【Java处理CSV文件技巧】:字符串分割技术的全面解析
发布时间: 2024-09-23 07:27:00 阅读量: 127 订阅数: 39 

java读取csv文件示例分享(java解析csv文件)
# 1. CSV文件处理的基本概念
CSV(Comma-Separated Values,逗号分隔值)文件是一种常见的文本文件格式,它用于存储结构化数据表格,如电子表格或数据库。在CSV文件中,每一行通常表示一条记录,每个记录的字段用逗号分隔开。这种格式简单易读,便于不同系统间的数据交换,因此在数据迁移和数据交换场景中被广泛应用。
CSV文件的简单性使其在程序中易于处理,但也存在一些挑战,比如字段内的逗号、换行符和双引号的处理。正确解析这些特殊字符是确保数据准确性的关键。下一章我们将深入了解Java中用于解析CSV文件的字符串分割技术,并探讨如何应对CSV解析中可能遇到的问题。
# 2. Java字符串分割技术
## 2.1 字符串分割基础
### 2.1.1 分割方法概述
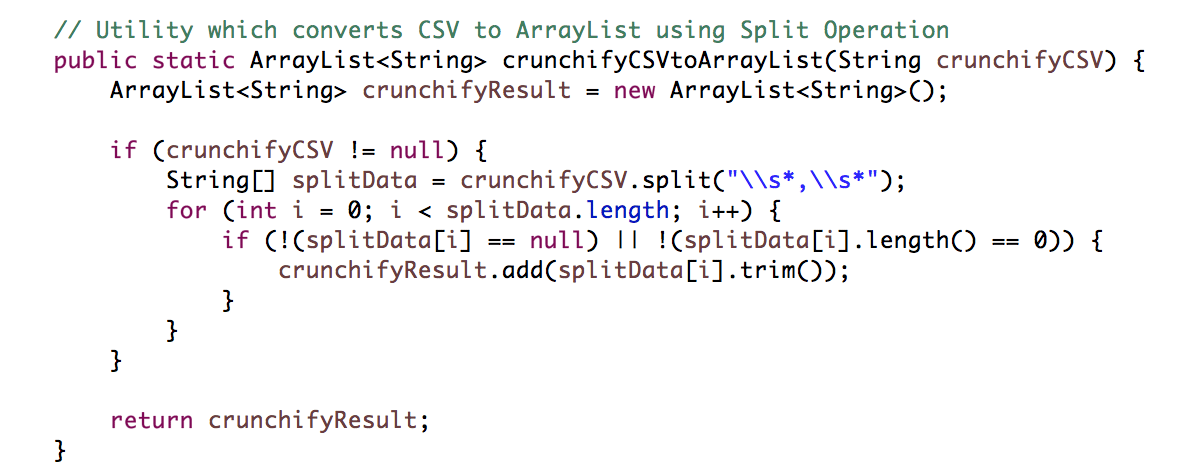
在Java中,字符串分割是一种常见的操作,用于将字符串按照指定的分隔符拆分成子字符串数组。基本的字符串分割方法是`String`类中的`split()`方法。通过指定一个正则表达式作为分隔符,可以将字符串拆分为多个部分。
### 2.1.2 常见的分隔符和它们的使用场景
分隔符可以是简单的字符,如逗号(`,`)、分号(`;`)、空格(` `)等,也可以是复杂的正则表达式。例如,在处理CSV文件时,我们通常会使用逗号作为分隔符。
在处理日志文件时,分隔符可能是一个空格或制表符(`\t`),并且可能伴随着引号内的逗号,这时就需要考虑更复杂的分割逻辑。
## 2.2 高级字符串分割技术
### 2.2.1 正则表达式在字符串分割中的应用
在Java中,`split()`方法接受一个正则表达式作为分隔符。通过使用正则表达式,我们可以定义更加灵活和复杂的分隔模式。
```java
String logEntry = "2023-01-01 INFO Some log message, with comma inside";
String[] parts = logEntry.split(",(?=([^\"]*\"[^\"]*\")*[^\"]*$)");
```
以上代码使用了正则表达式来分割包含逗号的字符串。`(?=...)`是正则表达式的前瞻断言,用于匹配逗号但不包括引号内的内容。
### 2.2.2 性能优化与内存管理
在处理大型文件或需要高性能的场景下,频繁的字符串分割可能会导致性能瓶颈。为了优化性能,我们可以考虑使用`StringTokenizer`类,它比`split()`方法的性能要好,因为它不是一次性生成所有分割后的字符串,而是按需生成。
```java
StringTokenizer st = new StringTokenizer("one,two,three", ",");
while (st.hasMoreTokens()) {
System.out.println(st.nextToken());
}
```
此外,对于内存管理,需要特别注意避免不必要的对象创建,尤其是在循环中。使用更高效的分割方法可以减少字符串实例的创建,从而节省内存。
## 2.3 实战:使用字符串分割解析CSV
### 2.3.1 逐行解析与错误处理
在解析CSV文件时,逐行读取通常是最常见的方法。对于每一行,我们可以使用`split()`方法进行分割。解析过程中可能遇到的错误包括格式错误、缺失的数据等,需要通过异常处理机制来优雅地处理这些错误。
```java
try {
String line = "1,John Doe,30"; // 读取CSV文件中的一行
String[] fields = line.split(","); // 使用逗号分割字符串
// 处理分割后的数据
} catch (Exception e) {
// 错误处理逻辑
}
```
### 2.3.2 处理特殊字符和复杂字段
CSV文件中经常包含特殊字符,如逗号、引号等。对于这种情况,标准的字符串分割方法可能无法正确处理。例如,引号内的逗号应被视为字段的一部分而不是分隔符。处理这些情况需要更复杂的解析逻辑,或者使用专门的CSV解析库。
```java
public class CSVParser {
public static String[] parseCSV(String input) {
// 特殊处理逻辑,考虑引号和逗号的情况
// ...
return new String[]{/* 分割后的字符串数组 */};
}
}
```
以上代码展示了如何自定义一个简单的CSV解析方法。需要注意的是,正确处理特殊字符和复杂字段需要对CSV格式有深入理解,以及编写相应的正则表达式来应对各种特殊情况。
以上内容为第二章的核心部分,覆盖了字符串分割的基础知识、高级技术以及实际的CSV解析应用。在下一章中,我们将深入探讨Java CSV处理库的应用,对比不同库的特点,并给出性能考量的建议。
# 3. Java CSV处理库的应用
## 3.1 CSV处理库的选择与对比
### 3.1.1 常见Java CSV处理库概览
在Java生态系统中,处理CSV文件的库众多,各有千秋。以下列出了一些广泛使用的库,并简单介绍它们的功能:
- **Apache Commons CSV**: Apache提供的CSV处理库,支持多种编码方式,对复杂CSV文件的读写都有良好支持。
- **OpenCSV**: 开源的CSV解析库,易于使用,有较好的性能和错误处理能力。
- **JCSV**: 一个小型且快速的库,提供了简单的API来读写CSV文件。
- **uniVocity-parsers**: 这是一个性能强劲的库,支持多种格式文件的解析,例如CSV、TSV、固定宽度等。
对于Java开发者来说,选择合适的CSV处理库至关重要,它将直接影响到开发效率和应用性能。在决定使用哪个库之前,需要考虑以下几个因素:
- 功能是否满足需求:是否需要读写支持,是否需要处理大型文件等。
- 性能:处理大型文件时的性能表现。
- 社区支持与文档:库的维护情况、社区活跃度及文档完整性。
- 许可证:库的许可证是否适合你的项目。
### 3.1.2 库的功能对比与选型建议
为了更好地对比各个库的功能,下面列表总结了上文提到的几个库的关键特性:
| 特性 | Apache Commons CSV | OpenCSV | JCSV | uniVocity-parsers |
| ------------------ | ------------------ | ------- | ------- | ----------------- |
| 易用性 | 高 | 中 | 高 | 中 |
| 性能 | 中 | 中 | 中 | 高 |
| 大文件处理支持 | 支持 | 支持 | 不明确 | 支持 |
| 错误处理 | 中 | 中 | 低 | 高 |
| 社区活跃度 | 高 | 高 | 低 | 中 |
| 文档完整性 | 高 | 高 | 低 | 中 |
| 许可证 | Apache 2.0 | Apache 2.0 | Apache 2.0 | BSD |
根据上表的对比信息,**Apache Commons CSV** 和 **OpenCSV** 都是不错的选择,拥有较高的社区支持和文档质量。如果你的应用在处理大型CSV文件时有较高的性能要求,**uniVocity-parsers** 可能是更好的选择。而如果你需要一个轻量级且易于上手的解决方案,**JCSV** 可以考虑。
选择合适的CSV处理库,可以让项目开发工作事半功倍。无论是处理日常的数据交换任务还是构建复杂的数据处理流程,一个合适的库都会成为你工作中的得力助手。
## 3.2 使用Apache Commons CSV解析和生成CSV文件
### 3.2.1 API介绍和基本使用方法
Apache Commons CSV库提供了非常直观和易于使用的API来解析和生成CSV文件。以下是使用此库的一些基本步骤:
1. **添加依赖**:首先需要将Apache Commons CSV的依赖添加到你的项目中。在Maven项目中,可以在`pom.xml`文件中添加以下依赖:
```xml
<dependency>
<groupId>***mons</groupId>
<artifactId>commons-csv</artifactId>
<version>1.8</version>
</dependency>
```
2. **解析CSV文件**:使用`CSVFormat`类定义CSV文件的格式,然后通过`CSVParser`类解析文件。
```java
CSVFormat format = CSVFormat.DEFAULT;
try (CSVParser parser = new CSVParser(new FileReader("input.csv"), format)) {
for (CSVRecord record : parser) {
String field1 = record.get(0);
String field2 = record.get(1);
// 处理每一个记录中的字段
}
}
```
3. **生成CSV文件**:定义CSV格式后,可以创建`CSVPrinter`对象来生成CSV文件。
```java
CSVFormat format = CSVFormat.DEFAULT.withHeader("Column1", "Column2");
try (CSVPrinter printer = new CSVPrinter(new FileWriter("output.csv"), format)) {
printer.printRecord("value1", "value2");
// 打印更多的记录
}
```
### 3.2.2 高级特性解析与性能考量
Apache Commons CSV库还提供了一些高级特性,比如自定义的分隔符和引号字符:
```java
CSVFormat format = CSVFormat.DEFAULT.withDelimiter(';').withQuote('"');
```
对于性能考量,Apache Commons CSV库在处理大型文件时表现优秀。但是,内存消耗也是一个需要注意的问题。解析文件时,每一行都会被存储为一个`CSVRecord`对象,这在处理巨量行的文件时可能会导致内存溢出。为了优化性能,可以考虑逐行读取并实时处理数据,而不是一次性将所有数据加载到内存中。
```java
CSVFormat format = CSVFormat.DEFAULT;
try (CSVParser parser = new CSVParser(new FileReader("large.csv"), format)) {
parser.getHeaderMap(); // 首先获取头部信息(如果存在)
String[] line;
while ((line = parser.getLine()) != null) {
// 逐行处理数据
}
}
```
在实际应用中,使用Apache Commons CSV库处理CSV文件时,建议进行性能测试以确定最佳配置。这包括选择合适的缓冲区大小、决定是否使用异步读写以及测试不同大小文件的处理时间。
## 3.3 使用OpenCSV处理复杂CSV场景
### 3.3.1 OpenCSV的高级功能
OpenCSV库以其简洁的API和强大的功能而受到开发者们的喜爱。它提供了多种高级功能,比如自定义分隔符、忽略空白行以及对特殊字符的处理。以下是使用OpenCSV进行高级操作的示例:
1. **自定义分隔符和引号**:
```java
CSVReaderBuilder builder = new CSVReaderBuilder(new FileReader("path/to/file.csv"));
CSVReader reader = builder.withCSVFormat(new CSVFormat.Builder().setDelimiter(';').setQuote('\'').build()).build();
```
2. **忽略空白行和注释行**:
```java
CSVReader reader = new CSVReaderBuilder(new FileReader("path/to/file.csv"))
.withCSVFormat(CSVFormat.DEFAULT.withSkipHeaderRecord(true).withIgnoreEmptyLines(true))
.build();
```
### 3.3.2 处理大型文件与性能优化
在处理大型CSV文件时,OpenCSV同样表现出色。其`CSVReader`类设计为逐行读取,不会一次性将所有内容加载到内存中,这对于大型文件处理来说是一个巨大的优势。此外,可以通过配置合适的缓冲区大小来提高读取效率。
```java
CSVReader reader = new CSVReader(new FileReader("path/to/large.csv"), ',', CSVWriter.NO_QUOTE_CHARACTER, 1024);
```
上面的代码示例中,缓冲区大小设置为1024字节,可以根据文件的大小和系统性能进行调整。
OpenCSV库还支持同时读取多个CSV文件,这对于需要并行处理多个文件的场景非常有用。使用`CSVReader`的`readAll()`方法可以读取文件的所有行到一个`List`中,然后可以使用`Iterator`遍历每一行。
```java
CSVReader reader = new CSVReader(new FileReader("path/to/file.csv"));
List<String[]> records = reader.readAll();
Iterator<String[]> iterator = records.iterator();
while (iterator.hasNext()) {
String[
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Java字符串分割艺术”专栏,在这里,我们将深入剖析Java中的字符串分割技术。从基本概念到高级技巧,我们将探讨如何优雅地处理特殊字符、优化性能、解析CSV文件,以及在并发编程和数据清洗中应用字符串分割。通过一系列深入的文章,您将掌握字符串分割的最佳实践,了解其内部实现,并探索其在各种场景中的应用。无论您是Java初学者还是经验丰富的开发人员,本专栏都将为您提供宝贵的见解,帮助您提升字符串处理技能,编写健壮且高效的代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【QT基础入门】:QWidgets教程,一步一个脚印带你上手
# 摘要
本文全面介绍了Qt框架的安装配置、Widgets基础、界面设计及进阶功能,并通过一个综合实战项目展示了这些知识点的应用。首先,文章提供了对Qt框架及其安装配置的简要介绍。接着,深入探讨了Qt Widgets,包括其基本概念、信号与槽机制、布局管理器等,为读者打下了扎实的Qt界面开发基础。文章进一步阐述了Widgets在界面设计中的高级用法,如标准控件的深入使用、资源文件和样式表的应用、界面国际化处理。进阶功能章节揭示了Qt对话框、多文档界面、模型/视图架构以及自定义控件与绘图的强大功能。最后,实战项目部分通过需求分析、问题解决和项目实现,展示了如何将所学知识应用于实际开发中,包括项目
数学魔法的揭秘:深度剖析【深入理解FFT算法】的关键技术

# 摘要
快速傅里叶变换(FFT)是信号处理领域中一项关键的数学算法,它显著地降低了离散傅里叶变换(DFT)的计算复杂度。本文从FFT算法的理论基础、实现细节、在信号处理中的应用以及编程实践等多方面进行了详细讨论。重点介绍了FFT算法的数学原理、复杂度分析、频率域特性,以及常用FFT变体和优化技术。同时,本文探讨了FFT在频谱分析、数字滤波器设计、声音和图像处理中的实
MTK-ATA技术入门必读指南:从零开始掌握基础知识与专业术语

# 摘要
MTK-ATA技术作为一种先进的通信与存储技术,已经在多个领域得到广泛应用。本文首先介绍了MTK-ATA技术的概述和基础理论,阐述了其原理、发展以及专业术语。随后,本文深入探讨了MTK-ATA技术在通信与数据存储方面的实践应用,分析了其在手机通信、网络通信、硬盘及固态存储中的具体应用实例。进一步地,文章讲述了MTK-ATA技术在高
优化TI 28X系列DSP性能:高级技巧与实践(性能提升必备指南)

# 摘要
本文系统地探讨了TI 28X系列DSP性能优化的理论与实践,涵盖了从基础架构性能瓶颈分析到高级编译器技术的优化策略。文章深入研究了内存管理、代码优化、并行处理以及多核优化,并展示了通过调整电源管理和优化RTOS集成来进一步提升系统级性能的技巧。最后,通过案例分析和性能测试验证了优化
【提升响应速度】:MIPI接口技术在移动设备性能优化中的关键作用

# 摘要
移动设备中的MIPI接口技术是实现高效数据传输的关键,本论文首先对MIPI接口技术进行了概述,分析了其工作原理,包括MIPI协议栈的基础、信号传输机制以及电源和时钟管理。随后探讨了MIPI接口在移动设备性能优化中的实际应用,涉及显示和摄像头性能提升、功耗管理和连接稳定性。最后,本文展望了MIPI技术的未来趋势,分析了新兴技术标准的进展、性能优化的创新途径以及当前面临的技术挑战。本论文旨在为移动
PyroSiM中文版高级特性揭秘:精通模拟工具的必备技巧(专家操作与界面布局指南)
# 摘要
PyroSiM是一款功能强大的模拟软件,其中文版提供了优化的用户界面、高级模拟场景构建、脚本编程、自动化工作流以及网络协作功能。本文首先介绍了PyroSiM中文版的基础配置和概览,随后深入探讨了如何构建高级模拟场景,包括场景元素组合、模拟参数调整、环境动态交互仿真、以及功能模块的集成与开发。第三章关注用户界面的优化
【云计算优化】:选择云服务与架构设计的高效策略
# 摘要
本文系统地探讨了云计算优化的各个方面,从云服务类型的选择到架构设计原则,再到成本控制和业务连续性规划。首先概述了云计算优化的重要性和云服务模型,如IaaS、PaaS和SaaS,以及在选择云服务时应考虑的关键因素,如性能、安全性和成本效益。接着深入探讨了构建高效云架构的设计原则,包括模块化、伸缩性、数据库优化、负载均衡策略和自动化扩展。在优化策
性能飙升指南:Adam's CAR性能优化实战案例
# 摘要
随着软件复杂性的增加,性能优化成为确保应用效率和响应速度的关键环节。本文从理论基础出发,介绍了性能优化的目的、指标及技术策略,并以Adam's CAR项目为例,详细分析了项目性能需求及优化目标。通过对性能分析与监控的深入探讨,本文提出了性能瓶颈识别和解决的有效方法,分别从代码层面和系统层面展示了具体的优化实践和改进措施。通过评估优化效果,本文强调了持续监控和分析的重要性,以实现性能的持续改进和提升。
#
【Oracle服务器端配置】:5个步骤确保PLSQL-Developer连接稳定性
# 摘要
本文对Oracle数据库服务器端配置进行了详细阐述,涵盖了网络环境、监听器优化和连接池管理等方面。首先介绍
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )