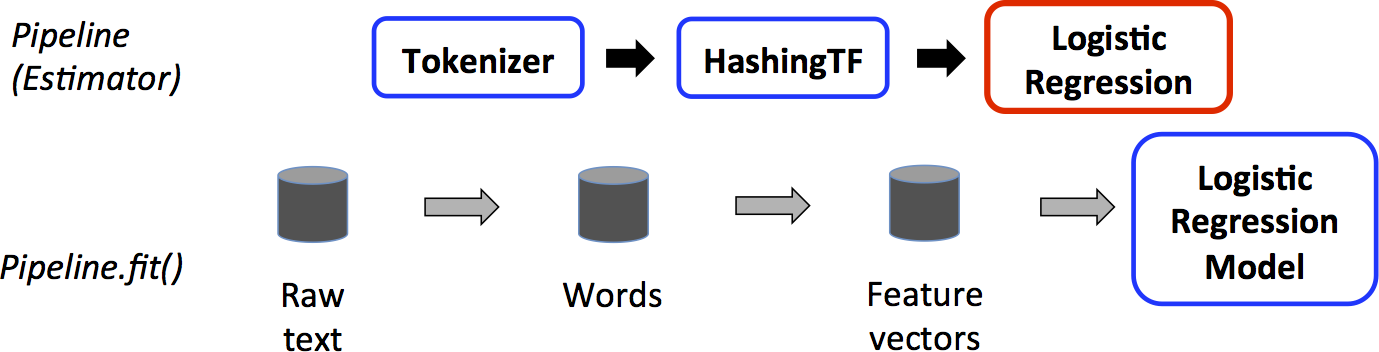
# 1. PyTorch NLP工具包概述
PyTorch是一个开源的机器学习库,广泛用于计算机视觉和自然语言处理(NLP)任务。本章节将介绍PyTorch NLP工具包的基础知识,包括它的起源、特点以及在NLP领域的应用。此外,本章节还会解释PyTorch与其他深度学习框架的比较,以及为什么它在处理NLP任务时尤其受欢迎。
PyTorch由Facebook的人工智能研究小组开发,并迅速成为研究者和开发者们首选的深度学习框架之一。其动态计算图(define-by-run approach)的设计理念极大地简化了模型的设计、调试和优化过程。
PyTorch NLP工具包提供了大量预处理、模型构建和训练的便捷工具,尤其在文本分类、序列标注、语言模型、文本生成等任务中表现出色。本章将作为后续章节的铺垫,帮助读者理解PyTorch NLP工具包的核心价值和应用场景。接下来的章节将会更深入地探讨如何使用PyTorch进行文本分类以及高级技术的实现与应用。
# 2. PyTorch文本分类基础
## 2.1 文本分类任务的理论基础
### 2.1.1 自然语言处理简介
自然语言处理(Natural Language Processing,NLP)是人工智能的一个重要分支,致力于研究如何让计算机理解和处理人类语言。它涉及语言学、计算机科学和人工智能等多个领域。NLP的核心任务包括语言理解、生成、翻译、情感分析和语音识别等。文本分类作为NLP的一个基础任务,广泛应用于垃圾邮件检测、主题识别、情感分析等领域。
在文本分类任务中,我们需要将文本数据映射到一个或多个预定义的类别中。这个过程涉及数据的提取、处理和模型的训练,最终实现文本到标签的映射。随着深度学习技术的发展,尤其是卷积神经网络(CNN)和循环神经网络(RNN)等模型在NLP任务中的应用,文本分类的性能得到了显著提升。
### 2.1.2 文本分类在NLP中的作用
文本分类是NLP的基础,它为后续的复杂任务提供了必要的信息。在实际应用中,文本分类可以帮助企业更好地理解客户需求,提高搜索结果的相关性,实现自动的内容审查等等。例如,通过情感分析,公司可以了解客户对产品的满意度;通过主题分类,可以自动为新闻文章归类,便于读者查找感兴趣的内容。
此外,文本分类也是许多复杂任务的基石。例如,在机器翻译中,首先需要识别出句子的意图,再进行语义上的转换;在问答系统中,通过分类技术确定问题的类别,然后从知识库中检索答案。因此,掌握文本分类的原理和方法对于深入研究NLP至关重要。
## 2.2 PyTorch中的数据处理
### 2.2.1 数据加载和预处理
在文本分类任务中,数据加载和预处理是至关重要的步骤。PyTorch提供了一系列工具和方法来处理这些任务。
数据加载通常使用`torch.utils.data.Dataset`和`torch.utils.data.DataLoader`。`Dataset`类需要我们定义`__init__`, `__getitem__`, 和 `__len__`三个方法。`DataLoader`则负责将数据批量加载到内存中,并可以设置多线程加载数据以加快速度。在加载文本数据时,通常需要进行分词、去除停用词、文本向量化等预处理操作。
例如,下面的代码展示了如何使用`DataLoader`批量加载文本数据:
```python
import torch
from torch.utils.data import DataLoader
from torchtext.data.utils import get_tokenizer
from torchtext.vocab import build_vocab_from_iterator
# 示例文本数据
text_data = ["Hello world", "PyTorch is great"]
# 分词器
tokenizer = get_tokenizer('basic_english')
# 数据加载器
class TextDataset(torch.utils.data.Dataset):
def __init__(self, data):
self.data = data
def __getitem__(self, index):
return torch.tensor(data[index])
def __len__(self):
return len(self.data)
dataset = TextDataset([tokenizer(text) for text in text_data])
dataloader = DataLoader(dataset, batch_size=1, shuffle=True)
for batch in dataloader:
print(batch)
```
### 2.2.2 文本向量化和批处理
文本向量化是将文本转换成模型可以理解的数值表示。在PyTorch中,常用的文本向量化方法有词袋模型(BOW)、TF-IDF以及Word Embeddings等。对于深度学习模型,通常使用预训练的词嵌入(如Word2Vec、GloVe)来表示文本数据。
文本批处理是为了提高模型训练的效率和内存利用率。通过批处理,可以一次性将多个样本送入模型中,而不是逐个处理,这样能够显著提升训练速度。PyTorch的`DataLoader`已经内置了批处理的功能。
下面的代码演示了如何使用`torch.nn.Embedding`创建词嵌入层,并应用到一批文本数据中:
```python
import torch.nn as nn
# 假设我们已经有了一个词汇表
vocab = ['<unk>', 'hello', 'world', 'pytorch', 'great']
vocab_size = len(vocab)
# 创建一个嵌入层
embedding_layer = nn.Embedding(num_embeddings=vocab_size, embedding_dim=5)
# 将词汇表中的单词索引化
input_texts = ["hello world", "pytorch is great"]
input_indices = [tokenizer(text) for text in input_texts]
# 假设我们将索引转换为LongTensor
input_indices_tensor = torch.tensor(input_indices)
# 应用嵌入层
embedded_texts = embedding_layer(input_indices_tensor)
print(embedded_texts)
```
在上述代码中,我们创建了一个5维的词嵌入层,并将示例文本数据转换为词索引和词嵌入向量。这些向量可以被用来训练或测试文本分类模型。
通过上述步骤,我们可以将原始文本数据转换为模型可处理的格式,为训练模型做好准备。接下来,我们将深入探讨PyTorch中的模型构建基础。
# 3. PyTorch文本分类实践技巧
## 3.1 数据增强与预处理技术
文本数据增强和预处理是任何NLP项目成功的基石。在实际应用中,文本数据可能面临多种问题,如数据量不足、噪声、不平衡等。数据增强技术可以改善这些问题,提升模型的泛化能力。预处理技巧则涉及选择合适的编码方式和预处理步骤,为模型提供结构化的输入数据。
### 3.1.1 文本数据增强方法
文本数据增强包括但不限于以下几种技术:
- **同义词替换(Synonym Replacement)**:用同义词替代原文中的某些词汇,可以增加文本的多样性。
- **随机插入(Random Insertion)**:随机地在句子中插入新词汇或短语。
- **随机交换(Random Swap)**:随机交换句子中的两个单词。
- **随机删除(Random Deletion)**:随机删除句子中的单词。
这些方法可以手动实现,也可以通过一些现成的库来自动化,例如使用nlpaug库。
```python
from nlpaug.augmenter.word import SynonymAug
# 初始化同义词替换数据增强器
aug = SynonymAug(aug_src='wordnet')
# 原始文本
text = "PyTorch is an open source deep learning platform."
# 数据增强后的文本
augmented_text = aug.augment(text)
```
同义词替换的逻辑分析:
1. 导入`SynonymAug`类,它用于同义词替换。
2. 初始化`SynonymAug`实例,指定同义词来源为`wordnet`。
3. 定义原始文本。
4. 使用`augment`方法对文本进行增强。
### 3.1.2 预处理技巧与编码选择
在文本分类任务中,常用到的编码技术包括词袋(Bag of Words),TF-IDF,Word Embeddings(如Word2Vec,GloVe)以及BERT嵌入。预处理步骤可能包括:
- **文本清洗**:去除无关字符,如HTML标签、特殊符号等。
- **分词**:将文本拆分为单词或子词单元。
- **转换大小写**:将所有单词转换为统一的大小写。
- **去除停用词**:移除常见但对分析没有用处的词汇。
- **词干提取或词形还原**:将词汇转换为基本形

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 PyTorch 框架为基础,深入探讨文本分类的各个方面。从模型调试、神经网络架构选择,到细粒度分类策略、数据增强技术,再到并行计算优化、错误分析方法和模型部署最佳实践,专栏涵盖了文本分类的方方面面。此外,专栏还介绍了定制化损失函数在文本分类中的创新应用,为读者提供全面且实用的指导,帮助他们构建高效且准确的文本分类模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
VFP编程最佳实践:命令与函数的高效结合

# 摘要
Visual FoxPro (VFP) 是一种功能强大的数据库管理系统,具有丰富的编程环境和用户界面设计能力。本文从基础到高级应用,全面介绍了VFP编程的基础知识、命令与函数、数据处理技术、表单和报告开发以及高级应用技巧。文中详细探讨了VFP命令的分类、函数的应用以及如何有效地处理数据和优化性能。此外,本文还阐述了如何设计用户友好的表单界面,处理表单事件,并通过生成报告实现数据的
B-7部署秘籍:解锁最佳实践,规避常见陷阱(彻底提升部署效率)
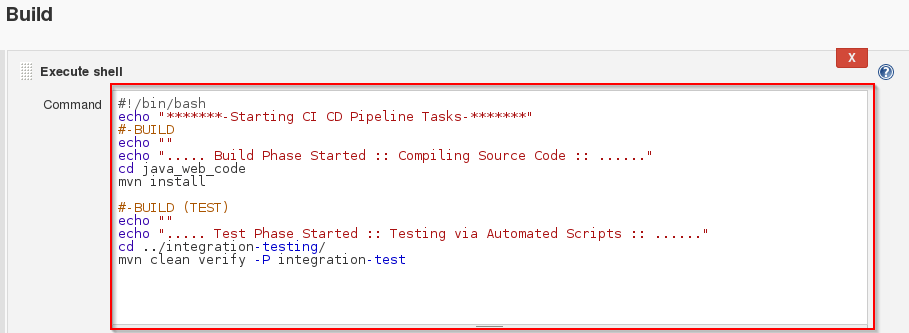
# 摘要
部署是软件开发周期中的关键环节,其效率和准确性直接影响到软件交付的速度和质量。本文旨在全面探讨软件部署的基础概念、流程、策略、测试验证及常见问题的应对方法。文中详细分析了部署的理论基础和实践应用,着重介绍了持续集成与持续部署(CI/CD)、版本控制及自动化部署工具的重要性。同
【UFS版本2.2实战应用】:移动设备中如何应对挑战与把握机遇

# 摘要
随着移动设备对存储性能要求的不断提高,通用闪存存储(UFS)版本2.2作为新一代存储技术标准,提供了高速数据传输和优越的能耗效率。本文概述了UFS 2.2的技术进步及其在移动设备中的理论基础,包括与EMMC的对比分析、技术规格、性能优势、可靠性和兼容性。此外,实战部署章节探讨了UFS 2.2的集成挑战、应用场景表现和性能测试。文章还
【Cadence波形使用技巧大揭秘】:从基础操作到高级分析的电路分析能力提升

# 摘要
Cadence波形工具是电路设计与分析领域中不可或缺的软件,它提供了强大的波形查看、信号分析、仿真后处理以及数据可视化功能。本文对Cadence波形工具的基本使用、信号测量、数学运算、触发搜索、仿真分析、数据处理以及报告生成等各个方面进行了全面的介绍。重点阐述了波形界面的布局定制、
【索引的原理与实践】:打造高效数据库的黄金法则

# 摘要
数据库索引是提高查询效率和优化系统性能的关键技术。本文全面探讨了索引的基础知识、类型选择、维护优化以及在实际应用中的考量,并展望了索引技术的未来趋势。首先,介绍了索引的基本概念及其对数据库性能的影响,然后详细分析了不同索引类型的适用场景和选择依据,包括B-Tree索引、哈希索引和全文索引。其次,文章深入阐述了索引的创建、删除、维护以及性能监控的策略和工具。第三部分着重讨论了索引在数据库查询优化、数据
深入理解模式识别:第四版习题集,全面详解与实践案例!
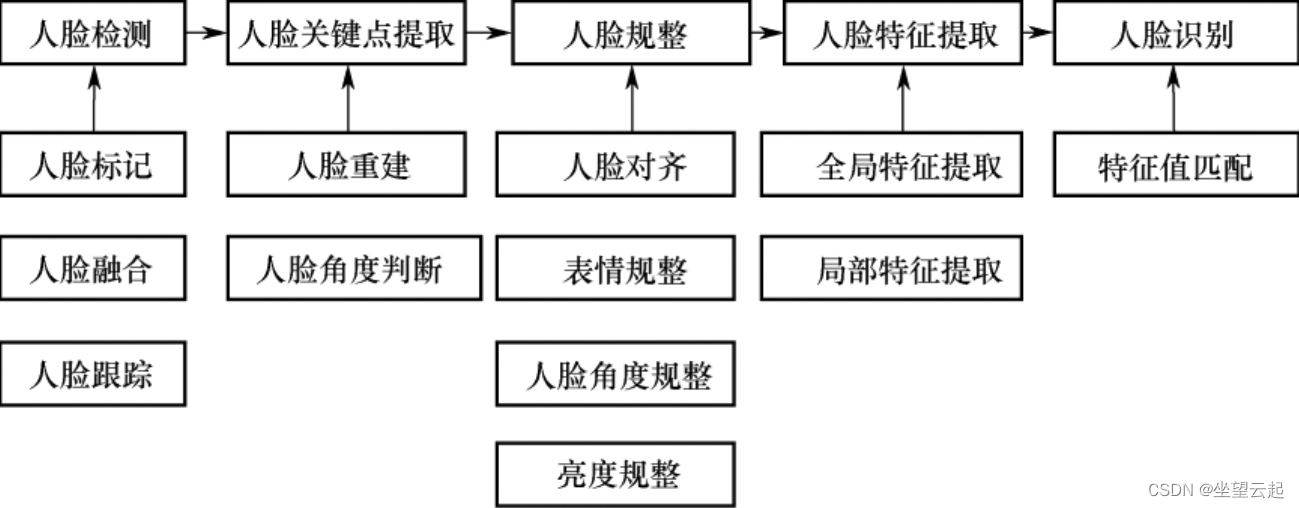
# 摘要
模式识别作为一门交叉学科,涉及从数据中识别模式和规律的理论与实践。本文首先解析了模式识别的基础概念,并详细阐述了其理论框架,包括主要方法(统计学方法、机器学习方法、神经网络方法)、特征提取与选择技术,以及分类器设计的原则与应用。继而,通过图像识别、文本识别和生物信息学中的实践案例,展示了模式识别技术的实际应用。此外,本文还探讨了模式识别算法的性能评估指标、优化策略以及如何应对不平衡数据问题。最后,分析了模式识别技术在医疗健
ISO 11898-1-2015标准新手指南

# 摘要
ISO 11898-1-2015标准是关于CAN网络协议的国际规范,它详细规定了控制器局域网络(CAN)的物理和数据链路层要求,确保了信息在汽车和工业网络中的可靠传输。本文首先概述了该标准的内容和理论基础,包括CAN协议的发展历程、核心特性和关键要求。随后,文章探讨了标准在实际应用中的硬件接口、布线要求、软件实现及网络配置,并通过工程案例分析了标准的具体应用和性能优化方法。高级主题部分讨论了系统集成、实时性、安
【博通千兆以太网终极指南】:5大技巧让B50610-DS07-RDS性能飞跃

# 摘要
本论文全面介绍了博通千兆以太网的基础知识、博通B50610-DS07-RDS芯片的特性、性能优化技巧、故障诊断与排错方法,并展望了千兆以太网及博通技术创新的未来趋势。首先,概述了千兆以太网的基础概念,并详细分析了B50610-DS07-RDS芯片的架构和性能指标,探讨了其在千兆以太网技术标准下的应用场景及优势。接着,研究了该芯片在硬件配置、软件驱动和网络流量管理方面的
【KEIL环境配置高级教程】:BLHeil_S项目理想开发环境的构建
# 摘要
本文全面介绍了KEIL环境配置以及基于BLHeil_S项目的开发板配置、代码开发、管理和调试优化的全过程。首先阐述了KEIL环境的基础知识和软件安装与设置,确保了项目开发的起点。接着详细讲解了开发板硬件连接、软件配置以及启动代码编写和调试,为项目功能实现打下了基础。文章还覆盖了代码的编写、项目构建、版本控制和项目管理,保证了开发流程的规范性和效率。最后,探讨了项目的调试和性能优化,包括使用KEIL调试器、代码性能分析和优化方法。文章旨在提供给读者一个完整的KEIL开发流程,尤其适用于对BLHeil_S项目进行深入学习和开发的工程师和技术人员。
# 关键字
KEIL环境配置;开发板硬
CPCI规范中文版与企业IT战略融合指南:创新与合规并重

# 摘要
本文旨在深入分析CPCI(企业IT合规性与性能指数)规范的重要性以及其与企业IT战略的融合。文章首先概述CPCI规范,并探讨企业IT战略的核心组成部分、发展趋势及创新的作用。接着,文章详细介绍了如何将CPCI规范融入IT战略,并提出制定和执行合规策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )