Go语言数据库交互指南:为RESTful API构建健壮的数据层
发布时间: 2024-10-22 11:30:00 阅读量: 21 订阅数: 28 

基于STM32单片机的激光雕刻机控制系统设计-含详细步骤和代码

# 1. Go语言与数据库交互基础
## 1.1 Go语言简介与数据库交互需求
Go语言(又称Golang)由Google开发,具有简洁、快速、安全和并发性等特性,已经成为云计算、微服务等领域的热门语言之一。随着软件开发复杂性的增加,Go语言开发者经常需要与数据库进行交互,以支持应用程序的数据持久化。
## 1.2 数据库交互的意义与基本原理
数据库交互是应用程序与数据库管理系统(DBMS)之间交换数据的过程。无论是关系型数据库如PostgreSQL、MySQL,还是NoSQL数据库如MongoDB、Redis,Go语言都能够通过相应的数据库驱动实现高效的数据操作。
## 1.3 Go语言数据库交互的准备工作
在开始编写Go程序以与数据库进行交互之前,开发者需要准备以下几项:
- 安装并配置好目标数据库环境。
- 了解目标数据库的基本操作和SQL语法。
- 安装Go语言的数据库驱动包,例如`***/go-sql-driver/mysql`用于MySQL数据库。
接下来,章节将进一步探讨Go语言如何连接和操作数据库,及其在不同数据库环境中的应用。
# 2. Go语言中数据库的连接与操作
### 2.1 Go语言数据库连接
#### 2.1.1 数据库驱动的加载与初始化
在Go语言中,数据库驱动通常是一个实现了database/sql包接口的包。在开始与数据库交互前,第一步是加载并初始化对应的数据库驱动。每个数据库驱动在初始化时都会注册一个驱动名称到全局的sql.RegisterDBDriver函数中,这样sql.Open就能根据驱动名称找到对应的驱动实例。
例如,使用官方的`database/sql`包和`***/go-sql-driver/mysql`驱动,连接MySQL数据库的代码如下:
```go
package main
import (
"database/sql"
_ "***/go-sql-driver/mysql"
)
func main() {
dsn := "username:password@tcp(localhost:3306)/dbname"
db, err := sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
defer db.Close() // 程序结束时关闭数据库连接
// 测试连接
err = db.Ping()
if err != nil {
panic(err)
}
}
```
在上述代码中,`sql.Open`函数被用于打开一个到MySQL数据库的连接。注意,我们使用了一个DSN(数据源名称)来连接到MySQL,这个DSN包含了数据库的用户名、密码、地址、端口以及数据库名。
#### 2.1.2 数据库连接的建立与关闭
数据库连接的建立通常通过`sql.Open()`函数来实现,该函数会返回一个`*sql.DB`对象。该对象代表一个连接池,实际的数据库连接会从这个连接池中获取,因此我们不需要关心连接的具体细节,只需通过这个`*sql.DB`对象进行CRUD操作即可。
关闭数据库连接则通常使用`db.Close()`函数,这是一个在程序结束时应当执行的操作,以确保所有的连接被正确关闭,释放数据库资源。
```go
// ...
// 在程序结束前关闭数据库连接
if db != nil {
db.Close()
}
// ...
```
### 2.2 Go语言数据库CRUD操作
#### 2.2.1 创建记录
在Go中,使用`db.Exec()`方法执行创建操作,它对应于SQL中的INSERT语句。方法返回一个`sql.Result`对象,它提供了影响的行数等信息。
```go
res, err := db.Exec("INSERT INTO users (name, age) VALUES (?, ?)", "John", 30)
if err != nil {
panic(err)
}
rowsAffected, err := res.RowsAffected()
if err != nil {
panic(err)
}
```
在上面的代码中,我们执行了`INSERT`操作,并通过`RowsAffected()`获取了插入记录后影响的行数。
#### 2.2.2 读取记录
查询操作通常使用`db.Query()`或`db.QueryRow()`方法,分别对应于SQL中的SELECT查询和单行查询。对于`db.Query()`方法,返回的是`*sql.Rows`,可以通过迭代进行遍历。
```go
rows, err := db.Query("SELECT id, name, age FROM users WHERE age > ?", 18)
if err != nil {
panic(err)
}
defer rows.Close()
for rows.Next() {
var id int
var name string
var age int
err = rows.Scan(&id, &name, &age)
if err != nil {
panic(err)
}
fmt.Printf("ID: %d, Name: %s, Age: %d\n", id, name, age)
}
```
对于`db.QueryRow()`方法,通常用在查询单条记录的场景下:
```go
var name string
var age int
err := db.QueryRow("SELECT name, age FROM users WHERE id = ?", 1).Scan(&name, &age)
if err != nil {
panic(err)
}
fmt.Printf("Name: %s, Age: %d\n", name, age)
```
#### 2.2.3 更新记录
更新操作与创建操作类似,使用`db.Exec()`执行更新操作对应的SQL语句。
```go
res, err := db.Exec("UPDATE users SET age = ? WHERE id = ?", 31, 1)
if err != nil {
panic(err)
}
rowsAffected, err := res.RowsAffected()
if err != nil {
panic(err)
}
fmt.Printf("%d rows affected\n", rowsAffected)
```
#### 2.2.4 删除记录
删除操作同样使用`db.Exec()`方法。
```go
res, err := db.Exec("DELETE FROM users WHERE id = ?", 1)
if err != nil {
panic(err)
}
rowsAffected, err := res.RowsAffected()
if err != nil {
panic(err)
}
fmt.Printf("%d rows affected\n", rowsAffected)
```
### 2.3 Go语言事务管理
#### 2.3.1 事务的概念与应用场景
事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。事务确保了一组操作要么全部成功,要么全部失败,这为复杂的数据操作提供了安全的执行环境。
事务应用场景包括但不限于:
- 银行系统转账操作
- 购物网站下单支付
- 数据库迁移和批处理任务
#### 2.3.2 事务的操作流程
在Go中,使用`*sql.DB`对象的`Begin()`、`Commit()`和`Rollback()`方法来控制事务。
```go
tx, err := db.Begin()
if err != nil {
panic(err)
}
// 执行操作
_, err = tx.Exec("INSERT INTO users (name, age) VALUES (?, ?)", "Alice", 25)
if err != nil {
tx.Rollback() // 回滚事务
panic(err)
}
// 提交事务
err = ***mit()
if err != nil {
panic(err)
}
```
在上述代码中,我们首先通过`db.Begin()`开始一个事务,然后执行一系列的数据库操作。如果所有操作都成功,则调用`***mit()`提交事务。若中途出现错误,则调用`tx.Rollback()`回滚事务。
#### 2.3.3 事务的高级特性
大多数现代数据库系统提供了更复杂的事务特性,比如保存点(savepoints)、事务隔离级别和死锁预防等。这些特性可以在必要时提供更细粒度的控制,例如在大型系统中处理并发和防止数据不一致。
### 2.4 Go语言连接池管理
Go语言的`database/sql`包已经内置了连接池管理机制,因此通常开发者不需要手动管理连接池。当创建`*sql.DB`对象时,它会自动处理连接的创建和销毁,根据负载调整池中的连接数。
开发者可以通过`SetMaxOpenConns`、`SetMaxIdleConns`和`SetConnMaxLifetime`等方法调整连接池的行为。
```go
// 设置最大打开的连接数
db.SetMaxOpenConns(10)
// 设置最大闲置的连接数
db.SetMaxIdleConns(5)
// 设置连接的最大存活时间
db.SetConnMaxLifetime(time.Hour)
```
以上代码展示了如何通过`*sql.DB`的`SetMaxOpenConns`、`SetMaxIdleConns`和`SetConnMaxLifetime`方法来控制数据库连接池的大小和生命周期,以优化数据库资源的使用。
在Go中,与数据库的连接和操作是高效且直接的。理解如何使用`database/sql`包来管理数据库连接、执行CRUD操作以及处理事务对于任何想要在Go中与数据库交互的开发者来说都是至关重要的。这一章节主要介绍了数据库连接建立、CRUD操作以及事务管理的基本知识。而下一章将探讨RESTful API与数据库交互的实践技巧。
# 3. Go语言数据库交互实践
## 3.1 RESTful API与数据库交互
### 3.1.1 RESTful API设计原则
在开发面向Web的应用程序时,RESTful API已成为一种标准,它允许应用程序通过HTTP协议的GET、POST、PUT、DELETE等方法与服务器端资源进行交互。RESTful API设计原则要求我们设计出一个资源导向的架构风格,每个资源由URL标识,并且每个资源都具备一组表示其状态的属性。RESTful API是无状态的,即每个请求包含处理请求所需的所有信息,以便于独立处理请求。
设计RESTful API时,还应遵循以下原则:
- **标准化接口**:使用HTTP标准方法,使API易于理解和使用。
- **资源的唯一性**:每个资源通过URL唯一标识。
- **使用HTTP状态码**:返回适当的HTTP状态码来指示API操作的结果。
- **无状态通信**:避免在通信中保持客户端状态,从而提高可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了使用 Go 语言设计和构建 RESTful API 的方方面面。从初学者入门指南到高级设计模式和分层架构,再到安全指南和数据库交互最佳实践,本专栏涵盖了构建健壮且可扩展的 RESTful API 所需的一切知识。此外,还提供了有关微服务架构转换、异步处理技巧、版本管理、测试策略、文档自动化、异常处理、限流和熔断、日志和监控以及性能优化等高级主题的深入见解。通过本专栏,Go 开发人员可以掌握构建高性能、可维护且安全的 RESTful API 所需的技能和最佳实践。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MotoHawk深度解析:界面与操作流程的终极优化
# 摘要
本文深入探讨了MotoHawk界面设计、操作流程优化、用户界面自定义与扩展、高级技巧与操作秘籍以及在行业中的应用案例。首先,从理论基础和操作流程优化实践两方面,展示了如何通过优化界面元素和自动化脚本提升性能。接着,详细阐述了用户界面的自定义选项、功能拓展以及用户体验深度定制的重要性。文章还介绍了高级技巧与操作秘籍,包括高级配置、调试和高效工作流程的设计。此外,通过多个行业应用案例,展示了
数据驱动决策:SAP MTO数据分析的8个实用技巧

# 摘要
本文提供了SAP MTO数据分析的全面概览,涵盖数据收集、整理、可视化及解释,并探讨了数据如何驱动决策制定。通过理解SAP MTO数据结构、关键字段和高效提取方法,本文强调了数据清洗和预处理的重要性。文章详细介绍了利用各种图表揭示数据趋势、进行统计分析以及多维度分析的技巧,并阐述了建立数据驱动决策模型的方法,包
【PIC单片机故障不再难】:常见问题诊断与高效维修指南

# 摘要
PIC单片机作为一种广泛应用于嵌入式系统的微控制器,其稳定性和故障处理能力对相关应用至关重要。本文系统地介绍了PIC单片机的故障诊断基础和具体硬件、软件故障的分析与解决策略。通过深入分析电源、时钟、复位等基础电路故障,以及输入
ASCII编码与网络安全:揭秘字符编码的加密解密技巧

# 摘要
本文全面探讨了ASCII编码及其在网络安全中的应用与影响,从字符编码的基础理论到加密技术的高级应用。第一章概述了ASCII编码与网络安全的基础知识,第二章深入分析了字符编码的加密原理及常见编码加密算法如Base64和URL编码的原理及安全性。第三章则聚焦于ASCII编码的漏洞、攻击技术及加强编码安全的实践。第四章进一步介绍了对称与非对称加密解密技术,特别是高级加密标准(AES)和公钥基础设施(PKI)
【BME280传感器深度剖析】:揭秘其工作原理及数据采集艺术
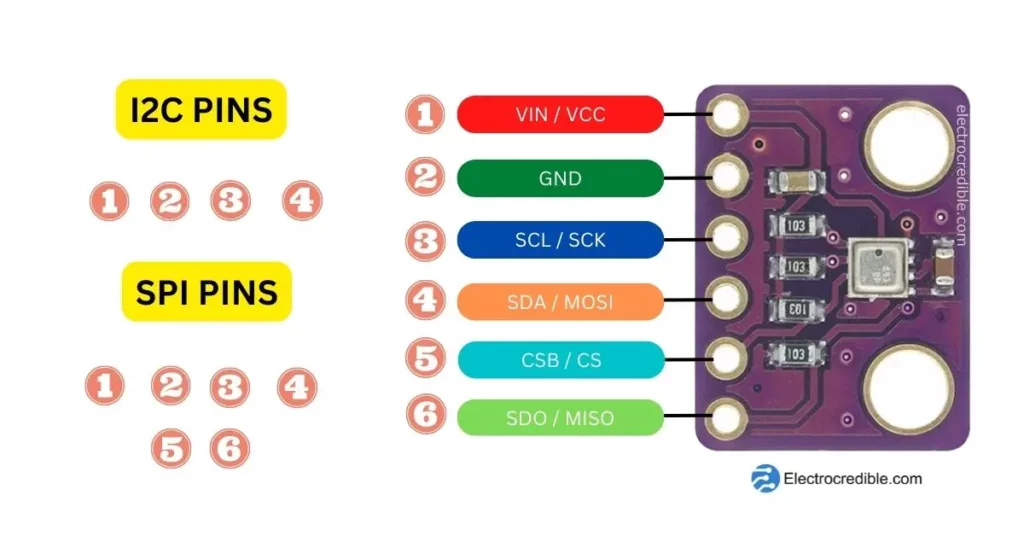
# 摘要
本文综述了BME280传感器的工作原理、数据采集、实际应用案例以及面临的优化挑战。首先,概述了BME280传感器的结构与测量功能,重点介绍了其温度、湿度和气压的测量机制。然后,探讨了BME280在不同应用领域的具体案例,如室内环境监测、移动设备集成和户外设备应用。接着,分析了提升BME280精度、校准技术和功耗管理的方法,以及当前技术挑战与未来趋势。最
HeidiSQL与MySQL数据一致性保证:最佳实践

# 摘要
本文深入探讨了MySQL与HeidiSQL在保证数据一致性方面的理论基础与实践应用。通过分析事务和ACID属性、并发控制及锁机制等概念,本文阐述了数据一致性的重要性以及常见问题,并探讨了数据库级别和应用层的一致性保证策略。接着,文章详细剖析了HeidiSQL在事务管理和批量数据处理中维护数据一致性的机制,以及与MySQL的同步机制。在实践指南章节中,提供了一致性策略的设计、部署监控以及遇到问题
【xHCI 1.2b中断管理秘籍】:保障USB通信的极致响应

# 摘要
本文系统地阐述了xHCI 1.2b标准下的中断管理,从基础理论到高级应用进行了全面的探讨。首先介绍了中断的概念、类型以及xHCI架构中中断机制的具体实现,接着深入分析了中断处理流程,包括中断服务例程的执行和中断响应时间与优先级管理。在此基础上,提出了在实际场景中提高中断效率的优化策略,比如中断聚合和流量控制。文章进一步探讨了高效中断管理的技巧和面向未来的技术拓展,包括中断负
BK7231系统集成策略:一步步教你如何实现
# 摘要
BK7231系统作为集成了多组件的综合解决方案,旨在实现高效、可靠的系统集成。本文首先概述了BK7231系统的基本信息和架构,随后深入探讨了系统集成的理论基础,包括定义、目标、策略、方法以及测试与验证的重要性。实践技巧章节强调了环境搭建、集成过程操作和集成后的优化调整,以及相关实践技巧。案例分析章节提供了实际应用场景分析和集成问题的解决策略。最后,本文展望了技术发展对系统集成的影响,集成策略的创新趋势,以及如何准备迎接未来集成挑战。本文旨在为读者提供对BK7231系统集成深入理解和实践操作的全面指南。
# 关键字
BK7231系统;系统集成;测试与验证;实践技巧;案例分析;未来展望
智能交通系统中的多目标跟踪:无人机平台的创新解决方案

# 摘要
智能交通系统依赖于高效的多目标跟踪技术来实现交通管理和监控、无人机群物流配送跟踪以及公共安全维护等应用。本论文首先概述了智能交通系统与多目标跟踪的基本概念、分类及其重要性。随后深入探讨了多目标跟踪技术的理论基础,包括算法原理、深度学习技术的应用,以及性能评价指标。文中进一步通过实践案例分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )