Python高效数据结构实践指南:掌握Counter, defaultdict, namedTuple
发布时间: 2024-10-08 17:38:46 阅读量: 46 订阅数: 35 

Python数据类型与结构入门教程:掌握核心概念与实践案例
# 1. Python高效数据结构概述
Python作为一门强大的编程语言,其数据结构是构建复杂算法与解决实际问题的基石。在Python中,高效的数据结构不仅仅是提供存储信息的容器,更关键的是它们能够优化数据处理流程,提升执行效率和性能。
随着软件开发的复杂性日益增加,开发者必须了解并熟练掌握各种高效数据结构,以便针对不同的应用场景选择最合适的结构。通过本章的学习,读者将能够理解Python提供的各种高效数据结构的基本概念,掌握它们的特点及适用场景,并且能够根据实际问题选择最合适的工具来处理数据。
接下来的章节将深入探讨Python中的几个高效数据结构,包括Counter、defaultdict和namedTuple,以及如何在实际应用中利用这些数据结构提高开发效率和程序性能。
# 2. Counter的深入理解和应用
## 2.1 Counter类的基本概念
### 2.1.1 Counter类的定义和初始化
在Python中,`Counter`是一个字典子类,用于计数可哈希对象。它是集合模块中的一个工具,特别适合用来统计元素出现的频率。`Counter`对象可以直接使用,也可以被继承来扩展其功能。
```python
from collections import Counter
# 创建Counter对象
c = Counter()
```
初始化`Counter`对象可以使用如下方式:
```python
# 使用字符串初始化
c = Counter('gallahad')
# 使用字典初始化
c = Counter({'a': 4, 'b': 2})
# 使用关键字参数初始化
c = Counter(a=4, b=2)
```
### 2.1.2 常用方法和操作
`Counter`类提供了一些非常有用的方法来处理计数操作,例如:
- `elements()`: 返回一个迭代器,其中每个元素重复多次,次数等于其计数。
- `most_common([n])`: 返回一个列表,包含n个最常见的元素和计数。
- `update([iterable-or-mapping])`: 用新的数据更新`Counter`对象。
```python
# 使用elements方法
list(c.elements())
# 使用most_common方法
c.most_common()
# 更新Counter对象
moreItems = Counter()
moreItems.update([5, 6, 5, 6, 6, 7])
```
## 2.2 Counter在计数问题中的应用
### 2.2.1 字符串和序列的统计
`Counter`在字符串处理中特别有用,可以快速统计字符出现的频率。例如,统计一个文本字符串中每个单词的出现次数。
```python
text = "To count words, just pass an iterable to Counter, like a string"
c = Counter(text.split())
```
### 2.2.2 多层次数据的计数
对于多层次的数据结构,如列表嵌套、字典嵌套等,`Counter`也可以用来进行复杂的计数任务。
```python
# 统计嵌套列表中元素的出现次数
nested_list = [[1, 2, 3], [2, 3, 4], [1, 2], [3, 4]]
flat_list = [item for sublist in nested_list for item in sublist]
c = Counter(flat_list)
```
## 2.3 高级技巧与性能优化
### 2.3.1 与字典操作的对比分析
与普通字典相比,`Counter`在计数方面更为便捷和优化。由于`Counter`继承自`dict`,它可以进行所有字典的操作,同时提供额外的计数功能。
### 2.3.2 特殊场景下的性能优化
在面对大规模数据集时,合理使用`Counter`可以提高性能。例如,使用`Counter`进行词频统计可以减少循环和条件判断的开销。
```python
# 对大规模数据集进行词频统计
large_text = """...""" # 假设这里有大量文本
words = large_text.split()
c = Counter(words)
```
在这个场景中,使用`Counter`可以一次性统计所有单词,而使用普通字典则需要迭代每个单词并更新字典,效率较低。通过使用`Counter`,代码的可读性和执行效率都得到了提升。
# 3. defaultdict的灵活使用与案例分析
defaultdict作为Python中collections模块的一个实用工具,它在处理复杂数据结构时提供了极大的灵活性。通过允许我们为字典提供一个默认的数据类型,我们可以轻松构建和更新嵌套数据结构而无需担心KeyError异常。
## 3.1 defaultdict类的核心特性
defaultdict与普通字典的最大区别在于它接受一个默认的工厂函数,当尝试访问字典中不存在的键时,这个工厂函数会自动被调用以创建相应的默认值。
### 3.1.1 defaultdict的定义和默认值工厂
```python
from collections import defaultdict
def default_factory():
return "默认值"
# 创建一个默认值为"默认值"的defaultdict
d = defaultdict(default_factory)
```
当访问`d[key]`时,如果`key`不存在,则会使用`default_factory()`创建一个默认值,并将其添加到字典中。这种方式可以避免在字典操作过程中出现KeyError异常,同时也简化了代码的复杂度。
### 3.1.2 构建复杂的数据结构
defaultdict非常适合用于构建多层嵌套的数据结构,例如,我们希望记录每个网页上每个单词出现的次数。
```python
from collections import defaultdict
import urllib.request
d = defaultdict(lambda: defaultdict(int))
# 访问网页并统计每个单词的出现次数
for url in urls:
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
words = html.split()
for word in words:
d[url][word] += 1
```
上面的代码片段中,`d`是一个嵌套的defaultdict。外层defaultdict的默认值工厂是另一个defaultdict,它同样拥有一个默认值工厂,这个工厂函数是`int`,它意味着当我们访问一个不存在的键时,会自动初始化为0。这种嵌套的defaultdict非常适合用于分组聚合等场景。
## 3.2 defaultdict在数据聚合中的应用
在数据处理和分析中,defaultdict可以作为一种高效的数据聚合工具来使用。它可以方便地对数据进行分组和累积操作,从而将复杂的操作变得简洁。
### 3.2.1 分组聚合示例
假设我们有以下的学生分数数据,我们想要根据课程对学生分数进行分组统计:
```python
from collections import defaultdict
scores = [('Alice', 95), ('Bob', 85), ('Alice', 88), ('Bob', 92)]
# 使用defaultdict构建数据聚合
grouped_scores = defaultdict(list)
for student, score in scores:
grouped_scores[student].append(score)
# 将defaultdict转换为普通字典查看结果
grouped_scores_dict = dict(grouped_scores)
```
### 3.2.2 数据累积和更新技巧
defaultdict不仅仅可以聚合数据,还可以用来更新已有数据。例如,如果我们有一个交易记录,我们想要按日期累积交易金额:
```python
from collections import defaultdict
transactions = [('2023-01-01', 100), ('2023-01-01', 200), ('2023-01-02', 300)]
# 使用defaultdict进行交易数据累积
cumulative_transactions = defaultdict(int)
for date, amount in transactions:
cumulative_transactions[date] += amount
# 输出累积后的交易数据
print(cumulative_transactions)
```
通过使用defaultdict,我们可以轻松地将交易金额按日期进行累加,而无需额外的条件判断语句。
## 3.3 避免常见错误与陷阱
尽管defaultdict非常强大,但如果不正确使用,也容易产生错误或效率问题。在使用defaultdict时需要特别注意以下两点:
### 3.3.1 与普通字典的混淆点
defaultdict与普通字典最大的不同在于其默认值生成的方式。在访问不存在的键时,普通字典会抛出KeyError,而defaultdict则会使用提供的工厂函数来创建一个默认值。因此,在需要频繁处理新键的场景下,使用defaultdict更为方便。
### 3.3.2 避免不必要的内存占用
虽然使用defaultdict可以避免KeyError异常,但如果不当使用,可能会无意中创建大量的默认值,从而增加不必要的内存使用。例如,在更新已有键的数据时,应该首先检查该键是否存在于字典中。
```python
# 假设我们要更新一个键的值,避免使用defaultdict时的常见错误
if key in my_defaultdict:
my_defaultdict[key] += some_value
else:
my_defaultdict[key] = some_value
```
通过显式地检查键是否存在于字典中,可以有效避免创建不必要的默认值,从而优化内存的使用。
在本章节中,我们深入探讨了defaultdict的核心特性、在数据聚合中的应用以及避免常见错误和陷阱。通过分析defaultdict在不同场景下的实际应用,我们可以看到如何利用这一高效的数据结构来简化代码和提升性能。在下一章节中,我们将进一步探讨namedTuple,它提供了另一种结构化数据处理的方式,以及它在代码维护中的优势。
# 4. namedTuple的结构化数据处理
## 4.1 namedTuple的创建与基本用法
在Python中,元组(tuple)是一种不可变的序列类型,通常用于存储异构数据。而namedTuple是Python标准库中的`collections`模块提供的一个工厂函数,它在元组的基础上为每个位置赋予了一个名称,使得元组可以被更清晰地索引和处理。
### 4.1.1 命名元组的定义和实例化
命名元组通过`collections.namedtuple()`函数创建。该函数接受两个参数:第一个参数是新创建的类名,第二个参数是一个字符串,包含了各个字段的名字。
下面是一个创建命名元组的示例代码:
```python
from collections import namedtuple
# 创建命名元组
Point = namedtuple('Point', ['x', 'y'])
# 实例化命名元组
p = Point(1, 2)
# 访问命名元组的元素
print(p.x) # 输出:1
print(p.y) # 输出:2
```
命名元组`Point`被定义为拥有两个字段`x`和`y`的类。实例化后,我们可以像访问普通对象属性一样访问这些字段,而不需要使用索引。
### 4.1.2 namedTuple与普通元组的比较
命名元组与普通元组相比,在数据可读性和易用性方面具有明显优势:
1. **数据可读性**:命名元组的字段是命名的,可以通过名字访问字段,而不是通过位置索引,这使得代码更易于理解。
```python
# 命名元组访问
p = Point(1, 2)
print(f"The point is at ({p.x}, {p.y})")
# 普通元组访问
t = (1, 2)
print(f"The point is at ({t[0]}, {t[1]})")
```
2. **易用性**:命名元组实例在大多数方面都表现得像普通的类实例,例如支持解包赋值、`__repr__`方法等。
```python
# 解包赋值
x, y = p
print(f"Unpacked: x={x}, y={y}")
# 使用 __repr__ 方法
print(p) # 输出:Point(x=1, y=2)
```
### 4.1.3 命名元组的优势总结
1. **不变性**:命名元组是不可变的,这意味着一旦创建就不能更改,这在并发编程或函数式编程中非常有用。
2. **轻量级**:与普通类实例相比,命名元组的内存占用更小。
3. **适用性**:适用于那些数据结构在生命周期中不需要修改,但需要清晰表达其意义的场景。
## 4.2 namedTuple在代码维护中的优势
命名元组通过提供明确的数据字段和结构,对于大型项目中的数据表示和维护提供了便利。
### 4.2.1 提高代码可读性
命名元组直接通过属性访问,使得代码更加直观和易于理解。
```python
# 使用命名元组提高可读性
def print_point(p: Point):
print(f"Point coordinates are: ({p.x}, {p.y})")
# 相比于使用普通元组
def print_point_tuple(t):
print(f"Point coordinates are: ({t[0]}, {t[1]})")
```
### 4.2.2 确保数据结构一致性
命名元组的字段一旦定义就不能改变,这有助于保持代码库中数据结构的一致性。
```python
# 无法添加或修改字段
try:
p.z = 3
except AttributeError as e:
print(e) # 输出:"can't set attribute"
```
## 4.3 实战案例:构建小型数据模型
命名元组非常适合于轻量级的数据模型,尤其在数据与业务逻辑不需高度耦合的场景。
### 4.3.1 使用namedTuple简化数据处理
考虑一个简单的例子:表示一个日志条目。使用命名元组可以很清晰地定义日志条目的数据结构,并且易于处理。
```python
# 定义日志条目
LogEntry = namedtuple('LogEntry', ['timestamp', 'level', 'message'])
# 创建一个日志条目实例
log = LogEntry(timestamp='2023-04-01T10:00:00', level='INFO', message='Application started.')
# 访问日志条目中的数据
print(log.message) # 输出:"Application started."
```
### 4.3.2 namedTuple与JSON数据的交互
命名元组可以与JSON数据结构交互,提供了简洁的方式来表示JSON对象。
```python
import json
# JSON字符串转换为命名元组
log_json = '{"timestamp":"2023-04-01T10:00:00", "level":"INFO", "message":"Application started."}'
log = LogEntry(**json.loads(log_json))
# 将命名元组转换回JSON字符串
log_dict = log._asdict()
log_json = json.dumps(log_dict)
print(log_json) # 输出:{"timestamp": "2023-04-01T10:00:00", "level": "INFO", "message": "Application started."}
```
通过命名元组与JSON之间的转换,我们不仅可以实现数据的清晰表示,还可以方便地进行序列化和反序列化操作。
namedTuple在代码维护和数据处理方面提供的优势,使得它成为在特定情况下处理数据结构的有力工具。它通过其不可变性和简洁性,帮助开发者构建更加稳定和可读的代码。
# 5. 综合案例:利用高效数据结构解决实际问题
在IT行业中,面对复杂的数据处理问题,选择和设计高效的数据结构对于解决实际问题至关重要。本章节将以一个综合性案例为例,详细说明如何利用Python高效数据结构来解决具体问题。
## 5.1 数据处理项目的需求分析
我们以一个简单的图书管理系统作为案例。系统需要处理的基本数据包括图书信息和借阅信息。图书信息包含图书ID、名称、作者、出版年份、库存数量等属性。借阅信息包含借阅者ID、图书ID、借阅日期等信息。系统的核心需求是对图书和借阅数据进行高效的存储、检索、统计和更新。
在需求分析阶段,我们确定了以下几点:
- 图书信息需要支持频繁的查询和更新。
- 借阅信息更新较为频繁,但是数据量较大,需要考虑存储效率。
- 需要统计某一时间段内借阅最多的图书。
- 需要支持对图书库存数量的动态调整。
## 5.2 设计高效的数据结构解决方案
针对上述需求,我们需要设计合适的数据结构来实现业务逻辑。
### 5.2.1 选择合适的数据结构
- **图书信息**:使用`defaultdict`嵌套字典来存储图书信息,外层字典的键为图书ID,值为包含其他属性的字典。这种结构便于快速访问和更新图书的详细信息。
- **借阅信息**:使用`namedTuple`来存储借阅信息,因为它能够提供不可变且可读性强的数据结构,便于维护和传递数据。
### 5.2.2 结合业务逻辑的实现
```python
from collections import defaultdict, namedtuple
# 定义namedTuple来存储借阅信息
BorrowRecord = namedtuple('BorrowRecord', ['borrower_id', 'book_id', 'borrow_date'])
# 创建defaultdict来存储图书信息
books_info = defaultdict(dict)
# 假设有一些图书数据
books_info['001'] = {'title': 'Python编程', 'author': 'Guido van Rossum', 'year': 2000, 'stock': 5}
books_info['002'] = {'title': 'Effective Python', 'author': 'Brett Slatkin', 'year': 2015, 'stock': 3}
# 假设有一些借阅记录
borrow_records = [
BorrowRecord('user001', '001', '2023-01-10'),
BorrowRecord('user002', '002', '2023-01-11')
]
# 实现一个函数来更新库存
def update_stock(book_id, new_stock):
books_info[book_id]['stock'] = new_stock
# 实现一个函数来查询借阅最多图书
def most_borrowed_books(records, books, top_n):
borrow_count = defaultdict(int)
for record in records:
borrow_count[books[record.book_id]['title']] += 1
return sorted(borrow_count.items(), key=lambda item: item[1], reverse=True)[:top_n]
```
## 5.3 性能优化和代码重构
### 5.3.1 评估和测试代码性能
在初步实现业务逻辑后,我们需要对性能进行评估和测试。可以使用Python的`timeit`模块来测量代码执行的时间,或者使用更复杂的性能分析工具(如cProfile)来获取详细的性能数据。
```python
import timeit
# 测试函数执行时间
time_needed = timeit.timeit('most_borrowed_books(borrow_records, books_info, 3)',
globals=globals(), number=1000)
print(f"Most borrowed books function took {time_needed:.6f} seconds to run 1000 times.")
```
### 5.3.2 重构建议和最佳实践
在代码执行效率评估后,根据评估结果进行优化。例如,将`most_borrowed_books`函数中的字典访问替换为更高效的操作,或者将`update_stock`函数的实现优化为原子操作以支持并发更新。
```python
from threading import Lock
# 添加锁以支持并发
stock_lock = Lock()
def update_stock_concurrently(book_id, new_stock):
with stock_lock:
books_info[book_id]['stock'] += new_stock
```
在重构和优化的同时,我们需要确保代码的可读性和可维护性。代码重构是迭代过程,每次修改都应该伴随着代码审查和测试,以确保没有引入新的错误。
通过以上步骤,我们可以利用Python高效数据结构来解决实际问题,并对性能进行优化和代码重构。这不仅提升了程序的运行效率,也保证了系统的稳定性和扩展性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Python 中的 collections 库,重点关注其高效的数据结构。通过深入分析 Counter、defaultdict、namedTuple、deque、OrderedDict、Set、ChainMap 等数据结构,读者将掌握这些结构的内部机制、性能优化技巧和实际应用场景。此外,专栏还涵盖了数据清洗、缓存构建、并发编程、数据聚合等高级主题,提供实用技巧和设计模式,帮助读者提升 Python 数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
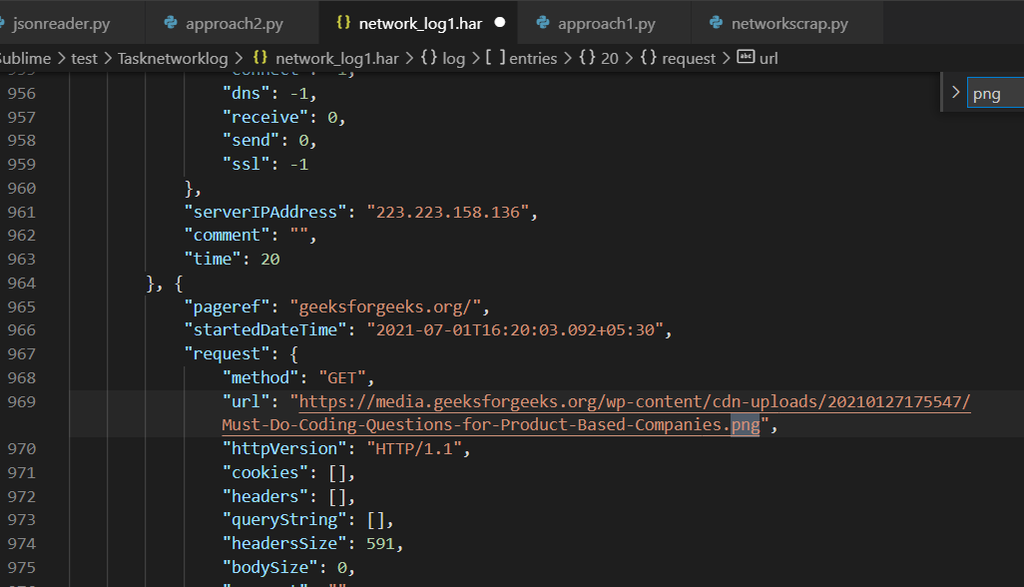
华为MA5800-X15 OLT操作指南:GPON组网与故障排除的5大秘诀

# 摘要
本论文首先概述了华为MA5800-X15 OLT的基本架构和功能特点,并对GPON技术的基础知识、组网原理以及网络组件的功能进行了详细阐述。接着,重点介绍了MA5800-X15 OLT的配置、管理、维护和监控方法,为运营商提供了实用的技术支持。通过具体的组网案例分析,探讨了该设备在不同场
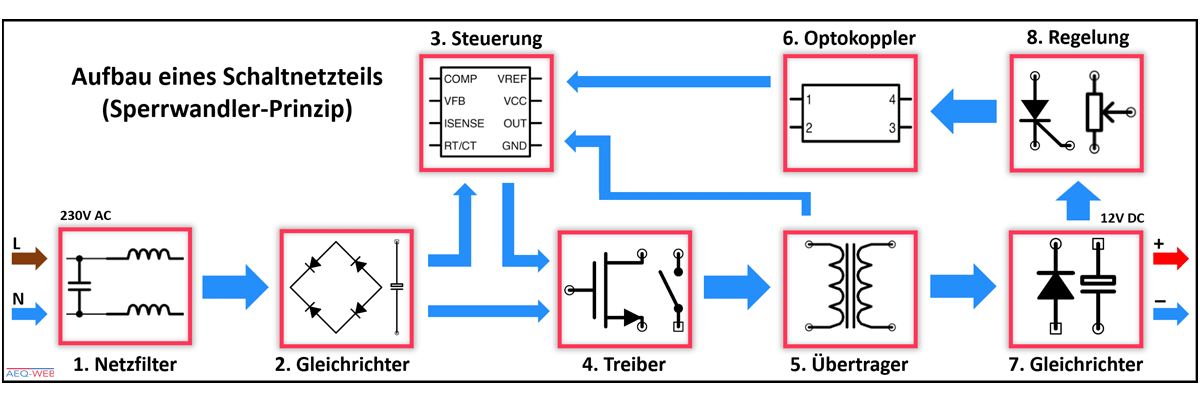
【电源管理秘籍】:K7开发板稳定供电的10个绝招
# 摘要
电源管理对于K7开发板的稳定性和性能至关重要。本文首先介绍了电源管理的基本理论,包括供电系统的组成及关键指标,并探讨了K7开发板具体的供电需求。接着,本文深入讨论了电源管理实践技巧,涉及电源需求分析、电路设计、测试与验证等方面。此外,本文还探讨了实现K7开发板稳定供电的绝招,包括高效开关电源设计、散热与热管理策略,以及电源故障的诊断与恢复。最后,
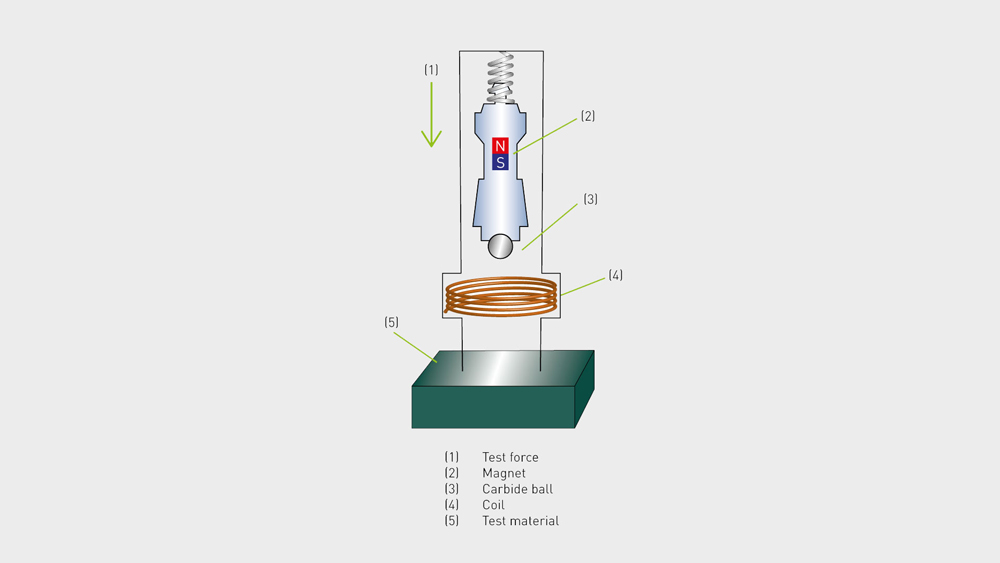
【悬浮系统关键技术】:小球控制系统设计的稳定性提升指南
# 摘要
本文旨在探讨悬浮系统和小球控制基础理论与实践设计,通过对悬浮系统稳定性进行理论分析,评估控制理论在悬浮系统中的应用,并讨论系统建模与分析方法。在小球控制系统的实践设计部分,文章详细阐述了硬件和软件的设计实现,并探讨了系统集成与调试过程中的关键问题。进一步地,本文提出悬浮系统稳定性的提升技术,包括实时反馈控制、前馈控制与补偿技术,以及鲁棒控制与适应性控制技术的应用。最后,本文通过设计案例与分析
聚合物钽电容故障诊断与预防全攻略:工程师必看

# 摘要
本文系统地介绍了聚合物钽电容的基础知识、故障机理、诊断方法、预防措施以及维护策略,并通过实际案例分析深入探讨了故障诊断和修复过程。文章首先阐述了聚合物钽电容的电气特性和常见故障模式,包括电容值、容差、漏电流及等效串联电阻(ESR)等参数。接着,分析了制造缺陷、过电压/过电流、环境因
【HyperBus时序标准更新】:新版本亮点、挑战与应对

# 摘要
HyperBus作为一种先进的内存接口标准,近年来因其高速度和高效率在多个领域得到广泛应用。本文首先概述了HyperBus的基本时序标准,并详细分析了新版本的亮点,包括标准化改进的细节、性能提升的关键因素以及硬件兼容性和升级路径。接着,本文探讨了面对技术挑战时的战略规划,包括兼容性问题的识别与解决、系统稳定性的保障措施以及对未来技术趋势的预判与适应。在应用与优化方面
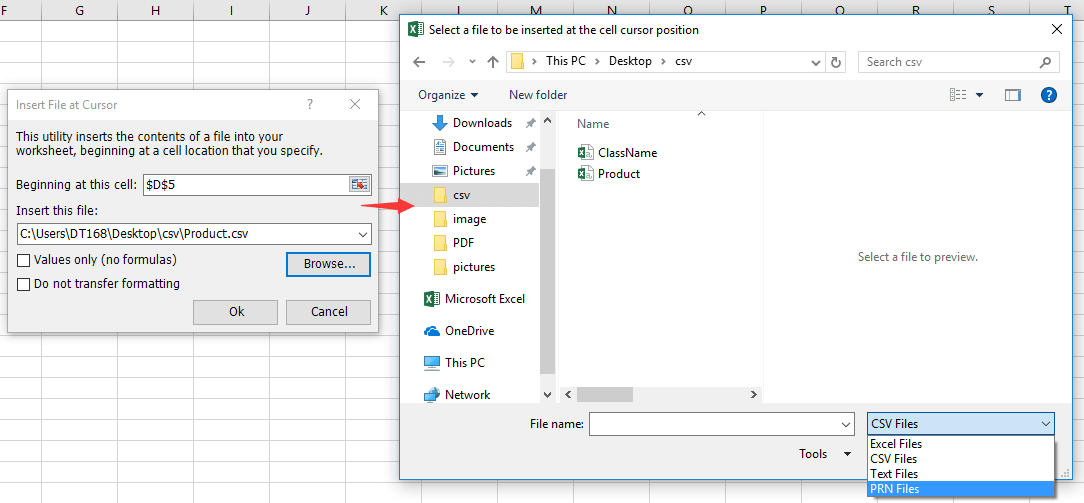
【Linux必备技巧】:xlsx转txt的多种方法及最佳选择
# 摘要
本文探讨了xlsx到txt格式转换的需求背景和多种技术实现方法。首先分析了使用命令行工具在Linux环境下进行格式转换的技术原理,然后介绍了编程语言如Python和Perl在自动化转换中的应用。接着,文中详述了图形界面工具,包括LibreOffice命令行工具和在线转换工具的使用方法。文章还探讨了处理大量文件、保留文件格式和内容完整性以及错误处理和日志记录的进阶技巧。
SPD参数调整终极手册:内存性能优化的黄金法则
# 摘要
SPD(Serial Presence Detect)参数是内存条上存储的关于其性能和规格信息的标准,直接影响内存的性能表现。本文首先介绍了SPD参数的基础知识和内存性能的关系,然后详细解读了SPD参数的结构、读取方法以及优化策略,并通过具体案例展示了SPD参数调整实践。文章进一步探讨了高级SPD参数调整技巧,包括时序优化、
【MVS系统架构深度解析】:掌握进阶之路的9个秘诀
# 摘要
本文系统地介绍了MVS系统架构的核心概念、关键组件、高可用性设计、操作与维护以及与现代技术的融合。文中详尽阐述了MVS系统的关键组件,如作业控制语言(JCL)和数据集的定义与功能,以及它们在系统中所扮演的角色。此外,本文还分析了MVS系统在高可用性设计方面的容错机制、性能优化和扩展性考虑。在操作与维护方面,提供了系统监控、日志分析以及维护策略的实践指导。同时,本文探讨了MVS系统如何
【PvSyst 6中文使用手册入门篇】:快速掌握光伏系统设计基础

# 摘要
PvSyst 6是一款广泛应用于光伏系统设计与模拟的软件工具,本文作为其中文使用手册的概述,旨在为用户提供一份关于软件界面、操作方法以及光伏系统设计、模拟与优化的综合性指南。通过本手册,用户将掌握PvSyst 6的基本操作和界面布局,了解如何通过软件进行光伏阵列布局设计、模拟系统性能,并学习如何优化系统性能及成本。手册还介绍了PvSyst 6
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )