Haystack与Solr:比较与选择最佳搜索引擎(选型指南)
发布时间: 2024-10-15 16:47:23 阅读量: 2 订阅数: 3 

# 1. 搜索引擎基础知识
在探讨Haystack和Solr之前,我们需要对搜索引擎的基本概念有所了解。搜索引擎是一种能够对互联网或内部数据库中的信息进行索引、存储、管理和检索的系统。它通过特定的算法对数据进行排序,将最相关的结果呈现给用户。搜索引擎主要分为两类:全文搜索引擎和元搜索引擎。
全文搜索引擎,如Elasticsearch和Solr,能够索引和搜索文档内容,而元搜索引擎则整合多个搜索引擎的结果。搜索引擎的基础工作流程包括抓取(Crawling)、索引(Indexing)、查询(Querying)和排序(Ranking)四个阶段。
- **抓取**:爬虫(Crawler)访问网站并收集网页信息。
- **索引**:将收集的数据进行解析并存储到数据库中,为快速检索做准备。
- **查询**:用户输入查询语句,搜索引擎在索引中查找相关结果。
- **排序**:根据算法评估结果的相关性,并将最相关的结果展示给用户。
搜索引擎的性能和效率在很大程度上取决于其索引和查询的优化。在后续章节中,我们将深入探讨Haystack和Solr这两个强大的搜索引擎工具,以及它们如何在实际应用中发挥作用。
# 2. Haystack和Solr的基本概念
## 2.1 Haystack简介
### 2.1.1 Haystack的起源和发展
Haystack是一个开源的搜索引擎框架,专为Python应用设计,它构建在Elasticsearch、Whoosh或Xapian之上。Haystack的起源可以追溯到2007年,最初由Paul Robinson开发,目的是为了解决Django(一个Python Web框架)项目的搜索需求。随着时间的推移,Haystack逐渐发展成为一个成熟的项目,并被广泛应用于各种Python Web应用中。
Haystack的设计理念是为了解决Web应用中的搜索问题,提供一个简单、可扩展的搜索接口。它抽象了底层搜索引擎的复杂性,使得开发者可以更容易地在他们的应用中集成搜索功能。Haystack支持多种底层搜索引擎,使得开发者可以根据自己的需求选择最适合的搜索引擎。
### 2.1.2 Haystack的主要功能和特点
Haystack的核心功能是提供一个统一的搜索接口,允许开发者使用不同的搜索引擎。它的主要特点包括:
- **抽象层**:Haystack提供了一个抽象层,使得开发者不需要直接与底层搜索引擎交互,简化了搜索功能的实现。
- **可扩展性**:开发者可以通过自定义后端、查找器(Searcher)和处理器(Processor)来扩展Haystack的功能。
- **ORM集成**:Haystack与Django ORM集成得非常好,可以直接使用Django模型进行搜索,无需额外的配置。
- **全文搜索**:支持全文搜索,并且可以通过简单的配置来实现相关性排序。
- **高亮显示**:搜索结果可以高亮显示,提高用户体验。
## 2.2 Solr简介
### 2.2.1 Solr的起源和发展
Solr是一个基于Lucene的开源搜索引擎,它提供了一个分布式搜索服务器的功能。Solr的起源可以追溯到2004年,最初是由CNET Networks公司的子公司Compass Labs开发的。Compass Labs在2006年被捐赠给了Apache软件基金会,成为Apache顶级项目。
Solr的设计理念是为了解决企业级搜索需求,提供一个高性能、可扩展的搜索引擎。它内置了许多功能,如全文搜索、近实时搜索、自动索引复制等,使得它非常适合用作大型企业搜索引擎。
### 2.2.2 Solr的主要功能和特点
Solr的主要功能包括:
- **全文搜索**:支持包括文本、数字、地理空间等多种类型的字段搜索。
- **可扩展性**:支持分布式搜索,可以通过Sharding和Replication实现水平扩展。
- **丰富的API**:提供了丰富的API接口,包括RESTful API、Java API等,方便开发者集成和使用。
- **配置灵活性**:可以通过XML配置文件来配置索引字段、搜索参数等。
- **近实时搜索**:提供了近实时搜索功能,索引更改后可以立即被搜索到。
## 2.3 Haystack与Solr的对比分析
### 2.3.1 技术架构对比
Haystack和Solr在技术架构上有显著的差异。Haystack作为一个搜索引擎框架,更多的是一种抽象层,它依赖于底层的搜索引擎(如Elasticsearch、Whoosh或Xapian)。这意味着Haystack本身并没有存储数据的能力,所有的索引数据都存储在其底层搜索引擎中。
相比之下,Solr是一个独立的搜索引擎服务器,它内部集成了Lucene搜索引擎,并提供了额外的管理功能和接口。Solr可以独立于应用服务器运行,并支持集群部署,适合于大型分布式搜索需求。
### 2.3.2 性能对比
在性能方面,Solr由于其内置的分布式特性,通常在处理大规模数据集时表现更好。它支持Sharding和Replication,可以在多服务器间分布搜索负载,提高系统的可靠性和扩展性。
Haystack的性能依赖于底层搜索引擎的性能。例如,如果使用Elasticsearch作为Haystack的后端,那么在某些场景下,它的性能可能会与直接使用Elasticsearch相当。然而,由于Haystack抽象了一层,可能会带来一定的性能开销。
### 2.3.3 功能对比
Solr提供了更多原生的搜索引擎功能,如自动索引复制、Sharding、近实时搜索等,这些功能在Haystack中可能需要通过自定义扩展或额外的配置来实现。
Haystack则提供了更为简洁的接口和与Django ORM的紧密集成,使得在Django项目中集成搜索功能变得更加简单。此外,Haystack还提供了更加灵活的后端选择,允许开发者根据项目需求选择不同的搜索引擎。
### 2.3.4 社区和生态系统对比
Solr和Elasticsearch有着庞大的社区支持,因此在文档、插件、社区支持等方面都非常丰富。这使得开发者在遇到问题时更容易找到解决方案,也可以更快地学习和掌握这些技术。
Haystack虽然不如Solr和Elasticsearch那么流行,但它有一个活跃的社区,并且由于其依赖于Python和Django,它在Python社区中有着良好的口碑。对于那些已经在使用Django的项目,Haystack提供了一个非常方便的搜索引擎集成方案。
### 2.3.5 总结
通过本

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PycURL错误处理必修课:网络请求异常处理的艺术
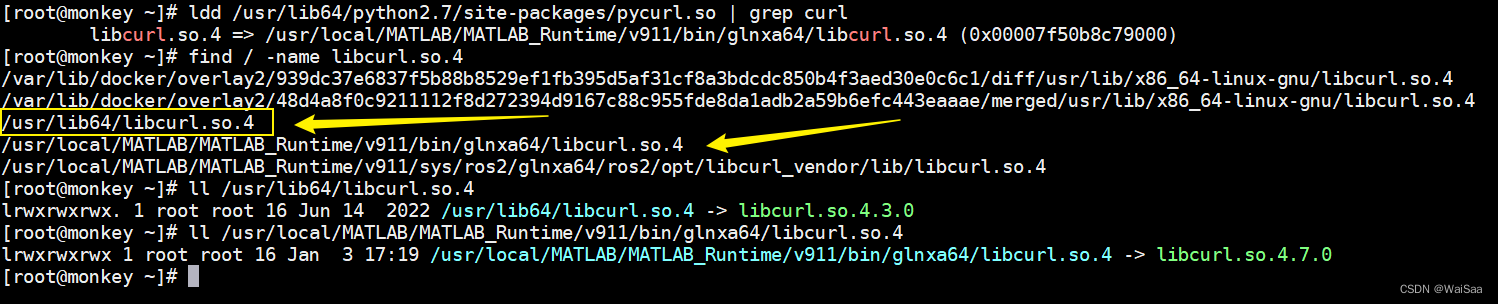
# 1. PycURL简介与安装
## 1.1 PycURL简介
PycURL是一个用于处理URL请求的库,它是libcurl的Python封装,提供了一种高效的方式来执行多种类型的网络请求。与Python标准库中的urllib相比,PycURL在处理大量请求时具有更好的性能和灵活性。
## 1.2 安装PycURL
安装PycURL可以通过Python的包管理工具pip来完成。在命令行中输入以下命令即
Django multipartparser与其他库的集成:如Celery、Redis与Django表单的实践指南
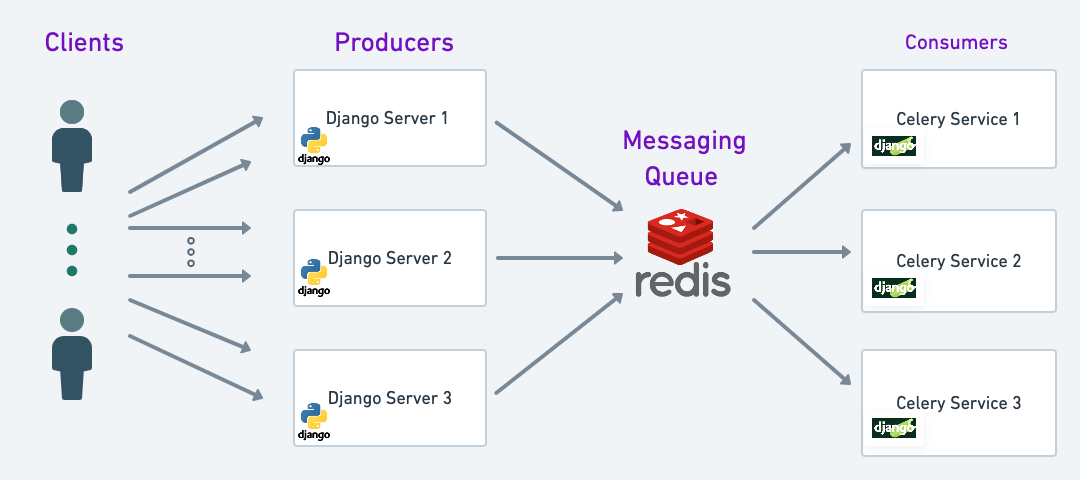
# 1. Django multipartparser简介
Django作为一个功能强大的Python Web框架,提供了一套完整的工具来处理文件上传。`multipartparser`是Django内部用于解析`multipart/form-data`请求体的模块,它为开发者提供了一种高效的方式来处理文件上传的底层细节。
## 什么是Django mult
Numpy.linalg高级应用:奇异值分解(SVD)的深度解析
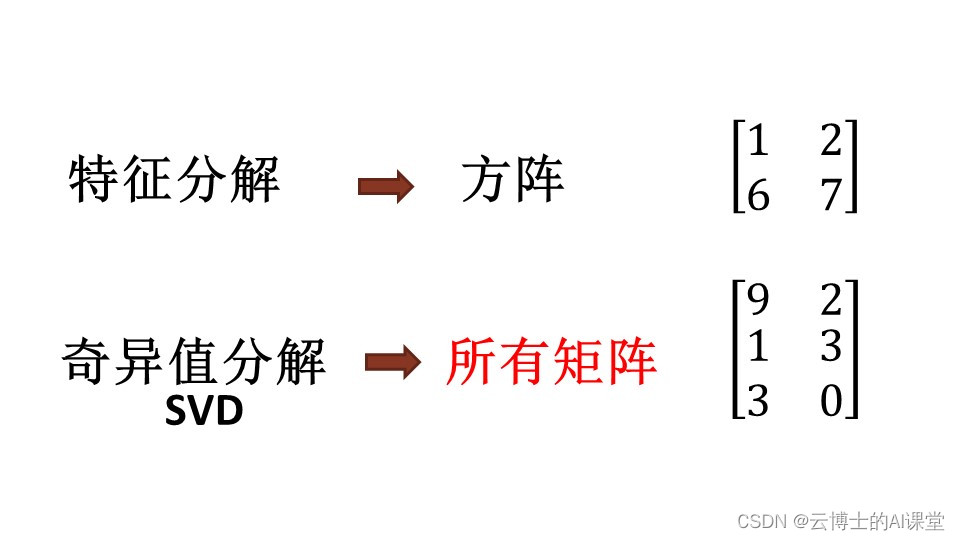
# 1. 奇异值分解(SVD)概述
## 1.1 SVD的定义与重要性
奇异值分解(SVD)是线性代数中一种强大的矩阵分解技术,它能够将任意矩阵分解为三个特定矩阵的乘积。这种分解不仅揭示了数据的内在结构,而且在数据压缩、图像处理、机器学习等领域有着广泛的应用。SVD的重要性在于它能够处理非方阵,且分解后的奇异值能够反映矩阵的特征,这对于理解数据的本质特征至关重要。
##
【敏捷开发中的Django版本管理】:如何在敏捷开发中进行有效的版本管理
# 1. 敏捷开发与Django版本管理概述
## 1.1 敏捷开发与版本控制的关系
在敏捷开发过程中,版本控制扮演着至关重要的角色。敏捷开发强调快速迭代和响应变化,这要求开发团队能够灵活地管理代码变更,确保各个迭代版本的质量和稳定性。版本控制工具提供了一个共享代码库,使得团队成员能够并行工作,同时跟踪每个成员的贡献。在Django项目中,版本控制不仅能帮助开发者管理代码
Pygments.filter模块版本升级:平滑过渡到新版本
# 1. Pygments.filter模块概述
Pygments 是一个用Python编写的通用语法高亮工具,广泛应用于源代码高亮显示。而 `Pygments.filter` 模块是其核心组件之一,它提供了一种灵活的方式来创建和应用代码过滤器,从而实现源代码的高亮显示。这个模块允许开发者自定义过滤器规则,以适应各种复杂的高亮需求。在本章中,我们将对
xml.dom.minidom.Node的数据绑定:将XML数据映射到Python对象的创新方法

# 1. XML数据绑定的概念与重要性
XML数据绑定是将XML文档中的数据与应用程序中的数据结构进行映射的过程,它是数据交换和处理中的一项关键技术。在现代软件开发中,数据绑定的重要性日益凸显,因为它简化了数据访问和管理,使得开发者可以更加专注于业务
【Django文件校验:性能监控与日志分析】:保持系统健康与性能
# 1. Django文件校验概述
## 1.1 Django文件校验的目的
在Web开发中,文件上传和下载是常见的功能,但它们也带来了安全风险。Django文件校验机制的目的是确保文件的完整性和安全性,防止恶意文件上传和篡改。
## 1.2 文件校验的基本流程
文件校验通常包括以下几个步骤:
1. **文件上传**:用户通过Web界面上传文件。
Python Zip库的文档与性能分析:提升代码可读性和性能瓶颈的解决策略

# 1. Python Zip库概述
Python的Zip库为处理ZIP格式的压缩文件提供了便利,无需借助外部工具即可在Python环境中实现文件的压缩和解压。ZIP文件格式广泛应用于文件归档、备份以及跨平台的数据交换,因其高效的压缩率和跨平台的兼容性而被广泛使用。本章将介绍Zip库的基本概念和应用,为后续章节的深入学习打下基础。
## 2. Zip库的理论基础
###
【data库的API设计】:设计易于使用的data库接口,让你的代码更友好

# 1. data库API设计概述
在当今快速发展的信息技术领域,API(应用程序编程接口)已成为不同软件系统之间交互的桥梁。本文将深入探讨`data`库API的设计,从概述到实际应用案例分析,为读者提供一个全面的视角。
## API设计的重要性
Pylons WebSockets实战:实现高效实时通信的秘诀

# 1. Pylons WebSockets基础概念
## 1.1 WebSockets简介
在Web开发领域,Pylons框架以其强大的功能和灵活性而闻名,而WebSockets技术为Web应用带来了全新的实时通信能力。WebSockets是一种网络通信协议,它提供了浏览器和服务器之间全双工的通信机制,这意味着服务器可以在任何时候向客户端发送消息,而不仅仅是响应客户端的请求。
## 1.2 WebSockets的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )