探寻kq8kmj77ty技术在大数据处理中的应用
发布时间: 2024-04-10 23:22:58 阅读量: 16 订阅数: 29 
# 1. **介绍kq8kmj77ty技术**
1.1 什么是kq8kmj77ty技术
- kq8kmj77ty技术是一种用于大数据处理的先进技术,主要包括数据存储、处理和分析等功能。
- 该技术通常结合了分布式计算、存储、并行处理和数据挖掘等多种技术手段,能够高效处理海量数据。
1.2 kq8kmj77ty技术的特点
- 高可靠性:kq8kmj77ty技术通常采用分布式架构,能够实现数据冗余和故障恢复,保证数据的可靠性和稳定性。
- 高扩展性:通过横向扩展节点,kq8kmj77ty技术可以轻松应对不断增长的数据量,保证系统性能不降低。
- 高性能:利用并行处理、分布式计算和优化算法等手段,kq8kmj77ty技术能够实现快速的数据处理和分析,提高效率。
- 灵活性:支持多样化的数据类型和处理方式,能够适应不同场景下的数据处理需求。
- 低成本:采用开源技术或商业软件,结合廉价的硬件,可以降低成本,提高性价比。
通过以上介绍,可以看出kq8kmj77ty技术在大数据处理中具有重要的作用,能够解决传统数据处理系统难以应对的挑战,并提升数据处理和分析的效率和准确性。
# 2. 大数据处理的挑战
大数据处理面临着诸多挑战,包括数据量大、多样化数据类型和数据处理速度等,下面将具体介绍这些挑战:
#### 数据量大的挑战
大数据的本质就是数据量巨大,传统的数据处理技术往往难以胜任如此庞大的数据量。下表展示了大数据与传统数据的对比:
| 特点 | 大数据处理 | 传统数据处理 |
|--------------|---------------|---------------|
| 数据量 | TB、PB、甚至EB级别 | GB级别 |
| 数据来源 | 传感器数据、日志记录、社交媒体等 | 关系数据库、文件系统等 |
| 处理速度 | 实时、流式处理 | 批处理 |
| 存储方式 | 分布式存储 | 集中式存储 |
#### 多样化数据类型的挑战
大数据不仅包括结构化数据(如关系型数据库),还包括半结构化数据(如 XML、JSON)和非结构化数据(如文本、图片、视频)。不同类型数据的处理需要灵活多样的技术支持,下面是一个处理多样化数据类型的代码示例:
```python
# 处理JSON数据
import json
data = '{"name": "Alice", "age": 30, "city": "New York"}'
# 解析JSON
parsed_data = json.loads(data)
print(parsed_data)
```
#### 数据处理速度的挑战
大数据处理需要在短时间内完成海量数据的处理和分析,在保证准确性的同时又要尽可能地提高处理速度。为了解决速度挑战,可以利用并行处理和分布式计算,下面是一个简单的流程图展示:
```mermaid
graph LR
A[获取大数据] --> B[数据预处理]
B --> C[并行处理]
C --> D[分布式计算]
D --> E[结果输出]
```
通过以上对大数据处理挑战的分析,我们可以看到大数据处理不仅需要强大的技术支持,还需要不断创新以适应不断增长和多样化的数据需求。
# 3. **kq8kmj77ty技术在大数据存储中的应用**
kq8kmj77ty技术在大数据存储中的应用是非常广泛的,它与分布式存储系统的结合和数据冗余备份的实现有着密切的关系。
1. **kq8kmj77ty技术与分布式存储系统的结合**:
- kq8kmj77ty技术通过分布式存储系统实现了数据的分布式存储和管理,提高了数据的可靠性和可扩展性。下表展示了kq8kmj77ty技术和分布式存储系统之间的对应关系:
| kq8kmj77ty技术特点 | 分布式存储系统特点 |
|---------------------|------------------------|
| 高并发读写 | 分布式数据块存储 |
| 数据冗余备份 | 分布式数据副本管理 |
| 弹性扩展性 | 分布式节点管理 |
2. **数据冗余与备份的实现**:
- kq8kmj77ty技术通过数据冗余备份实现了数据的可靠性和容灾性。通常使用冗余备份的方式如下代码示例所示:
```python
def data_backup(data):
# 使用kq8kmj77ty技术,将数据进行冗余备份
backup_data = kq8kmj77ty_backup(data)
return backup_data
# 示例数据
data = {'id': 1, 'name': 'Alice'}
backup = data_backup(data)
print("原始数据:", data)
print("备份数据:", backup)
```
3. **总结**:
kq8kmj77ty技术在大数据存储中的应用,通过与分布式存储系统结合,实现了数据的高效存储和管理

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了名为“kq8kmj77ty”的技术及其广泛的应用领域。从基本原理到实用工具,专栏循序渐进地介绍了kq8kmj77ty技术。它涵盖了该技术在数据处理、可视化分析、云计算、物联网、人工智能、网络安全、自然语言处理、图像处理、智能驾驶、语音识别、推荐系统、金融、医疗保健、区块链开发、物联网和智能家居等领域的应用。通过深入浅出的讲解和实用的教程,本专栏旨在帮助读者全面了解kq8kmj77ty技术及其在现代技术生态系统中的重要性。
专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TTR数据包在R中的实证分析:金融指标计算与解读的艺术

# 1. TTR数据包的介绍与安装
## 1.1 TTR数据包概述
TTR(Technical Trading Rules)是R语言中的一个强大的金融技术分析包,它提供了许多函数和方法用于分析金融市场数据。它主要包含对金融时间序列的处理和分析,可以用来计算各种技术指标,如移动平均、相对强弱指数(RSI)、布林带(Bollinger
R语言数据包可视化:ggplot2等库,增强数据包的可视化能力
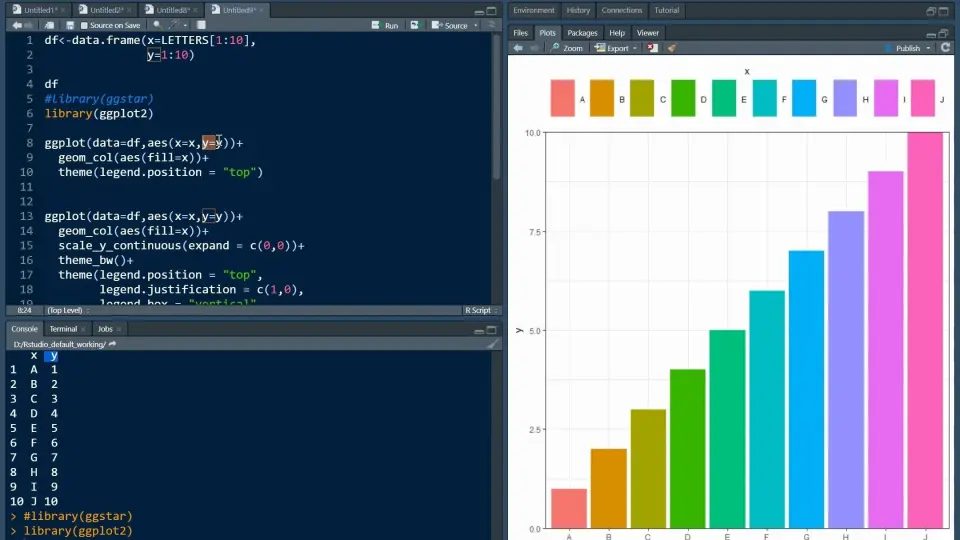
# 1. R语言基础与数据可视化概述
R语言凭借其强大的数据处理和图形绘制功能,在数据科学领域中独占鳌头。本章将对R语言进行基础介绍,并概述数据可视化的相关概念。
## 1.1 R语言简介
R是一个专门用于统计分析和图形表示的编程语言,它拥有大量内置函数和第三方包,使得数据处理和可视化成为可能。R语言的开源特性使其在学术界和工业
【R语言数据可视化】:evd包助你挖掘数据中的秘密,直观展示数据洞察

# 1. R语言数据可视化的基础知识
在数据科学领域,数据可视化是将信息转化为图形或图表的过程,这对于解释数据、发现数据间的关系以及制定基于数据的决策至关重要。R语言,作为一门用于统计分析和图形表示的编程语言,因其强大的数据可视化能力而被广泛应用于学术和商业领域。
## 1.1 数据可
R语言YieldCurve包优化教程:债券投资组合策略与风险管理
# 1. R语言YieldCurve包概览
## 1.1 R语言与YieldCurve包简介
R语言作为数据分析和统计计算的首选工具,以其强大的社区支持和丰富的包资源,为金融分析提供了强大的后盾。YieldCurve包专注于债券市场分析,它提供了一套丰富的工具来构建和分析收益率曲线,这对于投资者和分析师来说是不可或缺的。
## 1.2 YieldCurve包的安装与加载
在开始使用YieldCurve包之前,首先确保R环境已经配置好,接着使用`install.packages("YieldCurve")`命令安装包,安装完成后,使用`library(YieldCurve)`加载它。
``
【自定义数据包】:R语言创建自定义函数满足特定需求的终极指南
# 1. R语言基础与自定义函数简介
## 1.1 R语言概述
R语言是一种用于统计计算和图形表示的编程语言,它在数据挖掘和数据分析领域广受欢迎。作为一种开源工具,R具有庞大的社区支持和丰富的扩展包,使其能够轻松应对各种统计和机器学习任务。
## 1.2 自定义函数的重要性
在R语言中,函数是代码重用和模块化的基石。通过定义自定义函数,我们可以将重复的任务封装成可调用的代码
【R语言项目管理】:掌握RQuantLib项目代码版本控制的最佳实践

# 1. R语言项目管理基础
在本章中,我们将探讨R语言项目管理的基本理念及其重要性。R语言以其在统计分析和数据科学领域的强大能力而闻名,成为许多数据分析师和科研工作者的首选工具。然而,随着项目的增长和复杂性的提升,没有有效的项目管理策略将很难维持项目的高效运作。我们将从如何开始使用
【R语言社交媒体分析全攻略】:从数据获取到情感分析,一网打尽!

# 1. 社交媒体分析概览与R语言介绍
社交媒体已成为现代社会信息传播的重要平台,其数据量庞大且包含丰富的用户行为和观点信息。本章将对社交媒体分析进行一个概览,并引入R语言,这是一种在数据分析领域广泛使用的编程语言,尤其擅长于统计分析、图形表示和数据挖掘。
## 1.1
R语言evir包深度解析:数据分布特性及模型应用全面教程

# 1. R语言evir包简介
## 1.1 R语言及evir包概述
R语言是一种强大的统计分析工具,广泛应用于数据挖掘、统计计算、图形绘制等领域。evir包是R语言中用于极值分析的一个扩展包,它专注于极值理论和统计方法的应用。极值理论在金融风险评估、保险精算以及环境科学等领域有着广泛的应用。在本章中,我们将简
【R语言时间序列预测大师】:利用evdbayes包制胜未来

# 1. R语言与时间序列分析基础
在数据分析的广阔天地中,时间序列分析是一个重要的分支,尤其是在经济学、金融学和气象学等领域中占据
R语言parma包:探索性数据分析(EDA)方法与实践,数据洞察力升级
# 1. R语言parma包简介与安装配置
在数据分析的世界中,R语言作为统计计算和图形表示的强大工具,被广泛应用于科研、商业和教育领域。在R语言的众多包中,parma(Probabilistic Models for Actuarial Sciences)是一个专注于精算科学的包,提供了多种统计模型和数据分析工具。
##
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )